|
|
--- |
|
|
datasets: |
|
|
- UCSC-VLAA/MedReason |
|
|
base_model: |
|
|
- II-Vietnam/Medical-SFT-Qwen2.5-7B-Instruct-24-april |
|
|
tags: |
|
|
- RL |
|
|
- Medical |
|
|
--- |
|
|
|
|
|
# II Medical Model |
|
|
|
|
|
## Dataset |
|
|
- Training: MedReason dataset, decontaminated with validation sets to prevent data leakage. |
|
|
- Validation: 10 distinct medical validation datasets used to evaluate model performance. |
|
|
|
|
|
## Evaluation Scores |
|
|
|
|
|
| Dataset | DS 1 | DS 2 | DS 3 | DS 4 | DS 5 | DS 6 | DS 7 | DS 8 | DS 9 | DS 10 | |
|
|
|---------|----------|----------|----------|----------|----------|----------|----------|----------|----------|-----------| |
|
|
| QWQ | - | - | - | - | - | - | - | - | - | - | |
|
|
| ... | - | - | - | - | - | - | - | - | - | - | |
|
|
| II-SFT | - | - | - | - | - | - | - | - | - | - | |
|
|
| II-SFT-DAPO | - | - | - | - | - | - | - | - | - | - | |
|
|
|
|
|
## Training Details |
|
|
|
|
|
Model: Fine-tuned on II-Vietnam/Medical-SFT-Qwen2.5-7B-Instruct-24-april. |
|
|
|
|
|
Algorithm: DAPO (GRPO-based adversarial estimator). |
|
|
|
|
|
Key Hyperparameters: |
|
|
- Max prompt length: 2048 tokens. |
|
|
- Max response length: 12288 tokens. |
|
|
- Overlong buffer: Enabled, 4096 tokens, penalty factor 1.0. |
|
|
- Clip ratios: Low 0.2, High 0.28. |
|
|
- Batch sizes: Train prompt 512, Generation prompt 1536, Mini-batch 32. |
|
|
- Responses per prompt: 16. |
|
|
- Temperature: 1.0, Top-p: 1.0, Top-k: -1 (vLLM rollout). |
|
|
- Learning rate: 1e-6, Warmup steps: 10, Weight decay: 0.1. |
|
|
- Epochs: 20, Nodes: 2, GPUs per node: 8. |
|
|
|
|
|
|
|
|
Optimization: |
|
|
- Loss aggregation: Token-mean. |
|
|
- Gradient clipping: 1.0. |
|
|
- Entropy coefficient: 0. |
|
|
- FSDP: Parameter and optimizer offloading enabled. |
|
|
- Sequence parallel size: 4. |
|
|
- Dynamic batch size: Enabled. |
|
|
|
|
|
|
|
|
Reward Model: |
|
|
- Overlong buffer enabled with penalty factor 1.0. |
|
|
- KL divergence in reward/loss: Disabled. |
|
|
|
|
|
|
|
|
Training reward score |
|
|
 |
|
|
|
|
|
Validation while training score |
|
|
 |
|
|
|
|
|
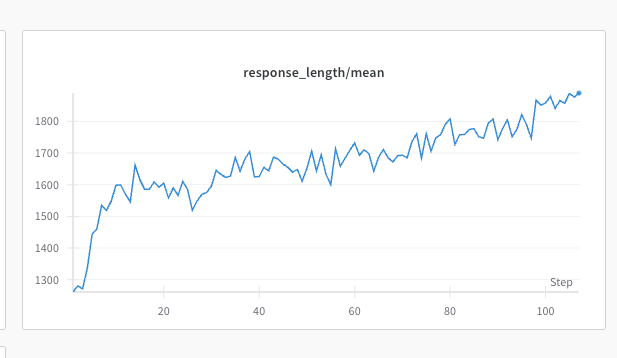
Response length |
|
|
 |

