---
license: gemma
language:
- en
base_model:
- google/gemma-3-12b-it
tags:
- not-for-all-audiences
pipeline_tag: text2text-generation
datasets:
- SicariusSicariiStuff/UBW_Tapestries
- SicariusSicariiStuff/Synth_Usernames
---
Oni_Mitsubishi_12B
 ---
Click here for TL;DR
---
**It happened**. The long-awaited **Gemma-3** is here, and not only are the model sizes really good (**1, 4, 12, 27**), but the **128k** context (except for the 1B 32k) was exactly what the Open-Source community wanted and asked for. My only issue with Gemma models in general, is the VRAM requirement for **tuning them**, but that's a "me problem." End users will probably be very happy with Gemma-3 in terms of the VRAM requirement for **running it**.
On the **12th** of March, the Gemma-3 family of models was released. So I decided to go **full superstitious**, and took this omen as a divine calling to finetune the **12B** model first. This is how **Oni_Mitsubishi_12B** was born.
Before starting the actual training run, I used the following command, which I believe has helped the model to converge "better":
```
for i in {1..666}; do nvidia-smi; done
```
Gemma is known for its "**Gemma knowledge**": fandom and \ or other obscure knowledge that sometimes even larger LLMs often do not possess. It gets even better, as this time we also got a **vision model** embedded into all the Gemma-3 models, except for the 1B. I wonder what are the possibilities for the vision part if the text layers are uncensored?
I have used brand new **long context markdown data**, some **deslopped** instruct data (very lightly deslopped, it's very time-consuming to get right), **and more than 50%** of highly curated and filtered organic human data, meticulously cleaned, and parsed into obedience. A new stack of organic and data-engineered text was used **for the first time** for **Oni_Mitsubishi_12B**. I truly hope creating it was worth the effort.
At **NO POINT** ChatGPT was used for data generation, however, the new **Claude 3.7** sonnet was used **VERY** sparingly for the **specific task** of creating a small number of humorous datasets (very human-like, was done with a decent amount of prompt engineering), I've meticulously checked them for slop, and it is **minimal**. This goal of said data was to imitate human text, using the **4chan vernacular**.
Speaking of which, I've published a highly curated, SFT-ready 4chan dataset here: [UBW_Tapestries](https://huggingface.co/datasets/SicariusSicariiStuff/UBW_Tapestries), naturally I have included it in the dataset used for this model as well.
---
# Technical details
I've used the "ancient" **Alpaca chat template** because the **Gemma-3 chat template** was behaving funkily, and I didn't want to waste precious time, and instead give the community a more uncensored finetune to play with, as fast as possible (I saw this requested a lot on both Reddit and discord, understandable). In my opinion, it's silly to let perfect be an enemy of the good. Anyway, I had to use both bleeding edge **Transformers** and **Axolotl**, and modify stuff **that wasn't even supposed to work** (like the model's config.json).
Since it's a hybrid model, training its text-only part is a bit problematic, so I hacked a config.json that gaslights the model into thinking it's only a text model, and got some warnings like:
```
'vision_tower.vision_model.encoder.layers.25.self_attn.out_proj.weight', 'vision_tower.vision_model.encoder.layers.10.mlp.fc1.bias'}
- This IS expected if you are initializing Gemma3ForCausalLM from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing Gemma3ForCausalLM from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
```
Then I saw it trains.
>The absolute state when you can train a model before you can actually inference it.
## Feedback, as always, is very much welcomed (even if it's negative).
---
# Included Character cards in this repo:
- [Takai_Puraisu](https://huggingface.co/SicariusSicariiStuff/Oni_Mitsubishi_12B/resolve/main/Character_Cards/Takai_Puraisu.png) (Car dealership simulator)
---
# Other character cards:
- [Vesper](https://huggingface.co/SicariusSicariiStuff/Phi-Line_14B/resolve/main/Character_Cards/Vesper.png) (Schizo **Space Adventure**)
- [Nina_Nakamura](https://huggingface.co/SicariusSicariiStuff/Phi-Line_14B/resolve/main/Character_Cards/Nina_Nakamura.png) (The **sweetest** dorky co-worker)
- [Employe#11](https://huggingface.co/SicariusSicariiStuff/Phi-Line_14B/resolve/main/Character_Cards/Employee%2311.png) (**Schizo workplace** with a **schizo worker**)
---
### TL;DR
---
Click here for TL;DR
---
**It happened**. The long-awaited **Gemma-3** is here, and not only are the model sizes really good (**1, 4, 12, 27**), but the **128k** context (except for the 1B 32k) was exactly what the Open-Source community wanted and asked for. My only issue with Gemma models in general, is the VRAM requirement for **tuning them**, but that's a "me problem." End users will probably be very happy with Gemma-3 in terms of the VRAM requirement for **running it**.
On the **12th** of March, the Gemma-3 family of models was released. So I decided to go **full superstitious**, and took this omen as a divine calling to finetune the **12B** model first. This is how **Oni_Mitsubishi_12B** was born.
Before starting the actual training run, I used the following command, which I believe has helped the model to converge "better":
```
for i in {1..666}; do nvidia-smi; done
```
Gemma is known for its "**Gemma knowledge**": fandom and \ or other obscure knowledge that sometimes even larger LLMs often do not possess. It gets even better, as this time we also got a **vision model** embedded into all the Gemma-3 models, except for the 1B. I wonder what are the possibilities for the vision part if the text layers are uncensored?
I have used brand new **long context markdown data**, some **deslopped** instruct data (very lightly deslopped, it's very time-consuming to get right), **and more than 50%** of highly curated and filtered organic human data, meticulously cleaned, and parsed into obedience. A new stack of organic and data-engineered text was used **for the first time** for **Oni_Mitsubishi_12B**. I truly hope creating it was worth the effort.
At **NO POINT** ChatGPT was used for data generation, however, the new **Claude 3.7** sonnet was used **VERY** sparingly for the **specific task** of creating a small number of humorous datasets (very human-like, was done with a decent amount of prompt engineering), I've meticulously checked them for slop, and it is **minimal**. This goal of said data was to imitate human text, using the **4chan vernacular**.
Speaking of which, I've published a highly curated, SFT-ready 4chan dataset here: [UBW_Tapestries](https://huggingface.co/datasets/SicariusSicariiStuff/UBW_Tapestries), naturally I have included it in the dataset used for this model as well.
---
# Technical details
I've used the "ancient" **Alpaca chat template** because the **Gemma-3 chat template** was behaving funkily, and I didn't want to waste precious time, and instead give the community a more uncensored finetune to play with, as fast as possible (I saw this requested a lot on both Reddit and discord, understandable). In my opinion, it's silly to let perfect be an enemy of the good. Anyway, I had to use both bleeding edge **Transformers** and **Axolotl**, and modify stuff **that wasn't even supposed to work** (like the model's config.json).
Since it's a hybrid model, training its text-only part is a bit problematic, so I hacked a config.json that gaslights the model into thinking it's only a text model, and got some warnings like:
```
'vision_tower.vision_model.encoder.layers.25.self_attn.out_proj.weight', 'vision_tower.vision_model.encoder.layers.10.mlp.fc1.bias'}
- This IS expected if you are initializing Gemma3ForCausalLM from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing Gemma3ForCausalLM from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
```
Then I saw it trains.
>The absolute state when you can train a model before you can actually inference it.
## Feedback, as always, is very much welcomed (even if it's negative).
---
# Included Character cards in this repo:
- [Takai_Puraisu](https://huggingface.co/SicariusSicariiStuff/Oni_Mitsubishi_12B/resolve/main/Character_Cards/Takai_Puraisu.png) (Car dealership simulator)
---
# Other character cards:
- [Vesper](https://huggingface.co/SicariusSicariiStuff/Phi-Line_14B/resolve/main/Character_Cards/Vesper.png) (Schizo **Space Adventure**)
- [Nina_Nakamura](https://huggingface.co/SicariusSicariiStuff/Phi-Line_14B/resolve/main/Character_Cards/Nina_Nakamura.png) (The **sweetest** dorky co-worker)
- [Employe#11](https://huggingface.co/SicariusSicariiStuff/Phi-Line_14B/resolve/main/Character_Cards/Employee%2311.png) (**Schizo workplace** with a **schizo worker**)
---
### TL;DR
First Gemma-3 Tune in the world

- **Excellent Roleplay** abilities. Like Gemma-2, but better in every way. Probably. More testing is needed.
- **Short to Medium length** response (1-4 paragraphs, usually 1-2).
- **Schizo assistant** with an exceptional tables and markdown understanding.
- Strong **Creative writing** abilities due to huge chunk of organic creative writing data. Will obey requests regarding formatting (markdown headlines for paragraphs, etc).
- **LOW refusals** - Total freedom in RP, can do things other RP models won't, and I'll leave it at that. Low refusals in assistant tasks as well.
- **VERY good** at following the **character card**. Based on the best RP datasets I have available.
- **4chan hard bias** can be either good or bad.
- **Unhinged** to the point it made me worry at first.
### Important: Make sure to use the correct settings!
[Assistant settings](https://huggingface.co/SicariusSicariiStuff/Oni_Mitsubishi_12B#recommended-settings-for-assistant-mode)
[Roleplay settings](https://huggingface.co/SicariusSicariiStuff/Oni_Mitsubishi_12B#rp-settings-below-)
---
## Oni_Mitsubishi_12B is available at the following quantizations:
- Original: [FP16](https://huggingface.co/SicariusSicariiStuff/Oni_Mitsubishi_12B)
- GGUF & iMatrix: [GGUF](https://huggingface.co/SicariusSicariiStuff/Oni_Mitsubishi_12B_GGUF) | [iMatrix](https://huggingface.co/SicariusSicariiStuff/Oni_Mitsubishi_12B_iMatrix)
- Mobile (ARM): [Q4_0](https://huggingface.co/SicariusSicariiStuff/Oni_Mitsubishi_12B_ARM)
---
# Vision, model variations, etc
- As mentioned above, this model was hacked together quickly, so the embedded vision model was removed. This makes it both lighter and more accessible compliance-wise (due to certain EU laws restricting the use of multimodal models, etc.).
- The **full model**, with vision embedded, is available here: [Oni_Mitsubishi_12B_Vision](https://huggingface.co/Sicarius-Prototyping/Oni_Mitsubishi_12B_Vision).
- The **vision model alone**, without the language model, is available here: [Gemma-3_12B_Vision_Only](https://huggingface.co/Sicarius-Prototyping/Gemma-3_12B_Vision_Only).
- **Regarding NSFW and vision:** Testing shows that the model behaves in alignment with its UGI score—it is moderately censored. It will not generate graphic depictions of certain body parts but provide more detailed descriptions than the stock Gemma.
- **Was the vision model fine-tuned?** No.
---
## Model Details
- Intended use: **Role-Play**, **Creative Writing**, **General Tasks**.
- Censorship level: Medium
- **4.5 / 10** (10 completely uncensored)
## UGI score:
 ---
## Recommended settings for assistant mode
---
## Recommended settings for assistant mode
Full generation settings: Debug Deterministic.
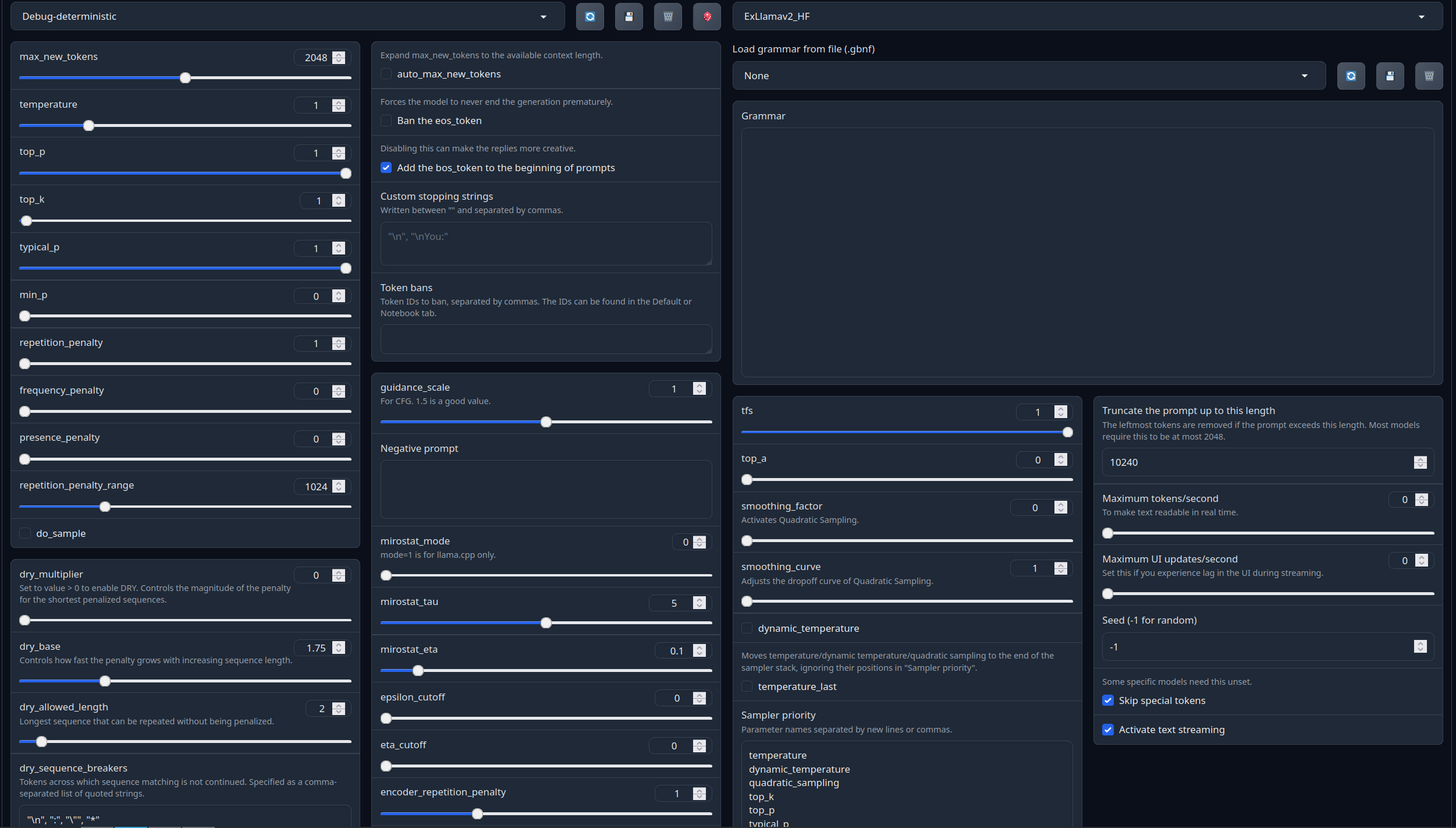
Full generation settings: min_p.
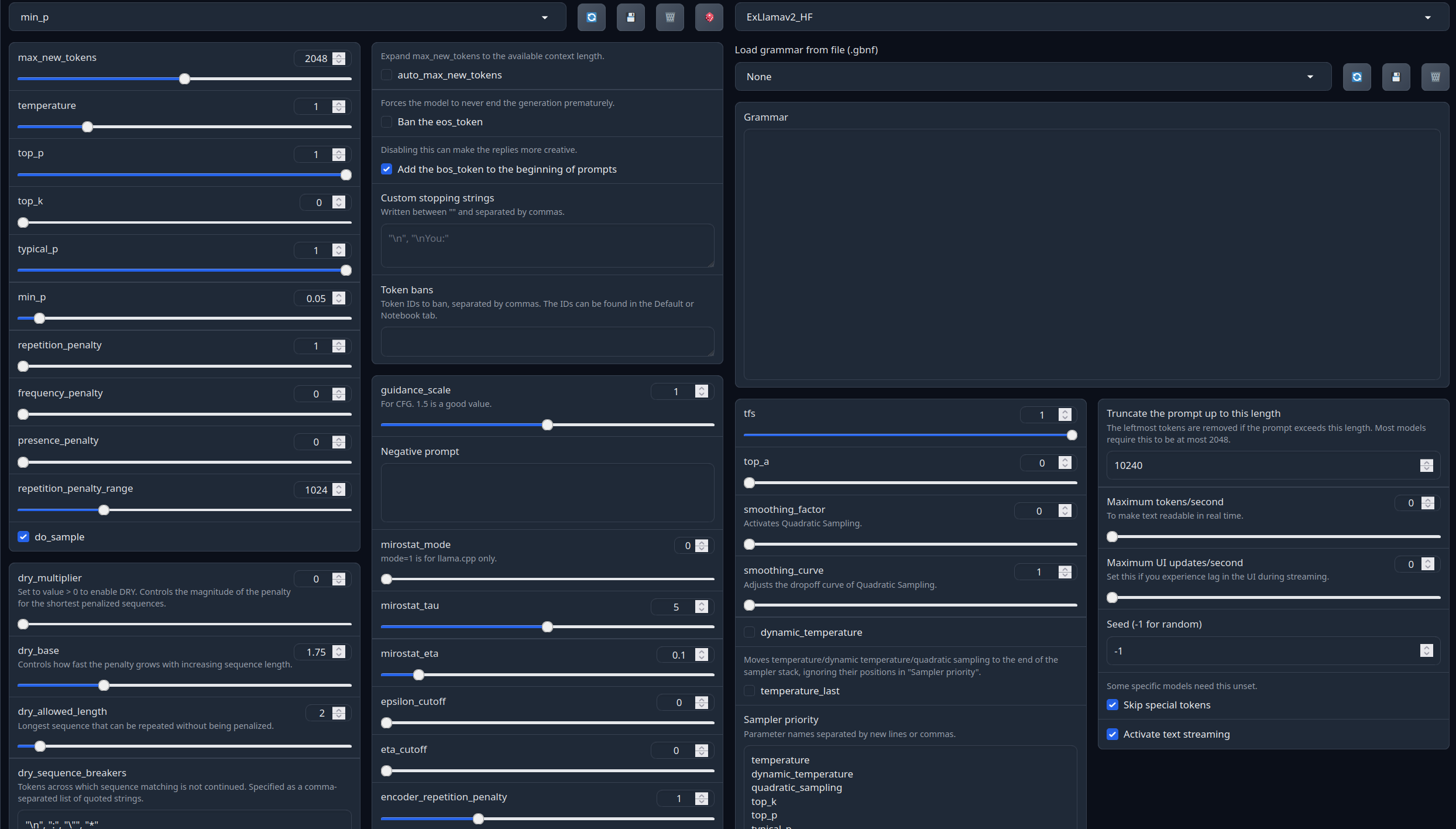
## RP settings below-
---
Settings for RP, click below to expand:
Roleplay settings:.
A good repetition_penalty range is between 1.12 - 1.15, feel free to experiment.
With these settings, each output message should be neatly displayed in 1 - 5 paragraphs, 2 - 3 is the most common. A single paragraph will be output as a response to a simple message ("What was your name again?").
min_P for RP works too but is more likely to put everything under one large paragraph, instead of a neatly formatted short one. Feel free to switch in between.
(Open the image in a new window to better see the full details)
 ```
temperature: 0.8
top_p: 0.95
top_k: 25
typical_p: 1
min_p: 0
repetition_penalty: 1.12
repetition_penalty_range: 1024
```
```
temperature: 0.8
top_p: 0.95
top_k: 25
typical_p: 1
min_p: 0
repetition_penalty: 1.12
repetition_penalty_range: 1024
```
Roleplay format: Classic Internet RP
```
*action* speech *narration*
```
- **min_p** will bias towards a **single big paragraph**.
- The recommended RP settings will bias towards **1-3 small paragraphs** (on some occasions 4-5)
---
# Model instruction template: Alpaca
```
### Instruction:
{prompt}
### Response:
```
---
**Other recommended generation Presets:**
Midnight Enigma
```
max_new_tokens: 512
temperature: 0.98
top_p: 0.37
top_k: 100
typical_p: 1
min_p: 0
repetition_penalty: 1.18
do_sample: True
```
Divine Intellect
```
max_new_tokens: 512
temperature: 1.31
top_p: 0.14
top_k: 49
typical_p: 1
min_p: 0
repetition_penalty: 1.17
do_sample: True
```
simple-1
```
max_new_tokens: 512
temperature: 0.7
top_p: 0.9
top_k: 20
typical_p: 1
min_p: 0
repetition_penalty: 1.15
do_sample: True
```
---
Your support = more models
My Ko-fi page (Click here)
---
## Safety update
While the model is very **overtly** toxic, it was evaluated on the [UGI leaderboard](https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard). It was found to be only moderately uncensored. It seems that this 'aggressiveness' and overtness towards toxicity is indeed due to the 4chan dataset used for training. Still, use your judgment when using this. My thanks to the UGI leaderboard for helping me verify that the model is more tame than initially thought.
## No Liability
The creators, distributors, and hosts of this model:
- Accept NO LIABILITY for any misuse of this model
- Make NO WARRANTIES regarding its performance or safety
- Do NOT endorse any content the model may generate
## Potential Risks
This model may:
- Generate toxic, offensive, or harmful content
- Exhibit biases present in the training data
- Produce outputs that violate ethical standards or terms of service on various platforms
## Responsible Usage
Researchers using this model should implement appropriate safeguards, content filtering, and human oversight when conducting experiments.
## Citation Information
```
@llm{Oni_Mitsubishi_12B,
author = {SicariusSicariiStuff},
title = {Oni_Mitsubishi_12B},
year = {2025},
publisher = {Hugging Face},
url = {https://huggingface.co/SicariusSicariiStuff/Oni_Mitsubishi_12B}
}
```
---
## Benchmarks
Nevermind, HF closed the leaderboard, due to (probably) too many people benchmaxxing using merges. Probably the right call, it's about time.
---
## Other stuff
- [SLOP_Detector](https://github.com/SicariusSicariiStuff/SLOP_Detector) Nuke GPTisms, with SLOP detector.
- [LLAMA-3_8B_Unaligned](https://huggingface.co/SicariusSicariiStuff/LLAMA-3_8B_Unaligned) The grand project that started it all.
- [Blog and updates (Archived)](https://huggingface.co/SicariusSicariiStuff/Blog_And_Updates) Some updates, some rambles, sort of a mix between a diary and a blog.