🤗 [EMOVA-Models](https://huggingface.co/collections/Emova-ollm/emova-models-67779d377bb8261e6057a320) | 🤗 [EMOVA-Datasets](https://huggingface.co/collections/Emova-ollm/emova-datasets-67779be7d02447a2d0891bf6) | 🤗 [EMOVA-Demo](https://huggingface.co/spaces/Emova-ollm/EMOVA-demo)
📄 [Paper](https://arxiv.org/abs/2409.18042) | 🌐 [Project-Page](https://emova-ollm.github.io/) | 💻 [Github](https://github.com/emova-ollm/EMOVA) | 💻 [EMOVA-Speech-Tokenizer-Github](https://github.com/emova-ollm/EMOVA_speech_tokenizer)
## Model Summary
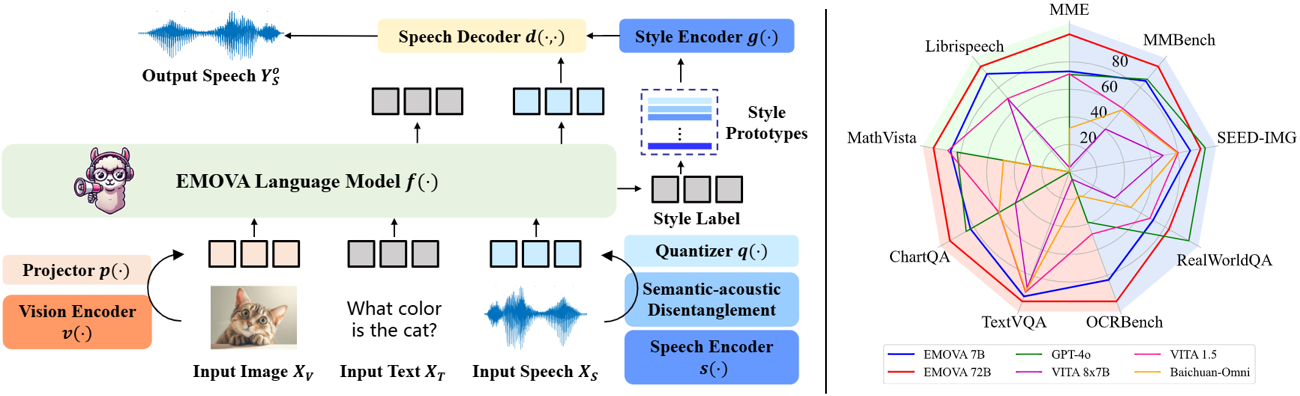
**EMOVA** (**EM**otionally **O**mni-present **V**oice **A**ssistant) is a novel end-to-end omni-modal LLM that can see, hear and speak without relying on external models. Given the omni-modal (i.e., textual, visual and speech) inputs, EMOVA can generate both textual and speech responses with vivid emotional controls by utilizing the speech decoder together with a style encoder. EMOVA possesses general omni-modal understanding and generation capabilities, featuring its superiority in advanced vision-language understanding, emotional spoken dialogue, and spoken dialogue with structural data understanding. We summarize its key advantages as:
- **State-of-the-art omni-modality performance**: EMOVA achieves state-of-the-art comparable results on both **vision-language** and **speech** benchmarks simultaneously. Our best performing model, **EMOVA-72B**, even surpasses commercial models including GPT-4o and Gemini Pro 1.5.
- **Emotional spoken dialogue**: A **semantic-acoustic disentangled** speech tokenizer and a lightweight **style control** module are adopted for seamless omni-modal alignment and diverse speech style controllability. EMOVA supports **bilingual (Chinese and English)** spoken dialogue with **24 speech style** controls (i.e., 2 speakers, 3 pitches and 4 emotions).
- **Diverse configurations**: We open-source 3 configurations, **EMOVA-3B/7B/72B**, to support omni-modal usage under different computational budgets. Check our [Model Zoo](https://huggingface.co/collections/Emova-ollm/emova-models-67779d377bb8261e6057a320) and find the best fit model for your computational devices!