Datasets:


Commit
·
d4bef0a
1
Parent(s):
8903672
docs: add calibration analysis
Browse files- README.md +11 -0
- mvl-sib_calibration.png +0 -0
README.md
CHANGED
|
@@ -280,6 +280,17 @@ print(dataset[0])
|
|
| 280 |
'index_id': 0}
|
| 281 |
```
|
| 282 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 283 |
## Tasks
|
| 284 |
|
| 285 |
Large vision-language models must select one of 4 candidate sentences that best matches the topic of the reference images (\`images-to-sentence') or, conversely, choose one of 4 candidate images corresponding to the topic of the reference sentences (\`sentences-to-image'). We present the model with the list of topics that images and sentences may be associated with. Otherwise, it would be unclear along which dimension the model should match images and sentences. The portion of the prompt that introduces the task is provided in English, while the sentences to be topically aligned with images are presented in one of the 205 languages included in MVL-SIB.
|
|
|
|
| 280 |
'index_id': 0}
|
| 281 |
```
|
| 282 |
|
| 283 |
+
### Number of samples
|
| 284 |
+
|
| 285 |
+
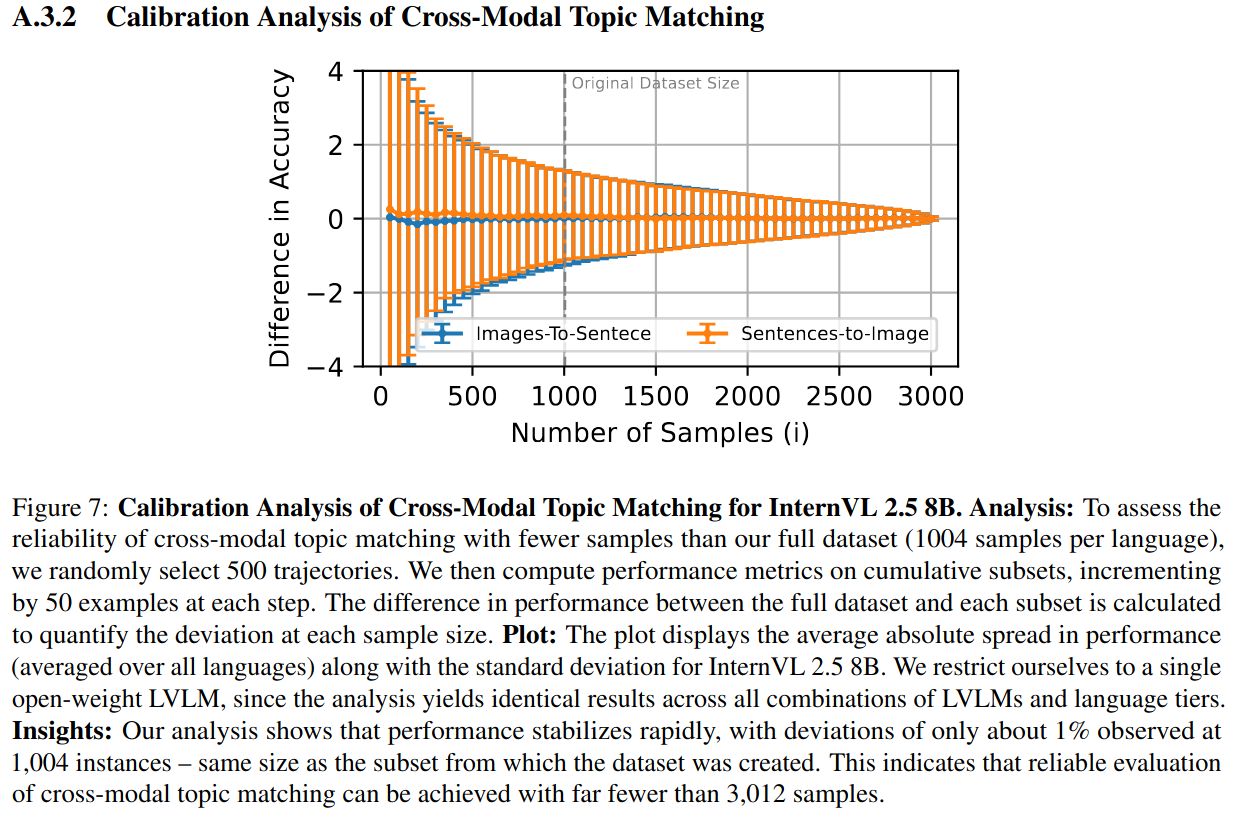
The dataset upsamples the pooled [SIB-200](https://huggingface.co/datasets/Davlan/sib200) (1,004 instances) 3 times, coupling each sentence in SIB-200 with different sets of images and sentences (cf. [Section 3.1 MVL-SIB](https://arxiv.org/pdf/2502.12852)). We nevertheless observed that cross-modal topic matching is stable with only the original dataset size (i.e., 1,004 instances). **To reduce the number of instances per language, you can load the dataset as follows**:
|
| 286 |
+
|
| 287 |
+
```python
|
| 288 |
+
# add "test[:1004] to only pick the first 1004 instances of the test set
|
| 289 |
+
dataset = load_dataset("WueNLP/mvl-sib", "sent2img.eng_Latn", split="test[:1004]", trust_remote_code=True)
|
| 290 |
+
```
|
| 291 |
+
|
| 292 |
+

|
| 293 |
+
|
| 294 |
## Tasks
|
| 295 |
|
| 296 |
Large vision-language models must select one of 4 candidate sentences that best matches the topic of the reference images (\`images-to-sentence') or, conversely, choose one of 4 candidate images corresponding to the topic of the reference sentences (\`sentences-to-image'). We present the model with the list of topics that images and sentences may be associated with. Otherwise, it would be unclear along which dimension the model should match images and sentences. The portion of the prompt that introduces the task is provided in English, while the sentences to be topically aligned with images are presented in one of the 205 languages included in MVL-SIB.
|
mvl-sib_calibration.png
ADDED
|