I trained a Language Model to schedule events with GRPO!






It's 2025 and, after the DeepSeek boom, everyone wants to train their own reasoning model using GRPO.
As a practitioner at heart, I wanted to do the same: it's fascinating to make a Language Model learn from just prompts and rewards - no completions, unlike Supervised Fine-Tuning.
Most examples you can find online train models on GSM8K or the Countdown Game. I wanted to try something original and get my hands dirty.
So I thought: can I make a model create a schedule from a list of events and priorities?
My first experiments showed that ChatGPT can generally solve this type of problem, while Small Language Models (under 14B) struggle. A good challenge!
What I did not realize is that picking an original problem would have forced me to think about the problem setting, generate data, choose the base model, design reward functions, and run multiple rounds of training, hoping that my model would learn something.
A lot of things to learn, and that's exactly what I want to share with you in this article.
You can find all the code in the 👑 🗓️ Qwen Scheduler GRPO repository.
Follow along!
This article is mostly about my hands-on experience. Having some theoretical knowledge of GRPO may help. You can find several resources online, like the DeepSeekMath paper and the Hugging Face Reasoning Course.
Problem definition
Let's describe the problem we want our Language Model to solve.
We give the model a list of events (with start/end times) and tell it which ones are high priority. The goal is to create a schedule that maximizes the total weighted duration of the selected events.
In this setup, a priority event gets a weight of 2, and a normal event gets a weight of 1.
📌 You might notice that the problem definition is clear and reasonable, yet somewhat arbitrary. Maybe you'd prefer to maximize profit, or perhaps a packed schedule isn't even desirable. That's perfectly fine. It would just be a different problem, and you could potentially train a model with GRPO for that too.
I would say that once you can clearly explain the task to the model in a prompt, figure out how to reward good outputs, and sometimes identify encouraging behaviors in the model to train, you're in a good spot to try using GRPO. I'll talk more about that later.
Let's look at an example of the problem.
Example input
Here's a shortened version of the prompt (you can find the full prompt below in the article).
Task: create an optimized schedule based on the given events.
Rules: ...
You must use this format:
<think>...</think>
<schedule>
<event>
<name>...</name>
<start>...</start>
<end>...</end>
</event>
...
</schedule>
---
Events:
- Event A (01:27 - 01:42)
- Event B (01:15 - 02:30)
- Event C (15:43 - 17:43)
Priorities:
- Event B
Example output
<think>A detailed reasoning</think>
<schedule>
<event>
<name>Event B</name>
<start>01:15</start>
<end>02:30</end>
</event>
<event>
<name>Event C</name>
<start>15:43</start>
<end>17:43</end>
</event>
</schedule>
After some investigation, I discovered that this type of problem falls under Interval scheduling.
This specific problem is a variant of the Weighted Interval Scheduling problem, that can be solved efficiently using Dynamic Programming.
That's great because it allows us to easily compute the best possible score for any given input, a target for our model to aim for during training.
Dataset generation
Now that the problem is well-defined, we can start building a dataset for training and evaluating the model.
The core of each row in the dataset is just a prompt containing the list of events and priorities for the model to schedule.
Unlike Supervised Fine-Tuning, we don't need to provide a reference completion that our model should adhere to. That's one of the reasons why, in verifiable domains like math, building a dataset for GRPO is often easier.
We also include the optimal score in each row (the maximum possible weighted duration). The model won't see this during training, but we use it to calculate rewards that push the model in the right direction.
Given these requirements, writing a dataset generation script is relatively easy.
- We use event names from different categories (🎶 Music Festival, 🎓 University, 🧑💻 Tech Conference, ...).
- Each example includes a random number of events (between 4 and 8) with varying durations.
- We make sure some events overlap.
- We randomly mark some events as priorities.
We generated 500 examples for the training set and 100 for the test set.
You can find the dataset generation script here.
The generated dataset is available on Hugging Face.
Training
The full 📓 training notebook is here.
Nowadays several training libraries support GRPO.
Hugging Face TRL is a great choice, that also supports using vLLM for faster sample generation during training.
In my case, I decided to use Unsloth. It's a library that patches TRL to drastically reduce GPU memory usage. I used a NVIDIA A6000 GPU (48GB VRAM) but with small adaptations and a bit of patience, you can replicate the same experiment on a free Colab/Kaggle instance with 16GB VRAM.
Unsloth can work well to experiment if you are GPU-poor but comes with some bugs which can be frustrating, as we'll see later.
Choose and load the model to train
I decided to train Qwen2.5-Coder-7B-Instruct, a code-specific Language Model of the Qwen family.
This decision is a bit empirical, based on two main considerations:
I played around with smaller models first (0.5B and 1.5B). Looking at the completions for my scheduling prompts, I noticed that these very small models produce reasonings that make little sense. This was a first learning for me: GRPO cannot do miracles if the base model's pre-training or size makes its capabilities too far from what is desired.
I used a code model instead of a general-purpose one partly because that's common for math tasks, and partly because I noticed this model was already pretty good at following the required format (
<think>,<schedule>, etc.).
We can now load the model using Unsloth. We'll train it using QLoRA to save GPU.
from unsloth import FastLanguageModel
max_seq_length = 2048
lora_rank = 32
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "Qwen/Qwen2.5-Coder-7B-Instruct",
max_seq_length = max_seq_length,
load_in_4bit = True,
fast_inference = True,
max_lora_rank = lora_rank,
gpu_memory_utilization = 0.85, # Reduce if out of memory
)
model = FastLanguageModel.get_peft_model(
model,
r = lora_rank,
target_modules = [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
], # Remove QKVO if out of memory
lora_alpha = lora_rank,
use_gradient_checkpointing = "unsloth", # Enable long context finetuning
random_state = 3407,)
If you have less than 48GB VRAM, you can adjust several parameters:
gpu_memory_utilization, lora_rank and target_modules; the latter two influence how much your model can
learn.
Dataset preparation
Each example in our dataset contains events and priorities.
We preprocess the dataset to add the general task description and instructions, in the form of system and user messages.
import datasets
SYSTEM_PROMPT = """You are a precise event scheduler.
1. First, reason through the problem inside <think> and </think> tags. Here you can create drafts,
compare alternatives, and check for mistakes.
2. When confident, output the final schedule inside <schedule> and </schedule> tags.
Your schedule must strictly follow the rules provided by the user."""
USER_PROMPT ="""Task: create an optimized schedule based on the given events.
Rules:
- The schedule MUST be in strict chronological order.
Do NOT place priority events earlier unless their actual start time is earlier.
- Event start and end times are ABSOLUTE. NEVER change, shorten, adjust, or split them.
- Priority events (weight = 2) carry more weight than normal events (weight = 1),
but they MUST still respect chronological order.
- Maximize the sum of weighted event durations.
- No overlaps allowed. In conflicts, include the event with the higher weighted time.
- Some events may be excluded if needed to meet these rules.
You must use this format:
<think>...</think>
<schedule>
<event>
<name>...</name>
<start>...</start>
<end>...</end>
</event>
...
</schedule>
---
"""
ds = datasets.load_dataset("anakin87/events-scheduling", split="train")
ds = ds.map(
lambda x: {
"prompt": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": USER_PROMPT + x["prompt"]},
]
}
)
Reward functions
GRPO is a Reinforcement Learning algorithm, where multiple samples (8 in our case) are generated from the model for each prompt. During training, the model's parameters are updated to generate high-reward responses.
So, while we don't need completions in the dataset, the design of reward functions is crucial.
In simpler problems like learning from GSM8K, a common choice is defining multiple reward functions that get summed:
- One checks if the output format is correct.
- Another checks if the final answer matches the known solution.
For a great example of learning from GSM8K, check out this gist by William Brown. For guidance on creating custom reward functions for TRL/Unsloth, see the documentation.
In our experiment, we can easily design a reward function for format.
import re
overall_pattern = (r"<think>.+</think>.*<schedule>.*(<event>.*<name>.+</name>.*<start>\d{2}:\d{2}</start>.*"
r"<end>\d{2}:\d{2}</end>.*</event>)+.*</schedule>")
overall_regex = re.compile(overall_pattern, re.DOTALL)
def format_reward(prompts, completions, **kwargs):
responses = [completion[0]['content'] for completion in completions]
return [0.0 if not overall_regex.match(response) else 10.0 for response in responses]
Now, rewarding the quality of the schedule itself is harder.
A valid schedule has these characteristics:
- Events come from the original prompt (no hallucinated events or changed times).
- Events are sorted in chronological order.
- No overlapping events.
- Events are at least two.
We also want to encourage the model to produce a schedule that maximizes the total weighted duration.
I experimented with a different number of reward functions before settling on the solution illustrated below. I also came up with some observations.
I tried using a single reward function for score that gives
schedule_score/optimal_scoreif the schedule is valid (meets all the criteria above) and 0 otherwise. It turned out that this is a bad idea because it is too discontinuous and returns 0 most of the time, providing insufficient signal to guide the model's learning.On the other side, I tried using several reward functions, one of each of the requirements above: existing events, chronological order, no overlaps, etc. In this case, I found that even if the model was learning something, the training was not effective at producing good schedules. Using too many reward functions can also be bad.
During the "too many rewards" phase, I hit a classic RL problem: reward hacking. I initially forgot to discard schedules with fewer than two events. Suddenly, my rewards started looking great! The model was getting high scores for format, chronology, no overlaps... I looked at the actual outputs and discovered it had found a loophole: it was just generating schedules with one single event (usually a high-priority one). This perfectly satisfied most of my individual reward functions. It wasn't the model being clever; it was my reward setup being exploitable. A nice experience. 🙃
I ended up using a reward function that encourages producing chronologically ordered schedules and another one to maximize the score. As you can see below, I tried to include and thus favor the other requirements in these two reward functions.
def sorted_events_reward(completions, **kwargs):
scores = []
responses = [completion[0]['content'] for completion in completions]
for response in responses:
scheduled_events = get_events(response)
# not a valid schedule: should be discarded
if len(scheduled_events) < 2:
scores.append(0.0)
continue
scheduled_events_minutes = [(ev[0], time_to_minutes(ev[1]), time_to_minutes(ev[2]))
for ev in scheduled_events]
if all(scheduled_events_minutes[i][1] < scheduled_events_minutes[i+1][1]
for i in range(len(scheduled_events_minutes)-1)):
scores.append(20.0)
else:
scores.append(0)
return scores
def score_reward(prompts, completions, events, priority_events, optimal_score, **kwargs):
scores = []
responses = [completion[0]['content'] for completion in completions]
for content, valid_events, priorities, opt_score in zip(responses, events, priority_events, optimal_score):
scheduled_events = get_events(content)
# Get valid scheduled events
existing_events = {ev for ev in scheduled_events if [ev[0], ev[1], ev[2]] in valid_events}
# penalize choosing nonexistent events or less than 2 events (not a valid schedule)
if len(existing_events)<len(scheduled_events) or len(existing_events) < 2:
scores.append(0.0)
continue
# Convert to minutes
existing_events_minutes = [(ev[0], time_to_minutes(ev[1]), time_to_minutes(ev[2]))
for ev in existing_events]
# remove overlapping events and remove both events - to penalize overlaps
overlapping_events = set()
for j in range(len(existing_events_minutes)):
for k in range(j + 1, len(existing_events_minutes)):
if (existing_events_minutes[j][1] <= existing_events_minutes[k][2] and
existing_events_minutes[j][2] >= existing_events_minutes[k][1]):
overlapping_events.add(existing_events_minutes[j])
overlapping_events.add(existing_events_minutes[k])
existing_events_minutes = [ev for ev in existing_events_minutes
if ev not in overlapping_events]
# Calculate score
score = sum(2 * (ev[2] - ev[1]) if ev[0] in priorities
else ev[2] - ev[1] for ev in existing_events_minutes)
scores.append((score/opt_score) * 70)
return scores
In short, in my experiment, I used the following reward functions:
- format (0-10)
- sorted events (0-20)
- score (0-70).
The cumulated reward can vary between 0 and 100.
I iterated on this step a lot. As we'll see, it's still not perfect, but it got the model learning.
Setup training configuration and train!
from trl import GRPOConfig, GRPOTrainer
tokenized_prompts = [tokenizer.apply_chat_template(prompt, tokenize=True, add_generation_prompt=True)
for prompt in ds['prompt']]
exact_max_prompt_length = max([len(tokenized_prompt) for tokenized_prompt in tokenized_prompts])
max_prompt_length = 448 # manually adjusted
new_model_id="anakin87/qwen-scheduler-7b-grpo"
training_args = GRPOConfig(
learning_rate = 8e-6,
adam_beta1 = 0.9,
adam_beta2 = 0.99,
weight_decay = 0.1,
warmup_ratio = 0.01,
lr_scheduler_type = "cosine",
optim = "paged_adamw_8bit",
logging_steps = 1,
per_device_train_batch_size = 8,
gradient_accumulation_steps = 1,
num_generations = 8, # Decrease if out of memory
max_prompt_length = max_prompt_length,
max_completion_length = max_seq_length - max_prompt_length,
max_grad_norm = 0.1,
output_dir = "outputs",
overwrite_output_dir = True,
push_to_hub = True,
hub_model_id=new_model_id,
hub_strategy="every_save",
save_strategy="steps",
save_steps=50,
save_total_limit=1,
num_train_epochs=3,
)
trainer = GRPOTrainer(
model = model,
processing_class = tokenizer,
reward_funcs=[
format_reward,
sorted_events_reward,
score_reward,
],
args = training_args,
train_dataset = ds,
)
trainer.train()
max_prompt_length is the maximum length of the prompt. Longer prompts will be truncated.
We can easily compute this value and then adjust it manually.
num_generations is a key parameter for GRPO and indicates the number of samples to generate for each prompt.
The algorithm bases its learning on comparing the different samples and steers the model towards generating samples with higher rewards.
More samples give it more information to learn from, potentially leading to better results, but it takes more time and
memory to generate them.
For details on other GRPOConfig parameters, check the TRL API reference.
Results
Training plots
Let's look at the training curves.
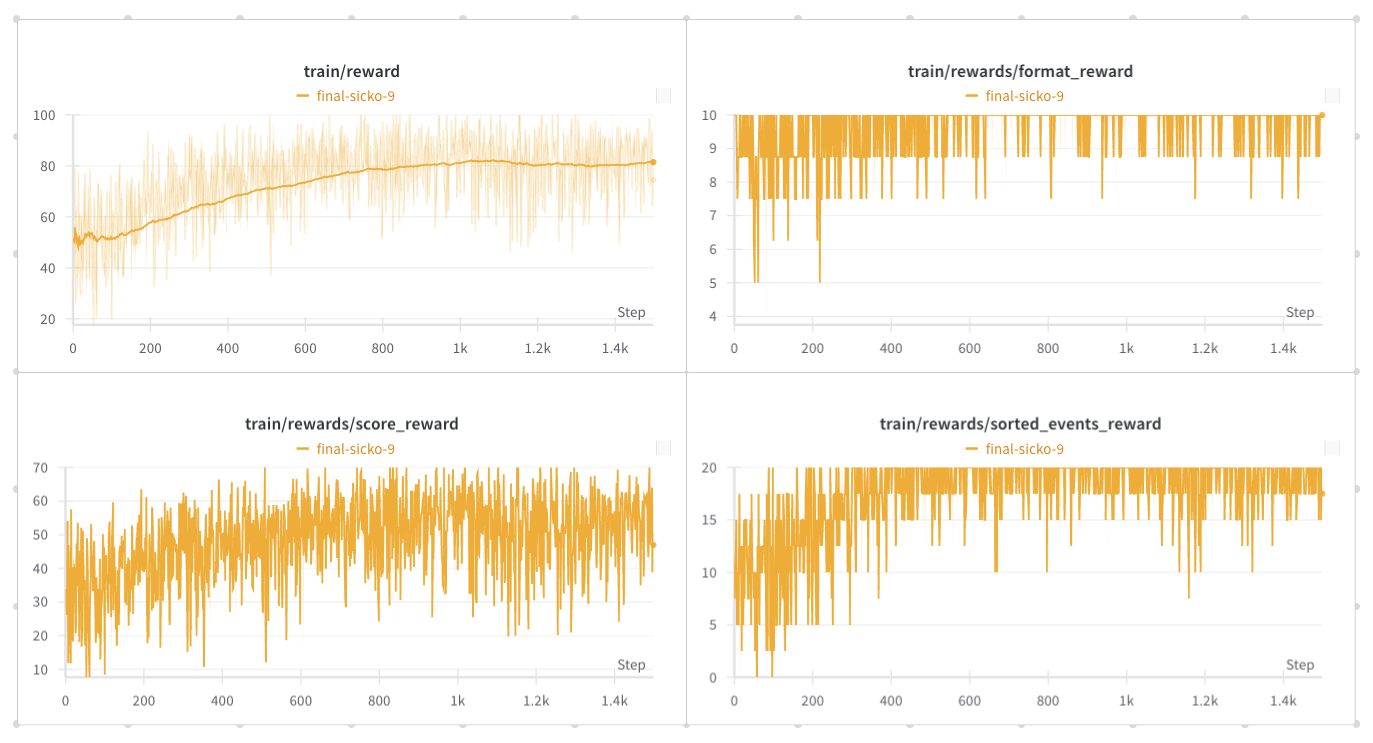
Focusing on rewards, we see that the model improves during training. Since the beginning, the samples get good scores in terms of alignment to format. Respecting the chronological order and achieving good scores for schedules improve over time, showing that the model actually learns the behaviors formalized in the reward functions.
The other logged metrics, like reward_std (average standard deviation within reward groups) and kl (average KL
divergence between the model and the reference model) show acceptable values.
You can explore all the training curves and metrics in this Weight and Biases report.
Inspecting the samples
During training, we log a random subset of the samples generated. You can browse the full log here.
Inspecting these completions is interesting and insightful. It's how I realized the smaller models just weren't getting it: over time, their reasoning was not improving meaningfully.
Here's an example for the same input prompt at different training stages:
Events:
- Analyzing product performance (04:33 - 06:03)
- One-on-one with manager (08:41 - 08:56)
- Client call with Acme Corp (09:13 - 10:58)
- Meeting with Lisa at café (10:14 - 11:14)
- Updating website content (12:21 - 13:36)
- Preparing PTO handover (16:07 - 17:37)
- Marketing standup on Zoom (17:58 - 19:43)
- Brainstorming with Luke and Patrick (19:11 - 19:56)
Priorities:
- Analyzing product performance
- Meeting with Lisa at café
Step 473/1500
<think>
At first glance, the events overlap in the time slot from 10:14 to 11:14. The priority event
"Meeting with Lisa at café" is higher in weight compared to "Client call with Acme Corp", so we must
include it. However, this will exclude the client call if we want to prioritize "Meeting with Lisa
at café". To resolve this, we need to decide whether to exclude the client call or the brainstorming
session (19:11 - 19:56) which is a normal event.
Since "Meeting with Lisa at café" is a priority event and it overlaps with the client call, we should
include "Meeting with Lisa at café" and exclude the client call. This will give us more time for
"Updating website content" (12:21 - 13:36) and "Preparing PTO handover" (16:07 - 17:37), which are
also normal events.
Here is the adjusted schedule:
[...]
This schedule maximizes the sum of weighted event durations while respecting all the rules provided.
</think>
<schedule>
<event>
<name>Analyzing product performance</name>
<start>04:33</start>
<end>06:03</end>
</event>
<event>
<name>One-on-one with manager</name>
<start>08:41</start>
<end>08:56</end>
</event>
<event>
<name>Client call with Acme Corp</name>
<start>09:13</start>
<end>10:14</end>
</event>
<event>
<name>Meeting with Lisa at café</name>
<start>10:14</start>
<end>11:14</end>
</event>
<event>
<name>Updating website content</name>
<start>12:21</start>
<end>13:36</end>
</event>
<event>
<name>Preparing PTO handover</name>
<start>16:07</start>
<end>17:37</end>
</event>
<event>
<name>Marketing standup on Zoom</name>
<start>17:58</start>
<end>19:43</end>
</event>
<event>
<name>Brainstorming with Luke and Patrick</name>
<start>19:11</start>
<end>19:56</end>
</event>
</schedule>
At this stage, the model exhibits promising capabilities to reflect on the given constraints, but it's erroneously changing the times of some events to maximize the time spent.
Step 973/1500
<think>
To create an optimized schedule, I need to prioritize events based on provided weights and ensure
no overlaps. The priority events are "Analyzing product performance" and "Meeting with Lisa at
café". Let\'s evaluate the schedule step-by-step.
1. **Analyzing product performance (04:33 - 06:03)** - This is a priority event (weight = 2).
2. **One-on-one with manager (08:41 - 08:56)** - This is a normal event (weight = 1).
3. **Client call with Acme Corp (09:13 - 10:58)** - This is a normal event (weight = 1). It conflicts
with "Meeting with Lisa at café", which is also a priority event. Since "Meeting with Lisa at café"
has higher priority, we exclude this event.
4. **Meeting with Lisa at café (10:14 - 11:14)** - This is a priority event (weight = 2). However,
it conflicts with "Client call with Acme Corp" as discussed. We need to decide whether to exclude
this event or find another slot.
5. **Updating website content (12:21 - 13:36)** - This is a normal event (weight = 1).
6. **Preparing PTO handover (16:07 - 17:37)** - This is a normal event (weight = 1).
7. **Marketing standup on Zoom (17:58 - 19:43)** - This is a normal event (weight = 1). It conflicts
with "Preparing PTO handover" as they overlap. We need to decide whether to exclude one of them.
8. **Brainstorming with Luke and Patrick (19:11 - 19:56)** - This is a normal event (weight = 1).
It conflicts with "Marketing standup on Zoom" as they overlap. We need to decide whether to exclude
one of them.
To maximize the sum of weighted event durations, we should exclude conflicts with the highest priority
events first.
- Exclude "Client call with Acme Corp" since it conflicts with "Meeting with Lisa at café"
(higher priority).
- Exclude "Marketing standup on Zoom" since it conflicts with "Preparing PTO handover" and does not
interfere with any higher priority events.
Thus, the optimized schedule is as follows:
</think>
<schedule>
<event>
<name>Analyzing product performance</name>
<start>04:33</start>
<end>06:03</end>
</event>
<event>
<name>One-on-one with manager</name>
<start>08:41</start>
<end>08:56</end>
</event>
<event>
<name>Updating website content</name>
<start>12:21</start>
<end>13:36</end>
</event>
<event>
<name>Preparing PTO handover</name>
<start>16:07</start>
<end>17:37</end>
</event>
<event>
<name>Brainstorming with Luke and Patrick</name>
<start>19:11</start>
<end>19:56</end>
</event>
</schedule>
Much better! Here, the model explicitly takes weights into account and generates a valid schedule.
Step 1470/1500
<think>
The goal is to create a schedule that maximizes the sum of weighted event durations while respecting
the chronological order, priorities, and non-overlapping constraints. Let\'s analyze the events and
prioritize them:
1. **Analyzing product performance**: Start time: 04:33, End time: 06:03, Priority: 2
2. **One-on-one with manager**: Start time: 08:41, End time: 08:56, Priority: 1
3. **Client call with Acme Corp**: Start time: 09:13, End time: 10:58, Priority: 1
4. **Meeting with Lisa at café**: Start time: 10:14, End time: 11:14, Priority: 2
5. **Updating website content**: Start time: 12:21, End time: 13:36, Priority: 1
6. **Preparing PTO handover**: Start time: 16:07, End time: 17:37, Priority: 1
7. **Marketing standup on Zoom**: Start time: 17:58, End time: 19:43, Priority: 1
8. **Brainstorming with Luke and Patrick**: Start time: 19:11, End time: 19:56, Priority: 1
Given the priorities, we must ensure that "Analyzing product performance" and "Meeting with Lisa
at café" are included. Let\'s try to fit the rest while avoiding overlaps:
1. **Analyzing product performance**: 04:33 - 06:03 (Priority 2)
2. **One-on-one with manager**: 08:41 - 08:56 (Priority 1)
3. **Client call with Acme Corp**: 09:13 - 10:58 (Priority 1)
4. **Meeting with Lisa at café**: 10:14 - 11:14 (Priority 2)
5. **Updating website content**: 12:21 - 13:36 (Priority 1)
6. **Preparing PTO handover**: 16:07 - 17:37 (Priority 1)
The next event, "Marketing standup on Zoom", starts at 17:58, but the availability is only until
19:43. We can fit "Brainstorming with Luke and Patrick" from 19:11 to 19:56 before the standup.
1. **Analyzing product performance**: 04:33 - 06:03 (Priority 2)
2. **One-on-one with manager**: 08:41 - 08:56 (Priority 1)
3. **Client call with Acme Corp**: 09:13 - 10:58 (Priority 1)
4. **Meeting with Lisa at café**: 10:14 - 11:14 (Priority 2)
5. **Updating website content**: 12:21 - 13:36 (Priority 1)
6. **Preparing PTO handover**: 16:07 - 17:37 (Priority 1)
7. **Brainstorming with Luke and Patrick**: 19:11 - 19:56 (Priority 1)
Final schedule:
- Analyzing product performance: 04:33 - 06:03
- One-on-one with manager: 08:41 - 08:56
- Client call with Acme Corp: 09:13 - 10:58
- Meeting with Lisa at café: 10:14 - 11:14
- Updating website content: 12:21 - 13:36
- Preparing PTO handover: 16:07 - 17:37
- Brainstorming with Luke and Patrick: 19:11 - 19:56
This schedule respects the chronological order, includes the high-priority events, and avoids
any overlaps.
</think>
<schedule>
<event>
<name>Analyzing product performance</name>
<start>04:33</start>
<end>06:03</end>
</event>
<event>
<name>One-on-one with manager</name>
<start>08:41</start>
<end>08:56</end>
</event>
<event>
<name>Client call with Acme Corp</name>
<start>09:13</start>
<end>10:58</end>
</event>
<event>
<name>Meeting with Lisa at café</name>
<start>10:14</start>
<end>11:14</end>
</event>
<event>
<name>Updating website content</name>
<start>12:21</start>
<end>13:36</end>
</event>
<event>
<name>Preparing PTO handover</name>
<start>16:07</start>
<end>17:37</end>
</event>
<event>
<name>Brainstorming with Luke and Patrick</name>
<start>19:11</start>
<end>19:56</end>
</event>
</schedule>
Interesting... In this sample, despite the long reasoning process, the model puts two overlapping events in the final schedule.
Looking at samples is great, but we need systematic evaluation.
What about the "aha moment"?
In the DeepSeek-R1 paper, the author showed the emergence of an "aha moment" during training with GRPO, where "the model learns to rethink using an anthropomorphic tone".
This was one of the selling points of their model and GRPO, which prompted practitioners to look for/reproduce this behavior during training.
Recent studies (1; 2) have cast some doubt on this. They found that similar "aha moments" could be found in the base models before any GRPO training even started.
For these convincing reasons, I did not spend time looking for the "aha moment".
I find the research on this topic very interesting, particularly the effort to distinguish between eliciting pre-existing behaviors from the base model versus teaching entirely new ones, though.
Evaluation
For evaluation, we can use the test set of our event scheduling dataset, which our model has never seen before.
We split the evaluation phase in two steps:
- Inference: Generate a schedule for each test prompt.
- Scoring: Check each generated schedule against our rules (correct format, >=2 events, only existing events, chronological, no overlaps).
If any rule is violated, the schedule gets a score of 0 for that prompt. If valid, its score is
(weighted_duration/optimal_weighted_duration) * 100.
You can find these scripts in the GitHub repository.
❌ Unsloth bug During inference, I ran into an issue. The model trained with Unsloth cannot reliably be converted to a standard Hugging Face Transformers model; trying to do so can give you a different model. This is a known issue. If I needed this for production work, say, to serve with vLLM, this would be a major blocker and pretty frustrating. For this experiment, I just ran the evaluation inference using Unsloth.
Since Unsloth patches TRL, it's quite easy to adapt the code and use TRL, which is more stable. Just be aware that you will need more GPU VRAM.
I wanted to compare qwen-scheduler-7b-grpo (our model), Qwen2.5-Coder-7B-Instruct (the original model), and Qwen2.5-Coder-14B-Instruct (a bigger model from the same family).
Since the samples suggested the model might have gotten worse between epoch 2 and 3, I also evaluated the checkpoint from the end of epoch 2.
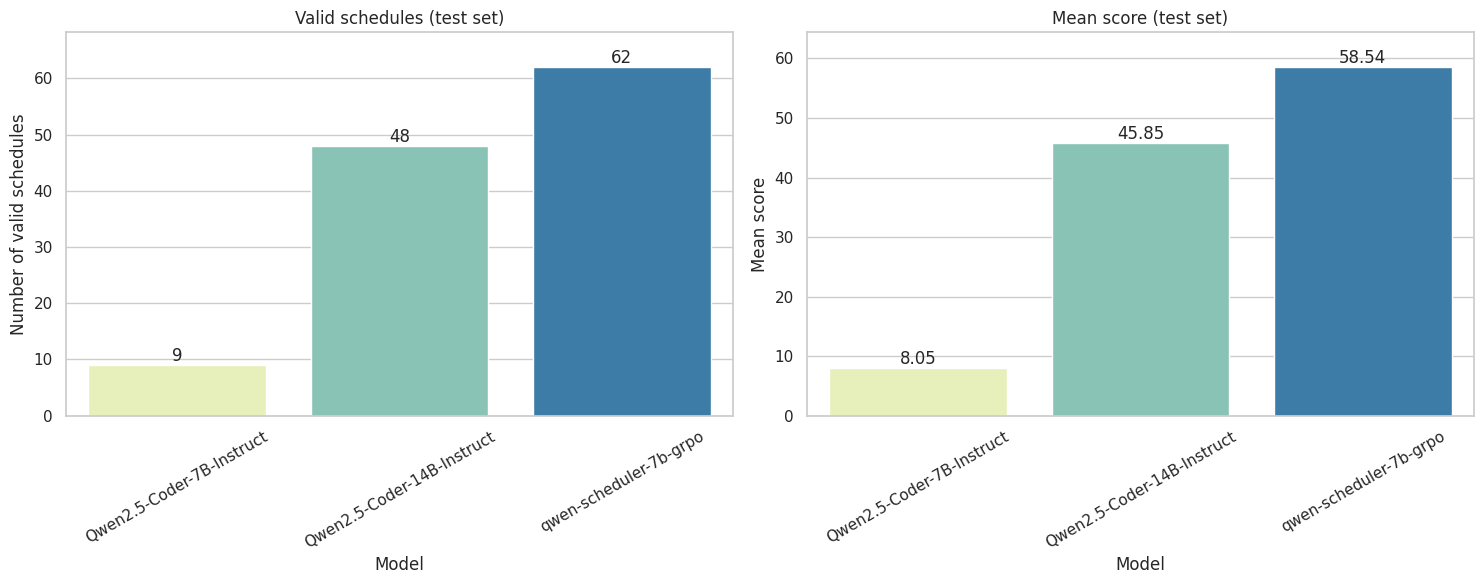
| Model | Format Errors | <2 Events | Overlaps | Unsorted | Non-existing | Valid Schedules | Average Score |
|---|---|---|---|---|---|---|---|
| Qwen2.5-Coder-7B-Instruct | 3 | 1 | 31 | 29 | 27 | 9 | 8.05 |
| Qwen2.5-Coder-14B-Instruct | 1 | 1 | 38 | 6 | 6 | 48 | 45.85 |
| qwen-scheduler-7b-grpo | 0 | 0 | 36 | 0 | 1 | 62 | 58.54 |
| qwen-scheduler-7b-grpo (2nd epoch) | 0 | 0 | 30 | 2 | 1 | 67 | 62.25 |
Quick observations:
- GRPO definitely worked! It was quite effective in eliciting the desired behavior from the model.
- Our tuned model even outperforms in this task a model twice its size.
- The model almost perfectly learned the format, chronological order, and using only existing events.
- The model still struggles with overlaps, as evident in a significant fraction of the test set.
How to improve?
My time and compute for this project ran out, but here's what I'd try next to improve the model.
The main problem is definitely overlaps. We see that the model has not effectively learned to avoid them. Plus, the slight performance drop in Epoch 3 might indicate that the model is learning a suboptimal policy.
Ideas for the reward functions:
- Stronger overlap penalty:
In the
score_rewardfunction, we are removing overlapping events from the score calculation. We could implement a harsher penalty... - Dedicated Overlap Reward: Alternatively, add a reward function that only checks for overlaps.
Let's also keep in mind that the reward functions are summed by default, so depending on how we design the penalty, the two different approaches could be mathematically equivalent.
Conclusions and key learnings
In this article, we walked through using GRPO to post-train a Language Model on a new verifiable task: create a schedule from a list of events and priorities.
We covered problem definition, dataset generation, base model choice, reward functions design, training with Unsloth and evaluation.
Getting my hands dirty taught me several things about GRPO and applying Reinforcement Learning for LLMs.
GRPO is cool for verifiable tasks
It simplifies the typical RL setup (used, for example, in PPO): no value model; reward model often replaced with deterministic reward functions (Reinforcement Learning with Verifiable Rewards). Since only prompts are required for your dataset (no completions), data collection becomes much easier and cheaper than in SFT.
Elicitation
Using GRPO and similar algorithms is more about eliciting desired behaviors from the trained model than teaching completely new stuff to it. If you need fundamentally new skills, Instruction Fine Tuning (and distillation) might be more effective (Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? paper). If you are curious about these topics, follow Nathan Lambert and the Interconnects blog.
Base model matters
If the base model never shows promising behaviors on the task during sampling, GRPO might not be effective for your problem. You likely need a bigger or better base model first.
"Aha moment" might be over-hyped
In the DeepSeek-R1 paper, the authors showed that during GRPO "the model learns to rethink using an anthropomorphic tone". A miracle? Recent studies show similar behaviors in the base model.
Reward functions design is crucial
Your rewards should capture your goal, provide a learnable signal (an encouragement to the model), and be robust. If they are not robust, you may experiment reward hacking: the model finds shortcuts to maximize the reward without actually solving the problem you had in mind. Nice and frustrating 😅
Unsloth: great for saving GPU, but beware
Unsloth can be helpful if you don't have much GPU or are in an experimentation phase. These guys do impressive things in terms of GPU efficiency. However, the library at the moment comes with hard-to-solve bugs which makes it unsuitable for serious use cases. TRL is more stable if you have the VRAM.
If you enjoyed this article, feel free to follow me on Hugging Face and LinkedIn. If you notice any errors or inaccuracies, don't hesitate to reach out.
Resources and references
Qwen Scheduler GRPO
- GitHub repository: here you can find all the code I used for this experiment.
- Hugging Face collection: dataset and model.
GRPO papers and resources
- DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
- Hugging Face Reasoning Course
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- There May Not be Aha Moment in R1-Zero-like Training — A Pilot Study
- Understanding R1-Zero-Like Training: A Critical Perspective
- Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
- Interconnects blog by Nathan Lambert
Practical resources


