

Upload folder using huggingface_hub
Browse files- .gitattributes +4 -0
- LICENSE +202 -0
- Notice.txt +1 -0
- README.md +257 -3
- added_tokens.json +33 -0
- config.json +195 -0
- configuration_aimv2.py +61 -0
- configuration_qwen2.py +204 -0
- configuration_sailvl.py +113 -0
- conversation.py +371 -0
- generation_config.json +4 -0
- merges.txt +0 -0
- model-00001-of-00004.safetensors +3 -0
- model-00002-of-00004.safetensors +3 -0
- model-00003-of-00004.safetensors +3 -0
- model-00004-of-00004.safetensors +3 -0
- model.safetensors.index.json +525 -0
- modeling_aimv2.py +198 -0
- modeling_qwen2.py +1514 -0
- modeling_sailvl.py +388 -0
- special_tokens_map.json +31 -0
- statics/paper_page.png +3 -0
- statics/performance.png +3 -0
- statics/sail.png +3 -0
- tokenizer.json +3 -0
- tokenizer.model +3 -0
- tokenizer_config.json +279 -0
- vocab.json +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,7 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
*.jpg filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
*.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
*.json filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
model.safetensors filter=lfs diff=lfs merge=lfs -text
|
LICENSE
ADDED
|
@@ -0,0 +1,202 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
Apache License
|
| 3 |
+
Version 2.0, January 2004
|
| 4 |
+
http://www.apache.org/licenses/
|
| 5 |
+
|
| 6 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 7 |
+
|
| 8 |
+
1. Definitions.
|
| 9 |
+
|
| 10 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 11 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 12 |
+
|
| 13 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 14 |
+
the copyright owner that is granting the License.
|
| 15 |
+
|
| 16 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 17 |
+
other entities that control, are controlled by, or are under common
|
| 18 |
+
control with that entity. For the purposes of this definition,
|
| 19 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 20 |
+
direction or management of such entity, whether by contract or
|
| 21 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 22 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 23 |
+
|
| 24 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 25 |
+
exercising permissions granted by this License.
|
| 26 |
+
|
| 27 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 28 |
+
including but not limited to software source code, documentation
|
| 29 |
+
source, and configuration files.
|
| 30 |
+
|
| 31 |
+
"Object" form shall mean any form resulting from mechanical
|
| 32 |
+
transformation or translation of a Source form, including but
|
| 33 |
+
not limited to compiled object code, generated documentation,
|
| 34 |
+
and conversions to other media types.
|
| 35 |
+
|
| 36 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 37 |
+
Object form, made available under the License, as indicated by a
|
| 38 |
+
copyright notice that is included in or attached to the work
|
| 39 |
+
(an example is provided in the Appendix below).
|
| 40 |
+
|
| 41 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 42 |
+
form, that is based on (or derived from) the Work and for which the
|
| 43 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 44 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 45 |
+
of this License, Derivative Works shall not include works that remain
|
| 46 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 47 |
+
the Work and Derivative Works thereof.
|
| 48 |
+
|
| 49 |
+
"Contribution" shall mean any work of authorship, including
|
| 50 |
+
the original version of the Work and any modifications or additions
|
| 51 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 52 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 53 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 54 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 55 |
+
means any form of electronic, verbal, or written communication sent
|
| 56 |
+
to the Licensor or its representatives, including but not limited to
|
| 57 |
+
communication on electronic mailing lists, source code control systems,
|
| 58 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 59 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 60 |
+
excluding communication that is conspicuously marked or otherwise
|
| 61 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 62 |
+
|
| 63 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 64 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 65 |
+
subsequently incorporated within the Work.
|
| 66 |
+
|
| 67 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 68 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 69 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 70 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 71 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 72 |
+
Work and such Derivative Works in Source or Object form.
|
| 73 |
+
|
| 74 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 75 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 76 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 77 |
+
(except as stated in this section) patent license to make, have made,
|
| 78 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 79 |
+
where such license applies only to those patent claims licensable
|
| 80 |
+
by such Contributor that are necessarily infringed by their
|
| 81 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 82 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 83 |
+
institute patent litigation against any entity (including a
|
| 84 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 85 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 86 |
+
or contributory patent infringement, then any patent licenses
|
| 87 |
+
granted to You under this License for that Work shall terminate
|
| 88 |
+
as of the date such litigation is filed.
|
| 89 |
+
|
| 90 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 91 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 92 |
+
modifications, and in Source or Object form, provided that You
|
| 93 |
+
meet the following conditions:
|
| 94 |
+
|
| 95 |
+
(a) You must give any other recipients of the Work or
|
| 96 |
+
Derivative Works a copy of this License; and
|
| 97 |
+
|
| 98 |
+
(b) You must cause any modified files to carry prominent notices
|
| 99 |
+
stating that You changed the files; and
|
| 100 |
+
|
| 101 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 102 |
+
that You distribute, all copyright, patent, trademark, and
|
| 103 |
+
attribution notices from the Source form of the Work,
|
| 104 |
+
excluding those notices that do not pertain to any part of
|
| 105 |
+
the Derivative Works; and
|
| 106 |
+
|
| 107 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 108 |
+
distribution, then any Derivative Works that You distribute must
|
| 109 |
+
include a readable copy of the attribution notices contained
|
| 110 |
+
within such NOTICE file, excluding those notices that do not
|
| 111 |
+
pertain to any part of the Derivative Works, in at least one
|
| 112 |
+
of the following places: within a NOTICE text file distributed
|
| 113 |
+
as part of the Derivative Works; within the Source form or
|
| 114 |
+
documentation, if provided along with the Derivative Works; or,
|
| 115 |
+
within a display generated by the Derivative Works, if and
|
| 116 |
+
wherever such third-party notices normally appear. The contents
|
| 117 |
+
of the NOTICE file are for informational purposes only and
|
| 118 |
+
do not modify the License. You may add Your own attribution
|
| 119 |
+
notices within Derivative Works that You distribute, alongside
|
| 120 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 121 |
+
that such additional attribution notices cannot be construed
|
| 122 |
+
as modifying the License.
|
| 123 |
+
|
| 124 |
+
You may add Your own copyright statement to Your modifications and
|
| 125 |
+
may provide additional or different license terms and conditions
|
| 126 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 127 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 128 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 129 |
+
the conditions stated in this License.
|
| 130 |
+
|
| 131 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 132 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 133 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 134 |
+
this License, without any additional terms or conditions.
|
| 135 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 136 |
+
the terms of any separate license agreement you may have executed
|
| 137 |
+
with Licensor regarding such Contributions.
|
| 138 |
+
|
| 139 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 140 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 141 |
+
except as required for reasonable and customary use in describing the
|
| 142 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 143 |
+
|
| 144 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 145 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 146 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 147 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 148 |
+
implied, including, without limitation, any warranties or conditions
|
| 149 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 150 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 151 |
+
appropriateness of using or redistributing the Work and assume any
|
| 152 |
+
risks associated with Your exercise of permissions under this License.
|
| 153 |
+
|
| 154 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 155 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 156 |
+
unless required by applicable law (such as deliberate and grossly
|
| 157 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 158 |
+
liable to You for damages, including any direct, indirect, special,
|
| 159 |
+
incidental, or consequential damages of any character arising as a
|
| 160 |
+
result of this License or out of the use or inability to use the
|
| 161 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 162 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 163 |
+
other commercial damages or losses), even if such Contributor
|
| 164 |
+
has been advised of the possibility of such damages.
|
| 165 |
+
|
| 166 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 167 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 168 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 169 |
+
or other liability obligations and/or rights consistent with this
|
| 170 |
+
License. However, in accepting such obligations, You may act only
|
| 171 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 172 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 173 |
+
defend, and hold each Contributor harmless for any liability
|
| 174 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 175 |
+
of your accepting any such warranty or additional liability.
|
| 176 |
+
|
| 177 |
+
END OF TERMS AND CONDITIONS
|
| 178 |
+
|
| 179 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 180 |
+
|
| 181 |
+
To apply the Apache License to your work, attach the following
|
| 182 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 183 |
+
replaced with your own identifying information. (Don't include
|
| 184 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 185 |
+
comment syntax for the file format. We also recommend that a
|
| 186 |
+
file or class name and description of purpose be included on the
|
| 187 |
+
same "printed page" as the copyright notice for easier
|
| 188 |
+
identification within third-party archives.
|
| 189 |
+
|
| 190 |
+
Copyright [yyyy] [name of copyright owner]
|
| 191 |
+
|
| 192 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 193 |
+
you may not use this file except in compliance with the License.
|
| 194 |
+
You may obtain a copy of the License at
|
| 195 |
+
|
| 196 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 197 |
+
|
| 198 |
+
Unless required by applicable law or agreed to in writing, software
|
| 199 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 200 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 201 |
+
See the License for the specific language governing permissions and
|
| 202 |
+
limitations under the License.
|
Notice.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Copyright (year) Bytedance Ltd. and/or its affiliates
|
README.md
CHANGED
|
@@ -1,3 +1,257 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: apache-2.0
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
- zh
|
| 6 |
+
base_model:
|
| 7 |
+
- Qwen/Qwen2.5-1.5B-Instruct
|
| 8 |
+
---
|
| 9 |
+
## Introduction
|
| 10 |
+
|
| 11 |
+

|
| 12 |
+
|
| 13 |
+
SAIL-VL is a state-of-the-art vision-language model (VLM) developed by the Bytedance Douyin Content Team. The goal of SAIL-VL is to develope a high-performance vision language model that facilitates deployment on mobile devices and ensures accessibility and affordability for a broad audience. Through careful tuning of data and training recipes, SAIL-VL demonstrates that even a small VLM can benefit significantly from data scaling.
|
| 14 |
+
|
| 15 |
+
SAIL-VL V1.5 is the brand new version of our model, which incorporates advanced techniques to achieve higher performance. For visual encoding, we use the stronger AIM-V2 ViT as our vision encoder, introduce the progressive training strategy to warmup and a visual token scaling strategy during inference. During training, we introduce an adaptive stream packing strategy to support higher throughput and longer sequences. Finally, we add more conversation and reasoning data, filter out noisy data and add a new training stage for videos. With all these updates, our model outperforms recent SoTA models of comparable sizes, InternVL-3-2B, Ovis2-2B and even Qwen2.5-VL-3B.
|
| 16 |
+
|
| 17 |
+
Please enjoy our model and feel free to contact us for any question or opportunity.
|
| 18 |
+
|
| 19 |
+
## News🚀🚀🚀
|
| 20 |
+
- 2024-4-16: 📖 We released our powerful v1.5 series models, check out at [🤗SAIL-VL-1.5-2B](https://huggingface.co/BytedanceDouyinContent/SAIL-VL-1.5-2B) [🤗SAIL-VL-1.5-8B](https://huggingface.co/BytedanceDouyinContent/SAIL-VL-1.5-8B) ~
|
| 21 |
+
- 2024-2-19: 📖 We released our 8B model, check out at [🤗SAIL-VL-8B](https://huggingface.co/BytedanceDouyinContent/SAIL-VL-8B) ~
|
| 22 |
+
- 2024-1-10: 📖 We released our paper on Arxiv: [Scalable Vision Language Model Training via High Quality Data Curation
|
| 23 |
+
](https://arxiv.org/abs/2501.05952)
|
| 24 |
+
- 2024-12-25: 🚀 We ranked the 1st in [OpenCompass Multi-modal Leaderboard](https://rank.opencompass.org.cn/leaderboard-multimodal/?m=REALTIME) among models of 2B parameters.
|
| 25 |
+
## Model Card
|
| 26 |
+
|
| 27 |
+
### Model Architecture:
|
| 28 |
+
|
| 29 |
+
| Architecture | ViT | LLM | Adapter | Token Merge | Resolution |
|
| 30 |
+
| --- | --- | --- | --- | --- | --- |
|
| 31 |
+
| [🤗SAIL-VL-1.5-2B](https://huggingface.co/BytedanceDouyinContent/SAIL-VL-1.5-2B) | [🤗AimV2-Huge](https://huggingface.co/apple/aimv2-huge-patch14-448) |[🤗Qwen2.5-1.5B](https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct) | 2-layer MLP | 2x2 | 448x448xN |
|
| 32 |
+
| [🤗SAIL-VL-1.5-8B](https://huggingface.co/BytedanceDouyinContent/SAIL-VL-1.5-8B) | [🤗InternViT-300M](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [🤗Qwen2.5-7B](https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct) | 2-layer MLP | 2x2 | 448x448xN |
|
| 33 |
+
| [🤗SAIL-VL-2B](https://huggingface.co/BytedanceDouyinContent/SAIL-VL-2B) | [🤗InternViT-300M](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [🤗Qwen2.5-1.5B](https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct) | 2-layer MLP | 2x2 | 448x448xN |
|
| 34 |
+
| [🤗SAIL-VL-8B](https://huggingface.co/BytedanceDouyinContent/SAIL-VL-8B) | [🤗InternViT-300M](https://huggingface.co/OpenGVLab/InternViT-300M-448px) | [🤗Qwen2.5-7B](https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct) | 2-layer MLP | 2x2 | 448x448xN |
|
| 35 |
+
|
| 36 |
+
### Training Recipes Overview:
|
| 37 |
+
|
| 38 |
+
Sail-VL benefits from high-quality data and carefully curated training recipes. We find the data quality, quantity and the design of curriculum training pipeline are crucial for model performance. With the proper design and data, the model's capacity scales effectively with data expansion at all stages, leading to enhanced performance.
|
| 39 |
+
|
| 40 |
+

|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
## Evaluation
|
| 44 |
+
|
| 45 |
+
SAIL-VL is competitive compared with recently released SoTAs, InternVL-2.5, Qwen2.5-VL, Ovis-2 and InternVL3.
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
### Detail Evaluations:
|
| 49 |
+
|
| 50 |
+
| Benchmark | InternVL-2.5-2B | Qwen2.5-VL-3B | InternVL3-2B | Ovis2-2B | SAIL-VL-1.5-2B |
|
| 51 |
+
|---------------------|------------|----------|--------------|--------------|---------------|
|
| 52 |
+
| OpenCompassAvg | 60.78 | 64.90 | 64.83 | 65.49 | 67.67 |
|
| 53 |
+
| Total Avg | 66.54 | 71.35 | 69.97 | 70.30 | 72.61 |
|
| 54 |
+
| GeneralQA Avg | 63.55 | 66.83 | 68.34 | 64.05 | 68.05 |
|
| 55 |
+
| OCR Avg | 76.79 | 83.25 | 79.27 | 83.09 | 83.74 |
|
| 56 |
+
| MMBench_DEV_V11 * | 79.73 | 82.40 | 84.25 | 81.79 | 85.05 |
|
| 57 |
+
| MathVista_MINI | 52.00 | 60.20 | 57.30 | 64.30 | 67.30 |
|
| 58 |
+
| MMStar * | 53.40 | 55.13 | 61.33 | 58.13 | 62.80 |
|
| 59 |
+
| MMMU_VAL * | 41.89 | 48.11 | 47.11 | 42.67 | 42.89 |
|
| 60 |
+
| MMVet | 61.33 | 61.24 | 65.14 | 57.39 | 61.38 |
|
| 61 |
+
| HallusionBench | 42.79 | 48.29 | 41.42 | 50.05 | 49.80 |
|
| 62 |
+
| AI2D_TEST + | 74.90 | 80.73 | 78.72 | 82.80 | 83.68 |
|
| 63 |
+
| OCRBench + | 802 | 830 | 834 | 868 | 885 |
|
| 64 |
+
| RealWorldQA * | 61.05 | 65.36 | 64.58 | 66.41 | 67.06 |
|
| 65 |
+
| NaturalBench * | 69.95 | 72.49 | 75.34 | 62.97 | 76.80 |
|
| 66 |
+
| InfoVQA_VAL + | 61.85 | 76.11 | 66.94 | 72.70 | 71.82 |
|
| 67 |
+
| ChartQA_TEST + | 79.36 | 87.00 | 80.40 | 84.72 | 84.84 |
|
| 68 |
+
| MME * | 75.25 | 77.46 | 77.44 | 72.32 | 73.67 |
|
| 69 |
+
| DocVQA_VAL + | 87.68 | 93.11 | 87.46 | 91.49 | 91.62 |
|
| 70 |
+
| TextVQA_VAL + | 76.76 | 79.55 | 78.71 | 80.00 | 81.98 |
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
Details for average performance section:
|
| 76 |
+
- OpenCompass-Avg includes public avaliable validation sets from OpenCompass: AI2D_TEST, HallusionBench, MMBench_DEV_V11, MMMU_DEV_VAL, MMStar, MMVet, MathVista_MINI, evaluated by our team.
|
| 77 |
+
|
| 78 |
+
- GeneralQA-Avg includes datasets with "*" mark.
|
| 79 |
+
|
| 80 |
+
- OCR-Avg includes datasets with "+" mark.
|
| 81 |
+
|
| 82 |
+
## How to Use
|
| 83 |
+
|
| 84 |
+
The basic usage and dynamic crop strategy of SAIL-VL follows InternVL2, you can easily switch Intern-VL series of models to our model. Here is a simple example of using our model:
|
| 85 |
+
|
| 86 |
+
### Requirements:
|
| 87 |
+
```
|
| 88 |
+
pip3 install einops transformers timm
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
### Code:
|
| 92 |
+
|
| 93 |
+
```Python
|
| 94 |
+
import numpy as np
|
| 95 |
+
import torch
|
| 96 |
+
import torchvision.transforms as T
|
| 97 |
+
from PIL import Image
|
| 98 |
+
from torchvision.transforms.functional import InterpolationMode
|
| 99 |
+
from transformers import AutoModel, AutoTokenizer
|
| 100 |
+
|
| 101 |
+
IMAGENET_MEAN = (0.485, 0.456, 0.406)
|
| 102 |
+
IMAGENET_STD = (0.229, 0.224, 0.225)
|
| 103 |
+
|
| 104 |
+
def build_transform(input_size):
|
| 105 |
+
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
|
| 106 |
+
transform = T.Compose([
|
| 107 |
+
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
|
| 108 |
+
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
|
| 109 |
+
T.ToTensor(),
|
| 110 |
+
T.Normalize(mean=MEAN, std=STD)
|
| 111 |
+
])
|
| 112 |
+
return transform
|
| 113 |
+
|
| 114 |
+
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
|
| 115 |
+
best_ratio_diff = float('inf')
|
| 116 |
+
best_ratio = (1, 1)
|
| 117 |
+
area = width * height
|
| 118 |
+
for ratio in target_ratios:
|
| 119 |
+
target_aspect_ratio = ratio[0] / ratio[1]
|
| 120 |
+
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
|
| 121 |
+
if ratio_diff < best_ratio_diff:
|
| 122 |
+
best_ratio_diff = ratio_diff
|
| 123 |
+
best_ratio = ratio
|
| 124 |
+
elif ratio_diff == best_ratio_diff:
|
| 125 |
+
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
|
| 126 |
+
best_ratio = ratio
|
| 127 |
+
return best_ratio
|
| 128 |
+
|
| 129 |
+
def dynamic_preprocess(image, min_num=1, max_num=10, image_size=448, use_thumbnail=False):
|
| 130 |
+
orig_width, orig_height = image.size
|
| 131 |
+
aspect_ratio = orig_width / orig_height
|
| 132 |
+
|
| 133 |
+
# calculate the existing image aspect ratio
|
| 134 |
+
target_ratios = set(
|
| 135 |
+
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
|
| 136 |
+
i * j <= max_num and i * j >= min_num)
|
| 137 |
+
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
|
| 138 |
+
|
| 139 |
+
# find the closest aspect ratio to the target
|
| 140 |
+
target_aspect_ratio = find_closest_aspect_ratio(
|
| 141 |
+
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
|
| 142 |
+
|
| 143 |
+
# calculate the target width and height
|
| 144 |
+
target_width = image_size * target_aspect_ratio[0]
|
| 145 |
+
target_height = image_size * target_aspect_ratio[1]
|
| 146 |
+
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
|
| 147 |
+
|
| 148 |
+
# resize the image
|
| 149 |
+
resized_img = image.resize((target_width, target_height))
|
| 150 |
+
processed_images = []
|
| 151 |
+
for i in range(blocks):
|
| 152 |
+
box = (
|
| 153 |
+
(i % (target_width // image_size)) * image_size,
|
| 154 |
+
(i // (target_width // image_size)) * image_size,
|
| 155 |
+
((i % (target_width // image_size)) + 1) * image_size,
|
| 156 |
+
((i // (target_width // image_size)) + 1) * image_size
|
| 157 |
+
)
|
| 158 |
+
# split the image
|
| 159 |
+
split_img = resized_img.crop(box)
|
| 160 |
+
processed_images.append(split_img)
|
| 161 |
+
assert len(processed_images) == blocks
|
| 162 |
+
if use_thumbnail and len(processed_images) != 1:
|
| 163 |
+
thumbnail_img = image.resize((image_size, image_size))
|
| 164 |
+
processed_images.append(thumbnail_img)
|
| 165 |
+
return processed_images
|
| 166 |
+
|
| 167 |
+
def load_image(image_file, input_size=448, max_num=10):
|
| 168 |
+
image = Image.open(image_file).convert('RGB')
|
| 169 |
+
transform = build_transform(input_size=input_size)
|
| 170 |
+
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
|
| 171 |
+
pixel_values = [transform(image) for image in images]
|
| 172 |
+
pixel_values = torch.stack(pixel_values)
|
| 173 |
+
return pixel_values
|
| 174 |
+
|
| 175 |
+
path = "BytedanceDouyinContent/SAIL-VL-1.5-2B"
|
| 176 |
+
model = AutoModel.from_pretrained(
|
| 177 |
+
path,
|
| 178 |
+
torch_dtype=torch.bfloat16,
|
| 179 |
+
trust_remote_code=True).eval().cuda()
|
| 180 |
+
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
|
| 181 |
+
|
| 182 |
+
# set the max number of tiles in `max_num`
|
| 183 |
+
pixel_values = load_image('./test.png', max_num=10).to(torch.bfloat16).cuda()
|
| 184 |
+
generation_config = dict(max_new_tokens=1024, do_sample=True)
|
| 185 |
+
|
| 186 |
+
# pure-text conversation
|
| 187 |
+
question = 'Hello, who are you?'
|
| 188 |
+
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
|
| 189 |
+
print(f'User: {question} Assistant: {response}')
|
| 190 |
+
|
| 191 |
+
question = 'Can you tell me a story?'
|
| 192 |
+
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
|
| 193 |
+
print(f'User: {question} Assistant: {response}')
|
| 194 |
+
|
| 195 |
+
# single-image single-round conversation
|
| 196 |
+
question = '<image> Please describe the image shortly.'
|
| 197 |
+
response = model.chat(tokenizer, pixel_values, question, generation_config)
|
| 198 |
+
print(f'User: {question} Assistant: {response}')
|
| 199 |
+
|
| 200 |
+
# single-image multi-round conversation
|
| 201 |
+
question = '<image> Please describe the image in detail.'
|
| 202 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
|
| 203 |
+
print(f'User: {question} Assistant: {response}')
|
| 204 |
+
|
| 205 |
+
question = 'Please write a poem according to the image.'
|
| 206 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
|
| 207 |
+
print(f'User: {question} Assistant: {response}')
|
| 208 |
+
```
|
| 209 |
+
<br>
|
| 210 |
+
|
| 211 |
+
## Acknowledge
|
| 212 |
+
|
| 213 |
+
Our model is built upon numerous outstanding open-source projects, and we are grateful for their contributions. We extend special thanks to the InternVL team and Qwen team for their great base models, and to the BAAI team (Infinity-MM) for their generous release of data.
|
| 214 |
+
|
| 215 |
+
## Citation
|
| 216 |
+
```
|
| 217 |
+
@article{dong2025scalable,
|
| 218 |
+
title={Scalable vision language model training via high quality data curation},
|
| 219 |
+
author={Dong, Hongyuan and Kang, Zijian and Yin, Weijie and Liang, Xiao and Feng, Chao and Ran, Jiao},
|
| 220 |
+
journal={arXiv preprint arXiv:2501.05952},
|
| 221 |
+
year={2025}
|
| 222 |
+
}
|
| 223 |
+
```
|
| 224 |
+
```
|
| 225 |
+
@misc{
|
| 226 |
+
sailvl,
|
| 227 |
+
title = {SAIL-VL: Scalable Vision Language Model Training with High Quality Data Curation},
|
| 228 |
+
url = {https://huggingface.co/BytedanceDouyinContent/SAIL-VL-2B/},
|
| 229 |
+
author = {Bytedance Douyin Content Team},
|
| 230 |
+
month = {December},
|
| 231 |
+
year = {2024}
|
| 232 |
+
}
|
| 233 |
+
```
|
| 234 |
+
## Contributions
|
| 235 |
+
This work is conducted by Bytedance Douyin Content Team, authored by:
|
| 236 |
+
```
|
| 237 |
+
{Hongyuan Dong, Zijian Kang, Weijie Yin}, Xiao Liang, Chao Feng, Jiao Ran
|
| 238 |
+
|
| 239 |
+
{*} Equal Contributions.
|
| 240 |
+
```
|
| 241 |
+
We also appreciate the support from the model evaluation team:
|
| 242 |
+
```
|
| 243 |
+
Zirui Guo, Yan Qiu, Yaling Mou, Ming Jiang, Jingwei Sun
|
| 244 |
+
```
|
| 245 |
+
And from AI platform team:
|
| 246 |
+
```
|
| 247 |
+
Huiyu Yu, Lin Dong, Yong Zhang
|
| 248 |
+
```
|
| 249 |
+
|
| 250 |
+
|
| 251 |
+
## License
|
| 252 |
+
|
| 253 |
+
This project is licensed under [Apache License 2.0](LICENSE).
|
| 254 |
+
|
| 255 |
+
## Contact
|
| 256 |
+
|
| 257 |
+
If you have any question, please feel free to contact us: [email protected]
|
added_tokens.json
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</box>": 151673,
|
| 3 |
+
"</img>": 151666,
|
| 4 |
+
"</quad>": 151669,
|
| 5 |
+
"</ref>": 151671,
|
| 6 |
+
"</tool_call>": 151658,
|
| 7 |
+
"<IMG_CONTEXT>": 151667,
|
| 8 |
+
"<box>": 151672,
|
| 9 |
+
"<img>": 151665,
|
| 10 |
+
"<quad>": 151668,
|
| 11 |
+
"<ref>": 151670,
|
| 12 |
+
"<tool_call>": 151657,
|
| 13 |
+
"<|box_end|>": 151649,
|
| 14 |
+
"<|box_start|>": 151648,
|
| 15 |
+
"<|endoftext|>": 151643,
|
| 16 |
+
"<|file_sep|>": 151664,
|
| 17 |
+
"<|fim_middle|>": 151660,
|
| 18 |
+
"<|fim_pad|>": 151662,
|
| 19 |
+
"<|fim_prefix|>": 151659,
|
| 20 |
+
"<|fim_suffix|>": 151661,
|
| 21 |
+
"<|im_end|>": 151645,
|
| 22 |
+
"<|im_start|>": 151644,
|
| 23 |
+
"<|image_pad|>": 151655,
|
| 24 |
+
"<|object_ref_end|>": 151647,
|
| 25 |
+
"<|object_ref_start|>": 151646,
|
| 26 |
+
"<|quad_end|>": 151651,
|
| 27 |
+
"<|quad_start|>": 151650,
|
| 28 |
+
"<|repo_name|>": 151663,
|
| 29 |
+
"<|video_pad|>": 151656,
|
| 30 |
+
"<|vision_end|>": 151653,
|
| 31 |
+
"<|vision_pad|>": 151654,
|
| 32 |
+
"<|vision_start|>": 151652
|
| 33 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,195 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_commit_hash": null,
|
| 3 |
+
"architectures": [
|
| 4 |
+
"SailVLModel"
|
| 5 |
+
],
|
| 6 |
+
"auto_map": {
|
| 7 |
+
"AutoConfig": "configuration_sailvl.SailVLConfig",
|
| 8 |
+
"AutoModel": "modeling_sailvl.SailVLModel",
|
| 9 |
+
"AutoModelForCausalLM": "modeling_sailvl.SailVLModel"
|
| 10 |
+
},
|
| 11 |
+
|
| 12 |
+
"downsample_ratio": 0.5,
|
| 13 |
+
"dynamic_image_size": true,
|
| 14 |
+
"force_image_size": 448,
|
| 15 |
+
"llm_config": {
|
| 16 |
+
"_name_or_path": "/tmp/huggingface_cache/Qwen2.5-7B-Instruct",
|
| 17 |
+
"add_cross_attention": false,
|
| 18 |
+
"architectures": [
|
| 19 |
+
"Qwen2ForCausalLM"
|
| 20 |
+
],
|
| 21 |
+
"attn_implementation": "flash_attention_2",
|
| 22 |
+
"attention_dropout": 0.0,
|
| 23 |
+
"bad_words_ids": null,
|
| 24 |
+
"begin_suppress_tokens": null,
|
| 25 |
+
"bos_token_id": 151643,
|
| 26 |
+
"chunk_size_feed_forward": 0,
|
| 27 |
+
"cross_attention_hidden_size": null,
|
| 28 |
+
"decoder_start_token_id": null,
|
| 29 |
+
"diversity_penalty": 0.0,
|
| 30 |
+
"do_sample": false,
|
| 31 |
+
"early_stopping": false,
|
| 32 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 33 |
+
"eos_token_id": 151645,
|
| 34 |
+
"exponential_decay_length_penalty": null,
|
| 35 |
+
"finetuning_task": null,
|
| 36 |
+
"forced_bos_token_id": null,
|
| 37 |
+
"forced_eos_token_id": null,
|
| 38 |
+
"hidden_act": "silu",
|
| 39 |
+
"hidden_size": 3584,
|
| 40 |
+
"id2label": {
|
| 41 |
+
"0": "LABEL_0",
|
| 42 |
+
"1": "LABEL_1"
|
| 43 |
+
},
|
| 44 |
+
"initializer_range": 0.02,
|
| 45 |
+
"intermediate_size": 18944,
|
| 46 |
+
"is_decoder": false,
|
| 47 |
+
"is_encoder_decoder": false,
|
| 48 |
+
"label2id": {
|
| 49 |
+
"LABEL_0": 0,
|
| 50 |
+
"LABEL_1": 1
|
| 51 |
+
},
|
| 52 |
+
"length_penalty": 1.0,
|
| 53 |
+
"max_length": 20,
|
| 54 |
+
"max_position_embeddings": 32768,
|
| 55 |
+
"max_window_layers": 28,
|
| 56 |
+
"min_length": 0,
|
| 57 |
+
"model_type": "qwen2",
|
| 58 |
+
"no_repeat_ngram_size": 0,
|
| 59 |
+
"num_attention_heads": 28,
|
| 60 |
+
"num_beam_groups": 1,
|
| 61 |
+
"num_beams": 1,
|
| 62 |
+
"num_hidden_layers": 28,
|
| 63 |
+
"num_key_value_heads": 4,
|
| 64 |
+
"num_return_sequences": 1,
|
| 65 |
+
"output_attentions": false,
|
| 66 |
+
"output_hidden_states": false,
|
| 67 |
+
"output_scores": false,
|
| 68 |
+
"pad_token_id": 151643,
|
| 69 |
+
"prefix": null,
|
| 70 |
+
"problem_type": null,
|
| 71 |
+
"pruned_heads": {},
|
| 72 |
+
"remove_invalid_values": false,
|
| 73 |
+
"repetition_penalty": 1.0,
|
| 74 |
+
"return_dict": true,
|
| 75 |
+
"return_dict_in_generate": false,
|
| 76 |
+
"rms_norm_eps": 1e-06,
|
| 77 |
+
"rope_scaling": null,
|
| 78 |
+
"rope_theta": 1000000.0,
|
| 79 |
+
"sep_token_id": null,
|
| 80 |
+
"sliding_window": null,
|
| 81 |
+
"suppress_tokens": null,
|
| 82 |
+
"task_specific_params": null,
|
| 83 |
+
"temperature": 1.0,
|
| 84 |
+
"tf_legacy_loss": false,
|
| 85 |
+
"tie_encoder_decoder": false,
|
| 86 |
+
"tie_word_embeddings": false,
|
| 87 |
+
"tokenizer_class": null,
|
| 88 |
+
"top_k": 50,
|
| 89 |
+
"top_p": 1.0,
|
| 90 |
+
"torch_dtype": "bfloat16",
|
| 91 |
+
"torchscript": false,
|
| 92 |
+
"transformers_version": "4.45.1",
|
| 93 |
+
"typical_p": 1.0,
|
| 94 |
+
"use_bfloat16": false,
|
| 95 |
+
"use_cache": true,
|
| 96 |
+
"use_sliding_window": false,
|
| 97 |
+
"vocab_size": 152064
|
| 98 |
+
},
|
| 99 |
+
"max_dynamic_patch": 12,
|
| 100 |
+
"min_dynamic_patch": 1,
|
| 101 |
+
"model_type": "internvl_chat",
|
| 102 |
+
"pad2square": false,
|
| 103 |
+
"ps_version": "v2",
|
| 104 |
+
"select_layer": -1,
|
| 105 |
+
"template": "sailvl-chat",
|
| 106 |
+
"torch_dtype": "bfloat16",
|
| 107 |
+
"transformers_version": null,
|
| 108 |
+
"use_backbone_lora": 0,
|
| 109 |
+
"use_llm_lora": 0,
|
| 110 |
+
"use_thumbnail": true,
|
| 111 |
+
"vision_config": {
|
| 112 |
+
"_name_or_path": "/tmp/huggingface_cache/ovis-4B-aimv2-ViT-huge-patch14-448",
|
| 113 |
+
"add_cross_attention": false,
|
| 114 |
+
"architectures": [
|
| 115 |
+
"AIMv2Model"
|
| 116 |
+
],
|
| 117 |
+
"attention_dropout": 0.0,
|
| 118 |
+
"auto_map": {
|
| 119 |
+
"AutoConfig": "configuration_aimv2.AIMv2Config",
|
| 120 |
+
"AutoModel": "modeling_aimv2.AIMv2Model",
|
| 121 |
+
"FlaxAutoModel": "modeling_flax_aimv2.FlaxAIMv2Model"
|
| 122 |
+
},
|
| 123 |
+
"bad_words_ids": null,
|
| 124 |
+
"begin_suppress_tokens": null,
|
| 125 |
+
"bos_token_id": null,
|
| 126 |
+
"chunk_size_feed_forward": 0,
|
| 127 |
+
"cross_attention_hidden_size": null,
|
| 128 |
+
"decoder_start_token_id": null,
|
| 129 |
+
"diversity_penalty": 0.0,
|
| 130 |
+
"do_sample": false,
|
| 131 |
+
"early_stopping": false,
|
| 132 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 133 |
+
"eos_token_id": null,
|
| 134 |
+
"exponential_decay_length_penalty": null,
|
| 135 |
+
"finetuning_task": null,
|
| 136 |
+
"forced_bos_token_id": null,
|
| 137 |
+
"forced_eos_token_id": null,
|
| 138 |
+
"hidden_size": 1536,
|
| 139 |
+
"id2label": {
|
| 140 |
+
"0": "LABEL_0",
|
| 141 |
+
"1": "LABEL_1"
|
| 142 |
+
},
|
| 143 |
+
"image_size": 448,
|
| 144 |
+
"intermediate_size": 4096,
|
| 145 |
+
"is_decoder": false,
|
| 146 |
+
"is_encoder_decoder": false,
|
| 147 |
+
"label2id": {
|
| 148 |
+
"LABEL_0": 0,
|
| 149 |
+
"LABEL_1": 1
|
| 150 |
+
},
|
| 151 |
+
"length_penalty": 1.0,
|
| 152 |
+
"max_length": 20,
|
| 153 |
+
"min_length": 0,
|
| 154 |
+
"model_type": "aimv2",
|
| 155 |
+
"no_repeat_ngram_size": 0,
|
| 156 |
+
"num_attention_heads": 12,
|
| 157 |
+
"num_beam_groups": 1,
|
| 158 |
+
"num_beams": 1,
|
| 159 |
+
"num_channels": 3,
|
| 160 |
+
"num_hidden_layers": 24,
|
| 161 |
+
"num_return_sequences": 1,
|
| 162 |
+
"output_attentions": false,
|
| 163 |
+
"output_hidden_states": false,
|
| 164 |
+
"output_scores": false,
|
| 165 |
+
"pad_token_id": null,
|
| 166 |
+
"patch_size": 14,
|
| 167 |
+
"prefix": null,
|
| 168 |
+
"problem_type": null,
|
| 169 |
+
"projection_dropout": 0.0,
|
| 170 |
+
"pruned_heads": {},
|
| 171 |
+
"qkv_bias": false,
|
| 172 |
+
"remove_invalid_values": false,
|
| 173 |
+
"repetition_penalty": 1.0,
|
| 174 |
+
"return_dict": true,
|
| 175 |
+
"return_dict_in_generate": false,
|
| 176 |
+
"rms_norm_eps": 1e-05,
|
| 177 |
+
"sep_token_id": null,
|
| 178 |
+
"suppress_tokens": null,
|
| 179 |
+
"task_specific_params": null,
|
| 180 |
+
"temperature": 1.0,
|
| 181 |
+
"tf_legacy_loss": false,
|
| 182 |
+
"tie_encoder_decoder": false,
|
| 183 |
+
"tie_word_embeddings": true,
|
| 184 |
+
"tokenizer_class": null,
|
| 185 |
+
"top_k": 50,
|
| 186 |
+
"top_p": 1.0,
|
| 187 |
+
"torch_dtype": "bfloat16",
|
| 188 |
+
"torchscript": false,
|
| 189 |
+
"transformers_version": "4.45.1",
|
| 190 |
+
"typical_p": 1.0,
|
| 191 |
+
"use_bfloat16": false,
|
| 192 |
+
"use_bias": false
|
| 193 |
+
}
|
| 194 |
+
}
|
| 195 |
+
|
configuration_aimv2.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# copied from https://huggingface.co/apple/aimv2-huge-patch14-448
|
| 2 |
+
from typing import Any
|
| 3 |
+
|
| 4 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 5 |
+
|
| 6 |
+
__all__ = ["AIMv2Config"]
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class AIMv2Config(PretrainedConfig):
|
| 10 |
+
"""This is the configuration class to store the configuration of an [`AIMv2Model`].
|
| 11 |
+
Instantiating a configuration with the defaults will yield a similar configuration
|
| 12 |
+
to that of the [apple/aimv2-large-patch14-224](https://huggingface.co/apple/aimv2-large-patch14-224).
|
| 13 |
+
Args:
|
| 14 |
+
hidden_size: Dimension of the hidden representations.
|
| 15 |
+
intermediate_size: Dimension of the SwiGLU representations.
|
| 16 |
+
num_hidden_layers: Number of hidden layers in the Transformer.
|
| 17 |
+
num_attention_heads: Number of attention heads for each attention layer
|
| 18 |
+
in the Transformer.
|
| 19 |
+
num_channels: Number of input channels.
|
| 20 |
+
image_size: Image size.
|
| 21 |
+
patch_size: Patch size.
|
| 22 |
+
rms_norm_eps: Epsilon value used for the RMS normalization layer.
|
| 23 |
+
attention_dropout: Dropout ratio for attention probabilities.
|
| 24 |
+
projection_dropout: Dropout ratio for the projection layer after the attention.
|
| 25 |
+
qkv_bias: Whether to add a bias to the queries, keys and values.
|
| 26 |
+
use_bias: Whether to add a bias in the feed-forward and projection layers.
|
| 27 |
+
kwargs: Keyword arguments for the [`PretrainedConfig`].
|
| 28 |
+
"""
|
| 29 |
+
|
| 30 |
+
model_type: str = "aimv2"
|
| 31 |
+
|
| 32 |
+
def __init__(
|
| 33 |
+
self,
|
| 34 |
+
hidden_size: int = 1024,
|
| 35 |
+
intermediate_size: int = 2816,
|
| 36 |
+
num_hidden_layers: int = 24,
|
| 37 |
+
num_attention_heads: int = 8,
|
| 38 |
+
num_channels: int = 3,
|
| 39 |
+
image_size: int = 224,
|
| 40 |
+
patch_size: int = 14,
|
| 41 |
+
rms_norm_eps: float = 1e-5,
|
| 42 |
+
attention_dropout: float = 0.0,
|
| 43 |
+
projection_dropout: float = 0.0,
|
| 44 |
+
qkv_bias: bool = False,
|
| 45 |
+
use_bias: bool = False,
|
| 46 |
+
**kwargs: Any,
|
| 47 |
+
):
|
| 48 |
+
super().__init__(**kwargs)
|
| 49 |
+
self.hidden_size = hidden_size
|
| 50 |
+
self.intermediate_size = intermediate_size
|
| 51 |
+
self.num_hidden_layers = num_hidden_layers
|
| 52 |
+
self.num_attention_heads = num_attention_heads
|
| 53 |
+
self.num_channels = num_channels
|
| 54 |
+
self.patch_size = patch_size
|
| 55 |
+
self.image_size = image_size
|
| 56 |
+
self.attention_dropout = attention_dropout
|
| 57 |
+
self.rms_norm_eps = rms_norm_eps
|
| 58 |
+
|
| 59 |
+
self.projection_dropout = projection_dropout
|
| 60 |
+
self.qkv_bias = qkv_bias
|
| 61 |
+
self.use_bias = use_bias
|
configuration_qwen2.py
ADDED
|
@@ -0,0 +1,204 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# --------------------------------------------------------
|
| 3 |
+
# SailVL
|
| 4 |
+
# Copyright (2024) Bytedance Ltd. and/or its affiliates
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
# --------------------------------------------------------
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
# Copyright 2024 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.
|
| 20 |
+
#
|
| 21 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 22 |
+
# you may not use this file except in compliance with the License.
|
| 23 |
+
# You may obtain a copy of the License at
|
| 24 |
+
#
|
| 25 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 26 |
+
#
|
| 27 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 28 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 29 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 30 |
+
# See the License for the specific language governing permissions and
|
| 31 |
+
# limitations under the License.
|
| 32 |
+
"""Qwen2 model configuration"""
|
| 33 |
+
|
| 34 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 35 |
+
from transformers.modeling_rope_utils import rope_config_validation
|
| 36 |
+
from transformers.utils import logging
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
logger = logging.get_logger(__name__)
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class Qwen2Config(PretrainedConfig):
|
| 43 |
+
r"""
|
| 44 |
+
This is the configuration class to store the configuration of a [`Qwen2Model`]. It is used to instantiate a
|
| 45 |
+
Qwen2 model according to the specified arguments, defining the model architecture. Instantiating a configuration
|
| 46 |
+
with the defaults will yield a similar configuration to that of
|
| 47 |
+
Qwen2-7B-beta [Qwen/Qwen2-7B-beta](https://huggingface.co/Qwen/Qwen2-7B-beta).
|
| 48 |
+
|
| 49 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 50 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
Args:
|
| 54 |
+
vocab_size (`int`, *optional*, defaults to 151936):
|
| 55 |
+
Vocabulary size of the Qwen2 model. Defines the number of different tokens that can be represented by the
|
| 56 |
+
`inputs_ids` passed when calling [`Qwen2Model`]
|
| 57 |
+
hidden_size (`int`, *optional*, defaults to 4096):
|
| 58 |
+
Dimension of the hidden representations.
|
| 59 |
+
intermediate_size (`int`, *optional*, defaults to 22016):
|
| 60 |
+
Dimension of the MLP representations.
|
| 61 |
+
num_hidden_layers (`int`, *optional*, defaults to 32):
|
| 62 |
+
Number of hidden layers in the Transformer encoder.
|
| 63 |
+
num_attention_heads (`int`, *optional*, defaults to 32):
|
| 64 |
+
Number of attention heads for each attention layer in the Transformer encoder.
|
| 65 |
+
num_key_value_heads (`int`, *optional*, defaults to 32):
|
| 66 |
+
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
|
| 67 |
+
`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
|
| 68 |
+
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
|
| 69 |
+
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
|
| 70 |
+
by meanpooling all the original heads within that group. For more details checkout [this
|
| 71 |
+
paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `32`.
|
| 72 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
|
| 73 |
+
The non-linear activation function (function or string) in the decoder.
|
| 74 |
+
max_position_embeddings (`int`, *optional*, defaults to 32768):
|
| 75 |
+
The maximum sequence length that this model might ever be used with.
|
| 76 |
+
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 77 |
+
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
| 78 |
+
rms_norm_eps (`float`, *optional*, defaults to 1e-06):
|
| 79 |
+
The epsilon used by the rms normalization layers.
|
| 80 |
+
use_cache (`bool`, *optional*, defaults to `True`):
|
| 81 |
+
Whether or not the model should return the last key/values attentions (not used by all models). Only
|
| 82 |
+
relevant if `config.is_decoder=True`.
|
| 83 |
+
tie_word_embeddings (`bool`, *optional*, defaults to `False`):
|
| 84 |
+
Whether the model's input and output word embeddings should be tied.
|
| 85 |
+
rope_theta (`float`, *optional*, defaults to 10000.0):
|
| 86 |
+
The base period of the RoPE embeddings.
|
| 87 |
+
rope_scaling (`Dict`, *optional*):
|
| 88 |
+
Dictionary containing the scaling configuration for the RoPE embeddings. NOTE: if you apply new rope type
|
| 89 |
+
and you expect the model to work on longer `max_position_embeddings`, we recommend you to update this value
|
| 90 |
+
accordingly.
|
| 91 |
+
Expected contents:
|
| 92 |
+
`rope_type` (`str`):
|
| 93 |
+
The sub-variant of RoPE to use. Can be one of ['default', 'linear', 'dynamic', 'yarn', 'longrope',
|
| 94 |
+
'llama3'], with 'default' being the original RoPE implementation.
|
| 95 |
+
`factor` (`float`, *optional*):
|
| 96 |
+
Used with all rope types except 'default'. The scaling factor to apply to the RoPE embeddings. In
|
| 97 |
+
most scaling types, a `factor` of x will enable the model to handle sequences of length x *
|
| 98 |
+
original maximum pre-trained length.
|
| 99 |
+
`original_max_position_embeddings` (`int`, *optional*):
|
| 100 |
+
Used with 'dynamic', 'longrope' and 'llama3'. The original max position embeddings used during
|
| 101 |
+
pretraining.
|
| 102 |
+
`attention_factor` (`float`, *optional*):
|
| 103 |
+
Used with 'yarn' and 'longrope'. The scaling factor to be applied on the attention
|
| 104 |
+
computation. If unspecified, it defaults to value recommended by the implementation, using the
|
| 105 |
+
`factor` field to infer the suggested value.
|
| 106 |
+
`beta_fast` (`float`, *optional*):
|
| 107 |
+
Only used with 'yarn'. Parameter to set the boundary for extrapolation (only) in the linear
|
| 108 |
+
ramp function. If unspecified, it defaults to 32.
|
| 109 |
+
`beta_slow` (`float`, *optional*):
|
| 110 |
+
Only used with 'yarn'. Parameter to set the boundary for interpolation (only) in the linear
|
| 111 |
+
ramp function. If unspecified, it defaults to 1.
|
| 112 |
+
`short_factor` (`List[float]`, *optional*):
|
| 113 |
+
Only used with 'longrope'. The scaling factor to be applied to short contexts (<
|
| 114 |
+
`original_max_position_embeddings`). Must be a list of numbers with the same length as the hidden
|
| 115 |
+
size divided by the number of attention heads divided by 2
|
| 116 |
+
`long_factor` (`List[float]`, *optional*):
|
| 117 |
+
Only used with 'longrope'. The scaling factor to be applied to long contexts (<
|
| 118 |
+
`original_max_position_embeddings`). Must be a list of numbers with the same length as the hidden
|
| 119 |
+
size divided by the number of attention heads divided by 2
|
| 120 |
+
`low_freq_factor` (`float`, *optional*):
|
| 121 |
+
Only used with 'llama3'. Scaling factor applied to low frequency components of the RoPE
|
| 122 |
+
`high_freq_factor` (`float`, *optional*):
|
| 123 |
+
Only used with 'llama3'. Scaling factor applied to high frequency components of the RoPE
|
| 124 |
+
use_sliding_window (`bool`, *optional*, defaults to `False`):
|
| 125 |
+
Whether to use sliding window attention.
|
| 126 |
+
sliding_window (`int`, *optional*, defaults to 4096):
|
| 127 |
+
Sliding window attention (SWA) window size. If not specified, will default to `4096`.
|
| 128 |
+
max_window_layers (`int`, *optional*, defaults to 28):
|
| 129 |
+
The number of layers that use SWA (Sliding Window Attention). The bottom layers use SWA while the top use full attention.
|
| 130 |
+
attention_dropout (`float`, *optional*, defaults to 0.0):
|
| 131 |
+
The dropout ratio for the attention probabilities.
|
| 132 |
+
|
| 133 |
+
```python
|
| 134 |
+
>>> from transformers import Qwen2Model, Qwen2Config
|
| 135 |
+
|
| 136 |
+
>>> # Initializing a Qwen2 style configuration
|
| 137 |
+
>>> configuration = Qwen2Config()
|
| 138 |
+
|
| 139 |
+
>>> # Initializing a model from the Qwen2-7B style configuration
|
| 140 |
+
>>> model = Qwen2Model(configuration)
|
| 141 |
+
|
| 142 |
+
>>> # Accessing the model configuration
|
| 143 |
+
>>> configuration = model.config
|
| 144 |
+
```"""
|
| 145 |
+
|
| 146 |
+
model_type = "qwen2"
|
| 147 |
+
keys_to_ignore_at_inference = ["past_key_values"]
|
| 148 |
+
|
| 149 |
+
def __init__(
|
| 150 |
+
self,
|
| 151 |
+
vocab_size=151936,
|
| 152 |
+
hidden_size=4096,
|
| 153 |
+
intermediate_size=22016,
|
| 154 |
+
num_hidden_layers=32,
|
| 155 |
+
num_attention_heads=32,
|
| 156 |
+
num_key_value_heads=32,
|
| 157 |
+
hidden_act="silu",
|
| 158 |
+
max_position_embeddings=32768,
|
| 159 |
+
initializer_range=0.02,
|
| 160 |
+
rms_norm_eps=1e-6,
|
| 161 |
+
use_cache=True,
|
| 162 |
+
tie_word_embeddings=False,
|
| 163 |
+
rope_theta=10000.0,
|
| 164 |
+
rope_scaling=None,
|
| 165 |
+
use_sliding_window=False,
|
| 166 |
+
sliding_window=4096,
|
| 167 |
+
max_window_layers=28,
|
| 168 |
+
attention_dropout=0.0,
|
| 169 |
+
gradient_checkpointing=True,
|
| 170 |
+
**kwargs,
|
| 171 |
+
):
|
| 172 |
+
self.vocab_size = vocab_size
|
| 173 |
+
self.max_position_embeddings = max_position_embeddings
|
| 174 |
+
self.hidden_size = hidden_size
|
| 175 |
+
self.intermediate_size = intermediate_size
|
| 176 |
+
self.num_hidden_layers = num_hidden_layers
|
| 177 |
+
self.num_attention_heads = num_attention_heads
|
| 178 |
+
self.use_sliding_window = use_sliding_window
|
| 179 |
+
self.sliding_window = sliding_window if use_sliding_window else None
|
| 180 |
+
self.max_window_layers = max_window_layers
|
| 181 |
+
self.gradient_checkpointing = gradient_checkpointing
|
| 182 |
+
|
| 183 |
+
# for backward compatibility
|
| 184 |
+
if num_key_value_heads is None:
|
| 185 |
+
num_key_value_heads = num_attention_heads
|
| 186 |
+
|
| 187 |
+
self.num_key_value_heads = num_key_value_heads
|
| 188 |
+
self.hidden_act = hidden_act
|
| 189 |
+
self.initializer_range = initializer_range
|
| 190 |
+
self.rms_norm_eps = rms_norm_eps
|
| 191 |
+
self.use_cache = use_cache
|
| 192 |
+
self.rope_theta = rope_theta
|
| 193 |
+
self.rope_scaling = rope_scaling
|
| 194 |
+
self.attention_dropout = attention_dropout
|
| 195 |
+
# Validate the correctness of rotary position embeddings parameters
|
| 196 |
+
# BC: if there is a 'type' field, move it to 'rope_type'.
|
| 197 |
+
if self.rope_scaling is not None and "type" in self.rope_scaling:
|
| 198 |
+
self.rope_scaling["rope_type"] = self.rope_scaling["type"]
|
| 199 |
+
rope_config_validation(self)
|
| 200 |
+
|
| 201 |
+
super().__init__(
|
| 202 |
+
tie_word_embeddings=tie_word_embeddings,
|
| 203 |
+
**kwargs,
|
| 204 |
+
)
|
configuration_sailvl.py
ADDED
|
@@ -0,0 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# SailVL
|
| 3 |
+
# Copyright (2024) Bytedance Ltd. and/or its affiliates
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
# --------------------------------------------------------
|
| 16 |
+
|
| 17 |
+
import copy
|
| 18 |
+
|
| 19 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 20 |
+
from transformers.utils import logging
|
| 21 |
+
|
| 22 |
+
from .configuration_aimv2 import AIMv2Config
|
| 23 |
+
from .configuration_qwen2 import Qwen2Config
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
logger = logging.get_logger(__name__)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
class SailVLConfig(PretrainedConfig):
|
| 30 |
+
model_type = 'sailvl'
|
| 31 |
+
is_composition = True
|
| 32 |
+
|
| 33 |
+
def __init__(
|
| 34 |
+
self,
|
| 35 |
+
vision_config=None,
|
| 36 |
+
llm_config=None,
|
| 37 |
+
use_backbone_lora=0,
|
| 38 |
+
use_llm_lora=0,
|
| 39 |
+
pad2square=False,
|
| 40 |
+
select_layer=-4,
|
| 41 |
+
force_image_size=None,
|
| 42 |
+
downsample_ratio=0.5,
|
| 43 |
+
template=None,
|
| 44 |
+
dynamic_image_size=False,
|
| 45 |
+
use_thumbnail=False,
|
| 46 |
+
ps_version='v1',
|
| 47 |
+
min_dynamic_patch=1,
|
| 48 |
+
max_dynamic_patch=6,
|
| 49 |
+
**kwargs
|
| 50 |
+
):
|
| 51 |
+
super().__init__(**kwargs)
|
| 52 |
+
|
| 53 |
+
if vision_config is None:
|
| 54 |
+
vision_config = {}
|
| 55 |
+
logger.info(
|
| 56 |
+
'vision_config is None. Initializing the InternVisionConfig with default values.')
|
| 57 |
+
|
| 58 |
+
if llm_config is None:
|
| 59 |
+
llm_config = {'architectures': ['InternLM2ForCausalLM']}
|
| 60 |
+
logger.info(
|
| 61 |
+
'llm_config is None. Initializing the LlamaConfig config with default values (`LlamaConfig`).')
|
| 62 |
+
|
| 63 |
+
self.vision_config = AIMv2Config(**vision_config)
|
| 64 |
+
if llm_config['architectures'][0] == 'Qwen2ForCausalLM':
|
| 65 |
+
self.llm_config = Qwen2Config(**llm_config)
|
| 66 |
+
else:
|
| 67 |
+
raise ValueError('Unsupported architecture: {}'.format(
|
| 68 |
+
llm_config['architectures'][0]))
|
| 69 |
+
|
| 70 |
+
self.use_backbone_lora = use_backbone_lora
|
| 71 |
+
self.use_llm_lora = use_llm_lora
|
| 72 |
+
self.pad2square = pad2square
|
| 73 |
+
self.select_layer = select_layer
|
| 74 |
+
self.force_image_size = force_image_size
|
| 75 |
+
self.downsample_ratio = downsample_ratio
|
| 76 |
+
self.template = template
|
| 77 |
+
self.dynamic_image_size = dynamic_image_size
|
| 78 |
+
self.use_thumbnail = use_thumbnail
|
| 79 |
+
self.ps_version = ps_version # pixel shuffle version
|
| 80 |
+
self.min_dynamic_patch = min_dynamic_patch
|
| 81 |
+
self.max_dynamic_patch = max_dynamic_patch
|
| 82 |
+
|
| 83 |
+
logger.info(f'vision_select_layer: {self.select_layer}')
|
| 84 |
+
logger.info(f'ps_version: {self.ps_version}')
|
| 85 |
+
logger.info(f'min_dynamic_patch: {self.min_dynamic_patch}')
|
| 86 |
+
logger.info(f'max_dynamic_patch: {self.max_dynamic_patch}')
|
| 87 |
+
|
| 88 |
+
def to_dict(self):
|
| 89 |
+
"""
|
| 90 |
+
Serializes this instance to a Python dictionary. Override the default [`~PretrainedConfig.to_dict`].
|
| 91 |
+
|
| 92 |
+
Returns:
|
| 93 |
+
`Dict[str, any]`: Dictionary of all the attributes that make up this configuration instance,
|
| 94 |
+
"""
|
| 95 |
+
output = copy.deepcopy(self.__dict__)
|
| 96 |
+
|
| 97 |
+
output['vision_config'] = self.vision_config.to_dict()
|
| 98 |
+
output['llm_config'] = self.llm_config.to_dict()
|
| 99 |
+
output['model_type'] = self.__class__.model_type
|
| 100 |
+
output['use_backbone_lora'] = self.use_backbone_lora
|
| 101 |
+
output['use_llm_lora'] = self.use_llm_lora
|
| 102 |
+
output['pad2square'] = self.pad2square
|
| 103 |
+
output['select_layer'] = self.select_layer
|
| 104 |
+
output['force_image_size'] = self.force_image_size
|
| 105 |
+
output['downsample_ratio'] = self.downsample_ratio
|
| 106 |
+
output['template'] = self.template
|
| 107 |
+
output['dynamic_image_size'] = self.dynamic_image_size
|
| 108 |
+
output['use_thumbnail'] = self.use_thumbnail
|
| 109 |
+
output['ps_version'] = self.ps_version
|
| 110 |
+
output['min_dynamic_patch'] = self.min_dynamic_patch
|
| 111 |
+
output['max_dynamic_patch'] = self.max_dynamic_patch
|
| 112 |
+
|
| 113 |
+
return output
|
conversation.py
ADDED
|
@@ -0,0 +1,371 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# SailVL
|
| 3 |
+
# Copyright (2024) Bytedance Ltd. and/or its affiliates
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
# --------------------------------------------------------
|
| 16 |
+
|
| 17 |
+
"""
|
| 18 |
+
Conversation prompt templates.
|
| 19 |
+
|
| 20 |
+
We kindly request that you import fastchat instead of copying this file if you wish to use it.
|
| 21 |
+
If you have changes in mind, please contribute back so the community can benefit collectively and continue to maintain these valuable templates.
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
import dataclasses
|
| 25 |
+
from enum import IntEnum, auto
|
| 26 |
+
from typing import Any, Dict, List, Tuple, Union
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
class SeparatorStyle(IntEnum):
|
| 30 |
+
"""Separator styles."""
|
| 31 |
+
|
| 32 |
+
ADD_COLON_SINGLE = auto()
|
| 33 |
+
ADD_COLON_TWO = auto()
|
| 34 |
+
ADD_COLON_SPACE_SINGLE = auto()
|
| 35 |
+
NO_COLON_SINGLE = auto()
|
| 36 |
+
NO_COLON_TWO = auto()
|
| 37 |
+
ADD_NEW_LINE_SINGLE = auto()
|
| 38 |
+
LLAMA2 = auto()
|
| 39 |
+
CHATGLM = auto()
|
| 40 |
+
CHATML = auto()
|
| 41 |
+
CHATINTERN = auto()
|
| 42 |
+
DOLLY = auto()
|
| 43 |
+
RWKV = auto()
|
| 44 |
+
PHOENIX = auto()
|
| 45 |
+
ROBIN = auto()
|
| 46 |
+
FALCON_CHAT = auto()
|
| 47 |
+
CHATGLM3 = auto()
|
| 48 |
+
INTERNVL_ZH = auto()
|
| 49 |
+
MPT = auto()
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
@dataclasses.dataclass
|
| 53 |
+
class Conversation:
|
| 54 |
+
"""A class that manages prompt templates and keeps all conversation history."""
|
| 55 |
+
|
| 56 |
+
# The name of this template
|
| 57 |
+
name: str
|
| 58 |
+
# The template of the system prompt
|
| 59 |
+
system_template: str = '{system_message}'
|
| 60 |
+
# The system message
|
| 61 |
+
system_message: str = ''
|
| 62 |
+
# The names of two roles
|
| 63 |
+
roles: Tuple[str] = ('USER', 'ASSISTANT')
|
| 64 |
+
# All messages. Each item is (role, message).
|
| 65 |
+
messages: List[List[str]] = ()
|
| 66 |
+
# The number of few shot examples
|
| 67 |
+
offset: int = 0
|
| 68 |
+
# The separator style and configurations
|
| 69 |
+
sep_style: SeparatorStyle = SeparatorStyle.ADD_COLON_SINGLE
|
| 70 |
+
sep: str = '\n'
|
| 71 |
+
sep2: str = None
|
| 72 |
+
# Stop criteria (the default one is EOS token)
|
| 73 |
+
stop_str: Union[str, List[str]] = None
|
| 74 |
+
# Stops generation if meeting any token in this list
|
| 75 |
+
stop_token_ids: List[int] = None
|
| 76 |
+
|
| 77 |
+
def get_prompt(self) -> str:
|
| 78 |
+
"""Get the prompt for generation."""
|
| 79 |
+
system_prompt = self.system_template.format(
|
| 80 |
+
system_message=self.system_message)
|
| 81 |
+
if self.sep_style == SeparatorStyle.ADD_COLON_SINGLE:
|
| 82 |
+
ret = system_prompt + self.sep
|
| 83 |
+
for role, message in self.messages:
|
| 84 |
+
if message:
|
| 85 |
+
ret += role + ': ' + message + self.sep
|
| 86 |
+
else:
|
| 87 |
+
ret += role + ':'
|
| 88 |
+
return ret
|
| 89 |
+
elif self.sep_style == SeparatorStyle.ADD_COLON_TWO:
|
| 90 |
+
seps = [self.sep, self.sep2]
|
| 91 |
+
ret = system_prompt + seps[0]
|
| 92 |
+
for i, (role, message) in enumerate(self.messages):
|
| 93 |
+
if message:
|
| 94 |
+
ret += role + ': ' + message + seps[i % 2]
|
| 95 |
+
else:
|
| 96 |
+
ret += role + ':'
|
| 97 |
+
return ret
|
| 98 |
+
elif self.sep_style == SeparatorStyle.ADD_COLON_SPACE_SINGLE:
|
| 99 |
+
ret = system_prompt + self.sep
|
| 100 |
+
for role, message in self.messages:
|
| 101 |
+
if message:
|
| 102 |
+
ret += role + ': ' + message + self.sep
|
| 103 |
+
else:
|
| 104 |
+
ret += role + ': ' # must be end with a space
|
| 105 |
+
return ret
|
| 106 |
+
elif self.sep_style == SeparatorStyle.ADD_NEW_LINE_SINGLE:
|
| 107 |
+
ret = '' if system_prompt == '' else system_prompt + self.sep
|
| 108 |
+
for role, message in self.messages:
|
| 109 |
+
if message:
|
| 110 |
+
ret += role + '\n' + message + self.sep
|
| 111 |
+
else:
|
| 112 |
+
ret += role + '\n'
|
| 113 |
+
return ret
|
| 114 |
+
elif self.sep_style == SeparatorStyle.NO_COLON_SINGLE:
|
| 115 |
+
ret = system_prompt
|
| 116 |
+
for role, message in self.messages:
|
| 117 |
+
if message:
|
| 118 |
+
ret += role + message + self.sep
|
| 119 |
+
else:
|
| 120 |
+
ret += role
|
| 121 |
+
return ret
|
| 122 |
+
elif self.sep_style == SeparatorStyle.NO_COLON_TWO:
|
| 123 |
+
seps = [self.sep, self.sep2]
|
| 124 |
+
ret = system_prompt
|
| 125 |
+
for i, (role, message) in enumerate(self.messages):
|
| 126 |
+
if message:
|
| 127 |
+
ret += role + message + seps[i % 2]
|
| 128 |
+
else:
|
| 129 |
+
ret += role
|
| 130 |
+
return ret
|
| 131 |
+
elif self.sep_style == SeparatorStyle.RWKV:
|
| 132 |
+
ret = system_prompt
|
| 133 |
+
for i, (role, message) in enumerate(self.messages):
|
| 134 |
+
if message:
|
| 135 |
+
ret += (
|
| 136 |
+
role
|
| 137 |
+
+ ': '
|
| 138 |
+
+ message.replace('\r\n', '\n').replace('\n\n', '\n')
|
| 139 |
+
)
|
| 140 |
+
ret += '\n\n'
|
| 141 |
+
else:
|
| 142 |
+
ret += role + ':'
|
| 143 |
+
return ret
|
| 144 |
+
elif self.sep_style == SeparatorStyle.LLAMA2:
|
| 145 |
+
seps = [self.sep, self.sep2]
|
| 146 |
+
if self.system_message:
|
| 147 |
+
ret = system_prompt
|
| 148 |
+
else:
|
| 149 |
+
ret = '[INST] '
|
| 150 |
+
for i, (role, message) in enumerate(self.messages):
|
| 151 |
+
tag = self.roles[i % 2]
|
| 152 |
+
if message:
|
| 153 |
+
if i == 0:
|
| 154 |
+
ret += message + ' '
|
| 155 |
+
else:
|
| 156 |
+
ret += tag + ' ' + message + seps[i % 2]
|
| 157 |
+
else:
|
| 158 |
+
ret += tag
|
| 159 |
+
return ret
|
| 160 |
+
elif self.sep_style == SeparatorStyle.CHATGLM:
|
| 161 |
+
# source: https://huggingface.co/THUDM/chatglm-6b/blob/1d240ba371910e9282298d4592532d7f0f3e9f3e/modeling_chatglm.py#L1302-L1308
|
| 162 |
+
# source2: https://huggingface.co/THUDM/chatglm2-6b/blob/e186c891cf64310ac66ef10a87e6635fa6c2a579/modeling_chatglm.py#L926
|
| 163 |
+
round_add_n = 1 if self.name == 'chatglm2' else 0
|
| 164 |
+
if system_prompt:
|
| 165 |
+
ret = system_prompt + self.sep
|
| 166 |
+
else:
|
| 167 |
+
ret = ''
|
| 168 |
+
|
| 169 |
+
for i, (role, message) in enumerate(self.messages):
|
| 170 |
+
if i % 2 == 0:
|
| 171 |
+
ret += f'[Round {i//2 + round_add_n}]{self.sep}'
|
| 172 |
+
|
| 173 |
+
if message:
|
| 174 |
+
ret += f'{role}:{message}{self.sep}'
|
| 175 |
+
else:
|
| 176 |
+
ret += f'{role}:'
|
| 177 |
+
return ret
|
| 178 |
+
elif self.sep_style == SeparatorStyle.CHATML:
|
| 179 |
+
ret = '' if system_prompt == '' else system_prompt + self.sep + '\n'
|
| 180 |
+
for role, message in self.messages:
|
| 181 |
+
if message:
|
| 182 |
+
ret += role + '\n' + message + self.sep + '\n'
|
| 183 |
+
else:
|
| 184 |
+
ret += role + '\n'
|
| 185 |
+
return ret
|
| 186 |
+
elif self.sep_style == SeparatorStyle.CHATGLM3:
|
| 187 |
+
ret = ''
|
| 188 |
+
if self.system_message:
|
| 189 |
+
ret += system_prompt
|
| 190 |
+
for role, message in self.messages:
|
| 191 |
+
if message:
|
| 192 |
+
ret += role + '\n' + ' ' + message
|
| 193 |
+
else:
|
| 194 |
+
ret += role
|
| 195 |
+
return ret
|
| 196 |
+
elif self.sep_style == SeparatorStyle.CHATINTERN:
|
| 197 |
+
# source: https://huggingface.co/internlm/internlm-chat-7b-8k/blob/bd546fa984b4b0b86958f56bf37f94aa75ab8831/modeling_internlm.py#L771
|
| 198 |
+
seps = [self.sep, self.sep2]
|
| 199 |
+
ret = system_prompt
|
| 200 |
+
for i, (role, message) in enumerate(self.messages):
|
| 201 |
+
# if i % 2 == 0:
|
| 202 |
+
# ret += "<s>"
|
| 203 |
+
if message:
|
| 204 |
+
ret += role + ':' + message + seps[i % 2] + '\n'
|
| 205 |
+
else:
|
| 206 |
+
ret += role + ':'
|
| 207 |
+
return ret
|
| 208 |
+
elif self.sep_style == SeparatorStyle.DOLLY:
|
| 209 |
+
seps = [self.sep, self.sep2]
|
| 210 |
+
ret = system_prompt
|
| 211 |
+
for i, (role, message) in enumerate(self.messages):
|
| 212 |
+
if message:
|
| 213 |
+
ret += role + ':\n' + message + seps[i % 2]
|
| 214 |
+
if i % 2 == 1:
|
| 215 |
+
ret += '\n\n'
|
| 216 |
+
else:
|
| 217 |
+
ret += role + ':\n'
|
| 218 |
+
return ret
|
| 219 |
+
elif self.sep_style == SeparatorStyle.PHOENIX:
|
| 220 |
+
ret = system_prompt
|
| 221 |
+
for role, message in self.messages:
|
| 222 |
+
if message:
|
| 223 |
+
ret += role + ': ' + '<s>' + message + '</s>'
|
| 224 |
+
else:
|
| 225 |
+
ret += role + ': ' + '<s>'
|
| 226 |
+
return ret
|
| 227 |
+
elif self.sep_style == SeparatorStyle.ROBIN:
|
| 228 |
+
ret = system_prompt + self.sep
|
| 229 |
+
for role, message in self.messages:
|
| 230 |
+
if message:
|
| 231 |
+
ret += role + ':\n' + message + self.sep
|
| 232 |
+
else:
|
| 233 |
+
ret += role + ':\n'
|
| 234 |
+
return ret
|
| 235 |
+
elif self.sep_style == SeparatorStyle.FALCON_CHAT:
|
| 236 |
+
ret = ''
|
| 237 |
+
if self.system_message:
|
| 238 |
+
ret += system_prompt + self.sep
|
| 239 |
+
for role, message in self.messages:
|
| 240 |
+
if message:
|
| 241 |
+
ret += role + ': ' + message + self.sep
|
| 242 |
+
else:
|
| 243 |
+
ret += role + ':'
|
| 244 |
+
|
| 245 |
+
return ret
|
| 246 |
+
elif self.sep_style == SeparatorStyle.INTERNVL_ZH:
|
| 247 |
+
seps = [self.sep, self.sep2]
|
| 248 |
+
ret = self.system_message + seps[0]
|
| 249 |
+
for i, (role, message) in enumerate(self.messages):
|
| 250 |
+
if message:
|
| 251 |
+
ret += role + ': ' + message + seps[i % 2]
|
| 252 |
+
else:
|
| 253 |
+
ret += role + ':'
|
| 254 |
+
return ret
|
| 255 |
+
elif self.sep_style == SeparatorStyle.MPT:
|
| 256 |
+
ret = system_prompt + self.sep
|
| 257 |
+
for role, message in self.messages:
|
| 258 |
+
if message:
|
| 259 |
+
if type(message) is tuple:
|
| 260 |
+
message, _, _ = message
|
| 261 |
+
ret += role + message + self.sep
|
| 262 |
+
else:
|
| 263 |
+
ret += role
|
| 264 |
+
return ret
|
| 265 |
+
else:
|
| 266 |
+
raise ValueError(f'Invalid style: {self.sep_style}')
|
| 267 |
+
|
| 268 |
+
def set_system_message(self, system_message: str):
|
| 269 |
+
"""Set the system message."""
|
| 270 |
+
self.system_message = system_message
|
| 271 |
+
|
| 272 |
+
def append_message(self, role: str, message: str):
|
| 273 |
+
"""Append a new message."""
|
| 274 |
+
self.messages.append([role, message])
|
| 275 |
+
|
| 276 |
+
def update_last_message(self, message: str):
|
| 277 |
+
"""Update the last output.
|
| 278 |
+
|
| 279 |
+
The last message is typically set to be None when constructing the prompt,
|
| 280 |
+
so we need to update it in-place after getting the response from a model.
|
| 281 |
+
"""
|
| 282 |
+
self.messages[-1][1] = message
|
| 283 |
+
|
| 284 |
+
def to_gradio_chatbot(self):
|
| 285 |
+
"""Convert the conversation to gradio chatbot format."""
|
| 286 |
+
ret = []
|
| 287 |
+
for i, (role, msg) in enumerate(self.messages[self.offset:]):
|
| 288 |
+
if i % 2 == 0:
|
| 289 |
+
ret.append([msg, None])
|
| 290 |
+
else:
|
| 291 |
+
ret[-1][-1] = msg
|
| 292 |
+
return ret
|
| 293 |
+
|
| 294 |
+
def to_openai_api_messages(self):
|
| 295 |
+
"""Convert the conversation to OpenAI chat completion format."""
|
| 296 |
+
ret = [{'role': 'system', 'content': self.system_message}]
|
| 297 |
+
|
| 298 |
+
for i, (_, msg) in enumerate(self.messages[self.offset:]):
|
| 299 |
+
if i % 2 == 0:
|
| 300 |
+
ret.append({'role': 'user', 'content': msg})
|
| 301 |
+
else:
|
| 302 |
+
if msg is not None:
|
| 303 |
+
ret.append({'role': 'assistant', 'content': msg})
|
| 304 |
+
return ret
|
| 305 |
+
|
| 306 |
+
def copy(self):
|
| 307 |
+
return Conversation(
|
| 308 |
+
name=self.name,
|
| 309 |
+
system_template=self.system_template,
|
| 310 |
+
system_message=self.system_message,
|
| 311 |
+
roles=self.roles,
|
| 312 |
+
messages=[[x, y] for x, y in self.messages],
|
| 313 |
+
offset=self.offset,
|
| 314 |
+
sep_style=self.sep_style,
|
| 315 |
+
sep=self.sep,
|
| 316 |
+
sep2=self.sep2,
|
| 317 |
+
stop_str=self.stop_str,
|
| 318 |
+
stop_token_ids=self.stop_token_ids,
|
| 319 |
+
)
|
| 320 |
+
|
| 321 |
+
def dict(self):
|
| 322 |
+
return {
|
| 323 |
+
'template_name': self.name,
|
| 324 |
+
'system_message': self.system_message,
|
| 325 |
+
'roles': self.roles,
|
| 326 |
+
'messages': self.messages,
|
| 327 |
+
'offset': self.offset,
|
| 328 |
+
}
|
| 329 |
+
|
| 330 |
+
|
| 331 |
+
# A global registry for all conversation templates
|
| 332 |
+
conv_templates: Dict[str, Conversation] = {}
|
| 333 |
+
|
| 334 |
+
|
| 335 |
+
def register_conv_template(template: Conversation, override: bool = False):
|
| 336 |
+
"""Register a new conversation template."""
|
| 337 |
+
if not override:
|
| 338 |
+
assert (
|
| 339 |
+
template.name not in conv_templates
|
| 340 |
+
), f'{template.name} has been registered.'
|
| 341 |
+
|
| 342 |
+
conv_templates[template.name] = template
|
| 343 |
+
|
| 344 |
+
|
| 345 |
+
def get_conv_template(name: str) -> Conversation:
|
| 346 |
+
"""Get a conversation template."""
|
| 347 |
+
return conv_templates[name].copy()
|
| 348 |
+
|
| 349 |
+
|
| 350 |
+
# Both Hermes-2 and internlm2-chat are chatml-format conversation templates. The difference
|
| 351 |
+
# is that during training, the preprocessing function for the Hermes-2 template doesn't add
|
| 352 |
+
# <s> at the beginning of the tokenized sequence, while the internlm2-chat template does.
|
| 353 |
+
# Therefore, they are completely equivalent during inference.
|
| 354 |
+
|
| 355 |
+
register_conv_template(
|
| 356 |
+
Conversation(
|
| 357 |
+
name='sailvl-chat',
|
| 358 |
+
system_template='<|im_start|>system\n{system_message}',
|
| 359 |
+
# note: The new system prompt was not used here to avoid changes in benchmark performance.
|
| 360 |
+
# The internal code name for sailvl is univl, we keep it for consistency.
|
| 361 |
+
system_message='你是由抖音内容理解组开发的多模态大模型,英文名叫UniVL, 是一个有用无害的人工智能助手。',
|
| 362 |
+
roles=('<|im_start|>user\n', '<|im_start|>assistant\n'),
|
| 363 |
+
sep_style=SeparatorStyle.MPT,
|
| 364 |
+
sep='<|im_end|>',
|
| 365 |
+
stop_token_ids=[
|
| 366 |
+
2,
|
| 367 |
+
92543,
|
| 368 |
+
92542
|
| 369 |
+
]
|
| 370 |
+
)
|
| 371 |
+
)
|
generation_config.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"transformers_version": "4.37.2"
|
| 4 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model-00001-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:105deb79e6ce3aa403f0fa2a6eab6b793431887d1c05442d3e5eb2565a8e4d98
|
| 3 |
+
size 4979185704
|
model-00002-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9e95a1aded4ef069cedb7368c3f9cfbe8c8864a11d30f6ba25465a68b924cdf2
|
| 3 |
+
size 4991497784
|
model-00003-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2b4549be68c703a6cd75e63cf5095660c72d24bf470adf00165728f79272a6eb
|
| 3 |
+
size 4932752872
|
model-00004-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0271ad4f17d6ed92190cec750e49dd3a6d334e12694477aa8a48f58955e531a1
|
| 3 |
+
size 1761694376
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,525 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 16665065472
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"language_model.lm_head.weight": "model-00004-of-00004.safetensors",
|
| 7 |
+
"language_model.model.embed_tokens.weight": "model-00001-of-00004.safetensors",
|
| 8 |
+
"language_model.model.layers.0.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 9 |
+
"language_model.model.layers.0.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 10 |
+
"language_model.model.layers.0.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 11 |
+
"language_model.model.layers.0.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 12 |
+
"language_model.model.layers.0.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 13 |
+
"language_model.model.layers.0.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 14 |
+
"language_model.model.layers.0.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 15 |
+
"language_model.model.layers.0.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 16 |
+
"language_model.model.layers.0.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 17 |
+
"language_model.model.layers.0.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 18 |
+
"language_model.model.layers.0.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 19 |
+
"language_model.model.layers.0.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 20 |
+
"language_model.model.layers.1.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 21 |
+
"language_model.model.layers.1.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 22 |
+
"language_model.model.layers.1.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 23 |
+
"language_model.model.layers.1.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 24 |
+
"language_model.model.layers.1.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 25 |
+
"language_model.model.layers.1.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 26 |
+
"language_model.model.layers.1.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 27 |
+
"language_model.model.layers.1.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 28 |
+
"language_model.model.layers.1.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 29 |
+
"language_model.model.layers.1.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 30 |
+
"language_model.model.layers.1.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 31 |
+
"language_model.model.layers.1.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 32 |
+
"language_model.model.layers.10.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 33 |
+
"language_model.model.layers.10.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 34 |
+
"language_model.model.layers.10.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 35 |
+
"language_model.model.layers.10.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 36 |
+
"language_model.model.layers.10.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 37 |
+
"language_model.model.layers.10.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 38 |
+
"language_model.model.layers.10.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 39 |
+
"language_model.model.layers.10.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 40 |
+
"language_model.model.layers.10.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 41 |
+
"language_model.model.layers.10.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 42 |
+
"language_model.model.layers.10.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 43 |
+
"language_model.model.layers.10.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 44 |
+
"language_model.model.layers.11.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 45 |
+
"language_model.model.layers.11.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 46 |
+
"language_model.model.layers.11.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 47 |
+
"language_model.model.layers.11.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 48 |
+
"language_model.model.layers.11.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 49 |
+
"language_model.model.layers.11.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 50 |
+
"language_model.model.layers.11.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 51 |
+
"language_model.model.layers.11.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 52 |
+
"language_model.model.layers.11.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 53 |
+
"language_model.model.layers.11.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 54 |
+
"language_model.model.layers.11.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 55 |
+
"language_model.model.layers.11.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 56 |
+
"language_model.model.layers.12.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 57 |
+
"language_model.model.layers.12.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 58 |
+
"language_model.model.layers.12.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 59 |
+
"language_model.model.layers.12.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 60 |
+
"language_model.model.layers.12.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 61 |
+
"language_model.model.layers.12.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 62 |
+
"language_model.model.layers.12.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 63 |
+
"language_model.model.layers.12.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 64 |
+
"language_model.model.layers.12.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 65 |
+
"language_model.model.layers.12.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 66 |
+
"language_model.model.layers.12.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 67 |
+
"language_model.model.layers.12.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 68 |
+
"language_model.model.layers.13.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 69 |
+
"language_model.model.layers.13.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 70 |
+
"language_model.model.layers.13.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 71 |
+
"language_model.model.layers.13.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 72 |
+
"language_model.model.layers.13.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 73 |
+
"language_model.model.layers.13.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 74 |
+
"language_model.model.layers.13.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 75 |
+
"language_model.model.layers.13.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 76 |
+
"language_model.model.layers.13.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 77 |
+
"language_model.model.layers.13.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 78 |
+
"language_model.model.layers.13.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 79 |
+
"language_model.model.layers.13.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 80 |
+
"language_model.model.layers.14.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 81 |
+
"language_model.model.layers.14.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 82 |
+
"language_model.model.layers.14.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 83 |
+
"language_model.model.layers.14.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 84 |
+
"language_model.model.layers.14.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 85 |
+
"language_model.model.layers.14.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 86 |
+
"language_model.model.layers.14.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 87 |
+
"language_model.model.layers.14.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 88 |
+
"language_model.model.layers.14.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 89 |
+
"language_model.model.layers.14.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 90 |
+
"language_model.model.layers.14.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 91 |
+
"language_model.model.layers.14.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 92 |
+
"language_model.model.layers.15.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 93 |
+
"language_model.model.layers.15.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 94 |
+
"language_model.model.layers.15.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 95 |
+
"language_model.model.layers.15.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 96 |
+
"language_model.model.layers.15.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 97 |
+
"language_model.model.layers.15.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 98 |
+
"language_model.model.layers.15.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 99 |
+
"language_model.model.layers.15.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 100 |
+
"language_model.model.layers.15.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 101 |
+
"language_model.model.layers.15.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 102 |
+
"language_model.model.layers.15.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 103 |
+
"language_model.model.layers.15.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 104 |
+
"language_model.model.layers.16.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 105 |
+
"language_model.model.layers.16.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 106 |
+
"language_model.model.layers.16.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 107 |
+
"language_model.model.layers.16.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 108 |
+
"language_model.model.layers.16.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 109 |
+
"language_model.model.layers.16.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 110 |
+
"language_model.model.layers.16.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 111 |
+
"language_model.model.layers.16.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 112 |
+
"language_model.model.layers.16.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 113 |
+
"language_model.model.layers.16.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 114 |
+
"language_model.model.layers.16.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 115 |
+
"language_model.model.layers.16.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 116 |
+
"language_model.model.layers.17.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 117 |
+
"language_model.model.layers.17.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 118 |
+
"language_model.model.layers.17.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 119 |
+
"language_model.model.layers.17.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 120 |
+
"language_model.model.layers.17.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 121 |
+
"language_model.model.layers.17.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 122 |
+
"language_model.model.layers.17.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 123 |
+
"language_model.model.layers.17.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 124 |
+
"language_model.model.layers.17.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 125 |
+
"language_model.model.layers.17.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 126 |
+
"language_model.model.layers.17.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 127 |
+
"language_model.model.layers.17.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 128 |
+
"language_model.model.layers.18.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 129 |
+
"language_model.model.layers.18.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 130 |
+
"language_model.model.layers.18.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 131 |
+
"language_model.model.layers.18.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 132 |
+
"language_model.model.layers.18.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 133 |
+
"language_model.model.layers.18.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 134 |
+
"language_model.model.layers.18.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 135 |
+
"language_model.model.layers.18.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 136 |
+
"language_model.model.layers.18.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 137 |
+
"language_model.model.layers.18.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 138 |
+
"language_model.model.layers.18.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 139 |
+
"language_model.model.layers.18.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 140 |
+
"language_model.model.layers.19.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 141 |
+
"language_model.model.layers.19.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 142 |
+
"language_model.model.layers.19.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 143 |
+
"language_model.model.layers.19.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 144 |
+
"language_model.model.layers.19.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 145 |
+
"language_model.model.layers.19.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 146 |
+
"language_model.model.layers.19.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 147 |
+
"language_model.model.layers.19.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 148 |
+
"language_model.model.layers.19.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 149 |
+
"language_model.model.layers.19.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 150 |
+
"language_model.model.layers.19.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 151 |
+
"language_model.model.layers.19.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 152 |
+
"language_model.model.layers.2.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 153 |
+
"language_model.model.layers.2.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 154 |
+
"language_model.model.layers.2.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 155 |
+
"language_model.model.layers.2.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 156 |
+
"language_model.model.layers.2.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 157 |
+
"language_model.model.layers.2.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 158 |
+
"language_model.model.layers.2.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 159 |
+
"language_model.model.layers.2.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 160 |
+
"language_model.model.layers.2.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 161 |
+
"language_model.model.layers.2.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 162 |
+
"language_model.model.layers.2.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 163 |
+
"language_model.model.layers.2.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 164 |
+
"language_model.model.layers.20.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 165 |
+
"language_model.model.layers.20.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 166 |
+
"language_model.model.layers.20.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 167 |
+
"language_model.model.layers.20.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 168 |
+
"language_model.model.layers.20.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 169 |
+
"language_model.model.layers.20.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 170 |
+
"language_model.model.layers.20.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 171 |
+
"language_model.model.layers.20.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 172 |
+
"language_model.model.layers.20.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 173 |
+
"language_model.model.layers.20.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 174 |
+
"language_model.model.layers.20.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 175 |
+
"language_model.model.layers.20.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 176 |
+
"language_model.model.layers.21.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 177 |
+
"language_model.model.layers.21.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 178 |
+
"language_model.model.layers.21.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 179 |
+
"language_model.model.layers.21.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 180 |
+
"language_model.model.layers.21.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 181 |
+
"language_model.model.layers.21.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 182 |
+
"language_model.model.layers.21.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 183 |
+
"language_model.model.layers.21.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 184 |
+
"language_model.model.layers.21.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 185 |
+
"language_model.model.layers.21.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 186 |
+
"language_model.model.layers.21.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 187 |
+
"language_model.model.layers.21.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 188 |
+
"language_model.model.layers.22.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 189 |
+
"language_model.model.layers.22.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 190 |
+
"language_model.model.layers.22.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 191 |
+
"language_model.model.layers.22.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 192 |
+
"language_model.model.layers.22.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 193 |
+
"language_model.model.layers.22.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 194 |
+
"language_model.model.layers.22.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 195 |
+
"language_model.model.layers.22.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 196 |
+
"language_model.model.layers.22.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 197 |
+
"language_model.model.layers.22.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 198 |
+
"language_model.model.layers.22.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 199 |
+
"language_model.model.layers.22.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 200 |
+
"language_model.model.layers.23.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 201 |
+
"language_model.model.layers.23.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 202 |
+
"language_model.model.layers.23.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 203 |
+
"language_model.model.layers.23.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 204 |
+
"language_model.model.layers.23.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 205 |
+
"language_model.model.layers.23.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 206 |
+
"language_model.model.layers.23.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 207 |
+
"language_model.model.layers.23.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 208 |
+
"language_model.model.layers.23.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 209 |
+
"language_model.model.layers.23.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 210 |
+
"language_model.model.layers.23.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 211 |
+
"language_model.model.layers.23.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 212 |
+
"language_model.model.layers.24.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 213 |
+
"language_model.model.layers.24.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 214 |
+
"language_model.model.layers.24.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 215 |
+
"language_model.model.layers.24.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 216 |
+
"language_model.model.layers.24.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 217 |
+
"language_model.model.layers.24.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 218 |
+
"language_model.model.layers.24.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 219 |
+
"language_model.model.layers.24.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 220 |
+
"language_model.model.layers.24.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 221 |
+
"language_model.model.layers.24.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 222 |
+
"language_model.model.layers.24.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 223 |
+
"language_model.model.layers.24.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 224 |
+
"language_model.model.layers.25.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 225 |
+
"language_model.model.layers.25.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 226 |
+
"language_model.model.layers.25.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 227 |
+
"language_model.model.layers.25.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 228 |
+
"language_model.model.layers.25.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 229 |
+
"language_model.model.layers.25.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 230 |
+
"language_model.model.layers.25.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 231 |
+
"language_model.model.layers.25.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 232 |
+
"language_model.model.layers.25.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 233 |
+
"language_model.model.layers.25.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 234 |
+
"language_model.model.layers.25.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 235 |
+
"language_model.model.layers.25.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 236 |
+
"language_model.model.layers.26.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 237 |
+
"language_model.model.layers.26.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
| 238 |
+
"language_model.model.layers.26.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 239 |
+
"language_model.model.layers.26.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 240 |
+
"language_model.model.layers.26.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 241 |
+
"language_model.model.layers.26.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
| 242 |
+
"language_model.model.layers.26.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 243 |
+
"language_model.model.layers.26.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 244 |
+
"language_model.model.layers.26.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
| 245 |
+
"language_model.model.layers.26.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 246 |
+
"language_model.model.layers.26.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
| 247 |
+
"language_model.model.layers.26.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 248 |
+
"language_model.model.layers.27.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 249 |
+
"language_model.model.layers.27.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
| 250 |
+
"language_model.model.layers.27.mlp.gate_proj.weight": "model-00004-of-00004.safetensors",
|
| 251 |
+
"language_model.model.layers.27.mlp.up_proj.weight": "model-00004-of-00004.safetensors",
|
| 252 |
+
"language_model.model.layers.27.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 253 |
+
"language_model.model.layers.27.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
| 254 |
+
"language_model.model.layers.27.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 255 |
+
"language_model.model.layers.27.self_attn.o_proj.weight": "model-00004-of-00004.safetensors",
|
| 256 |
+
"language_model.model.layers.27.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
| 257 |
+
"language_model.model.layers.27.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 258 |
+
"language_model.model.layers.27.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
| 259 |
+
"language_model.model.layers.27.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 260 |
+
"language_model.model.layers.3.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 261 |
+
"language_model.model.layers.3.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 262 |
+
"language_model.model.layers.3.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 263 |
+
"language_model.model.layers.3.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 264 |
+
"language_model.model.layers.3.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 265 |
+
"language_model.model.layers.3.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 266 |
+
"language_model.model.layers.3.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 267 |
+
"language_model.model.layers.3.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 268 |
+
"language_model.model.layers.3.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 269 |
+
"language_model.model.layers.3.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 270 |
+
"language_model.model.layers.3.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 271 |
+
"language_model.model.layers.3.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 272 |
+
"language_model.model.layers.4.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 273 |
+
"language_model.model.layers.4.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 274 |
+
"language_model.model.layers.4.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 275 |
+
"language_model.model.layers.4.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 276 |
+
"language_model.model.layers.4.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 277 |
+
"language_model.model.layers.4.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 278 |
+
"language_model.model.layers.4.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 279 |
+
"language_model.model.layers.4.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 280 |
+
"language_model.model.layers.4.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 281 |
+
"language_model.model.layers.4.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 282 |
+
"language_model.model.layers.4.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 283 |
+
"language_model.model.layers.4.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 284 |
+
"language_model.model.layers.5.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 285 |
+
"language_model.model.layers.5.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 286 |
+
"language_model.model.layers.5.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 287 |
+
"language_model.model.layers.5.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 288 |
+
"language_model.model.layers.5.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 289 |
+
"language_model.model.layers.5.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 290 |
+
"language_model.model.layers.5.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 291 |
+
"language_model.model.layers.5.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 292 |
+
"language_model.model.layers.5.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 293 |
+
"language_model.model.layers.5.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 294 |
+
"language_model.model.layers.5.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 295 |
+
"language_model.model.layers.5.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 296 |
+
"language_model.model.layers.6.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 297 |
+
"language_model.model.layers.6.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 298 |
+
"language_model.model.layers.6.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 299 |
+
"language_model.model.layers.6.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 300 |
+
"language_model.model.layers.6.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 301 |
+
"language_model.model.layers.6.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 302 |
+
"language_model.model.layers.6.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 303 |
+
"language_model.model.layers.6.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 304 |
+
"language_model.model.layers.6.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 305 |
+
"language_model.model.layers.6.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 306 |
+
"language_model.model.layers.6.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 307 |
+
"language_model.model.layers.6.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 308 |
+
"language_model.model.layers.7.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 309 |
+
"language_model.model.layers.7.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 310 |
+
"language_model.model.layers.7.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 311 |
+
"language_model.model.layers.7.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 312 |
+
"language_model.model.layers.7.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 313 |
+
"language_model.model.layers.7.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 314 |
+
"language_model.model.layers.7.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 315 |
+
"language_model.model.layers.7.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 316 |
+
"language_model.model.layers.7.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 317 |
+
"language_model.model.layers.7.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 318 |
+
"language_model.model.layers.7.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 319 |
+
"language_model.model.layers.7.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 320 |
+
"language_model.model.layers.8.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 321 |
+
"language_model.model.layers.8.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 322 |
+
"language_model.model.layers.8.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 323 |
+
"language_model.model.layers.8.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 324 |
+
"language_model.model.layers.8.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 325 |
+
"language_model.model.layers.8.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 326 |
+
"language_model.model.layers.8.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 327 |
+
"language_model.model.layers.8.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 328 |
+
"language_model.model.layers.8.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 329 |
+
"language_model.model.layers.8.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 330 |
+
"language_model.model.layers.8.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 331 |
+
"language_model.model.layers.8.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 332 |
+
"language_model.model.layers.9.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 333 |
+
"language_model.model.layers.9.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 334 |
+
"language_model.model.layers.9.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 335 |
+
"language_model.model.layers.9.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 336 |
+
"language_model.model.layers.9.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 337 |
+
"language_model.model.layers.9.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
| 338 |
+
"language_model.model.layers.9.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 339 |
+
"language_model.model.layers.9.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 340 |
+
"language_model.model.layers.9.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
| 341 |
+
"language_model.model.layers.9.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 342 |
+
"language_model.model.layers.9.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
| 343 |
+
"language_model.model.layers.9.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 344 |
+
"language_model.model.norm.weight": "model-00004-of-00004.safetensors",
|
| 345 |
+
"mlp1.0.bias": "model-00004-of-00004.safetensors",
|
| 346 |
+
"mlp1.0.weight": "model-00004-of-00004.safetensors",
|
| 347 |
+
"mlp1.1.bias": "model-00004-of-00004.safetensors",
|
| 348 |
+
"mlp1.1.weight": "model-00004-of-00004.safetensors",
|
| 349 |
+
"mlp1.3.bias": "model-00004-of-00004.safetensors",
|
| 350 |
+
"mlp1.3.weight": "model-00004-of-00004.safetensors",
|
| 351 |
+
"vision_model.preprocessor.patchifier.norm.weight": "model-00001-of-00004.safetensors",
|
| 352 |
+
"vision_model.preprocessor.patchifier.proj.bias": "model-00001-of-00004.safetensors",
|
| 353 |
+
"vision_model.preprocessor.patchifier.proj.weight": "model-00001-of-00004.safetensors",
|
| 354 |
+
"vision_model.preprocessor.pos_embed": "model-00001-of-00004.safetensors",
|
| 355 |
+
"vision_model.trunk.blocks.0.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 356 |
+
"vision_model.trunk.blocks.0.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 357 |
+
"vision_model.trunk.blocks.0.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 358 |
+
"vision_model.trunk.blocks.0.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 359 |
+
"vision_model.trunk.blocks.0.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 360 |
+
"vision_model.trunk.blocks.0.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 361 |
+
"vision_model.trunk.blocks.0.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 362 |
+
"vision_model.trunk.blocks.1.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 363 |
+
"vision_model.trunk.blocks.1.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 364 |
+
"vision_model.trunk.blocks.1.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 365 |
+
"vision_model.trunk.blocks.1.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 366 |
+
"vision_model.trunk.blocks.1.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 367 |
+
"vision_model.trunk.blocks.1.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 368 |
+
"vision_model.trunk.blocks.1.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 369 |
+
"vision_model.trunk.blocks.10.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 370 |
+
"vision_model.trunk.blocks.10.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 371 |
+
"vision_model.trunk.blocks.10.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 372 |
+
"vision_model.trunk.blocks.10.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 373 |
+
"vision_model.trunk.blocks.10.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 374 |
+
"vision_model.trunk.blocks.10.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 375 |
+
"vision_model.trunk.blocks.10.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 376 |
+
"vision_model.trunk.blocks.11.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 377 |
+
"vision_model.trunk.blocks.11.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 378 |
+
"vision_model.trunk.blocks.11.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 379 |
+
"vision_model.trunk.blocks.11.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 380 |
+
"vision_model.trunk.blocks.11.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 381 |
+
"vision_model.trunk.blocks.11.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 382 |
+
"vision_model.trunk.blocks.11.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 383 |
+
"vision_model.trunk.blocks.12.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 384 |
+
"vision_model.trunk.blocks.12.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 385 |
+
"vision_model.trunk.blocks.12.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 386 |
+
"vision_model.trunk.blocks.12.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 387 |
+
"vision_model.trunk.blocks.12.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 388 |
+
"vision_model.trunk.blocks.12.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 389 |
+
"vision_model.trunk.blocks.12.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 390 |
+
"vision_model.trunk.blocks.13.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 391 |
+
"vision_model.trunk.blocks.13.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 392 |
+
"vision_model.trunk.blocks.13.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 393 |
+
"vision_model.trunk.blocks.13.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 394 |
+
"vision_model.trunk.blocks.13.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 395 |
+
"vision_model.trunk.blocks.13.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 396 |
+
"vision_model.trunk.blocks.13.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 397 |
+
"vision_model.trunk.blocks.14.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 398 |
+
"vision_model.trunk.blocks.14.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 399 |
+
"vision_model.trunk.blocks.14.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 400 |
+
"vision_model.trunk.blocks.14.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 401 |
+
"vision_model.trunk.blocks.14.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 402 |
+
"vision_model.trunk.blocks.14.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 403 |
+
"vision_model.trunk.blocks.14.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 404 |
+
"vision_model.trunk.blocks.15.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 405 |
+
"vision_model.trunk.blocks.15.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 406 |
+
"vision_model.trunk.blocks.15.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 407 |
+
"vision_model.trunk.blocks.15.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 408 |
+
"vision_model.trunk.blocks.15.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 409 |
+
"vision_model.trunk.blocks.15.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 410 |
+
"vision_model.trunk.blocks.15.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 411 |
+
"vision_model.trunk.blocks.16.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 412 |
+
"vision_model.trunk.blocks.16.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 413 |
+
"vision_model.trunk.blocks.16.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 414 |
+
"vision_model.trunk.blocks.16.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 415 |
+
"vision_model.trunk.blocks.16.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 416 |
+
"vision_model.trunk.blocks.16.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 417 |
+
"vision_model.trunk.blocks.16.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 418 |
+
"vision_model.trunk.blocks.17.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 419 |
+
"vision_model.trunk.blocks.17.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 420 |
+
"vision_model.trunk.blocks.17.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 421 |
+
"vision_model.trunk.blocks.17.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 422 |
+
"vision_model.trunk.blocks.17.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 423 |
+
"vision_model.trunk.blocks.17.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 424 |
+
"vision_model.trunk.blocks.17.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 425 |
+
"vision_model.trunk.blocks.18.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 426 |
+
"vision_model.trunk.blocks.18.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 427 |
+
"vision_model.trunk.blocks.18.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 428 |
+
"vision_model.trunk.blocks.18.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 429 |
+
"vision_model.trunk.blocks.18.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 430 |
+
"vision_model.trunk.blocks.18.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 431 |
+
"vision_model.trunk.blocks.18.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 432 |
+
"vision_model.trunk.blocks.19.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 433 |
+
"vision_model.trunk.blocks.19.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 434 |
+
"vision_model.trunk.blocks.19.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 435 |
+
"vision_model.trunk.blocks.19.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 436 |
+
"vision_model.trunk.blocks.19.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 437 |
+
"vision_model.trunk.blocks.19.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 438 |
+
"vision_model.trunk.blocks.19.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 439 |
+
"vision_model.trunk.blocks.2.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 440 |
+
"vision_model.trunk.blocks.2.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 441 |
+
"vision_model.trunk.blocks.2.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 442 |
+
"vision_model.trunk.blocks.2.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 443 |
+
"vision_model.trunk.blocks.2.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 444 |
+
"vision_model.trunk.blocks.2.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 445 |
+
"vision_model.trunk.blocks.2.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 446 |
+
"vision_model.trunk.blocks.20.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 447 |
+
"vision_model.trunk.blocks.20.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 448 |
+
"vision_model.trunk.blocks.20.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 449 |
+
"vision_model.trunk.blocks.20.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 450 |
+
"vision_model.trunk.blocks.20.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 451 |
+
"vision_model.trunk.blocks.20.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 452 |
+
"vision_model.trunk.blocks.20.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 453 |
+
"vision_model.trunk.blocks.21.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 454 |
+
"vision_model.trunk.blocks.21.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 455 |
+
"vision_model.trunk.blocks.21.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 456 |
+
"vision_model.trunk.blocks.21.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 457 |
+
"vision_model.trunk.blocks.21.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 458 |
+
"vision_model.trunk.blocks.21.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 459 |
+
"vision_model.trunk.blocks.21.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 460 |
+
"vision_model.trunk.blocks.22.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 461 |
+
"vision_model.trunk.blocks.22.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 462 |
+
"vision_model.trunk.blocks.22.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 463 |
+
"vision_model.trunk.blocks.22.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 464 |
+
"vision_model.trunk.blocks.22.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 465 |
+
"vision_model.trunk.blocks.22.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 466 |
+
"vision_model.trunk.blocks.22.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 467 |
+
"vision_model.trunk.blocks.23.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 468 |
+
"vision_model.trunk.blocks.23.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 469 |
+
"vision_model.trunk.blocks.23.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 470 |
+
"vision_model.trunk.blocks.23.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 471 |
+
"vision_model.trunk.blocks.23.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 472 |
+
"vision_model.trunk.blocks.23.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 473 |
+
"vision_model.trunk.blocks.23.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 474 |
+
"vision_model.trunk.blocks.3.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 475 |
+
"vision_model.trunk.blocks.3.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 476 |
+
"vision_model.trunk.blocks.3.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 477 |
+
"vision_model.trunk.blocks.3.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 478 |
+
"vision_model.trunk.blocks.3.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 479 |
+
"vision_model.trunk.blocks.3.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 480 |
+
"vision_model.trunk.blocks.3.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 481 |
+
"vision_model.trunk.blocks.4.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 482 |
+
"vision_model.trunk.blocks.4.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 483 |
+
"vision_model.trunk.blocks.4.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 484 |
+
"vision_model.trunk.blocks.4.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 485 |
+
"vision_model.trunk.blocks.4.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 486 |
+
"vision_model.trunk.blocks.4.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 487 |
+
"vision_model.trunk.blocks.4.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 488 |
+
"vision_model.trunk.blocks.5.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 489 |
+
"vision_model.trunk.blocks.5.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 490 |
+
"vision_model.trunk.blocks.5.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 491 |
+
"vision_model.trunk.blocks.5.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 492 |
+
"vision_model.trunk.blocks.5.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 493 |
+
"vision_model.trunk.blocks.5.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 494 |
+
"vision_model.trunk.blocks.5.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 495 |
+
"vision_model.trunk.blocks.6.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 496 |
+
"vision_model.trunk.blocks.6.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 497 |
+
"vision_model.trunk.blocks.6.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 498 |
+
"vision_model.trunk.blocks.6.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 499 |
+
"vision_model.trunk.blocks.6.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 500 |
+
"vision_model.trunk.blocks.6.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 501 |
+
"vision_model.trunk.blocks.6.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 502 |
+
"vision_model.trunk.blocks.7.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 503 |
+
"vision_model.trunk.blocks.7.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 504 |
+
"vision_model.trunk.blocks.7.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 505 |
+
"vision_model.trunk.blocks.7.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 506 |
+
"vision_model.trunk.blocks.7.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 507 |
+
"vision_model.trunk.blocks.7.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 508 |
+
"vision_model.trunk.blocks.7.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 509 |
+
"vision_model.trunk.blocks.8.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 510 |
+
"vision_model.trunk.blocks.8.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 511 |
+
"vision_model.trunk.blocks.8.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 512 |
+
"vision_model.trunk.blocks.8.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 513 |
+
"vision_model.trunk.blocks.8.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 514 |
+
"vision_model.trunk.blocks.8.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 515 |
+
"vision_model.trunk.blocks.8.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 516 |
+
"vision_model.trunk.blocks.9.attn.proj.weight": "model-00001-of-00004.safetensors",
|
| 517 |
+
"vision_model.trunk.blocks.9.attn.qkv.weight": "model-00001-of-00004.safetensors",
|
| 518 |
+
"vision_model.trunk.blocks.9.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 519 |
+
"vision_model.trunk.blocks.9.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 520 |
+
"vision_model.trunk.blocks.9.mlp.fc3.weight": "model-00001-of-00004.safetensors",
|
| 521 |
+
"vision_model.trunk.blocks.9.norm_1.weight": "model-00001-of-00004.safetensors",
|
| 522 |
+
"vision_model.trunk.blocks.9.norm_2.weight": "model-00001-of-00004.safetensors",
|
| 523 |
+
"vision_model.trunk.post_trunk_norm.weight": "model-00001-of-00004.safetensors"
|
| 524 |
+
}
|
| 525 |
+
}
|
modeling_aimv2.py
ADDED
|
@@ -0,0 +1,198 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# adapted from https://huggingface.co/apple/aimv2-huge-patch14-448 (modification: add gradient checkpoint support)
|
| 2 |
+
from typing import Optional, Tuple, Union
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from .configuration_aimv2 import AIMv2Config
|
| 6 |
+
from torch import nn
|
| 7 |
+
from torch.nn import functional as F
|
| 8 |
+
from transformers.modeling_outputs import BaseModelOutputWithNoAttention
|
| 9 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 10 |
+
|
| 11 |
+
__all__ = ["AIMv2Model"]
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class RMSNorm(nn.Module):
|
| 15 |
+
def __init__(self, dim: int, eps: float = 1e-6):
|
| 16 |
+
super().__init__()
|
| 17 |
+
self.weight = nn.Parameter(torch.ones(dim))
|
| 18 |
+
self.eps = eps
|
| 19 |
+
|
| 20 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 21 |
+
output = self._norm(x.float()).type_as(x)
|
| 22 |
+
return output * self.weight
|
| 23 |
+
|
| 24 |
+
def extra_repr(self) -> str:
|
| 25 |
+
return f"{tuple(self.weight.shape)}, eps={self.eps}"
|
| 26 |
+
|
| 27 |
+
def _norm(self, x: torch.Tensor) -> torch.Tensor:
|
| 28 |
+
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class AIMv2SwiGLUFFN(nn.Module):
|
| 32 |
+
def __init__(self, config: AIMv2Config):
|
| 33 |
+
super().__init__()
|
| 34 |
+
hidden_features = config.intermediate_size
|
| 35 |
+
in_features = config.hidden_size
|
| 36 |
+
bias = config.use_bias
|
| 37 |
+
|
| 38 |
+
self.fc1 = nn.Linear(in_features, hidden_features, bias=bias)
|
| 39 |
+
self.fc2 = nn.Linear(hidden_features, in_features, bias=bias)
|
| 40 |
+
self.fc3 = nn.Linear(in_features, hidden_features, bias=bias)
|
| 41 |
+
|
| 42 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 43 |
+
x = F.silu(self.fc1(x)) * self.fc3(x)
|
| 44 |
+
x = self.fc2(x)
|
| 45 |
+
return x
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class AIMv2PatchEmbed(nn.Module):
|
| 49 |
+
def __init__(self, config: AIMv2Config):
|
| 50 |
+
super().__init__()
|
| 51 |
+
self.proj = nn.Conv2d(
|
| 52 |
+
config.num_channels,
|
| 53 |
+
config.hidden_size,
|
| 54 |
+
kernel_size=(config.patch_size, config.patch_size),
|
| 55 |
+
stride=(config.patch_size, config.patch_size),
|
| 56 |
+
)
|
| 57 |
+
self.norm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 58 |
+
|
| 59 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 60 |
+
x = self.proj(x).flatten(2).transpose(1, 2)
|
| 61 |
+
x = self.norm(x)
|
| 62 |
+
return x
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
class AIMv2ViTPreprocessor(nn.Module):
|
| 66 |
+
def __init__(self, config: AIMv2Config):
|
| 67 |
+
super().__init__()
|
| 68 |
+
num_patches = (config.image_size // config.patch_size) ** 2
|
| 69 |
+
|
| 70 |
+
self.patchifier = AIMv2PatchEmbed(config)
|
| 71 |
+
self.pos_embed = nn.Parameter(torch.zeros((1, num_patches, config.hidden_size)))
|
| 72 |
+
|
| 73 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 74 |
+
tokens = self.patchifier(x)
|
| 75 |
+
_, N, _ = tokens.shape
|
| 76 |
+
pos_embed = self.pos_embed.to(tokens.device)
|
| 77 |
+
tokens = tokens + pos_embed[:, :N]
|
| 78 |
+
return tokens
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
class AIMv2Attention(nn.Module):
|
| 82 |
+
def __init__(self, config: AIMv2Config):
|
| 83 |
+
super().__init__()
|
| 84 |
+
dim = config.hidden_size
|
| 85 |
+
|
| 86 |
+
self.num_heads = config.num_attention_heads
|
| 87 |
+
self.qkv = nn.Linear(dim, dim * 3, bias=config.qkv_bias)
|
| 88 |
+
self.attn_drop = nn.Dropout(config.attention_dropout)
|
| 89 |
+
self.proj = nn.Linear(dim, dim, bias=config.use_bias)
|
| 90 |
+
self.proj_drop = nn.Dropout(config.projection_dropout)
|
| 91 |
+
|
| 92 |
+
def forward(
|
| 93 |
+
self, x: torch.Tensor, mask: Optional[torch.Tensor] = None
|
| 94 |
+
) -> torch.Tensor:
|
| 95 |
+
B, N, C = x.shape
|
| 96 |
+
qkv = (
|
| 97 |
+
self.qkv(x)
|
| 98 |
+
.reshape(B, N, 3, self.num_heads, C // self.num_heads)
|
| 99 |
+
.permute(2, 0, 3, 1, 4)
|
| 100 |
+
)
|
| 101 |
+
q, k, v = qkv.unbind(0)
|
| 102 |
+
|
| 103 |
+
x = F.scaled_dot_product_attention(q, k, v, attn_mask=mask)
|
| 104 |
+
x = x.transpose(1, 2).contiguous().reshape(B, N, C)
|
| 105 |
+
x = self.proj(x)
|
| 106 |
+
x = self.proj_drop(x)
|
| 107 |
+
return x
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
class AIMv2Block(nn.Module):
|
| 111 |
+
def __init__(self, config: AIMv2Config):
|
| 112 |
+
super().__init__()
|
| 113 |
+
self.attn = AIMv2Attention(config)
|
| 114 |
+
self.norm_1 = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 115 |
+
self.mlp = AIMv2SwiGLUFFN(config)
|
| 116 |
+
self.norm_2 = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 117 |
+
|
| 118 |
+
def forward(
|
| 119 |
+
self, x: torch.Tensor, mask: Optional[torch.Tensor] = None
|
| 120 |
+
) -> torch.Tensor:
|
| 121 |
+
x = x + self.attn(self.norm_1(x), mask)
|
| 122 |
+
x = x + self.mlp(self.norm_2(x))
|
| 123 |
+
return x
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
class AIMv2Transformer(nn.Module):
|
| 127 |
+
def __init__(self, config: AIMv2Config):
|
| 128 |
+
super().__init__()
|
| 129 |
+
self.blocks = nn.ModuleList(
|
| 130 |
+
[AIMv2Block(config) for _ in range(config.num_hidden_layers)]
|
| 131 |
+
)
|
| 132 |
+
self.post_trunk_norm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 133 |
+
self.gradient_checkpointing = False
|
| 134 |
+
|
| 135 |
+
def forward(
|
| 136 |
+
self,
|
| 137 |
+
tokens: torch.Tensor,
|
| 138 |
+
mask: Optional[torch.Tensor] = None,
|
| 139 |
+
output_hidden_states: bool = False,
|
| 140 |
+
) -> Tuple[torch.Tensor, Optional[Tuple[torch.Tensor, ...]]]:
|
| 141 |
+
hidden_states = () if output_hidden_states else None
|
| 142 |
+
for block in self.blocks:
|
| 143 |
+
if self.gradient_checkpointing and self.training:
|
| 144 |
+
tokens = self._gradient_checkpointing_func(block.__call__, tokens, mask)
|
| 145 |
+
else:
|
| 146 |
+
tokens = block(tokens, mask)
|
| 147 |
+
if output_hidden_states:
|
| 148 |
+
hidden_states += (tokens,)
|
| 149 |
+
tokens = self.post_trunk_norm(tokens)
|
| 150 |
+
return tokens, hidden_states
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
class AIMv2PretrainedModel(PreTrainedModel):
|
| 154 |
+
config_class = AIMv2Config
|
| 155 |
+
base_model_prefix = "aimv2"
|
| 156 |
+
supports_gradient_checkpointing = True
|
| 157 |
+
main_input_name = "pixel_values"
|
| 158 |
+
_no_split_modules = ["AIMv2ViTPreprocessor", "AIMv2Block"]
|
| 159 |
+
_supports_sdpa = True
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
class AIMv2Model(AIMv2PretrainedModel):
|
| 163 |
+
def __init__(self, config: AIMv2Config):
|
| 164 |
+
super().__init__(config)
|
| 165 |
+
self.preprocessor = AIMv2ViTPreprocessor(config)
|
| 166 |
+
self.trunk = AIMv2Transformer(config)
|
| 167 |
+
|
| 168 |
+
def forward(
|
| 169 |
+
self,
|
| 170 |
+
pixel_values: torch.Tensor,
|
| 171 |
+
mask: Optional[torch.Tensor] = None,
|
| 172 |
+
output_hidden_states: Optional[bool] = None,
|
| 173 |
+
return_dict: Optional[bool] = None,
|
| 174 |
+
) -> Union[
|
| 175 |
+
Tuple[torch.Tensor],
|
| 176 |
+
Tuple[torch.Tensor, Tuple[torch.Tensor, ...]],
|
| 177 |
+
BaseModelOutputWithNoAttention,
|
| 178 |
+
]:
|
| 179 |
+
if output_hidden_states is None:
|
| 180 |
+
output_hidden_states = self.config.output_hidden_states
|
| 181 |
+
if return_dict is None:
|
| 182 |
+
return_dict = self.config.use_return_dict
|
| 183 |
+
|
| 184 |
+
x = self.preprocessor(pixel_values)
|
| 185 |
+
x, hidden_states = self.trunk(
|
| 186 |
+
x, mask, output_hidden_states=output_hidden_states
|
| 187 |
+
)
|
| 188 |
+
|
| 189 |
+
if not return_dict:
|
| 190 |
+
res = (x,)
|
| 191 |
+
res += (hidden_states,) if output_hidden_states else ()
|
| 192 |
+
return res
|
| 193 |
+
|
| 194 |
+
return BaseModelOutputWithNoAttention(
|
| 195 |
+
last_hidden_state=x,
|
| 196 |
+
hidden_states=hidden_states,
|
| 197 |
+
)
|
| 198 |
+
|
modeling_qwen2.py
ADDED
|
@@ -0,0 +1,1514 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
|
| 3 |
+
# --------------------------------------------------------
|
| 4 |
+
# SailVL
|
| 5 |
+
# Copyright (2024) Bytedance Ltd. and/or its affiliates
|
| 6 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 7 |
+
# you may not use this file except in compliance with the License.
|
| 8 |
+
# You may obtain a copy of the License at
|
| 9 |
+
|
| 10 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 11 |
+
|
| 12 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 13 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 14 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 15 |
+
# See the License for the specific language governing permissions and
|
| 16 |
+
# limitations under the License.
|
| 17 |
+
# --------------------------------------------------------
|
| 18 |
+
|
| 19 |
+
# Copyright 2024 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.
|
| 20 |
+
#
|
| 21 |
+
# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
|
| 22 |
+
# and OPT implementations in this library. It has been modified from its
|
| 23 |
+
# original forms to accommodate minor architectural differences compared
|
| 24 |
+
# to GPT-NeoX and OPT used by the Meta AI team that trained the model.
|
| 25 |
+
#
|
| 26 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 27 |
+
# you may not use this file except in compliance with the License.
|
| 28 |
+
# You may obtain a copy of the License at
|
| 29 |
+
#
|
| 30 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 31 |
+
#
|
| 32 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 33 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 34 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 35 |
+
# See the License for the specific language governing permissions and
|
| 36 |
+
# limitations under the License.
|
| 37 |
+
"""PyTorch Qwen2 model."""
|
| 38 |
+
|
| 39 |
+
import math
|
| 40 |
+
from typing import List, Optional, Tuple, Union
|
| 41 |
+
|
| 42 |
+
import torch
|
| 43 |
+
import torch.utils.checkpoint
|
| 44 |
+
from torch import nn
|
| 45 |
+
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
|
| 46 |
+
|
| 47 |
+
from transformers.activations import ACT2FN
|
| 48 |
+
from transformers.cache_utils import Cache, DynamicCache, StaticCache
|
| 49 |
+
from transformers.generation import GenerationMixin
|
| 50 |
+
from transformers.modeling_attn_mask_utils import AttentionMaskConverter
|
| 51 |
+
from transformers.modeling_outputs import (
|
| 52 |
+
BaseModelOutputWithPast,
|
| 53 |
+
CausalLMOutputWithPast,
|
| 54 |
+
SequenceClassifierOutputWithPast,
|
| 55 |
+
TokenClassifierOutput,
|
| 56 |
+
)
|
| 57 |
+
from transformers.modeling_rope_utils import ROPE_INIT_FUNCTIONS
|
| 58 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 59 |
+
from transformers.utils import (
|
| 60 |
+
add_start_docstrings,
|
| 61 |
+
add_start_docstrings_to_model_forward,
|
| 62 |
+
is_flash_attn_2_available,
|
| 63 |
+
is_flash_attn_greater_or_equal_2_10,
|
| 64 |
+
is_torchdynamo_compiling,
|
| 65 |
+
logging,
|
| 66 |
+
replace_return_docstrings,
|
| 67 |
+
)
|
| 68 |
+
from .configuration_qwen2 import Qwen2Config
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
if is_flash_attn_2_available():
|
| 72 |
+
from transformers.modeling_flash_attention_utils import _flash_attention_forward
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
logger = logging.get_logger(__name__)
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
_CHECKPOINT_FOR_DOC = "Qwen/Qwen2-7B-beta"
|
| 79 |
+
_CONFIG_FOR_DOC = "Qwen2Config"
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
# Copied from transformers.models.llama.modeling_llama._prepare_4d_causal_attention_mask_with_cache_position
|
| 83 |
+
def _prepare_4d_causal_attention_mask_with_cache_position(
|
| 84 |
+
attention_mask: torch.Tensor,
|
| 85 |
+
sequence_length: int,
|
| 86 |
+
target_length: int,
|
| 87 |
+
dtype: torch.dtype,
|
| 88 |
+
device: torch.device,
|
| 89 |
+
min_dtype: float,
|
| 90 |
+
cache_position: torch.Tensor,
|
| 91 |
+
batch_size: int,
|
| 92 |
+
):
|
| 93 |
+
"""
|
| 94 |
+
Creates a causal 4D mask of shape `(batch_size, 1, query_length, key_value_length)` from a 2D mask of shape
|
| 95 |
+
`(batch_size, key_value_length)`, or if the input `attention_mask` is already 4D, do nothing.
|
| 96 |
+
|
| 97 |
+
Args:
|
| 98 |
+
attention_mask (`torch.Tensor`):
|
| 99 |
+
A 2D attention mask of shape `(batch_size, key_value_length)` or a 4D attention mask of shape `(batch_size, 1, query_length, key_value_length)`.
|
| 100 |
+
sequence_length (`int`):
|
| 101 |
+
The sequence length being processed.
|
| 102 |
+
target_length (`int`):
|
| 103 |
+
The target length: when generating with static cache, the mask should be as long as the static cache, to account for the 0 padding, the part of the cache that is not filled yet.
|
| 104 |
+
dtype (`torch.dtype`):
|
| 105 |
+
The dtype to use for the 4D attention mask.
|
| 106 |
+
device (`torch.device`):
|
| 107 |
+
The device to plcae the 4D attention mask on.
|
| 108 |
+
min_dtype (`float`):
|
| 109 |
+
The minimum value representable with the dtype `dtype`.
|
| 110 |
+
cache_position (`torch.Tensor`):
|
| 111 |
+
Indices depicting the position of the input sequence tokens in the sequence.
|
| 112 |
+
batch_size (`torch.Tensor`):
|
| 113 |
+
Batch size.
|
| 114 |
+
"""
|
| 115 |
+
if attention_mask is not None and attention_mask.dim() == 4:
|
| 116 |
+
# In this case we assume that the mask comes already in inverted form and requires no inversion or slicing.
|
| 117 |
+
causal_mask = attention_mask
|
| 118 |
+
else:
|
| 119 |
+
causal_mask = torch.full((sequence_length, target_length), fill_value=min_dtype, dtype=dtype, device=device)
|
| 120 |
+
if sequence_length != 1:
|
| 121 |
+
causal_mask = torch.triu(causal_mask.float(), diagonal=1).bfloat16()
|
| 122 |
+
causal_mask *= torch.arange(target_length, device=device) > cache_position.reshape(-1, 1)
|
| 123 |
+
causal_mask = causal_mask[None, None, :, :].expand(batch_size, 1, -1, -1)
|
| 124 |
+
if attention_mask is not None:
|
| 125 |
+
causal_mask = causal_mask.clone() # copy to contiguous memory for in-place edit
|
| 126 |
+
mask_length = attention_mask.shape[-1]
|
| 127 |
+
padding_mask = causal_mask[:, :, :, :mask_length] + attention_mask[:, None, None, :]
|
| 128 |
+
padding_mask = padding_mask == 0
|
| 129 |
+
causal_mask[:, :, :, :mask_length] = causal_mask[:, :, :, :mask_length].masked_fill(
|
| 130 |
+
padding_mask, min_dtype
|
| 131 |
+
)
|
| 132 |
+
|
| 133 |
+
return causal_mask
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaRMSNorm with Llama->Qwen2
|
| 137 |
+
class Qwen2RMSNorm(nn.Module):
|
| 138 |
+
def __init__(self, hidden_size, eps=1e-6):
|
| 139 |
+
"""
|
| 140 |
+
Qwen2RMSNorm is equivalent to T5LayerNorm
|
| 141 |
+
"""
|
| 142 |
+
super().__init__()
|
| 143 |
+
self.weight = nn.Parameter(torch.ones(hidden_size))
|
| 144 |
+
self.variance_epsilon = eps
|
| 145 |
+
|
| 146 |
+
def forward(self, hidden_states):
|
| 147 |
+
input_dtype = hidden_states.dtype
|
| 148 |
+
hidden_states = hidden_states.to(torch.float32)
|
| 149 |
+
variance = hidden_states.pow(2).mean(-1, keepdim=True)
|
| 150 |
+
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
|
| 151 |
+
return self.weight * hidden_states.to(input_dtype)
|
| 152 |
+
|
| 153 |
+
def extra_repr(self):
|
| 154 |
+
return f"{tuple(self.weight.shape)}, eps={self.variance_epsilon}"
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaRotaryEmbedding with Llama->Qwen2
|
| 158 |
+
class Qwen2RotaryEmbedding(nn.Module):
|
| 159 |
+
def __init__(
|
| 160 |
+
self,
|
| 161 |
+
dim=None,
|
| 162 |
+
max_position_embeddings=2048,
|
| 163 |
+
base=10000,
|
| 164 |
+
device=None,
|
| 165 |
+
scaling_factor=1.0,
|
| 166 |
+
rope_type="default",
|
| 167 |
+
config: Optional[Qwen2Config] = None,
|
| 168 |
+
):
|
| 169 |
+
super().__init__()
|
| 170 |
+
# TODO (joao): remove the `if` below, only used for BC
|
| 171 |
+
self.rope_kwargs = {}
|
| 172 |
+
if config is None:
|
| 173 |
+
logger.warning_once(
|
| 174 |
+
"`Qwen2RotaryEmbedding` can now be fully parameterized by passing the model config through the "
|
| 175 |
+
"`config` argument. All other arguments will be removed in v4.46"
|
| 176 |
+
)
|
| 177 |
+
self.rope_kwargs = {
|
| 178 |
+
"rope_type": rope_type,
|
| 179 |
+
"factor": scaling_factor,
|
| 180 |
+
"dim": dim,
|
| 181 |
+
"base": base,
|
| 182 |
+
"max_position_embeddings": max_position_embeddings,
|
| 183 |
+
}
|
| 184 |
+
self.rope_type = rope_type
|
| 185 |
+
self.max_seq_len_cached = max_position_embeddings
|
| 186 |
+
self.original_max_seq_len = max_position_embeddings
|
| 187 |
+
else:
|
| 188 |
+
# BC: "rope_type" was originally "type"
|
| 189 |
+
if config.rope_scaling is not None:
|
| 190 |
+
self.rope_type = config.rope_scaling.get("rope_type", config.rope_scaling.get("type"))
|
| 191 |
+
else:
|
| 192 |
+
self.rope_type = "default"
|
| 193 |
+
self.max_seq_len_cached = config.max_position_embeddings
|
| 194 |
+
self.original_max_seq_len = config.max_position_embeddings
|
| 195 |
+
|
| 196 |
+
self.config = config
|
| 197 |
+
self.rope_init_fn = ROPE_INIT_FUNCTIONS[self.rope_type]
|
| 198 |
+
|
| 199 |
+
inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device, **self.rope_kwargs)
|
| 200 |
+
self.register_buffer("inv_freq", inv_freq, persistent=False)
|
| 201 |
+
self.original_inv_freq = self.inv_freq
|
| 202 |
+
|
| 203 |
+
def _dynamic_frequency_update(self, position_ids, device):
|
| 204 |
+
"""
|
| 205 |
+
dynamic RoPE layers should recompute `inv_freq` in the following situations:
|
| 206 |
+
1 - growing beyond the cached sequence length (allow scaling)
|
| 207 |
+
2 - the current sequence length is in the original scale (avoid losing precision with small sequences)
|
| 208 |
+
"""
|
| 209 |
+
seq_len = torch.max(position_ids) + 1
|
| 210 |
+
if seq_len > self.max_seq_len_cached: # growth
|
| 211 |
+
inv_freq, self.attention_scaling = self.rope_init_fn(
|
| 212 |
+
self.config, device, seq_len=seq_len, **self.rope_kwargs
|
| 213 |
+
)
|
| 214 |
+
self.register_buffer("inv_freq", inv_freq, persistent=False) # TODO joao: may break with compilation
|
| 215 |
+
self.max_seq_len_cached = seq_len
|
| 216 |
+
|
| 217 |
+
if seq_len < self.original_max_seq_len and self.max_seq_len_cached > self.original_max_seq_len: # reset
|
| 218 |
+
self.register_buffer("inv_freq", self.original_inv_freq, persistent=False)
|
| 219 |
+
self.max_seq_len_cached = self.original_max_seq_len
|
| 220 |
+
|
| 221 |
+
@torch.no_grad()
|
| 222 |
+
def forward(self, x, position_ids):
|
| 223 |
+
if "dynamic" in self.rope_type:
|
| 224 |
+
self._dynamic_frequency_update(position_ids, device=x.device)
|
| 225 |
+
|
| 226 |
+
# Core RoPE block
|
| 227 |
+
inv_freq_expanded = self.inv_freq[None, :, None].float().expand(position_ids.shape[0], -1, 1)
|
| 228 |
+
position_ids_expanded = position_ids[:, None, :].float()
|
| 229 |
+
# Force float32 (see https://github.com/huggingface/transformers/pull/29285)
|
| 230 |
+
device_type = x.device.type
|
| 231 |
+
device_type = device_type if isinstance(device_type, str) and device_type != "mps" else "cpu"
|
| 232 |
+
with torch.autocast(device_type=device_type, enabled=False):
|
| 233 |
+
freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
|
| 234 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 235 |
+
cos = emb.cos()
|
| 236 |
+
sin = emb.sin()
|
| 237 |
+
|
| 238 |
+
# Advanced RoPE types (e.g. yarn) apply a post-processing scaling factor, equivalent to scaling attention
|
| 239 |
+
cos = cos * self.attention_scaling
|
| 240 |
+
sin = sin * self.attention_scaling
|
| 241 |
+
|
| 242 |
+
return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
# Copied from transformers.models.llama.modeling_llama.rotate_half
|
| 246 |
+
def rotate_half(x):
|
| 247 |
+
"""Rotates half the hidden dims of the input."""
|
| 248 |
+
x1 = x[..., : x.shape[-1] // 2]
|
| 249 |
+
x2 = x[..., x.shape[-1] // 2 :]
|
| 250 |
+
return torch.cat((-x2, x1), dim=-1)
|
| 251 |
+
|
| 252 |
+
|
| 253 |
+
# Copied from transformers.models.llama.modeling_llama.apply_rotary_pos_emb
|
| 254 |
+
def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
|
| 255 |
+
"""Applies Rotary Position Embedding to the query and key tensors.
|
| 256 |
+
|
| 257 |
+
Args:
|
| 258 |
+
q (`torch.Tensor`): The query tensor.
|
| 259 |
+
k (`torch.Tensor`): The key tensor.
|
| 260 |
+
cos (`torch.Tensor`): The cosine part of the rotary embedding.
|
| 261 |
+
sin (`torch.Tensor`): The sine part of the rotary embedding.
|
| 262 |
+
position_ids (`torch.Tensor`, *optional*):
|
| 263 |
+
Deprecated and unused.
|
| 264 |
+
unsqueeze_dim (`int`, *optional*, defaults to 1):
|
| 265 |
+
The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
|
| 266 |
+
sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
|
| 267 |
+
that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
|
| 268 |
+
k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
|
| 269 |
+
cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
|
| 270 |
+
the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
|
| 271 |
+
Returns:
|
| 272 |
+
`tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
|
| 273 |
+
"""
|
| 274 |
+
cos = cos.unsqueeze(unsqueeze_dim)
|
| 275 |
+
sin = sin.unsqueeze(unsqueeze_dim)
|
| 276 |
+
q_embed = (q * cos) + (rotate_half(q) * sin)
|
| 277 |
+
k_embed = (k * cos) + (rotate_half(k) * sin)
|
| 278 |
+
return q_embed, k_embed
|
| 279 |
+
|
| 280 |
+
|
| 281 |
+
# Copied from transformers.models.mistral.modeling_mistral.MistralMLP with Mistral->Qwen2
|
| 282 |
+
class Qwen2MLP(nn.Module):
|
| 283 |
+
def __init__(self, config):
|
| 284 |
+
super().__init__()
|
| 285 |
+
self.hidden_size = config.hidden_size
|
| 286 |
+
self.intermediate_size = config.intermediate_size
|
| 287 |
+
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
| 288 |
+
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
| 289 |
+
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
|
| 290 |
+
self.act_fn = ACT2FN[config.hidden_act]
|
| 291 |
+
|
| 292 |
+
def forward(self, hidden_state):
|
| 293 |
+
return self.down_proj(self.act_fn(self.gate_proj(hidden_state)) * self.up_proj(hidden_state))
|
| 294 |
+
|
| 295 |
+
|
| 296 |
+
# Copied from transformers.models.llama.modeling_llama.repeat_kv
|
| 297 |
+
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
|
| 298 |
+
"""
|
| 299 |
+
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
|
| 300 |
+
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
|
| 301 |
+
"""
|
| 302 |
+
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
|
| 303 |
+
if n_rep == 1:
|
| 304 |
+
return hidden_states
|
| 305 |
+
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
|
| 306 |
+
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
|
| 307 |
+
|
| 308 |
+
|
| 309 |
+
class Qwen2Attention(nn.Module):
|
| 310 |
+
"""
|
| 311 |
+
Multi-headed attention from 'Attention Is All You Need' paper. Modified to use sliding window attention: Longformer
|
| 312 |
+
and "Generating Long Sequences with Sparse Transformers".
|
| 313 |
+
"""
|
| 314 |
+
|
| 315 |
+
def __init__(self, config: Qwen2Config, layer_idx: Optional[int] = None):
|
| 316 |
+
super().__init__()
|
| 317 |
+
self.config = config
|
| 318 |
+
self.layer_idx = layer_idx
|
| 319 |
+
if layer_idx is None:
|
| 320 |
+
logger.warning_once(
|
| 321 |
+
f"Instantiating {self.__class__.__name__} without passing `layer_idx` is not recommended and will "
|
| 322 |
+
"to errors during the forward call, if caching is used. Please make sure to provide a `layer_idx` "
|
| 323 |
+
"when creating this class."
|
| 324 |
+
)
|
| 325 |
+
|
| 326 |
+
self.hidden_size = config.hidden_size
|
| 327 |
+
self.num_heads = config.num_attention_heads
|
| 328 |
+
self.head_dim = self.hidden_size // self.num_heads
|
| 329 |
+
self.num_key_value_heads = config.num_key_value_heads
|
| 330 |
+
self.num_key_value_groups = self.num_heads // self.num_key_value_heads
|
| 331 |
+
self.max_position_embeddings = config.max_position_embeddings
|
| 332 |
+
self.rope_theta = config.rope_theta
|
| 333 |
+
self.is_causal = True
|
| 334 |
+
self.attention_dropout = config.attention_dropout
|
| 335 |
+
|
| 336 |
+
if (self.head_dim * self.num_heads) != self.hidden_size:
|
| 337 |
+
raise ValueError(
|
| 338 |
+
f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
|
| 339 |
+
f" and `num_heads`: {self.num_heads})."
|
| 340 |
+
)
|
| 341 |
+
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=True)
|
| 342 |
+
self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=True)
|
| 343 |
+
self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=True)
|
| 344 |
+
self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)
|
| 345 |
+
|
| 346 |
+
self.rotary_emb = Qwen2RotaryEmbedding(config=self.config)
|
| 347 |
+
|
| 348 |
+
def forward(
|
| 349 |
+
self,
|
| 350 |
+
hidden_states: torch.Tensor,
|
| 351 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 352 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 353 |
+
past_key_value: Optional[Cache] = None,
|
| 354 |
+
output_attentions: bool = False,
|
| 355 |
+
use_cache: bool = False,
|
| 356 |
+
cache_position: Optional[torch.LongTensor] = None,
|
| 357 |
+
position_embeddings: Optional[Tuple[torch.Tensor, torch.Tensor]] = None, # will become mandatory in v4.46
|
| 358 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 359 |
+
bsz, q_len, _ = hidden_states.size()
|
| 360 |
+
|
| 361 |
+
query_states = self.q_proj(hidden_states)
|
| 362 |
+
key_states = self.k_proj(hidden_states)
|
| 363 |
+
value_states = self.v_proj(hidden_states)
|
| 364 |
+
|
| 365 |
+
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 366 |
+
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
| 367 |
+
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
| 368 |
+
|
| 369 |
+
if position_embeddings is None:
|
| 370 |
+
logger.warning_once(
|
| 371 |
+
"The attention layers in this model are transitioning from computing the RoPE embeddings internally "
|
| 372 |
+
"through `position_ids` (2D tensor with the indexes of the tokens), to using externally computed "
|
| 373 |
+
"`position_embeddings` (Tuple of tensors, containing cos and sin). In v4.46 `position_ids` will be "
|
| 374 |
+
"removed and `position_embeddings` will be mandatory."
|
| 375 |
+
)
|
| 376 |
+
cos, sin = self.rotary_emb(value_states, position_ids)
|
| 377 |
+
else:
|
| 378 |
+
cos, sin = position_embeddings
|
| 379 |
+
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
|
| 380 |
+
|
| 381 |
+
if past_key_value is not None:
|
| 382 |
+
cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position} # Specific to RoPE models
|
| 383 |
+
key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
|
| 384 |
+
|
| 385 |
+
# repeat k/v heads if n_kv_heads < n_heads
|
| 386 |
+
key_states = repeat_kv(key_states, self.num_key_value_groups)
|
| 387 |
+
value_states = repeat_kv(value_states, self.num_key_value_groups)
|
| 388 |
+
|
| 389 |
+
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
|
| 390 |
+
if attention_mask is not None: # no matter the length, we just slice it
|
| 391 |
+
causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
|
| 392 |
+
attn_weights = attn_weights + causal_mask
|
| 393 |
+
|
| 394 |
+
# upcast attention to fp32
|
| 395 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
|
| 396 |
+
attn_weights = nn.functional.dropout(attn_weights, p=self.attention_dropout, training=self.training)
|
| 397 |
+
attn_output = torch.matmul(attn_weights, value_states)
|
| 398 |
+
|
| 399 |
+
if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
|
| 400 |
+
raise ValueError(
|
| 401 |
+
f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
|
| 402 |
+
f" {attn_output.size()}"
|
| 403 |
+
)
|
| 404 |
+
|
| 405 |
+
attn_output = attn_output.transpose(1, 2).contiguous()
|
| 406 |
+
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
|
| 407 |
+
|
| 408 |
+
attn_output = self.o_proj(attn_output)
|
| 409 |
+
|
| 410 |
+
if not output_attentions:
|
| 411 |
+
attn_weights = None
|
| 412 |
+
|
| 413 |
+
return attn_output, attn_weights, past_key_value
|
| 414 |
+
|
| 415 |
+
|
| 416 |
+
class Qwen2FlashAttention2(Qwen2Attention):
|
| 417 |
+
"""
|
| 418 |
+
Qwen2 flash attention module, following Qwen2 attention module. This module inherits from `Qwen2Attention`
|
| 419 |
+
as the weights of the module stays untouched. The only required change would be on the forward pass
|
| 420 |
+
where it needs to correctly call the public API of flash attention and deal with padding tokens
|
| 421 |
+
in case the input contains any of them. Additionally, for sliding window attention, we apply SWA only to the bottom
|
| 422 |
+
config.max_window_layers layers.
|
| 423 |
+
"""
|
| 424 |
+
|
| 425 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2.__init__
|
| 426 |
+
def __init__(self, *args, **kwargs):
|
| 427 |
+
super().__init__(*args, **kwargs)
|
| 428 |
+
|
| 429 |
+
# TODO: Should be removed once Flash Attention for RoCm is bumped to 2.1.
|
| 430 |
+
# flash_attn<2.1 generates top-left aligned causal mask, while what is needed here is bottom-right alignement, that was made default for flash_attn>=2.1. This attribute is used to handle this difference. Reference: https://github.com/Dao-AILab/flash-attention/releases/tag/v2.1.0.
|
| 431 |
+
# Beware that with flash_attn<2.1, using q_seqlen != k_seqlen (except for the case q_seqlen == 1) produces a wrong mask (top-left).
|
| 432 |
+
self._flash_attn_uses_top_left_mask = not is_flash_attn_greater_or_equal_2_10()
|
| 433 |
+
|
| 434 |
+
def forward(
|
| 435 |
+
self,
|
| 436 |
+
hidden_states: torch.Tensor,
|
| 437 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 438 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 439 |
+
past_key_value: Optional[Cache] = None,
|
| 440 |
+
output_attentions: bool = False,
|
| 441 |
+
use_cache: bool = False,
|
| 442 |
+
cache_position: Optional[torch.LongTensor] = None,
|
| 443 |
+
position_embeddings: Optional[Tuple[torch.Tensor, torch.Tensor]] = None, # will become mandatory in v4.46
|
| 444 |
+
):
|
| 445 |
+
bsz, q_len, _ = hidden_states.size()
|
| 446 |
+
|
| 447 |
+
query_states = self.q_proj(hidden_states)
|
| 448 |
+
key_states = self.k_proj(hidden_states)
|
| 449 |
+
value_states = self.v_proj(hidden_states)
|
| 450 |
+
|
| 451 |
+
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 452 |
+
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
| 453 |
+
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
| 454 |
+
|
| 455 |
+
if position_embeddings is None:
|
| 456 |
+
logger.warning_once(
|
| 457 |
+
"The attention layers in this model are transitioning from computing the RoPE embeddings internally "
|
| 458 |
+
"through `position_ids` (2D tensor with the indexes of the tokens), to using externally computed "
|
| 459 |
+
"`position_embeddings` (Tuple of tensors, containing cos and sin). In v4.46 `position_ids` will be "
|
| 460 |
+
"removed and `position_embeddings` will be mandatory."
|
| 461 |
+
)
|
| 462 |
+
cos, sin = self.rotary_emb(value_states, position_ids)
|
| 463 |
+
else:
|
| 464 |
+
cos, sin = position_embeddings
|
| 465 |
+
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
|
| 466 |
+
|
| 467 |
+
if past_key_value is not None:
|
| 468 |
+
# Activate slicing cache only if the config has a value `sliding_windows` attribute
|
| 469 |
+
cache_has_contents = past_key_value.get_seq_length(self.layer_idx) > 0
|
| 470 |
+
kv_seq_len = key_states.shape[-2] + cache_position[0]
|
| 471 |
+
if (
|
| 472 |
+
getattr(self.config, "sliding_window", None) is not None
|
| 473 |
+
and kv_seq_len > self.config.sliding_window
|
| 474 |
+
and cache_has_contents
|
| 475 |
+
):
|
| 476 |
+
slicing_tokens = 1 - self.config.sliding_window
|
| 477 |
+
|
| 478 |
+
past_key = past_key_value[self.layer_idx][0]
|
| 479 |
+
past_value = past_key_value[self.layer_idx][1]
|
| 480 |
+
|
| 481 |
+
past_key = past_key[:, :, slicing_tokens:, :].contiguous()
|
| 482 |
+
past_value = past_value[:, :, slicing_tokens:, :].contiguous()
|
| 483 |
+
|
| 484 |
+
if past_key.shape[-2] != self.config.sliding_window - 1:
|
| 485 |
+
raise ValueError(
|
| 486 |
+
f"past key must have a shape of (`batch_size, num_heads, self.config.sliding_window-1, head_dim`), got"
|
| 487 |
+
f" {past_key.shape}"
|
| 488 |
+
)
|
| 489 |
+
|
| 490 |
+
if attention_mask is not None:
|
| 491 |
+
attention_mask = attention_mask[:, slicing_tokens:]
|
| 492 |
+
attention_mask = torch.cat([attention_mask, torch.ones_like(attention_mask[:, -1:])], dim=-1)
|
| 493 |
+
|
| 494 |
+
cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position} # Specific to RoPE models
|
| 495 |
+
key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
|
| 496 |
+
|
| 497 |
+
# repeat k/v heads if n_kv_heads < n_heads
|
| 498 |
+
key_states = repeat_kv(key_states, self.num_key_value_groups)
|
| 499 |
+
value_states = repeat_kv(value_states, self.num_key_value_groups)
|
| 500 |
+
dropout_rate = 0.0 if not self.training else self.attention_dropout
|
| 501 |
+
|
| 502 |
+
# In PEFT, usually we cast the layer norms in float32 for training stability reasons
|
| 503 |
+
# therefore the input hidden states gets silently casted in float32. Hence, we need
|
| 504 |
+
# cast them back in float16 just to be sure everything works as expected.
|
| 505 |
+
input_dtype = query_states.dtype
|
| 506 |
+
if input_dtype == torch.float32:
|
| 507 |
+
if torch.is_autocast_enabled():
|
| 508 |
+
target_dtype = torch.get_autocast_gpu_dtype()
|
| 509 |
+
# Handle the case where the model is quantized
|
| 510 |
+
elif hasattr(self.config, "_pre_quantization_dtype"):
|
| 511 |
+
target_dtype = self.config._pre_quantization_dtype
|
| 512 |
+
else:
|
| 513 |
+
target_dtype = self.q_proj.weight.dtype
|
| 514 |
+
|
| 515 |
+
logger.warning_once(
|
| 516 |
+
f"The input hidden states seems to be silently casted in float32, this might be related to"
|
| 517 |
+
f" the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
|
| 518 |
+
f" {target_dtype}."
|
| 519 |
+
)
|
| 520 |
+
|
| 521 |
+
query_states = query_states.to(target_dtype)
|
| 522 |
+
key_states = key_states.to(target_dtype)
|
| 523 |
+
value_states = value_states.to(target_dtype)
|
| 524 |
+
|
| 525 |
+
# Reashape to the expected shape for Flash Attention
|
| 526 |
+
query_states = query_states.transpose(1, 2)
|
| 527 |
+
key_states = key_states.transpose(1, 2)
|
| 528 |
+
value_states = value_states.transpose(1, 2)
|
| 529 |
+
|
| 530 |
+
if (
|
| 531 |
+
self.config.use_sliding_window
|
| 532 |
+
and getattr(self.config, "sliding_window", None) is not None
|
| 533 |
+
and self.layer_idx >= self.config.max_window_layers
|
| 534 |
+
):
|
| 535 |
+
sliding_window = self.config.sliding_window
|
| 536 |
+
else:
|
| 537 |
+
sliding_window = None
|
| 538 |
+
|
| 539 |
+
attn_output = _flash_attention_forward(
|
| 540 |
+
query_states,
|
| 541 |
+
key_states,
|
| 542 |
+
value_states,
|
| 543 |
+
attention_mask,
|
| 544 |
+
q_len,
|
| 545 |
+
position_ids=position_ids,
|
| 546 |
+
dropout=dropout_rate,
|
| 547 |
+
sliding_window=sliding_window,
|
| 548 |
+
is_causal=self.is_causal,
|
| 549 |
+
use_top_left_mask=self._flash_attn_uses_top_left_mask,
|
| 550 |
+
)
|
| 551 |
+
|
| 552 |
+
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size).contiguous()
|
| 553 |
+
attn_output = self.o_proj(attn_output)
|
| 554 |
+
|
| 555 |
+
if not output_attentions:
|
| 556 |
+
attn_weights = None
|
| 557 |
+
|
| 558 |
+
return attn_output, attn_weights, past_key_value
|
| 559 |
+
|
| 560 |
+
|
| 561 |
+
class Qwen2SdpaAttention(Qwen2Attention):
|
| 562 |
+
"""
|
| 563 |
+
Qwen2 attention module using torch.nn.functional.scaled_dot_product_attention. This module inherits from
|
| 564 |
+
`Qwen2Attention` as the weights of the module stays untouched. The only changes are on the forward pass to adapt to
|
| 565 |
+
SDPA API.
|
| 566 |
+
"""
|
| 567 |
+
|
| 568 |
+
# Adapted from Qwen2Attention.forward
|
| 569 |
+
def forward(
|
| 570 |
+
self,
|
| 571 |
+
hidden_states: torch.Tensor,
|
| 572 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 573 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 574 |
+
past_key_value: Optional[Cache] = None,
|
| 575 |
+
output_attentions: bool = False,
|
| 576 |
+
use_cache: bool = False,
|
| 577 |
+
cache_position: Optional[torch.LongTensor] = None,
|
| 578 |
+
position_embeddings: Optional[Tuple[torch.Tensor, torch.Tensor]] = None, # will become mandatory in v4.46
|
| 579 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 580 |
+
if output_attentions:
|
| 581 |
+
# TODO: Improve this warning with e.g. `model.config.attn_implementation = "manual"` once this is implemented.
|
| 582 |
+
logger.warning_once(
|
| 583 |
+
"Qwen2Model is using Qwen2SdpaAttention, but `torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to the manual attention implementation, "
|
| 584 |
+
'but specifying the manual implementation will be required from Transformers version v5.0.0 onwards. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
|
| 585 |
+
)
|
| 586 |
+
return super().forward(
|
| 587 |
+
hidden_states=hidden_states,
|
| 588 |
+
attention_mask=attention_mask,
|
| 589 |
+
position_ids=position_ids,
|
| 590 |
+
past_key_value=past_key_value,
|
| 591 |
+
output_attentions=output_attentions,
|
| 592 |
+
use_cache=use_cache,
|
| 593 |
+
)
|
| 594 |
+
|
| 595 |
+
bsz, q_len, _ = hidden_states.size()
|
| 596 |
+
|
| 597 |
+
query_states = self.q_proj(hidden_states)
|
| 598 |
+
key_states = self.k_proj(hidden_states)
|
| 599 |
+
value_states = self.v_proj(hidden_states)
|
| 600 |
+
|
| 601 |
+
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 602 |
+
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
| 603 |
+
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
| 604 |
+
|
| 605 |
+
if position_embeddings is None:
|
| 606 |
+
logger.warning_once(
|
| 607 |
+
"The attention layers in this model are transitioning from computing the RoPE embeddings internally "
|
| 608 |
+
"through `position_ids` (2D tensor with the indexes of the tokens), to using externally computed "
|
| 609 |
+
"`position_embeddings` (Tuple of tensors, containing cos and sin). In v4.46 `position_ids` will be "
|
| 610 |
+
"removed and `position_embeddings` will be mandatory."
|
| 611 |
+
)
|
| 612 |
+
cos, sin = self.rotary_emb(value_states, position_ids)
|
| 613 |
+
else:
|
| 614 |
+
cos, sin = position_embeddings
|
| 615 |
+
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
|
| 616 |
+
|
| 617 |
+
if past_key_value is not None:
|
| 618 |
+
cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position} # Specific to RoPE models
|
| 619 |
+
key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
|
| 620 |
+
|
| 621 |
+
key_states = repeat_kv(key_states, self.num_key_value_groups)
|
| 622 |
+
value_states = repeat_kv(value_states, self.num_key_value_groups)
|
| 623 |
+
|
| 624 |
+
causal_mask = attention_mask
|
| 625 |
+
if attention_mask is not None: # no matter the length, we just slice it
|
| 626 |
+
causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
|
| 627 |
+
|
| 628 |
+
# SDPA with memory-efficient backend is currently (torch==2.1.2) bugged with non-contiguous inputs with custom attn_mask,
|
| 629 |
+
# Reference: https://github.com/pytorch/pytorch/issues/112577.
|
| 630 |
+
if query_states.device.type == "cuda" and attention_mask is not None:
|
| 631 |
+
query_states = query_states.contiguous()
|
| 632 |
+
key_states = key_states.contiguous()
|
| 633 |
+
value_states = value_states.contiguous()
|
| 634 |
+
|
| 635 |
+
# We dispatch to SDPA's Flash Attention or Efficient kernels via this `is_causal` if statement instead of an inline conditional assignment
|
| 636 |
+
# in SDPA to support both torch.compile's dynamic shapes and full graph options. An inline conditional prevents dynamic shapes from compiling.
|
| 637 |
+
# The q_len > 1 is necessary to match with AttentionMaskConverter.to_causal_4d that does not create a causal mask in case q_len == 1.
|
| 638 |
+
is_causal = True if causal_mask is None and q_len > 1 else False
|
| 639 |
+
|
| 640 |
+
attn_output = torch.nn.functional.scaled_dot_product_attention(
|
| 641 |
+
query_states,
|
| 642 |
+
key_states,
|
| 643 |
+
value_states,
|
| 644 |
+
attn_mask=causal_mask,
|
| 645 |
+
dropout_p=self.attention_dropout if self.training else 0.0,
|
| 646 |
+
is_causal=is_causal,
|
| 647 |
+
)
|
| 648 |
+
|
| 649 |
+
attn_output = attn_output.transpose(1, 2).contiguous()
|
| 650 |
+
attn_output = attn_output.view(bsz, q_len, self.hidden_size)
|
| 651 |
+
|
| 652 |
+
attn_output = self.o_proj(attn_output)
|
| 653 |
+
|
| 654 |
+
return attn_output, None, past_key_value
|
| 655 |
+
|
| 656 |
+
|
| 657 |
+
QWEN2_ATTENTION_CLASSES = {
|
| 658 |
+
"eager": Qwen2Attention,
|
| 659 |
+
"flash_attention_2": Qwen2FlashAttention2,
|
| 660 |
+
"sdpa": Qwen2SdpaAttention,
|
| 661 |
+
}
|
| 662 |
+
|
| 663 |
+
|
| 664 |
+
class Qwen2DecoderLayer(nn.Module):
|
| 665 |
+
def __init__(self, config: Qwen2Config, layer_idx: int):
|
| 666 |
+
super().__init__()
|
| 667 |
+
self.hidden_size = config.hidden_size
|
| 668 |
+
|
| 669 |
+
if config.sliding_window and config._attn_implementation != "flash_attention_2":
|
| 670 |
+
logger.warning_once(
|
| 671 |
+
f"Sliding Window Attention is enabled but not implemented for `{config._attn_implementation}`; "
|
| 672 |
+
"unexpected results may be encountered."
|
| 673 |
+
)
|
| 674 |
+
self.self_attn = QWEN2_ATTENTION_CLASSES[config._attn_implementation](config, layer_idx)
|
| 675 |
+
|
| 676 |
+
self.mlp = Qwen2MLP(config)
|
| 677 |
+
self.input_layernorm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 678 |
+
self.post_attention_layernorm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 679 |
+
|
| 680 |
+
def forward(
|
| 681 |
+
self,
|
| 682 |
+
hidden_states: torch.Tensor,
|
| 683 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 684 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 685 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 686 |
+
output_attentions: Optional[bool] = False,
|
| 687 |
+
use_cache: Optional[bool] = False,
|
| 688 |
+
cache_position: Optional[torch.LongTensor] = None,
|
| 689 |
+
position_embeddings: Optional[Tuple[torch.Tensor, torch.Tensor]] = None, # will become mandatory in v4.46
|
| 690 |
+
**kwargs,
|
| 691 |
+
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
| 692 |
+
"""
|
| 693 |
+
Args:
|
| 694 |
+
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
|
| 695 |
+
attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
|
| 696 |
+
`(batch, sequence_length)` where padding elements are indicated by 0.
|
| 697 |
+
output_attentions (`bool`, *optional*):
|
| 698 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 699 |
+
returned tensors for more detail.
|
| 700 |
+
use_cache (`bool`, *optional*):
|
| 701 |
+
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
|
| 702 |
+
(see `past_key_values`).
|
| 703 |
+
past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
|
| 704 |
+
cache_position (`torch.LongTensor` of shape `(sequence_length)`, *optional*):
|
| 705 |
+
Indices depicting the position of the input sequence tokens in the sequence.
|
| 706 |
+
position_embeddings (`Tuple[torch.FloatTensor, torch.FloatTensor]`, *optional*):
|
| 707 |
+
Tuple containing the cosine and sine positional embeddings of shape `(batch_size, seq_len, head_dim)`,
|
| 708 |
+
with `head_dim` being the embedding dimension of each attention head.
|
| 709 |
+
kwargs (`dict`, *optional*):
|
| 710 |
+
Arbitrary kwargs to be ignored, used for FSDP and other methods that injects code
|
| 711 |
+
into the model
|
| 712 |
+
"""
|
| 713 |
+
|
| 714 |
+
residual = hidden_states
|
| 715 |
+
|
| 716 |
+
hidden_states = self.input_layernorm(hidden_states)
|
| 717 |
+
|
| 718 |
+
# Self Attention
|
| 719 |
+
hidden_states, self_attn_weights, present_key_value = self.self_attn(
|
| 720 |
+
hidden_states=hidden_states,
|
| 721 |
+
attention_mask=attention_mask,
|
| 722 |
+
position_ids=position_ids,
|
| 723 |
+
past_key_value=past_key_value,
|
| 724 |
+
output_attentions=output_attentions,
|
| 725 |
+
use_cache=use_cache,
|
| 726 |
+
cache_position=cache_position,
|
| 727 |
+
position_embeddings=position_embeddings,
|
| 728 |
+
)
|
| 729 |
+
hidden_states = residual + hidden_states
|
| 730 |
+
|
| 731 |
+
# Fully Connected
|
| 732 |
+
residual = hidden_states
|
| 733 |
+
hidden_states = self.post_attention_layernorm(hidden_states)
|
| 734 |
+
hidden_states = self.mlp(hidden_states)
|
| 735 |
+
hidden_states = residual + hidden_states
|
| 736 |
+
|
| 737 |
+
outputs = (hidden_states,)
|
| 738 |
+
|
| 739 |
+
if output_attentions:
|
| 740 |
+
outputs += (self_attn_weights,)
|
| 741 |
+
|
| 742 |
+
if use_cache:
|
| 743 |
+
outputs += (present_key_value,)
|
| 744 |
+
|
| 745 |
+
return outputs
|
| 746 |
+
|
| 747 |
+
|
| 748 |
+
QWEN2_START_DOCSTRING = r"""
|
| 749 |
+
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
|
| 750 |
+
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
|
| 751 |
+
etc.)
|
| 752 |
+
|
| 753 |
+
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
|
| 754 |
+
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
|
| 755 |
+
and behavior.
|
| 756 |
+
|
| 757 |
+
Parameters:
|
| 758 |
+
config ([`Qwen2Config`]):
|
| 759 |
+
Model configuration class with all the parameters of the model. Initializing with a config file does not
|
| 760 |
+
load the weights associated with the model, only the configuration. Check out the
|
| 761 |
+
[`~PreTrainedModel.from_pretrained`] method to load the model weights.
|
| 762 |
+
"""
|
| 763 |
+
|
| 764 |
+
|
| 765 |
+
@add_start_docstrings(
|
| 766 |
+
"The bare Qwen2 Model outputting raw hidden-states without any specific head on top.",
|
| 767 |
+
QWEN2_START_DOCSTRING,
|
| 768 |
+
)
|
| 769 |
+
class Qwen2PreTrainedModel(PreTrainedModel):
|
| 770 |
+
config_class = Qwen2Config
|
| 771 |
+
base_model_prefix = "model"
|
| 772 |
+
supports_gradient_checkpointing = True
|
| 773 |
+
_no_split_modules = ["Qwen2DecoderLayer"]
|
| 774 |
+
_skip_keys_device_placement = "past_key_values"
|
| 775 |
+
_supports_flash_attn_2 = True
|
| 776 |
+
_supports_sdpa = True
|
| 777 |
+
_supports_cache_class = True
|
| 778 |
+
_supports_quantized_cache = True
|
| 779 |
+
_supports_static_cache = True
|
| 780 |
+
|
| 781 |
+
def _init_weights(self, module):
|
| 782 |
+
std = self.config.initializer_range
|
| 783 |
+
if isinstance(module, nn.Linear):
|
| 784 |
+
module.weight.data.normal_(mean=0.0, std=std)
|
| 785 |
+
if module.bias is not None:
|
| 786 |
+
module.bias.data.zero_()
|
| 787 |
+
elif isinstance(module, nn.Embedding):
|
| 788 |
+
module.weight.data.normal_(mean=0.0, std=std)
|
| 789 |
+
if module.padding_idx is not None:
|
| 790 |
+
module.weight.data[module.padding_idx].zero_()
|
| 791 |
+
|
| 792 |
+
|
| 793 |
+
QWEN2_INPUTS_DOCSTRING = r"""
|
| 794 |
+
Args:
|
| 795 |
+
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
|
| 796 |
+
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
|
| 797 |
+
it.
|
| 798 |
+
|
| 799 |
+
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
| 800 |
+
[`PreTrainedTokenizer.__call__`] for details.
|
| 801 |
+
|
| 802 |
+
[What are input IDs?](../glossary#input-ids)
|
| 803 |
+
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 804 |
+
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
| 805 |
+
|
| 806 |
+
- 1 for tokens that are **not masked**,
|
| 807 |
+
- 0 for tokens that are **masked**.
|
| 808 |
+
|
| 809 |
+
[What are attention masks?](../glossary#attention-mask)
|
| 810 |
+
|
| 811 |
+
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
| 812 |
+
[`PreTrainedTokenizer.__call__`] for details.
|
| 813 |
+
|
| 814 |
+
If `past_key_values` is used, optionally only the last `decoder_input_ids` have to be input (see
|
| 815 |
+
`past_key_values`).
|
| 816 |
+
|
| 817 |
+
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
|
| 818 |
+
and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
|
| 819 |
+
information on the default strategy.
|
| 820 |
+
|
| 821 |
+
- 1 indicates the head is **not masked**,
|
| 822 |
+
- 0 indicates the head is **masked**.
|
| 823 |
+
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 824 |
+
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
|
| 825 |
+
config.n_positions - 1]`.
|
| 826 |
+
|
| 827 |
+
[What are position IDs?](../glossary#position-ids)
|
| 828 |
+
past_key_values (`Cache` or `tuple(tuple(torch.FloatTensor))`, *optional*):
|
| 829 |
+
Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
|
| 830 |
+
blocks) that can be used to speed up sequential decoding. This typically consists in the `past_key_values`
|
| 831 |
+
returned by the model at a previous stage of decoding, when `use_cache=True` or `config.use_cache=True`.
|
| 832 |
+
|
| 833 |
+
Two formats are allowed:
|
| 834 |
+
- a [`~cache_utils.Cache`] instance, see our
|
| 835 |
+
[kv cache guide](https://huggingface.co/docs/transformers/en/kv_cache);
|
| 836 |
+
- Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of
|
| 837 |
+
shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`). This is also known as the legacy
|
| 838 |
+
cache format.
|
| 839 |
+
|
| 840 |
+
The model will output the same cache format that is fed as input. If no `past_key_values` are passed, the
|
| 841 |
+
legacy cache format will be returned.
|
| 842 |
+
|
| 843 |
+
If `past_key_values` are used, the user can optionally input only the last `input_ids` (those that don't
|
| 844 |
+
have their past key value states given to this model) of shape `(batch_size, 1)` instead of all `input_ids`
|
| 845 |
+
of shape `(batch_size, sequence_length)`.
|
| 846 |
+
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
|
| 847 |
+
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
|
| 848 |
+
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
|
| 849 |
+
model's internal embedding lookup matrix.
|
| 850 |
+
use_cache (`bool`, *optional*):
|
| 851 |
+
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
|
| 852 |
+
`past_key_values`).
|
| 853 |
+
output_attentions (`bool`, *optional*):
|
| 854 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
| 855 |
+
tensors for more detail.
|
| 856 |
+
output_hidden_states (`bool`, *optional*):
|
| 857 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
| 858 |
+
more detail.
|
| 859 |
+
return_dict (`bool`, *optional*):
|
| 860 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 861 |
+
cache_position (`torch.LongTensor` of shape `(sequence_length)`, *optional*):
|
| 862 |
+
Indices depicting the position of the input sequence tokens in the sequence. Contrarily to `position_ids`,
|
| 863 |
+
this tensor is not affected by padding. It is used to update the cache in the correct position and to infer
|
| 864 |
+
the complete sequence length.
|
| 865 |
+
"""
|
| 866 |
+
|
| 867 |
+
|
| 868 |
+
@add_start_docstrings(
|
| 869 |
+
"The bare Qwen2 Model outputting raw hidden-states without any specific head on top.",
|
| 870 |
+
QWEN2_START_DOCSTRING,
|
| 871 |
+
)
|
| 872 |
+
class Qwen2Model(Qwen2PreTrainedModel):
|
| 873 |
+
"""
|
| 874 |
+
Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`Qwen2DecoderLayer`]
|
| 875 |
+
|
| 876 |
+
Args:
|
| 877 |
+
config: Qwen2Config
|
| 878 |
+
"""
|
| 879 |
+
|
| 880 |
+
def __init__(self, config: Qwen2Config):
|
| 881 |
+
super().__init__(config)
|
| 882 |
+
self.padding_idx = config.pad_token_id
|
| 883 |
+
self.vocab_size = config.vocab_size
|
| 884 |
+
|
| 885 |
+
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
|
| 886 |
+
self.layers = nn.ModuleList(
|
| 887 |
+
[Qwen2DecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
|
| 888 |
+
)
|
| 889 |
+
self._attn_implementation = config._attn_implementation
|
| 890 |
+
self.norm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 891 |
+
self.rotary_emb = Qwen2RotaryEmbedding(config=config)
|
| 892 |
+
|
| 893 |
+
self.gradient_checkpointing = False
|
| 894 |
+
# Initialize weights and apply final processing
|
| 895 |
+
self.post_init()
|
| 896 |
+
|
| 897 |
+
def get_input_embeddings(self):
|
| 898 |
+
return self.embed_tokens
|
| 899 |
+
|
| 900 |
+
def set_input_embeddings(self, value):
|
| 901 |
+
self.embed_tokens = value
|
| 902 |
+
|
| 903 |
+
@add_start_docstrings_to_model_forward(QWEN2_INPUTS_DOCSTRING)
|
| 904 |
+
def forward(
|
| 905 |
+
self,
|
| 906 |
+
input_ids: torch.LongTensor = None,
|
| 907 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 908 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 909 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 910 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 911 |
+
use_cache: Optional[bool] = None,
|
| 912 |
+
output_attentions: Optional[bool] = None,
|
| 913 |
+
output_hidden_states: Optional[bool] = None,
|
| 914 |
+
return_dict: Optional[bool] = None,
|
| 915 |
+
cache_position: Optional[torch.LongTensor] = None,
|
| 916 |
+
) -> Union[Tuple, BaseModelOutputWithPast]:
|
| 917 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 918 |
+
output_hidden_states = (
|
| 919 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 920 |
+
)
|
| 921 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 922 |
+
|
| 923 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 924 |
+
|
| 925 |
+
if (input_ids is None) ^ (inputs_embeds is not None):
|
| 926 |
+
raise ValueError(
|
| 927 |
+
"You cannot specify both input_ids and inputs_embeds at the same time, and must specify either one"
|
| 928 |
+
)
|
| 929 |
+
|
| 930 |
+
if self.gradient_checkpointing and self.training:
|
| 931 |
+
if use_cache:
|
| 932 |
+
logger.warning_once(
|
| 933 |
+
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
| 934 |
+
)
|
| 935 |
+
use_cache = False
|
| 936 |
+
|
| 937 |
+
# kept for BC (non `Cache` `past_key_values` inputs)
|
| 938 |
+
return_legacy_cache = False
|
| 939 |
+
if use_cache and not isinstance(past_key_values, Cache):
|
| 940 |
+
return_legacy_cache = True
|
| 941 |
+
if past_key_values is None:
|
| 942 |
+
past_key_values = DynamicCache()
|
| 943 |
+
else:
|
| 944 |
+
past_key_values = DynamicCache.from_legacy_cache(past_key_values)
|
| 945 |
+
logger.warning_once(
|
| 946 |
+
"We detected that you are passing `past_key_values` as a tuple of tuples. This is deprecated and "
|
| 947 |
+
"will be removed in v4.47. Please convert your cache or use an appropriate `Cache` class "
|
| 948 |
+
"(https://huggingface.co/docs/transformers/kv_cache#legacy-cache-format)"
|
| 949 |
+
)
|
| 950 |
+
|
| 951 |
+
if inputs_embeds is None:
|
| 952 |
+
inputs_embeds = self.embed_tokens(input_ids)
|
| 953 |
+
|
| 954 |
+
if cache_position is None:
|
| 955 |
+
past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
|
| 956 |
+
cache_position = torch.arange(
|
| 957 |
+
past_seen_tokens, past_seen_tokens + inputs_embeds.shape[1], device=inputs_embeds.device
|
| 958 |
+
)
|
| 959 |
+
if position_ids is None:
|
| 960 |
+
position_ids = cache_position.unsqueeze(0)
|
| 961 |
+
|
| 962 |
+
causal_mask = self._update_causal_mask(
|
| 963 |
+
attention_mask, inputs_embeds, cache_position, past_key_values, output_attentions
|
| 964 |
+
)
|
| 965 |
+
|
| 966 |
+
hidden_states = inputs_embeds
|
| 967 |
+
|
| 968 |
+
# create position embeddings to be shared across the decoder layers
|
| 969 |
+
position_embeddings = self.rotary_emb(hidden_states, position_ids)
|
| 970 |
+
|
| 971 |
+
# decoder layers
|
| 972 |
+
all_hidden_states = () if output_hidden_states else None
|
| 973 |
+
all_self_attns = () if output_attentions else None
|
| 974 |
+
next_decoder_cache = None
|
| 975 |
+
|
| 976 |
+
for decoder_layer in self.layers:
|
| 977 |
+
if output_hidden_states:
|
| 978 |
+
all_hidden_states += (hidden_states,)
|
| 979 |
+
|
| 980 |
+
if self.gradient_checkpointing and self.training:
|
| 981 |
+
layer_outputs = self._gradient_checkpointing_func(
|
| 982 |
+
decoder_layer.__call__,
|
| 983 |
+
hidden_states,
|
| 984 |
+
causal_mask,
|
| 985 |
+
position_ids,
|
| 986 |
+
past_key_values,
|
| 987 |
+
output_attentions,
|
| 988 |
+
use_cache,
|
| 989 |
+
cache_position,
|
| 990 |
+
position_embeddings,
|
| 991 |
+
)
|
| 992 |
+
else:
|
| 993 |
+
layer_outputs = decoder_layer(
|
| 994 |
+
hidden_states,
|
| 995 |
+
attention_mask=causal_mask,
|
| 996 |
+
position_ids=position_ids,
|
| 997 |
+
past_key_value=past_key_values,
|
| 998 |
+
output_attentions=output_attentions,
|
| 999 |
+
use_cache=use_cache,
|
| 1000 |
+
cache_position=cache_position,
|
| 1001 |
+
position_embeddings=position_embeddings,
|
| 1002 |
+
)
|
| 1003 |
+
|
| 1004 |
+
hidden_states = layer_outputs[0]
|
| 1005 |
+
|
| 1006 |
+
if use_cache:
|
| 1007 |
+
next_decoder_cache = layer_outputs[2 if output_attentions else 1]
|
| 1008 |
+
|
| 1009 |
+
if output_attentions:
|
| 1010 |
+
all_self_attns += (layer_outputs[1],)
|
| 1011 |
+
|
| 1012 |
+
hidden_states = self.norm(hidden_states)
|
| 1013 |
+
|
| 1014 |
+
# add hidden states from the last decoder layer
|
| 1015 |
+
if output_hidden_states:
|
| 1016 |
+
all_hidden_states += (hidden_states,)
|
| 1017 |
+
|
| 1018 |
+
next_cache = next_decoder_cache if use_cache else None
|
| 1019 |
+
if return_legacy_cache:
|
| 1020 |
+
next_cache = next_cache.to_legacy_cache()
|
| 1021 |
+
|
| 1022 |
+
if not return_dict:
|
| 1023 |
+
return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
|
| 1024 |
+
return BaseModelOutputWithPast(
|
| 1025 |
+
last_hidden_state=hidden_states,
|
| 1026 |
+
past_key_values=next_cache,
|
| 1027 |
+
hidden_states=all_hidden_states,
|
| 1028 |
+
attentions=all_self_attns,
|
| 1029 |
+
)
|
| 1030 |
+
|
| 1031 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaModel._update_causal_mask
|
| 1032 |
+
def _update_causal_mask(
|
| 1033 |
+
self,
|
| 1034 |
+
attention_mask: torch.Tensor,
|
| 1035 |
+
input_tensor: torch.Tensor,
|
| 1036 |
+
cache_position: torch.Tensor,
|
| 1037 |
+
past_key_values: Cache,
|
| 1038 |
+
output_attentions: bool,
|
| 1039 |
+
):
|
| 1040 |
+
if self.config._attn_implementation == "flash_attention_2":
|
| 1041 |
+
if attention_mask is not None and 0.0 in attention_mask:
|
| 1042 |
+
return attention_mask
|
| 1043 |
+
return None
|
| 1044 |
+
|
| 1045 |
+
# For SDPA, when possible, we will rely on its `is_causal` argument instead of its `attn_mask` argument, in
|
| 1046 |
+
# order to dispatch on Flash Attention 2. This feature is not compatible with static cache, as SDPA will fail
|
| 1047 |
+
# to infer the attention mask.
|
| 1048 |
+
past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
|
| 1049 |
+
using_static_cache = isinstance(past_key_values, StaticCache)
|
| 1050 |
+
|
| 1051 |
+
# When output attentions is True, sdpa implementation's forward method calls the eager implementation's forward
|
| 1052 |
+
if self.config._attn_implementation == "sdpa" and not using_static_cache and not output_attentions:
|
| 1053 |
+
if AttentionMaskConverter._ignore_causal_mask_sdpa(
|
| 1054 |
+
attention_mask,
|
| 1055 |
+
inputs_embeds=input_tensor,
|
| 1056 |
+
past_key_values_length=past_seen_tokens,
|
| 1057 |
+
is_training=self.training,
|
| 1058 |
+
):
|
| 1059 |
+
return None
|
| 1060 |
+
|
| 1061 |
+
dtype, device = input_tensor.dtype, input_tensor.device
|
| 1062 |
+
min_dtype = torch.finfo(dtype).min
|
| 1063 |
+
sequence_length = input_tensor.shape[1]
|
| 1064 |
+
if using_static_cache:
|
| 1065 |
+
target_length = past_key_values.get_max_length()
|
| 1066 |
+
else:
|
| 1067 |
+
target_length = (
|
| 1068 |
+
attention_mask.shape[-1]
|
| 1069 |
+
if isinstance(attention_mask, torch.Tensor)
|
| 1070 |
+
else past_seen_tokens + sequence_length + 1
|
| 1071 |
+
)
|
| 1072 |
+
|
| 1073 |
+
# In case the provided `attention` mask is 2D, we generate a causal mask here (4D).
|
| 1074 |
+
causal_mask = _prepare_4d_causal_attention_mask_with_cache_position(
|
| 1075 |
+
attention_mask,
|
| 1076 |
+
sequence_length=sequence_length,
|
| 1077 |
+
target_length=target_length,
|
| 1078 |
+
dtype=dtype,
|
| 1079 |
+
device=device,
|
| 1080 |
+
min_dtype=min_dtype,
|
| 1081 |
+
cache_position=cache_position,
|
| 1082 |
+
batch_size=input_tensor.shape[0],
|
| 1083 |
+
)
|
| 1084 |
+
|
| 1085 |
+
if (
|
| 1086 |
+
self.config._attn_implementation == "sdpa"
|
| 1087 |
+
and attention_mask is not None
|
| 1088 |
+
and attention_mask.device.type == "cuda"
|
| 1089 |
+
and not output_attentions
|
| 1090 |
+
):
|
| 1091 |
+
# Attend to all tokens in fully masked rows in the causal_mask, for example the relevant first rows when
|
| 1092 |
+
# using left padding. This is required by F.scaled_dot_product_attention memory-efficient attention path.
|
| 1093 |
+
# Details: https://github.com/pytorch/pytorch/issues/110213
|
| 1094 |
+
causal_mask = AttentionMaskConverter._unmask_unattended(causal_mask, min_dtype)
|
| 1095 |
+
|
| 1096 |
+
return causal_mask
|
| 1097 |
+
|
| 1098 |
+
|
| 1099 |
+
class Qwen2ForCausalLM(Qwen2PreTrainedModel, GenerationMixin):
|
| 1100 |
+
_tied_weights_keys = ["lm_head.weight"]
|
| 1101 |
+
|
| 1102 |
+
def __init__(self, config):
|
| 1103 |
+
super().__init__(config)
|
| 1104 |
+
self.model = Qwen2Model(config)
|
| 1105 |
+
self.vocab_size = config.vocab_size
|
| 1106 |
+
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
| 1107 |
+
|
| 1108 |
+
# Initialize weights and apply final processing
|
| 1109 |
+
self.post_init()
|
| 1110 |
+
|
| 1111 |
+
def get_input_embeddings(self):
|
| 1112 |
+
return self.model.embed_tokens
|
| 1113 |
+
|
| 1114 |
+
def set_input_embeddings(self, value):
|
| 1115 |
+
self.model.embed_tokens = value
|
| 1116 |
+
|
| 1117 |
+
def get_output_embeddings(self):
|
| 1118 |
+
return self.lm_head
|
| 1119 |
+
|
| 1120 |
+
def set_output_embeddings(self, new_embeddings):
|
| 1121 |
+
self.lm_head = new_embeddings
|
| 1122 |
+
|
| 1123 |
+
def set_decoder(self, decoder):
|
| 1124 |
+
self.model = decoder
|
| 1125 |
+
|
| 1126 |
+
def get_decoder(self):
|
| 1127 |
+
return self.model
|
| 1128 |
+
|
| 1129 |
+
@add_start_docstrings_to_model_forward(QWEN2_INPUTS_DOCSTRING)
|
| 1130 |
+
@replace_return_docstrings(output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
|
| 1131 |
+
def forward(
|
| 1132 |
+
self,
|
| 1133 |
+
input_ids: torch.LongTensor = None,
|
| 1134 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1135 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1136 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 1137 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 1138 |
+
labels: Optional[torch.LongTensor] = None,
|
| 1139 |
+
use_cache: Optional[bool] = None,
|
| 1140 |
+
output_attentions: Optional[bool] = None,
|
| 1141 |
+
output_hidden_states: Optional[bool] = None,
|
| 1142 |
+
return_dict: Optional[bool] = None,
|
| 1143 |
+
cache_position: Optional[torch.LongTensor] = None,
|
| 1144 |
+
num_logits_to_keep: int = 0,
|
| 1145 |
+
) -> Union[Tuple, CausalLMOutputWithPast]:
|
| 1146 |
+
r"""
|
| 1147 |
+
Args:
|
| 1148 |
+
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 1149 |
+
Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
|
| 1150 |
+
config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
|
| 1151 |
+
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
|
| 1152 |
+
|
| 1153 |
+
num_logits_to_keep (`int`, *optional*):
|
| 1154 |
+
Calculate logits for the last `num_logits_to_keep` tokens. If `0`, calculate logits for all
|
| 1155 |
+
`input_ids` (special case). Only last token logits are needed for generation, and calculating them only for that
|
| 1156 |
+
token can save memory, which becomes pretty significant for long sequences or large vocabulary size.
|
| 1157 |
+
|
| 1158 |
+
Returns:
|
| 1159 |
+
|
| 1160 |
+
Example:
|
| 1161 |
+
|
| 1162 |
+
```python
|
| 1163 |
+
>>> from transformers import AutoTokenizer, Qwen2ForCausalLM
|
| 1164 |
+
|
| 1165 |
+
>>> model = Qwen2ForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
|
| 1166 |
+
>>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
|
| 1167 |
+
|
| 1168 |
+
>>> prompt = "Hey, are you conscious? Can you talk to me?"
|
| 1169 |
+
>>> inputs = tokenizer(prompt, return_tensors="pt")
|
| 1170 |
+
|
| 1171 |
+
>>> # Generate
|
| 1172 |
+
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
|
| 1173 |
+
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
|
| 1174 |
+
"Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
|
| 1175 |
+
```"""
|
| 1176 |
+
|
| 1177 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 1178 |
+
output_hidden_states = (
|
| 1179 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 1180 |
+
)
|
| 1181 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1182 |
+
|
| 1183 |
+
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
|
| 1184 |
+
outputs = self.model(
|
| 1185 |
+
input_ids=input_ids,
|
| 1186 |
+
attention_mask=attention_mask,
|
| 1187 |
+
position_ids=position_ids,
|
| 1188 |
+
past_key_values=past_key_values,
|
| 1189 |
+
inputs_embeds=inputs_embeds,
|
| 1190 |
+
use_cache=use_cache,
|
| 1191 |
+
output_attentions=output_attentions,
|
| 1192 |
+
output_hidden_states=output_hidden_states,
|
| 1193 |
+
return_dict=return_dict,
|
| 1194 |
+
cache_position=cache_position,
|
| 1195 |
+
)
|
| 1196 |
+
|
| 1197 |
+
hidden_states = outputs[0]
|
| 1198 |
+
if labels is None and not is_torchdynamo_compiling():
|
| 1199 |
+
logger.warning_once(
|
| 1200 |
+
"Starting from v4.46, the `logits` model output will have the same type as the model (except at train time, where it will always be FP32)"
|
| 1201 |
+
)
|
| 1202 |
+
# Only compute necessary logits, and do not upcast them to float if we are not computing the loss
|
| 1203 |
+
# TODO: remove the float() operation in v4.46
|
| 1204 |
+
logits = self.lm_head(hidden_states[:, -num_logits_to_keep:, :]).float()
|
| 1205 |
+
|
| 1206 |
+
loss = None
|
| 1207 |
+
if labels is not None:
|
| 1208 |
+
# Upcast to float if we need to compute the loss to avoid potential precision issues
|
| 1209 |
+
logits = logits.float()
|
| 1210 |
+
# Shift so that tokens < n predict n
|
| 1211 |
+
shift_logits = logits[..., :-1, :].contiguous()
|
| 1212 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 1213 |
+
# Flatten the tokens
|
| 1214 |
+
loss_fct = CrossEntropyLoss()
|
| 1215 |
+
shift_logits = shift_logits.view(-1, self.config.vocab_size)
|
| 1216 |
+
shift_labels = shift_labels.view(-1)
|
| 1217 |
+
# Enable model parallelism
|
| 1218 |
+
shift_labels = shift_labels.to(shift_logits.device)
|
| 1219 |
+
loss = loss_fct(shift_logits, shift_labels)
|
| 1220 |
+
|
| 1221 |
+
if not return_dict:
|
| 1222 |
+
output = (logits,) + outputs[1:]
|
| 1223 |
+
return (loss,) + output if loss is not None else output
|
| 1224 |
+
|
| 1225 |
+
return CausalLMOutputWithPast(
|
| 1226 |
+
loss=loss,
|
| 1227 |
+
logits=logits,
|
| 1228 |
+
past_key_values=outputs.past_key_values,
|
| 1229 |
+
hidden_states=outputs.hidden_states,
|
| 1230 |
+
attentions=outputs.attentions,
|
| 1231 |
+
)
|
| 1232 |
+
|
| 1233 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.prepare_inputs_for_generation
|
| 1234 |
+
def prepare_inputs_for_generation(
|
| 1235 |
+
self,
|
| 1236 |
+
input_ids,
|
| 1237 |
+
past_key_values=None,
|
| 1238 |
+
attention_mask=None,
|
| 1239 |
+
inputs_embeds=None,
|
| 1240 |
+
cache_position=None,
|
| 1241 |
+
position_ids=None,
|
| 1242 |
+
use_cache=True,
|
| 1243 |
+
num_logits_to_keep=None,
|
| 1244 |
+
**kwargs,
|
| 1245 |
+
):
|
| 1246 |
+
# If we have cache: let's slice `input_ids` through `cache_position`, to keep only the unprocessed tokens
|
| 1247 |
+
# Exception 1: when passing input_embeds, input_ids may be missing entries
|
| 1248 |
+
# Exception 2: some generation methods do special slicing of input_ids, so we don't need to do it here
|
| 1249 |
+
if past_key_values is not None:
|
| 1250 |
+
if inputs_embeds is not None: # Exception 1
|
| 1251 |
+
input_ids = input_ids[:, -cache_position.shape[0] :]
|
| 1252 |
+
elif input_ids.shape[1] != cache_position.shape[0]: # Default case (the "else", a no op, is Exception 2)
|
| 1253 |
+
input_ids = input_ids[:, cache_position]
|
| 1254 |
+
|
| 1255 |
+
if attention_mask is not None and position_ids is None:
|
| 1256 |
+
# create position_ids on the fly for batch generation
|
| 1257 |
+
position_ids = attention_mask.long().cumsum(-1) - 1
|
| 1258 |
+
position_ids.masked_fill_(attention_mask == 0, 1)
|
| 1259 |
+
if past_key_values:
|
| 1260 |
+
position_ids = position_ids[:, -input_ids.shape[1] :]
|
| 1261 |
+
|
| 1262 |
+
# This `clone` call is needed to avoid recapturing cuda graphs with `torch.compile`'s `mode="reduce-overhead`, as otherwise the input `position_ids` would have various stride during the decoding. Here, simply using `.contiguous()` is not sufficient as in the batch size = 1 case, `position_ids` is already contiguous but with varying stride which retriggers a capture.
|
| 1263 |
+
position_ids = position_ids.clone(memory_format=torch.contiguous_format)
|
| 1264 |
+
|
| 1265 |
+
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
| 1266 |
+
if inputs_embeds is not None and cache_position[0] == 0:
|
| 1267 |
+
model_inputs = {"inputs_embeds": inputs_embeds, "input_ids": None}
|
| 1268 |
+
else:
|
| 1269 |
+
# The clone here is for the same reason as for `position_ids`.
|
| 1270 |
+
model_inputs = {"input_ids": input_ids.clone(memory_format=torch.contiguous_format), "inputs_embeds": None}
|
| 1271 |
+
|
| 1272 |
+
if isinstance(past_key_values, StaticCache) and attention_mask.ndim == 2:
|
| 1273 |
+
if model_inputs["inputs_embeds"] is not None:
|
| 1274 |
+
batch_size, sequence_length, _ = model_inputs["inputs_embeds"].shape
|
| 1275 |
+
device = model_inputs["inputs_embeds"].device
|
| 1276 |
+
else:
|
| 1277 |
+
batch_size, sequence_length = model_inputs["input_ids"].shape
|
| 1278 |
+
device = model_inputs["input_ids"].device
|
| 1279 |
+
|
| 1280 |
+
dtype = self.lm_head.weight.dtype
|
| 1281 |
+
min_dtype = torch.finfo(dtype).min
|
| 1282 |
+
|
| 1283 |
+
attention_mask = _prepare_4d_causal_attention_mask_with_cache_position(
|
| 1284 |
+
attention_mask,
|
| 1285 |
+
sequence_length=sequence_length,
|
| 1286 |
+
target_length=past_key_values.get_max_length(),
|
| 1287 |
+
dtype=dtype,
|
| 1288 |
+
device=device,
|
| 1289 |
+
min_dtype=min_dtype,
|
| 1290 |
+
cache_position=cache_position,
|
| 1291 |
+
batch_size=batch_size,
|
| 1292 |
+
)
|
| 1293 |
+
|
| 1294 |
+
if num_logits_to_keep is not None:
|
| 1295 |
+
model_inputs["num_logits_to_keep"] = num_logits_to_keep
|
| 1296 |
+
|
| 1297 |
+
model_inputs.update(
|
| 1298 |
+
{
|
| 1299 |
+
"position_ids": position_ids,
|
| 1300 |
+
"cache_position": cache_position,
|
| 1301 |
+
"past_key_values": past_key_values,
|
| 1302 |
+
"use_cache": use_cache,
|
| 1303 |
+
"attention_mask": attention_mask,
|
| 1304 |
+
}
|
| 1305 |
+
)
|
| 1306 |
+
return model_inputs
|
| 1307 |
+
|
| 1308 |
+
|
| 1309 |
+
@add_start_docstrings(
|
| 1310 |
+
"""
|
| 1311 |
+
The Qwen2 Model transformer with a sequence classification head on top (linear layer).
|
| 1312 |
+
|
| 1313 |
+
[`Qwen2ForSequenceClassification`] uses the last token in order to do the classification, as other causal models
|
| 1314 |
+
(e.g. GPT-2) do.
|
| 1315 |
+
|
| 1316 |
+
Since it does classification on the last token, it requires to know the position of the last token. If a
|
| 1317 |
+
`pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
|
| 1318 |
+
no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
|
| 1319 |
+
padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
|
| 1320 |
+
each row of the batch).
|
| 1321 |
+
""",
|
| 1322 |
+
QWEN2_START_DOCSTRING,
|
| 1323 |
+
)
|
| 1324 |
+
class Qwen2ForSequenceClassification(Qwen2PreTrainedModel):
|
| 1325 |
+
def __init__(self, config):
|
| 1326 |
+
super().__init__(config)
|
| 1327 |
+
self.num_labels = config.num_labels
|
| 1328 |
+
self.model = Qwen2Model(config)
|
| 1329 |
+
self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
|
| 1330 |
+
|
| 1331 |
+
# Initialize weights and apply final processing
|
| 1332 |
+
self.post_init()
|
| 1333 |
+
|
| 1334 |
+
def get_input_embeddings(self):
|
| 1335 |
+
return self.model.embed_tokens
|
| 1336 |
+
|
| 1337 |
+
def set_input_embeddings(self, value):
|
| 1338 |
+
self.model.embed_tokens = value
|
| 1339 |
+
|
| 1340 |
+
@add_start_docstrings_to_model_forward(QWEN2_INPUTS_DOCSTRING)
|
| 1341 |
+
def forward(
|
| 1342 |
+
self,
|
| 1343 |
+
input_ids: torch.LongTensor = None,
|
| 1344 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1345 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1346 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 1347 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 1348 |
+
labels: Optional[torch.LongTensor] = None,
|
| 1349 |
+
use_cache: Optional[bool] = None,
|
| 1350 |
+
output_attentions: Optional[bool] = None,
|
| 1351 |
+
output_hidden_states: Optional[bool] = None,
|
| 1352 |
+
return_dict: Optional[bool] = None,
|
| 1353 |
+
) -> Union[Tuple, SequenceClassifierOutputWithPast]:
|
| 1354 |
+
r"""
|
| 1355 |
+
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
|
| 1356 |
+
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
|
| 1357 |
+
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
|
| 1358 |
+
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
|
| 1359 |
+
"""
|
| 1360 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1361 |
+
|
| 1362 |
+
transformer_outputs = self.model(
|
| 1363 |
+
input_ids,
|
| 1364 |
+
attention_mask=attention_mask,
|
| 1365 |
+
position_ids=position_ids,
|
| 1366 |
+
past_key_values=past_key_values,
|
| 1367 |
+
inputs_embeds=inputs_embeds,
|
| 1368 |
+
use_cache=use_cache,
|
| 1369 |
+
output_attentions=output_attentions,
|
| 1370 |
+
output_hidden_states=output_hidden_states,
|
| 1371 |
+
return_dict=return_dict,
|
| 1372 |
+
)
|
| 1373 |
+
hidden_states = transformer_outputs[0]
|
| 1374 |
+
logits = self.score(hidden_states)
|
| 1375 |
+
|
| 1376 |
+
if input_ids is not None:
|
| 1377 |
+
batch_size = input_ids.shape[0]
|
| 1378 |
+
else:
|
| 1379 |
+
batch_size = inputs_embeds.shape[0]
|
| 1380 |
+
|
| 1381 |
+
if self.config.pad_token_id is None and batch_size != 1:
|
| 1382 |
+
raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")
|
| 1383 |
+
if self.config.pad_token_id is None:
|
| 1384 |
+
sequence_lengths = -1
|
| 1385 |
+
else:
|
| 1386 |
+
if input_ids is not None:
|
| 1387 |
+
# if no pad token found, use modulo instead of reverse indexing for ONNX compatibility
|
| 1388 |
+
sequence_lengths = torch.eq(input_ids, self.config.pad_token_id).int().argmax(-1) - 1
|
| 1389 |
+
sequence_lengths = sequence_lengths % input_ids.shape[-1]
|
| 1390 |
+
sequence_lengths = sequence_lengths.to(logits.device)
|
| 1391 |
+
else:
|
| 1392 |
+
sequence_lengths = -1
|
| 1393 |
+
|
| 1394 |
+
pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
|
| 1395 |
+
|
| 1396 |
+
loss = None
|
| 1397 |
+
if labels is not None:
|
| 1398 |
+
labels = labels.to(logits.device)
|
| 1399 |
+
if self.config.problem_type is None:
|
| 1400 |
+
if self.num_labels == 1:
|
| 1401 |
+
self.config.problem_type = "regression"
|
| 1402 |
+
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
|
| 1403 |
+
self.config.problem_type = "single_label_classification"
|
| 1404 |
+
else:
|
| 1405 |
+
self.config.problem_type = "multi_label_classification"
|
| 1406 |
+
|
| 1407 |
+
if self.config.problem_type == "regression":
|
| 1408 |
+
loss_fct = MSELoss()
|
| 1409 |
+
if self.num_labels == 1:
|
| 1410 |
+
loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
|
| 1411 |
+
else:
|
| 1412 |
+
loss = loss_fct(pooled_logits, labels)
|
| 1413 |
+
elif self.config.problem_type == "single_label_classification":
|
| 1414 |
+
loss_fct = CrossEntropyLoss()
|
| 1415 |
+
loss = loss_fct(pooled_logits.view(-1, self.num_labels), labels.view(-1))
|
| 1416 |
+
elif self.config.problem_type == "multi_label_classification":
|
| 1417 |
+
loss_fct = BCEWithLogitsLoss()
|
| 1418 |
+
loss = loss_fct(pooled_logits, labels)
|
| 1419 |
+
if not return_dict:
|
| 1420 |
+
output = (pooled_logits,) + transformer_outputs[1:]
|
| 1421 |
+
return ((loss,) + output) if loss is not None else output
|
| 1422 |
+
|
| 1423 |
+
return SequenceClassifierOutputWithPast(
|
| 1424 |
+
loss=loss,
|
| 1425 |
+
logits=pooled_logits,
|
| 1426 |
+
past_key_values=transformer_outputs.past_key_values,
|
| 1427 |
+
hidden_states=transformer_outputs.hidden_states,
|
| 1428 |
+
attentions=transformer_outputs.attentions,
|
| 1429 |
+
)
|
| 1430 |
+
|
| 1431 |
+
|
| 1432 |
+
@add_start_docstrings(
|
| 1433 |
+
"""
|
| 1434 |
+
The Qwen2 Model transformer with a token classification head on top (a linear layer on top of the hidden-states
|
| 1435 |
+
output) e.g. for Named-Entity-Recognition (NER) tasks.
|
| 1436 |
+
""",
|
| 1437 |
+
QWEN2_START_DOCSTRING,
|
| 1438 |
+
)
|
| 1439 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaForTokenClassification with Llama->Qwen2, LLAMA->QWEN2
|
| 1440 |
+
class Qwen2ForTokenClassification(Qwen2PreTrainedModel):
|
| 1441 |
+
def __init__(self, config):
|
| 1442 |
+
super().__init__(config)
|
| 1443 |
+
self.num_labels = config.num_labels
|
| 1444 |
+
self.model = Qwen2Model(config)
|
| 1445 |
+
if getattr(config, "classifier_dropout", None) is not None:
|
| 1446 |
+
classifier_dropout = config.classifier_dropout
|
| 1447 |
+
elif getattr(config, "hidden_dropout", None) is not None:
|
| 1448 |
+
classifier_dropout = config.hidden_dropout
|
| 1449 |
+
else:
|
| 1450 |
+
classifier_dropout = 0.1
|
| 1451 |
+
self.dropout = nn.Dropout(classifier_dropout)
|
| 1452 |
+
self.score = nn.Linear(config.hidden_size, config.num_labels)
|
| 1453 |
+
|
| 1454 |
+
# Initialize weights and apply final processing
|
| 1455 |
+
self.post_init()
|
| 1456 |
+
|
| 1457 |
+
def get_input_embeddings(self):
|
| 1458 |
+
return self.model.embed_tokens
|
| 1459 |
+
|
| 1460 |
+
def set_input_embeddings(self, value):
|
| 1461 |
+
self.model.embed_tokens = value
|
| 1462 |
+
|
| 1463 |
+
@add_start_docstrings_to_model_forward(QWEN2_INPUTS_DOCSTRING)
|
| 1464 |
+
def forward(
|
| 1465 |
+
self,
|
| 1466 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 1467 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1468 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1469 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 1470 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 1471 |
+
labels: Optional[torch.LongTensor] = None,
|
| 1472 |
+
use_cache: Optional[bool] = None,
|
| 1473 |
+
output_attentions: Optional[bool] = None,
|
| 1474 |
+
output_hidden_states: Optional[bool] = None,
|
| 1475 |
+
return_dict: Optional[bool] = None,
|
| 1476 |
+
) -> Union[Tuple, TokenClassifierOutput]:
|
| 1477 |
+
r"""
|
| 1478 |
+
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
|
| 1479 |
+
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
|
| 1480 |
+
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
|
| 1481 |
+
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
|
| 1482 |
+
"""
|
| 1483 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1484 |
+
|
| 1485 |
+
outputs = self.model(
|
| 1486 |
+
input_ids,
|
| 1487 |
+
attention_mask=attention_mask,
|
| 1488 |
+
position_ids=position_ids,
|
| 1489 |
+
past_key_values=past_key_values,
|
| 1490 |
+
inputs_embeds=inputs_embeds,
|
| 1491 |
+
use_cache=use_cache,
|
| 1492 |
+
output_attentions=output_attentions,
|
| 1493 |
+
output_hidden_states=output_hidden_states,
|
| 1494 |
+
return_dict=return_dict,
|
| 1495 |
+
)
|
| 1496 |
+
sequence_output = outputs[0]
|
| 1497 |
+
sequence_output = self.dropout(sequence_output)
|
| 1498 |
+
logits = self.score(sequence_output)
|
| 1499 |
+
|
| 1500 |
+
loss = None
|
| 1501 |
+
if labels is not None:
|
| 1502 |
+
loss_fct = CrossEntropyLoss()
|
| 1503 |
+
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
|
| 1504 |
+
|
| 1505 |
+
if not return_dict:
|
| 1506 |
+
output = (logits,) + outputs[2:]
|
| 1507 |
+
return ((loss,) + output) if loss is not None else output
|
| 1508 |
+
|
| 1509 |
+
return TokenClassifierOutput(
|
| 1510 |
+
loss=loss,
|
| 1511 |
+
logits=logits,
|
| 1512 |
+
hidden_states=outputs.hidden_states,
|
| 1513 |
+
attentions=outputs.attentions,
|
| 1514 |
+
)
|
modeling_sailvl.py
ADDED
|
@@ -0,0 +1,388 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# SailVL
|
| 3 |
+
# Copyright (2024) Bytedance Ltd. and/or its affiliates
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
# --------------------------------------------------------
|
| 16 |
+
|
| 17 |
+
# --------------------------------------------------------
|
| 18 |
+
# InternVL
|
| 19 |
+
# Copyright (c) 2024 OpenGVLab
|
| 20 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 21 |
+
# --------------------------------------------------------
|
| 22 |
+
import warnings
|
| 23 |
+
from typing import Any, List, Optional, Tuple, Union
|
| 24 |
+
|
| 25 |
+
import torch.utils.checkpoint
|
| 26 |
+
import transformers
|
| 27 |
+
from torch import nn
|
| 28 |
+
from torch.nn import CrossEntropyLoss
|
| 29 |
+
from transformers import (AutoModel, GenerationConfig, LlamaForCausalLM,
|
| 30 |
+
LlamaTokenizer)
|
| 31 |
+
from transformers.modeling_outputs import CausalLMOutputWithPast
|
| 32 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 33 |
+
from transformers.utils import ModelOutput, logging
|
| 34 |
+
from .modeling_qwen2 import Qwen2ForCausalLM
|
| 35 |
+
|
| 36 |
+
from .configuration_sailvl import SailVLConfig
|
| 37 |
+
from .conversation import get_conv_template
|
| 38 |
+
from .modeling_aimv2 import AIMv2Model
|
| 39 |
+
|
| 40 |
+
logger = logging.get_logger(__name__)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def version_cmp(v1, v2, op='eq'):
|
| 44 |
+
import operator
|
| 45 |
+
|
| 46 |
+
from packaging import version
|
| 47 |
+
op_func = getattr(operator, op)
|
| 48 |
+
return op_func(version.parse(v1), version.parse(v2))
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
class SailVLModel(PreTrainedModel):
|
| 52 |
+
config_class = SailVLConfig
|
| 53 |
+
main_input_name = 'pixel_values'
|
| 54 |
+
_supports_flash_attn_2 = True
|
| 55 |
+
_no_split_modules = ['AIMv2Model',
|
| 56 |
+
'LlamaDecoderLayer', 'InternLM2DecoderLayer']
|
| 57 |
+
|
| 58 |
+
def __init__(self, config: SailVLConfig, vision_model=None, language_model=None):
|
| 59 |
+
super().__init__(config)
|
| 60 |
+
|
| 61 |
+
assert version_cmp(transformers.__version__, '4.36.2', 'ge')
|
| 62 |
+
image_size = config.force_image_size or config.vision_config.image_size
|
| 63 |
+
patch_size = config.vision_config.patch_size
|
| 64 |
+
self.patch_size = patch_size
|
| 65 |
+
self.select_layer = config.select_layer
|
| 66 |
+
self.template = config.template
|
| 67 |
+
self.num_image_token = int(
|
| 68 |
+
(image_size // patch_size) ** 2 * (config.downsample_ratio ** 2))
|
| 69 |
+
self.downsample_ratio = config.downsample_ratio
|
| 70 |
+
self.ps_version = config.ps_version
|
| 71 |
+
|
| 72 |
+
logger.info(f'num_image_token: {self.num_image_token}')
|
| 73 |
+
logger.info(f'ps_version: {self.ps_version}')
|
| 74 |
+
if vision_model is not None:
|
| 75 |
+
self.vision_model = vision_model
|
| 76 |
+
else:
|
| 77 |
+
self.vision_model = AIMv2Model(config.vision_config)
|
| 78 |
+
if language_model is not None:
|
| 79 |
+
self.language_model = language_model
|
| 80 |
+
self.config.llm_config = language_model.config
|
| 81 |
+
else:
|
| 82 |
+
if config.llm_config.architectures[0] == 'LlamaForCausalLM':
|
| 83 |
+
self.language_model = LlamaForCausalLM(config.llm_config)
|
| 84 |
+
elif config.llm_config.architectures[0] == 'InternLM2ForCausalLM':
|
| 85 |
+
self.language_model = InternLM2ForCausalLM(config.llm_config)
|
| 86 |
+
elif config.llm_config.architectures[0] == 'Qwen2ForCausalLM':
|
| 87 |
+
self.language_model = Qwen2ForCausalLM(config.llm_config)
|
| 88 |
+
else:
|
| 89 |
+
raise NotImplementedError(
|
| 90 |
+
f'{config.llm_config.architectures[0]} is not implemented.')
|
| 91 |
+
|
| 92 |
+
vit_hidden_size = config.vision_config.hidden_size
|
| 93 |
+
llm_hidden_size = config.llm_config.hidden_size
|
| 94 |
+
|
| 95 |
+
self.mlp1 = nn.Sequential(
|
| 96 |
+
nn.LayerNorm(vit_hidden_size *
|
| 97 |
+
int(1 / self.downsample_ratio) ** 2),
|
| 98 |
+
nn.Linear(vit_hidden_size * int(1 / self.downsample_ratio)
|
| 99 |
+
** 2, llm_hidden_size),
|
| 100 |
+
nn.GELU(),
|
| 101 |
+
nn.Linear(llm_hidden_size, llm_hidden_size)
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
self.img_context_token_id = None
|
| 105 |
+
self.conv_template = get_conv_template(self.template)
|
| 106 |
+
self.system_message = self.conv_template.system_message
|
| 107 |
+
|
| 108 |
+
def forward(
|
| 109 |
+
self,
|
| 110 |
+
pixel_values: torch.FloatTensor,
|
| 111 |
+
input_ids: torch.LongTensor = None,
|
| 112 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 113 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 114 |
+
image_flags: Optional[torch.LongTensor] = None,
|
| 115 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 116 |
+
labels: Optional[torch.LongTensor] = None,
|
| 117 |
+
use_cache: Optional[bool] = None,
|
| 118 |
+
output_attentions: Optional[bool] = None,
|
| 119 |
+
output_hidden_states: Optional[bool] = None,
|
| 120 |
+
return_dict: Optional[bool] = None,
|
| 121 |
+
) -> Union[Tuple, CausalLMOutputWithPast]:
|
| 122 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 123 |
+
|
| 124 |
+
image_flags = image_flags.squeeze(-1)
|
| 125 |
+
input_embeds = self.language_model.get_input_embeddings()(input_ids)
|
| 126 |
+
|
| 127 |
+
vit_embeds = self.extract_feature(pixel_values)
|
| 128 |
+
vit_embeds = vit_embeds[image_flags == 1]
|
| 129 |
+
vit_batch_size = pixel_values.shape[0]
|
| 130 |
+
|
| 131 |
+
B, N, C = input_embeds.shape
|
| 132 |
+
input_embeds = input_embeds.reshape(B * N, C)
|
| 133 |
+
|
| 134 |
+
if torch.distributed.get_rank() == 0:
|
| 135 |
+
print(
|
| 136 |
+
f'dynamic ViT batch size: {vit_batch_size}, images per sample: {vit_batch_size / B}, dynamic token length: {N}')
|
| 137 |
+
|
| 138 |
+
input_ids = input_ids.reshape(B * N)
|
| 139 |
+
selected = (input_ids == self.img_context_token_id)
|
| 140 |
+
try:
|
| 141 |
+
input_embeds[selected] = input_embeds[selected] * \
|
| 142 |
+
0.0 + vit_embeds.reshape(-1, C)
|
| 143 |
+
except Exception as e:
|
| 144 |
+
vit_embeds = vit_embeds.reshape(-1, C)
|
| 145 |
+
print(f'warning: {e}, input_embeds[selected].shape={input_embeds[selected].shape}, '
|
| 146 |
+
f'vit_embeds.shape={vit_embeds.shape}')
|
| 147 |
+
n_token = selected.sum()
|
| 148 |
+
input_embeds[selected] = input_embeds[selected] * \
|
| 149 |
+
0.0 + vit_embeds[:n_token]
|
| 150 |
+
|
| 151 |
+
input_embeds = input_embeds.reshape(B, N, C)
|
| 152 |
+
|
| 153 |
+
outputs = self.language_model(
|
| 154 |
+
inputs_embeds=input_embeds,
|
| 155 |
+
attention_mask=attention_mask,
|
| 156 |
+
position_ids=position_ids,
|
| 157 |
+
past_key_values=past_key_values,
|
| 158 |
+
use_cache=use_cache,
|
| 159 |
+
output_attentions=output_attentions,
|
| 160 |
+
output_hidden_states=output_hidden_states,
|
| 161 |
+
return_dict=return_dict,
|
| 162 |
+
)
|
| 163 |
+
logits = outputs.logits
|
| 164 |
+
|
| 165 |
+
loss = None
|
| 166 |
+
if labels is not None:
|
| 167 |
+
# Shift so that tokens < n predict n
|
| 168 |
+
shift_logits = logits[..., :-1, :].contiguous()
|
| 169 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 170 |
+
# Flatten the tokens
|
| 171 |
+
loss_fct = CrossEntropyLoss()
|
| 172 |
+
shift_logits = shift_logits.view(-1,
|
| 173 |
+
self.language_model.config.vocab_size)
|
| 174 |
+
shift_labels = shift_labels.view(-1)
|
| 175 |
+
# Enable model parallelism
|
| 176 |
+
shift_labels = shift_labels.to(shift_logits.device)
|
| 177 |
+
loss = loss_fct(shift_logits, shift_labels)
|
| 178 |
+
|
| 179 |
+
if not return_dict:
|
| 180 |
+
output = (logits,) + outputs[1:]
|
| 181 |
+
return (loss,) + output if loss is not None else output
|
| 182 |
+
|
| 183 |
+
return CausalLMOutputWithPast(
|
| 184 |
+
loss=loss,
|
| 185 |
+
logits=logits,
|
| 186 |
+
past_key_values=outputs.past_key_values,
|
| 187 |
+
hidden_states=outputs.hidden_states,
|
| 188 |
+
attentions=outputs.attentions,
|
| 189 |
+
)
|
| 190 |
+
|
| 191 |
+
def pixel_shuffle(self, x, scale_factor=0.5):
|
| 192 |
+
n, w, h, c = x.size()
|
| 193 |
+
# N, W, H, C --> N, W, H * scale, C // scale
|
| 194 |
+
x = x.reshape(n, w, int(h * scale_factor), int(c / scale_factor))
|
| 195 |
+
# N, W, H * scale, C // scale --> N, H * scale, W, C // scale
|
| 196 |
+
x = x.permute(0, 2, 1, 3).contiguous()
|
| 197 |
+
# N, H * scale, W, C // scale --> N, H * scale, W * scale, C // (scale ** 2)
|
| 198 |
+
x = x.reshape(n, int(h * scale_factor), int(w * scale_factor),
|
| 199 |
+
int(c / (scale_factor * scale_factor)))
|
| 200 |
+
if self.ps_version == 'v1':
|
| 201 |
+
warnings.warn("In ps_version 'v1', the height and width have not been swapped back, "
|
| 202 |
+
'which results in a transposed image.')
|
| 203 |
+
else:
|
| 204 |
+
x = x.permute(0, 2, 1, 3).contiguous()
|
| 205 |
+
return x
|
| 206 |
+
|
| 207 |
+
def extract_feature(self, pixel_values):
|
| 208 |
+
if self.select_layer == -1:
|
| 209 |
+
vit_embeds = self.vision_model(
|
| 210 |
+
pixel_values=pixel_values,
|
| 211 |
+
output_hidden_states=False,
|
| 212 |
+
return_dict=True).last_hidden_state
|
| 213 |
+
else:
|
| 214 |
+
vit_embeds = self.vision_model(
|
| 215 |
+
pixel_values=pixel_values,
|
| 216 |
+
output_hidden_states=True,
|
| 217 |
+
return_dict=True).hidden_states[self.select_layer]
|
| 218 |
+
vit_embeds = vit_embeds # [:, :, :]
|
| 219 |
+
|
| 220 |
+
h = w = int(vit_embeds.shape[1] ** 0.5)
|
| 221 |
+
|
| 222 |
+
vit_embeds = vit_embeds.reshape(vit_embeds.shape[0], h, w, -1)
|
| 223 |
+
vit_embeds = self.pixel_shuffle(
|
| 224 |
+
vit_embeds, scale_factor=self.downsample_ratio)
|
| 225 |
+
vit_embeds = vit_embeds.reshape(
|
| 226 |
+
vit_embeds.shape[0], -1, vit_embeds.shape[-1])
|
| 227 |
+
vit_embeds = self.mlp1(vit_embeds)
|
| 228 |
+
return vit_embeds
|
| 229 |
+
|
| 230 |
+
def batch_chat(self, tokenizer, pixel_values, questions, generation_config, num_patches_list=None,
|
| 231 |
+
history=None, return_history=False, IMG_START_TOKEN='<img>', IMG_END_TOKEN='</img>',
|
| 232 |
+
IMG_CONTEXT_TOKEN='<IMG_CONTEXT>', verbose=False, image_counts=None):
|
| 233 |
+
if history is not None or return_history:
|
| 234 |
+
print('Now multi-turn chat is not supported in batch_chat.')
|
| 235 |
+
raise NotImplementedError
|
| 236 |
+
|
| 237 |
+
if image_counts is not None:
|
| 238 |
+
num_patches_list = image_counts
|
| 239 |
+
print(
|
| 240 |
+
'Warning: `image_counts` is deprecated. Please use `num_patches_list` instead.')
|
| 241 |
+
|
| 242 |
+
img_context_token_id = tokenizer.convert_tokens_to_ids(
|
| 243 |
+
IMG_CONTEXT_TOKEN)
|
| 244 |
+
self.img_context_token_id = img_context_token_id
|
| 245 |
+
|
| 246 |
+
if verbose and pixel_values is not None:
|
| 247 |
+
image_bs = pixel_values.shape[0]
|
| 248 |
+
print(f'dynamic ViT batch size: {image_bs}')
|
| 249 |
+
|
| 250 |
+
queries = []
|
| 251 |
+
for idx, num_patches in enumerate(num_patches_list):
|
| 252 |
+
question = questions[idx]
|
| 253 |
+
if pixel_values is not None and '<image>' not in question:
|
| 254 |
+
question = '<image>\n' + question
|
| 255 |
+
template = get_conv_template(self.template)
|
| 256 |
+
template.append_message(template.roles[0], question)
|
| 257 |
+
template.append_message(template.roles[1], None)
|
| 258 |
+
query = template.get_prompt()
|
| 259 |
+
|
| 260 |
+
image_tokens = IMG_START_TOKEN + IMG_CONTEXT_TOKEN * \
|
| 261 |
+
self.num_image_token * num_patches + IMG_END_TOKEN
|
| 262 |
+
query = query.replace('<image>', image_tokens, 1)
|
| 263 |
+
queries.append(query)
|
| 264 |
+
|
| 265 |
+
tokenizer.padding_side = 'left'
|
| 266 |
+
model_inputs = tokenizer(queries, return_tensors='pt', padding=True)
|
| 267 |
+
input_ids = model_inputs['input_ids'].cuda()
|
| 268 |
+
attention_mask = model_inputs['attention_mask'].cuda()
|
| 269 |
+
eos_token_id = tokenizer.convert_tokens_to_ids(template.sep)
|
| 270 |
+
generation_config['eos_token_id'] = eos_token_id
|
| 271 |
+
generation_output = self.generate(
|
| 272 |
+
pixel_values=pixel_values,
|
| 273 |
+
input_ids=input_ids,
|
| 274 |
+
attention_mask=attention_mask,
|
| 275 |
+
**generation_config
|
| 276 |
+
)
|
| 277 |
+
responses = tokenizer.batch_decode(
|
| 278 |
+
generation_output, skip_special_tokens=True)
|
| 279 |
+
responses = [response.split(template.sep)[0].strip()
|
| 280 |
+
for response in responses]
|
| 281 |
+
return responses
|
| 282 |
+
|
| 283 |
+
def chat(self, tokenizer, pixel_values, question, generation_config, history=None, return_history=False,
|
| 284 |
+
num_patches_list=None, IMG_START_TOKEN='<img>', IMG_END_TOKEN='</img>', IMG_CONTEXT_TOKEN='<IMG_CONTEXT>',
|
| 285 |
+
verbose=False):
|
| 286 |
+
|
| 287 |
+
if history is None and pixel_values is not None and '<image>' not in question:
|
| 288 |
+
question = '<image>\n' + question
|
| 289 |
+
|
| 290 |
+
if num_patches_list is None:
|
| 291 |
+
num_patches_list = [pixel_values.shape[0]
|
| 292 |
+
] if pixel_values is not None else []
|
| 293 |
+
assert pixel_values is None or len(
|
| 294 |
+
pixel_values) == sum(num_patches_list)
|
| 295 |
+
|
| 296 |
+
img_context_token_id = tokenizer.convert_tokens_to_ids(
|
| 297 |
+
IMG_CONTEXT_TOKEN)
|
| 298 |
+
self.img_context_token_id = img_context_token_id
|
| 299 |
+
|
| 300 |
+
template = get_conv_template(self.template)
|
| 301 |
+
template.system_message = self.system_message
|
| 302 |
+
eos_token_id = tokenizer.convert_tokens_to_ids(template.sep)
|
| 303 |
+
|
| 304 |
+
history = [] if history is None else history
|
| 305 |
+
for (old_question, old_answer) in history:
|
| 306 |
+
template.append_message(template.roles[0], old_question)
|
| 307 |
+
template.append_message(template.roles[1], old_answer)
|
| 308 |
+
template.append_message(template.roles[0], question)
|
| 309 |
+
template.append_message(template.roles[1], None)
|
| 310 |
+
query = template.get_prompt()
|
| 311 |
+
|
| 312 |
+
if verbose and pixel_values is not None:
|
| 313 |
+
image_bs = pixel_values.shape[0]
|
| 314 |
+
print(f'dynamic ViT batch size: {image_bs}')
|
| 315 |
+
|
| 316 |
+
for num_patches in num_patches_list:
|
| 317 |
+
image_tokens = IMG_START_TOKEN + IMG_CONTEXT_TOKEN * \
|
| 318 |
+
self.num_image_token * num_patches + IMG_END_TOKEN
|
| 319 |
+
query = query.replace('<image>', image_tokens, 1)
|
| 320 |
+
|
| 321 |
+
model_inputs = tokenizer(query, return_tensors='pt')
|
| 322 |
+
input_ids = model_inputs['input_ids'].cuda()
|
| 323 |
+
attention_mask = model_inputs['attention_mask'].cuda()
|
| 324 |
+
generation_config['eos_token_id'] = eos_token_id
|
| 325 |
+
generation_output = self.generate(
|
| 326 |
+
pixel_values=pixel_values,
|
| 327 |
+
input_ids=input_ids,
|
| 328 |
+
attention_mask=attention_mask,
|
| 329 |
+
**generation_config
|
| 330 |
+
)
|
| 331 |
+
response = tokenizer.batch_decode(
|
| 332 |
+
generation_output, skip_special_tokens=True)[0]
|
| 333 |
+
response = response.split(template.sep)[0].strip()
|
| 334 |
+
history.append((question, response))
|
| 335 |
+
if return_history:
|
| 336 |
+
return response, history
|
| 337 |
+
else:
|
| 338 |
+
query_to_print = query.replace(IMG_CONTEXT_TOKEN, '')
|
| 339 |
+
query_to_print = query_to_print.replace(
|
| 340 |
+
f'{IMG_START_TOKEN}{IMG_END_TOKEN}', '<image>')
|
| 341 |
+
if verbose:
|
| 342 |
+
print(query_to_print, response)
|
| 343 |
+
return response
|
| 344 |
+
|
| 345 |
+
@torch.no_grad()
|
| 346 |
+
def generate(
|
| 347 |
+
self,
|
| 348 |
+
pixel_values: Optional[torch.FloatTensor] = None,
|
| 349 |
+
input_ids: Optional[torch.FloatTensor] = None,
|
| 350 |
+
attention_mask: Optional[torch.LongTensor] = None,
|
| 351 |
+
visual_features: Optional[torch.FloatTensor] = None,
|
| 352 |
+
generation_config: Optional[GenerationConfig] = None,
|
| 353 |
+
output_hidden_states: Optional[bool] = None,
|
| 354 |
+
return_dict: Optional[bool] = None,
|
| 355 |
+
**generate_kwargs,
|
| 356 |
+
) -> torch.LongTensor:
|
| 357 |
+
|
| 358 |
+
assert self.img_context_token_id is not None
|
| 359 |
+
if pixel_values is not None:
|
| 360 |
+
if visual_features is not None:
|
| 361 |
+
vit_embeds = visual_features
|
| 362 |
+
else:
|
| 363 |
+
vit_embeds = self.extract_feature(pixel_values)
|
| 364 |
+
input_embeds = self.language_model.get_input_embeddings()(input_ids)
|
| 365 |
+
B, N, C = input_embeds.shape
|
| 366 |
+
input_embeds = input_embeds.reshape(B * N, C)
|
| 367 |
+
|
| 368 |
+
input_ids = input_ids.reshape(B * N)
|
| 369 |
+
selected = (input_ids == self.img_context_token_id)
|
| 370 |
+
assert selected.sum() != 0
|
| 371 |
+
input_embeds[selected] = vit_embeds.reshape(
|
| 372 |
+
-1, C).to(input_embeds.device)
|
| 373 |
+
|
| 374 |
+
input_embeds = input_embeds.reshape(B, N, C)
|
| 375 |
+
else:
|
| 376 |
+
input_embeds = self.language_model.get_input_embeddings()(input_ids)
|
| 377 |
+
|
| 378 |
+
outputs = self.language_model.generate(
|
| 379 |
+
inputs_embeds=input_embeds,
|
| 380 |
+
attention_mask=attention_mask,
|
| 381 |
+
generation_config=generation_config,
|
| 382 |
+
output_hidden_states=output_hidden_states,
|
| 383 |
+
return_dict=return_dict,
|
| 384 |
+
use_cache=True,
|
| 385 |
+
**generate_kwargs,
|
| 386 |
+
)
|
| 387 |
+
|
| 388 |
+
return outputs
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|im_start|>",
|
| 4 |
+
"<|im_end|>",
|
| 5 |
+
"<|object_ref_start|>",
|
| 6 |
+
"<|object_ref_end|>",
|
| 7 |
+
"<|box_start|>",
|
| 8 |
+
"<|box_end|>",
|
| 9 |
+
"<|quad_start|>",
|
| 10 |
+
"<|quad_end|>",
|
| 11 |
+
"<|vision_start|>",
|
| 12 |
+
"<|vision_end|>",
|
| 13 |
+
"<|vision_pad|>",
|
| 14 |
+
"<|image_pad|>",
|
| 15 |
+
"<|video_pad|>"
|
| 16 |
+
],
|
| 17 |
+
"eos_token": {
|
| 18 |
+
"content": "<|im_end|>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
},
|
| 24 |
+
"pad_token": {
|
| 25 |
+
"content": "<|endoftext|>",
|
| 26 |
+
"lstrip": false,
|
| 27 |
+
"normalized": false,
|
| 28 |
+
"rstrip": false,
|
| 29 |
+
"single_word": false
|
| 30 |
+
}
|
| 31 |
+
}
|
statics/paper_page.png
ADDED

|
Git LFS Details
|
statics/performance.png
ADDED
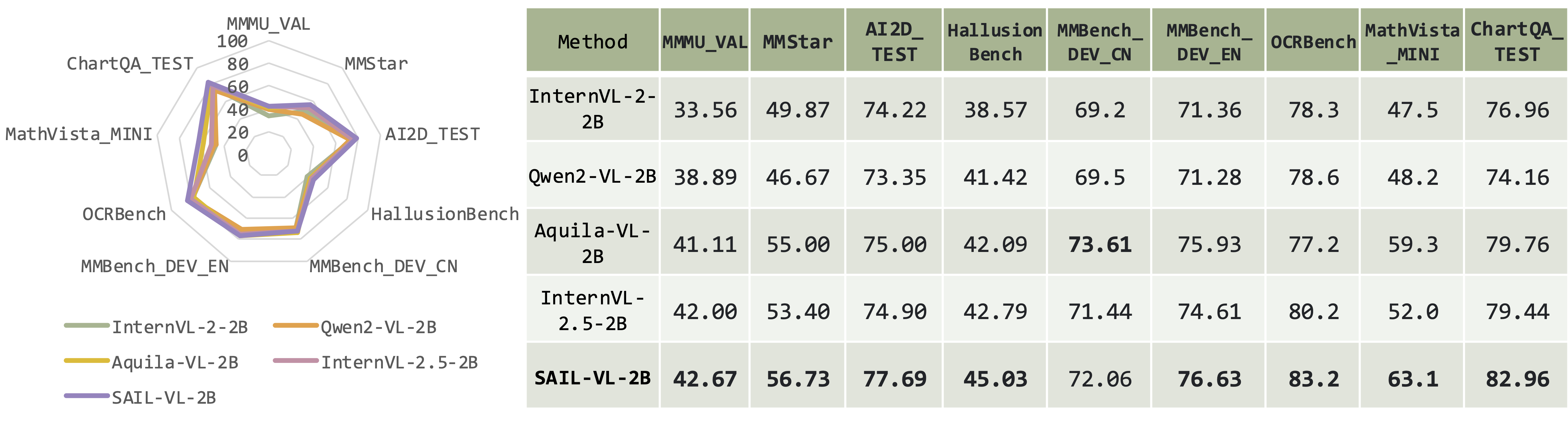
|
Git LFS Details
|
statics/sail.png
ADDED

|
Git LFS Details
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6f9ba4b4a6625b5047a1356f6081b641c3e4e6a4a198facbd4bef217747d1685
|
| 3 |
+
size 11423548
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f868398fc4e05ee1e8aeba95ddf18ddcc45b8bce55d5093bead5bbf80429b48b
|
| 3 |
+
size 1477754
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,279 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": false,
|
| 3 |
+
"add_prefix_space": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"151643": {
|
| 6 |
+
"content": "<|endoftext|>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"151644": {
|
| 14 |
+
"content": "<|im_start|>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"151645": {
|
| 22 |
+
"content": "<|im_end|>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
},
|
| 29 |
+
"151646": {
|
| 30 |
+
"content": "<|object_ref_start|>",
|
| 31 |
+
"lstrip": false,
|
| 32 |
+
"normalized": false,
|
| 33 |
+
"rstrip": false,
|
| 34 |
+
"single_word": false,
|
| 35 |
+
"special": true
|
| 36 |
+
},
|
| 37 |
+
"151647": {
|
| 38 |
+
"content": "<|object_ref_end|>",
|
| 39 |
+
"lstrip": false,
|
| 40 |
+
"normalized": false,
|
| 41 |
+
"rstrip": false,
|
| 42 |
+
"single_word": false,
|
| 43 |
+
"special": true
|
| 44 |
+
},
|
| 45 |
+
"151648": {
|
| 46 |
+
"content": "<|box_start|>",
|
| 47 |
+
"lstrip": false,
|
| 48 |
+
"normalized": false,
|
| 49 |
+
"rstrip": false,
|
| 50 |
+
"single_word": false,
|
| 51 |
+
"special": true
|
| 52 |
+
},
|
| 53 |
+
"151649": {
|
| 54 |
+
"content": "<|box_end|>",
|
| 55 |
+
"lstrip": false,
|
| 56 |
+
"normalized": false,
|
| 57 |
+
"rstrip": false,
|
| 58 |
+
"single_word": false,
|
| 59 |
+
"special": true
|
| 60 |
+
},
|
| 61 |
+
"151650": {
|
| 62 |
+
"content": "<|quad_start|>",
|
| 63 |
+
"lstrip": false,
|
| 64 |
+
"normalized": false,
|
| 65 |
+
"rstrip": false,
|
| 66 |
+
"single_word": false,
|
| 67 |
+
"special": true
|
| 68 |
+
},
|
| 69 |
+
"151651": {
|
| 70 |
+
"content": "<|quad_end|>",
|
| 71 |
+
"lstrip": false,
|
| 72 |
+
"normalized": false,
|
| 73 |
+
"rstrip": false,
|
| 74 |
+
"single_word": false,
|
| 75 |
+
"special": true
|
| 76 |
+
},
|
| 77 |
+
"151652": {
|
| 78 |
+
"content": "<|vision_start|>",
|
| 79 |
+
"lstrip": false,
|
| 80 |
+
"normalized": false,
|
| 81 |
+
"rstrip": false,
|
| 82 |
+
"single_word": false,
|
| 83 |
+
"special": true
|
| 84 |
+
},
|
| 85 |
+
"151653": {
|
| 86 |
+
"content": "<|vision_end|>",
|
| 87 |
+
"lstrip": false,
|
| 88 |
+
"normalized": false,
|
| 89 |
+
"rstrip": false,
|
| 90 |
+
"single_word": false,
|
| 91 |
+
"special": true
|
| 92 |
+
},
|
| 93 |
+
"151654": {
|
| 94 |
+
"content": "<|vision_pad|>",
|
| 95 |
+
"lstrip": false,
|
| 96 |
+
"normalized": false,
|
| 97 |
+
"rstrip": false,
|
| 98 |
+
"single_word": false,
|
| 99 |
+
"special": true
|
| 100 |
+
},
|
| 101 |
+
"151655": {
|
| 102 |
+
"content": "<|image_pad|>",
|
| 103 |
+
"lstrip": false,
|
| 104 |
+
"normalized": false,
|
| 105 |
+
"rstrip": false,
|
| 106 |
+
"single_word": false,
|
| 107 |
+
"special": true
|
| 108 |
+
},
|
| 109 |
+
"151656": {
|
| 110 |
+
"content": "<|video_pad|>",
|
| 111 |
+
"lstrip": false,
|
| 112 |
+
"normalized": false,
|
| 113 |
+
"rstrip": false,
|
| 114 |
+
"single_word": false,
|
| 115 |
+
"special": true
|
| 116 |
+
},
|
| 117 |
+
"151657": {
|
| 118 |
+
"content": "<tool_call>",
|
| 119 |
+
"lstrip": false,
|
| 120 |
+
"normalized": false,
|
| 121 |
+
"rstrip": false,
|
| 122 |
+
"single_word": false,
|
| 123 |
+
"special": false
|
| 124 |
+
},
|
| 125 |
+
"151658": {
|
| 126 |
+
"content": "</tool_call>",
|
| 127 |
+
"lstrip": false,
|
| 128 |
+
"normalized": false,
|
| 129 |
+
"rstrip": false,
|
| 130 |
+
"single_word": false,
|
| 131 |
+
"special": false
|
| 132 |
+
},
|
| 133 |
+
"151659": {
|
| 134 |
+
"content": "<|fim_prefix|>",
|
| 135 |
+
"lstrip": false,
|
| 136 |
+
"normalized": false,
|
| 137 |
+
"rstrip": false,
|
| 138 |
+
"single_word": false,
|
| 139 |
+
"special": false
|
| 140 |
+
},
|
| 141 |
+
"151660": {
|
| 142 |
+
"content": "<|fim_middle|>",
|
| 143 |
+
"lstrip": false,
|
| 144 |
+
"normalized": false,
|
| 145 |
+
"rstrip": false,
|
| 146 |
+
"single_word": false,
|
| 147 |
+
"special": false
|
| 148 |
+
},
|
| 149 |
+
"151661": {
|
| 150 |
+
"content": "<|fim_suffix|>",
|
| 151 |
+
"lstrip": false,
|
| 152 |
+
"normalized": false,
|
| 153 |
+
"rstrip": false,
|
| 154 |
+
"single_word": false,
|
| 155 |
+
"special": false
|
| 156 |
+
},
|
| 157 |
+
"151662": {
|
| 158 |
+
"content": "<|fim_pad|>",
|
| 159 |
+
"lstrip": false,
|
| 160 |
+
"normalized": false,
|
| 161 |
+
"rstrip": false,
|
| 162 |
+
"single_word": false,
|
| 163 |
+
"special": false
|
| 164 |
+
},
|
| 165 |
+
"151663": {
|
| 166 |
+
"content": "<|repo_name|>",
|
| 167 |
+
"lstrip": false,
|
| 168 |
+
"normalized": false,
|
| 169 |
+
"rstrip": false,
|
| 170 |
+
"single_word": false,
|
| 171 |
+
"special": false
|
| 172 |
+
},
|
| 173 |
+
"151664": {
|
| 174 |
+
"content": "<|file_sep|>",
|
| 175 |
+
"lstrip": false,
|
| 176 |
+
"normalized": false,
|
| 177 |
+
"rstrip": false,
|
| 178 |
+
"single_word": false,
|
| 179 |
+
"special": false
|
| 180 |
+
},
|
| 181 |
+
"151665": {
|
| 182 |
+
"content": "<img>",
|
| 183 |
+
"lstrip": false,
|
| 184 |
+
"normalized": false,
|
| 185 |
+
"rstrip": false,
|
| 186 |
+
"single_word": false,
|
| 187 |
+
"special": true
|
| 188 |
+
},
|
| 189 |
+
"151666": {
|
| 190 |
+
"content": "</img>",
|
| 191 |
+
"lstrip": false,
|
| 192 |
+
"normalized": false,
|
| 193 |
+
"rstrip": false,
|
| 194 |
+
"single_word": false,
|
| 195 |
+
"special": true
|
| 196 |
+
},
|
| 197 |
+
"151667": {
|
| 198 |
+
"content": "<IMG_CONTEXT>",
|
| 199 |
+
"lstrip": false,
|
| 200 |
+
"normalized": false,
|
| 201 |
+
"rstrip": false,
|
| 202 |
+
"single_word": false,
|
| 203 |
+
"special": true
|
| 204 |
+
},
|
| 205 |
+
"151668": {
|
| 206 |
+
"content": "<quad>",
|
| 207 |
+
"lstrip": false,
|
| 208 |
+
"normalized": false,
|
| 209 |
+
"rstrip": false,
|
| 210 |
+
"single_word": false,
|
| 211 |
+
"special": true
|
| 212 |
+
},
|
| 213 |
+
"151669": {
|
| 214 |
+
"content": "</quad>",
|
| 215 |
+
"lstrip": false,
|
| 216 |
+
"normalized": false,
|
| 217 |
+
"rstrip": false,
|
| 218 |
+
"single_word": false,
|
| 219 |
+
"special": true
|
| 220 |
+
},
|
| 221 |
+
"151670": {
|
| 222 |
+
"content": "<ref>",
|
| 223 |
+
"lstrip": false,
|
| 224 |
+
"normalized": false,
|
| 225 |
+
"rstrip": false,
|
| 226 |
+
"single_word": false,
|
| 227 |
+
"special": true
|
| 228 |
+
},
|
| 229 |
+
"151671": {
|
| 230 |
+
"content": "</ref>",
|
| 231 |
+
"lstrip": false,
|
| 232 |
+
"normalized": false,
|
| 233 |
+
"rstrip": false,
|
| 234 |
+
"single_word": false,
|
| 235 |
+
"special": true
|
| 236 |
+
},
|
| 237 |
+
"151672": {
|
| 238 |
+
"content": "<box>",
|
| 239 |
+
"lstrip": false,
|
| 240 |
+
"normalized": false,
|
| 241 |
+
"rstrip": false,
|
| 242 |
+
"single_word": false,
|
| 243 |
+
"special": true
|
| 244 |
+
},
|
| 245 |
+
"151673": {
|
| 246 |
+
"content": "</box>",
|
| 247 |
+
"lstrip": false,
|
| 248 |
+
"normalized": false,
|
| 249 |
+
"rstrip": false,
|
| 250 |
+
"single_word": false,
|
| 251 |
+
"special": true
|
| 252 |
+
}
|
| 253 |
+
},
|
| 254 |
+
"additional_special_tokens": [
|
| 255 |
+
"<|im_start|>",
|
| 256 |
+
"<|im_end|>",
|
| 257 |
+
"<|object_ref_start|>",
|
| 258 |
+
"<|object_ref_end|>",
|
| 259 |
+
"<|box_start|>",
|
| 260 |
+
"<|box_end|>",
|
| 261 |
+
"<|quad_start|>",
|
| 262 |
+
"<|quad_end|>",
|
| 263 |
+
"<|vision_start|>",
|
| 264 |
+
"<|vision_end|>",
|
| 265 |
+
"<|vision_pad|>",
|
| 266 |
+
"<|image_pad|>",
|
| 267 |
+
"<|video_pad|>"
|
| 268 |
+
],
|
| 269 |
+
"bos_token": null,
|
| 270 |
+
"chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0]['role'] == 'system' %}\n {{- messages[0]['content'] }}\n {%- else %}\n {{- 'You are Qwen, created by Alibaba Cloud. You are a helpful assistant.' }}\n {%- endif %}\n {{- \"\\n\\n# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0]['role'] == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0]['content'] + '<|im_end|>\\n' }}\n {%- else %}\n {{- '<|im_start|>system\\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- for message in messages %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) or (message.role == \"assistant\" and not message.tool_calls) %}\n {{- '<|im_start|>' + message.role + '\\n' + message.content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" %}\n {{- '<|im_start|>' + message.role }}\n {%- if message.content %}\n {{- '\\n' + message.content }}\n {%- endif %}\n {%- for tool_call in message.tool_calls %}\n {%- if tool_call.function is defined %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '\\n<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {{- tool_call.arguments | tojson }}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- message.content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}\n",
|
| 271 |
+
"clean_up_tokenization_spaces": false,
|
| 272 |
+
"eos_token": "<|im_end|>",
|
| 273 |
+
"errors": "replace",
|
| 274 |
+
"model_max_length": 131072,
|
| 275 |
+
"pad_token": "<|endoftext|>",
|
| 276 |
+
"split_special_tokens": false,
|
| 277 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 278 |
+
"unk_token": null
|
| 279 |
+
}
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|