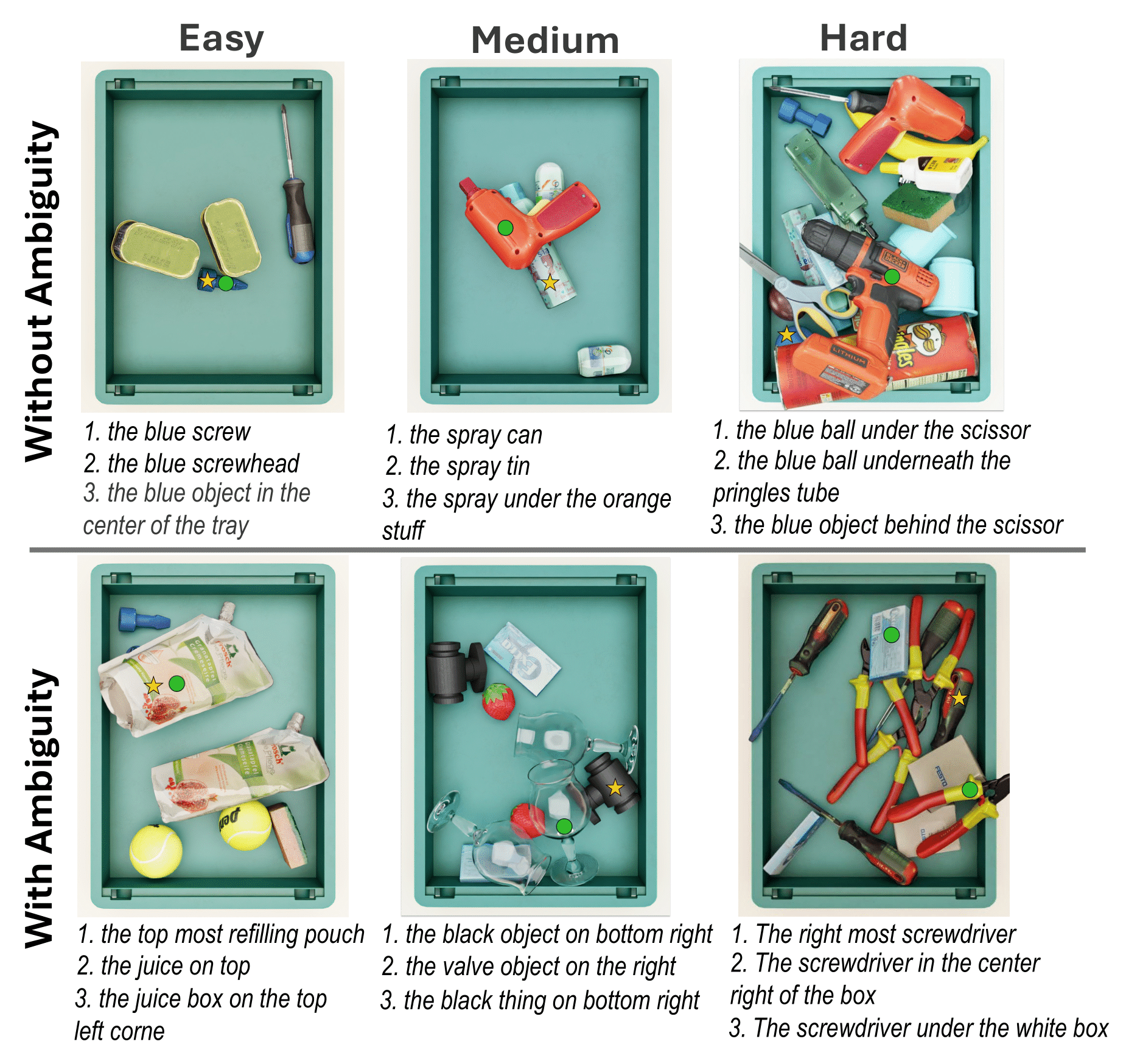
 Examples of FreeGraspData at different task difficulties with three user-provided instructions. Star indicates the target object, and green circle indicates the ground-truth objects to pick.
We introduce the ree-from language grasping dataset (FreeGraspDat), a novel dataset built upon MetaGraspNetv2 (1) to evaluate the robotic grasping task with free-form language instructions.
MetaGraspNetv2 is a large-scale simulated dataset featuring challenging aspects of robot vision in the bin-picking setting, including multi-view RGB-D images and metadata, eg object categories, amodal segmentation masks, and occlusion graphs indicating occlusion relationships between objects from each viewpoint.
To build FreeGraspDat, we selected scenes containing at least four objects to ensure sufficient scene clutter.
FreeGraspDat extends MetaGraspNetV2 in three aspects:
- i) we derive the ground-truth grasp sequence until reaching the target object from the occlusion graphs,
- ii) we categorize the task difficulty based on the obstruction level and instance ambiguity
- iii) we provide free-form language instructions, collected from human annotators.
**Ground-truth grasp sequence**
We obtain the ground-truth grasp sequence based on the object occlusion graphs provided in MetaGraspNetV2.
As the visual occlusion does not necessarily indicate obstruction, we thus first prune the edges in the provided occlusion graph that are less likely to form obstruction. Following the heuristic that less occlusion indicates less chance of obstruction, we remove the edges where the percentage of the occlusion area of the occluded object is below $1\%$.
From the node representing the target object, we can then traverse the pruned graph to locate the leaf node, that is the ground-truth object to grasp first. The sequence from the leaf node to the target node forms the correct sequence for the robotic grasping task.
**Grasp Difficulty Categorization**
We use the pruned occlusion graph to classify the grasping difficulty of target objects into three levels:
- **Easy**: Unobstructed target objects (leaf nodes in the pruned occlusion graph).
- **Medium**: Objects obstructed by at least one object (maximum hop distance to leaf nodes is 1).
- **Hard**: Objects obstructed by a chain of other objects (maximum hop distance to leaf nodes is more than 1).
Objects are labeled as **Ambiguous** if multiple instances of the same class exist in the scene.
This results in six robotic grasping difficulty categories:
- **Easy without Ambiguity**
- **Medium without Ambiguity**
- **Hard without Ambiguity**
- **Easy with Ambiguity**
- **Medium with Ambiguity**
- **Hard with Ambiguity**
**Free-form language user instructions**
For each of the six difficulty categories, we randomly select 50 objects, resulting in 300 robotic grasping scenarios.
For each scenario, we provide multiple users with a top-down image of the bin and a visual indicator highlighting the target object.
No additional context or information about the object is provided.
We instruct the user to provide an unambiguous natural language description of the indicated object with their best effort.
In total, ten users are involved in the data collection procedure, with a wide age span. %and a balanced gender distribution.
We randomly select three user instructions for each scenario, yielding a total of 900 evaluation scenarios.
This results in diverse language instructions.
Examples of FreeGraspData at different task difficulties with three user-provided instructions. Star indicates the target object, and green circle indicates the ground-truth objects to pick.
We introduce the ree-from language grasping dataset (FreeGraspDat), a novel dataset built upon MetaGraspNetv2 (1) to evaluate the robotic grasping task with free-form language instructions.
MetaGraspNetv2 is a large-scale simulated dataset featuring challenging aspects of robot vision in the bin-picking setting, including multi-view RGB-D images and metadata, eg object categories, amodal segmentation masks, and occlusion graphs indicating occlusion relationships between objects from each viewpoint.
To build FreeGraspDat, we selected scenes containing at least four objects to ensure sufficient scene clutter.
FreeGraspDat extends MetaGraspNetV2 in three aspects:
- i) we derive the ground-truth grasp sequence until reaching the target object from the occlusion graphs,
- ii) we categorize the task difficulty based on the obstruction level and instance ambiguity
- iii) we provide free-form language instructions, collected from human annotators.
**Ground-truth grasp sequence**
We obtain the ground-truth grasp sequence based on the object occlusion graphs provided in MetaGraspNetV2.
As the visual occlusion does not necessarily indicate obstruction, we thus first prune the edges in the provided occlusion graph that are less likely to form obstruction. Following the heuristic that less occlusion indicates less chance of obstruction, we remove the edges where the percentage of the occlusion area of the occluded object is below $1\%$.
From the node representing the target object, we can then traverse the pruned graph to locate the leaf node, that is the ground-truth object to grasp first. The sequence from the leaf node to the target node forms the correct sequence for the robotic grasping task.
**Grasp Difficulty Categorization**
We use the pruned occlusion graph to classify the grasping difficulty of target objects into three levels:
- **Easy**: Unobstructed target objects (leaf nodes in the pruned occlusion graph).
- **Medium**: Objects obstructed by at least one object (maximum hop distance to leaf nodes is 1).
- **Hard**: Objects obstructed by a chain of other objects (maximum hop distance to leaf nodes is more than 1).
Objects are labeled as **Ambiguous** if multiple instances of the same class exist in the scene.
This results in six robotic grasping difficulty categories:
- **Easy without Ambiguity**
- **Medium without Ambiguity**
- **Hard without Ambiguity**
- **Easy with Ambiguity**
- **Medium with Ambiguity**
- **Hard with Ambiguity**
**Free-form language user instructions**
For each of the six difficulty categories, we randomly select 50 objects, resulting in 300 robotic grasping scenarios.
For each scenario, we provide multiple users with a top-down image of the bin and a visual indicator highlighting the target object.
No additional context or information about the object is provided.
We instruct the user to provide an unambiguous natural language description of the indicated object with their best effort.
In total, ten users are involved in the data collection procedure, with a wide age span. %and a balanced gender distribution.
We randomly select three user instructions for each scenario, yielding a total of 900 evaluation scenarios.
This results in diverse language instructions.
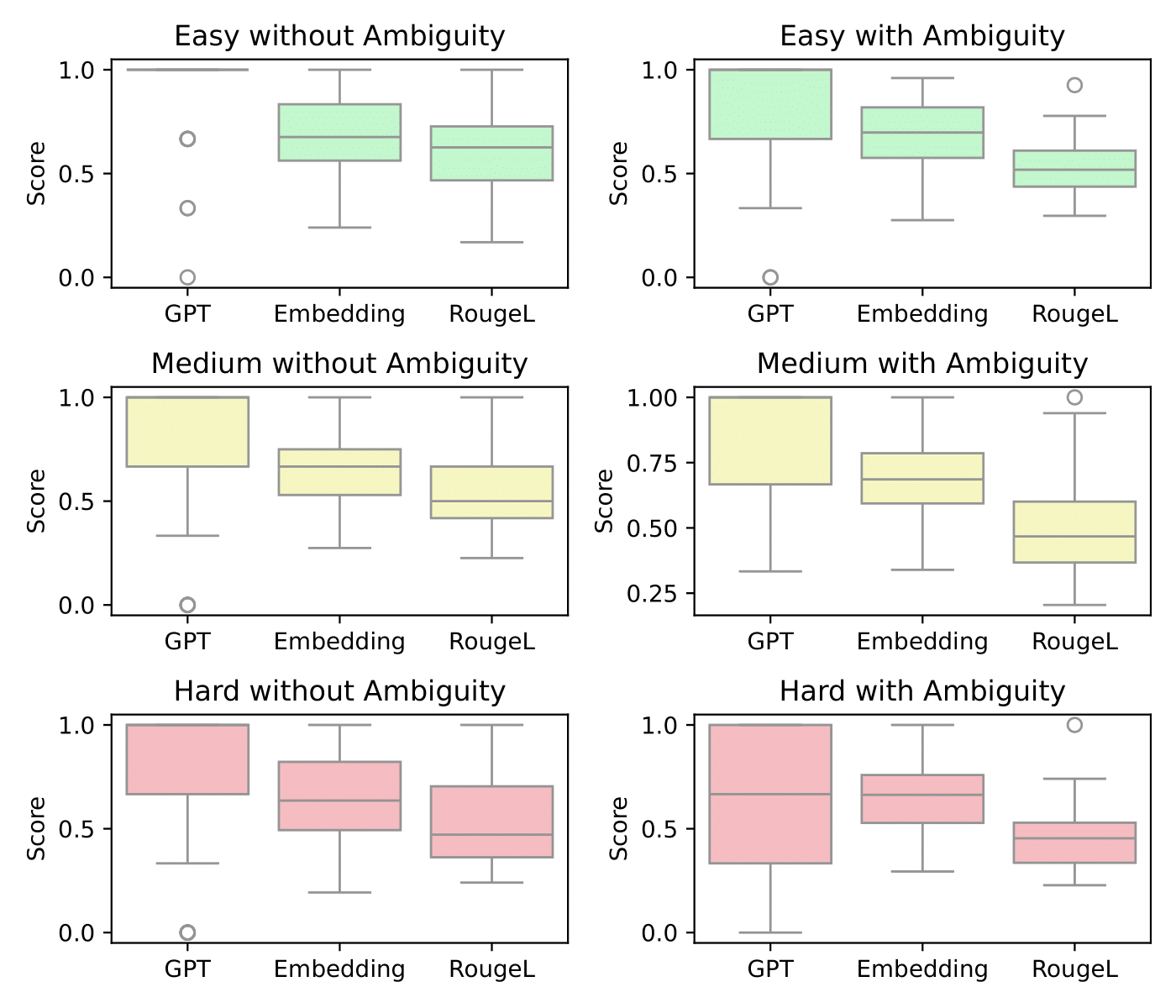 This figure illustrates the similarity distribution among the three user-defined instructions in Free-form language user instructions, based on GPT-4o's interpretability, semantic similarity, and sentence structure similarity.
To assess GPT-4o's interpretability, we introduce a novel metric, the GPT score, which measures GPT-4o's coherence in responses.
For each target, we provide \gpt with an image containing overlaid object IDs and ask it to identify the object specified by each of the three instructions.
The GPT score quantifies the fraction of correctly identified instructions, ranging from 0 (no correct identifications) to 1 (all three correct).
We evaluate semantic similarity using the embedding score, defined as the average SBERT (2) similarity across all pairs of user-defined instructions.
We assess structural similarity using the Rouge-L score, computed as the average Rouge-L (3) score across all instruction pairs.
Results indicate that instructions referring to the same target vary significantly in sentence structure (low Rouge-L score), reflecting differences in word choice and composition, while showing moderate variation in semantics (medium embedding score).
Interestingly, despite these variations, the consistently high GPT scores across all task difficulty levels suggest that GPT-4o is robust in identifying the correct target in the image, regardless of differences in instruction phrasing.
(1) Gilles, Maximilian, et al. "Metagraspnetv2: All-in-one dataset enabling fast and reliable robotic bin picking via object relationship reasoning and dexterous grasping." IEEE Transactions on Automation Science and Engineering 21.3 (2023): 2302-2320.
(2) Reimers, Nils, and Iryna Gurevych. "Sentence-bert: Sentence embeddings using siamese bert-networks." (2019).
(3) Lin, Chin-Yew, and Franz Josef Och. "Automatic evaluation of machine translation quality using longest common subsequence and skip-bigram statistics." Proceedings of the 42nd annual meeting of the association for computational linguistics (ACL-04). 2004.(3)
## Data Fields
```
- **__index_level_0__**: An integer representing the unique identifier for each example.
- **image**: The actual image sourced from the MetaGraspNetV2 dataset.
- **sceneId**: An integer identifier for the scene, directly taken from the MetaGrasp dataset. It corresponds to the specific scene in which the object appears.
- **queryObjId**: An integer identifier for the object being targeted, from the MetaGrasp dataset.
- **annotation**: A string containing the annotation details for the target object within the scene in a free-form language description.
- **groundTruthObjIds**: A string listing the object IDs that are considered the ground truth for the scene.
- **difficulty**: A string indicating the difficulty level of the grasp, reported in the introduction of the dataset. The difficulty levels are categorized based on the occlusion graph.
- **ambiguious**: A boolean indicating whether the object is ambiguous. An object is considered ambiguous if multiple instances of the same class are present in the scene.
- **split**: A string denoting the split (0, 1, or 2) corresponding to different annotations for the same image. This split indicates the partition of annotations, not the annotator itself.
```
## ArXiv link
https://arxiv.org/abs/2503.13082
## APA Citaion
Jiao, R., Fasoli, A., Giuliari, F., Bortolon, M., Povoli, S., Mei, G., Wang, Y., & Poiesi, F. (2025). Free-form language-based robotic reasoning and grasping. arXiv preprint arXiv:2503.13082.
## Bibtex
```
@article{jiao2025free,
title={Free-form language-based robotic reasoning and grasping},
author={Jiao, Runyu and Fasoli, Alice and Giuliari, Francesco and Bortolon, Matteo and Povoli, Sergio and Mei, Guofeng and Wang, Yiming and Poiesi, Fabio},
journal={arXiv preprint arXiv:2503.13082},
year={2025}
}
```
## Acknowledgement
This figure illustrates the similarity distribution among the three user-defined instructions in Free-form language user instructions, based on GPT-4o's interpretability, semantic similarity, and sentence structure similarity.
To assess GPT-4o's interpretability, we introduce a novel metric, the GPT score, which measures GPT-4o's coherence in responses.
For each target, we provide \gpt with an image containing overlaid object IDs and ask it to identify the object specified by each of the three instructions.
The GPT score quantifies the fraction of correctly identified instructions, ranging from 0 (no correct identifications) to 1 (all three correct).
We evaluate semantic similarity using the embedding score, defined as the average SBERT (2) similarity across all pairs of user-defined instructions.
We assess structural similarity using the Rouge-L score, computed as the average Rouge-L (3) score across all instruction pairs.
Results indicate that instructions referring to the same target vary significantly in sentence structure (low Rouge-L score), reflecting differences in word choice and composition, while showing moderate variation in semantics (medium embedding score).
Interestingly, despite these variations, the consistently high GPT scores across all task difficulty levels suggest that GPT-4o is robust in identifying the correct target in the image, regardless of differences in instruction phrasing.
(1) Gilles, Maximilian, et al. "Metagraspnetv2: All-in-one dataset enabling fast and reliable robotic bin picking via object relationship reasoning and dexterous grasping." IEEE Transactions on Automation Science and Engineering 21.3 (2023): 2302-2320.
(2) Reimers, Nils, and Iryna Gurevych. "Sentence-bert: Sentence embeddings using siamese bert-networks." (2019).
(3) Lin, Chin-Yew, and Franz Josef Och. "Automatic evaluation of machine translation quality using longest common subsequence and skip-bigram statistics." Proceedings of the 42nd annual meeting of the association for computational linguistics (ACL-04). 2004.(3)
## Data Fields
```
- **__index_level_0__**: An integer representing the unique identifier for each example.
- **image**: The actual image sourced from the MetaGraspNetV2 dataset.
- **sceneId**: An integer identifier for the scene, directly taken from the MetaGrasp dataset. It corresponds to the specific scene in which the object appears.
- **queryObjId**: An integer identifier for the object being targeted, from the MetaGrasp dataset.
- **annotation**: A string containing the annotation details for the target object within the scene in a free-form language description.
- **groundTruthObjIds**: A string listing the object IDs that are considered the ground truth for the scene.
- **difficulty**: A string indicating the difficulty level of the grasp, reported in the introduction of the dataset. The difficulty levels are categorized based on the occlusion graph.
- **ambiguious**: A boolean indicating whether the object is ambiguous. An object is considered ambiguous if multiple instances of the same class are present in the scene.
- **split**: A string denoting the split (0, 1, or 2) corresponding to different annotations for the same image. This split indicates the partition of annotations, not the annotator itself.
```
## ArXiv link
https://arxiv.org/abs/2503.13082
## APA Citaion
Jiao, R., Fasoli, A., Giuliari, F., Bortolon, M., Povoli, S., Mei, G., Wang, Y., & Poiesi, F. (2025). Free-form language-based robotic reasoning and grasping. arXiv preprint arXiv:2503.13082.
## Bibtex
```
@article{jiao2025free,
title={Free-form language-based robotic reasoning and grasping},
author={Jiao, Runyu and Fasoli, Alice and Giuliari, Francesco and Bortolon, Matteo and Povoli, Sergio and Mei, Guofeng and Wang, Yiming and Poiesi, Fabio},
journal={arXiv preprint arXiv:2503.13082},
year={2025}
}
```
## Acknowledgement

This project was supported by Fondazione VRT under the project Make Grasping Easy, PNRR ICSC National Research Centre for HPC, Big Data and Quantum Computing (CN00000013), and FAIR - Future AI Research (PE00000013), funded by NextGeneration EU.
 |
 |
 |