Recommended Settings
- LoRA Strength: 1.0
- Embedded Guidance Scale: 6.0
- Flow Shift: 5.0
Trigger Words
The key trigger phrase is: s31lf13 taking a selfie with their younger self
Prompt Template
For prompting, check out the example prompts; this way of prompting seems to work very well.
ComfyUI Workflow
This LoRA works with a modified version of Kijai's Wan Video Wrapper workflow. The main modification is adding a Wan LoRA node connected to the base model.
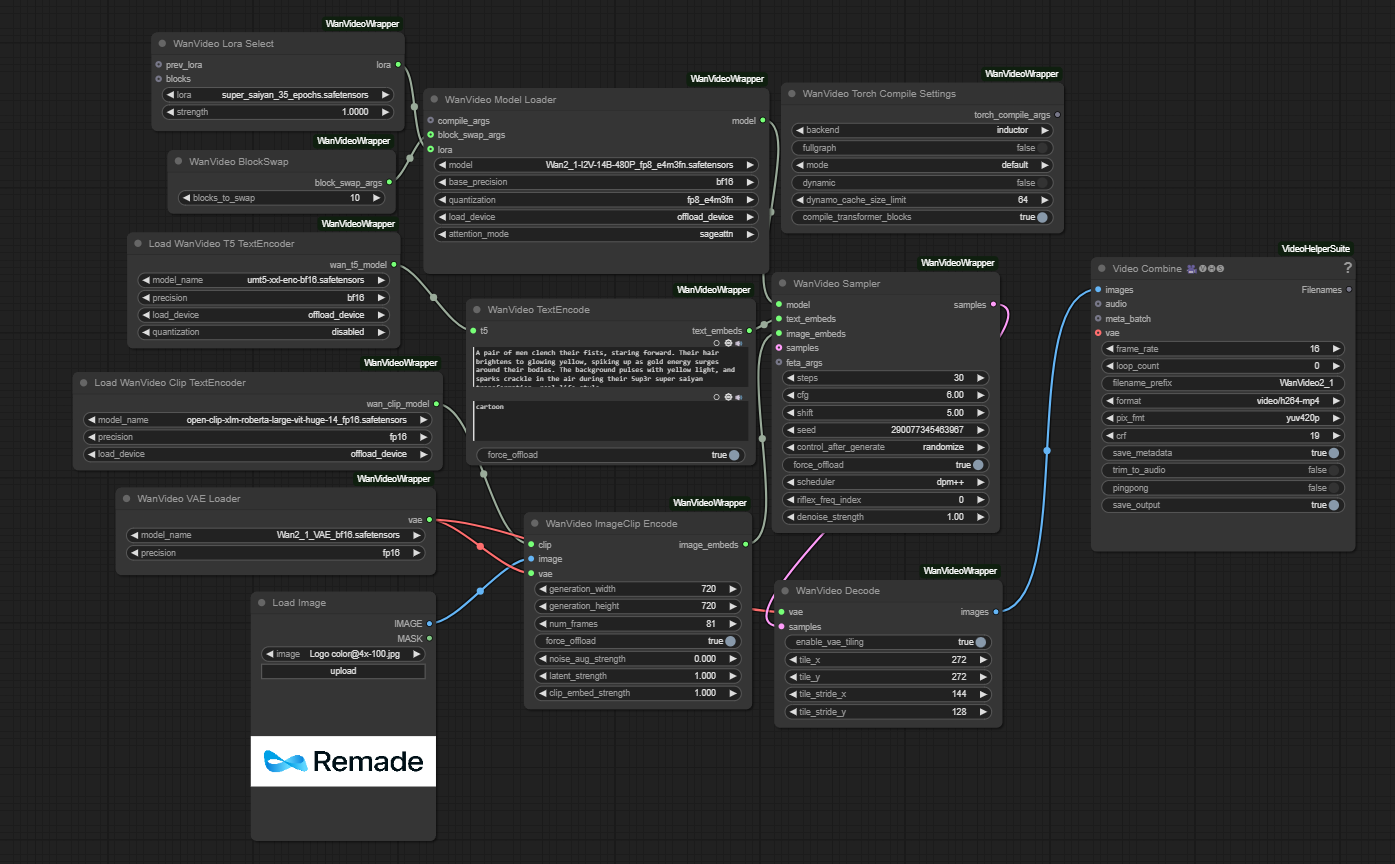
See the Downloads section above for the modified workflow.
Model Information
The model weights are available in Safetensors format. See the Downloads section above.
Training Details
- Base Model: Wan2.1 14B I2V 480p
- Training Data: Trained on 40 seconds of video comprised of 9 short clips (each clip captioned separately) of people taking a selfie with their younger self
- Epochs: 35
Additional Information
Training was done using Diffusion Pipe for Training
Acknowledgments
Special thanks to Kijai for the ComfyUI Wan Video Wrapper and tdrussell for the training scripts!