

Update throughput chart and improve README
Browse files- README.md +8 -1
- throughput.png +2 -2
README.md
CHANGED
|
@@ -49,7 +49,14 @@ In terms of the evaluation of reasoning ability, Ring-lite-linear-preview achi
|
|
| 49 |
|
| 50 |
## Inference Speed
|
| 51 |
|
| 52 |
-
To evaluate the generation throughput, we deploy Ring-lite-linear and the softmax-attention-based Ring-lite based on vLLM on a single NVIDIA A100 GPU.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 53 |
|
| 54 |
<p align="center">
|
| 55 |
<img src="https://huggingface.co/inclusionAI/Ring-lite-linear-preview/resolve/main/throughput.png" width="600"/>
|
|
|
|
| 49 |
|
| 50 |
## Inference Speed
|
| 51 |
|
| 52 |
+
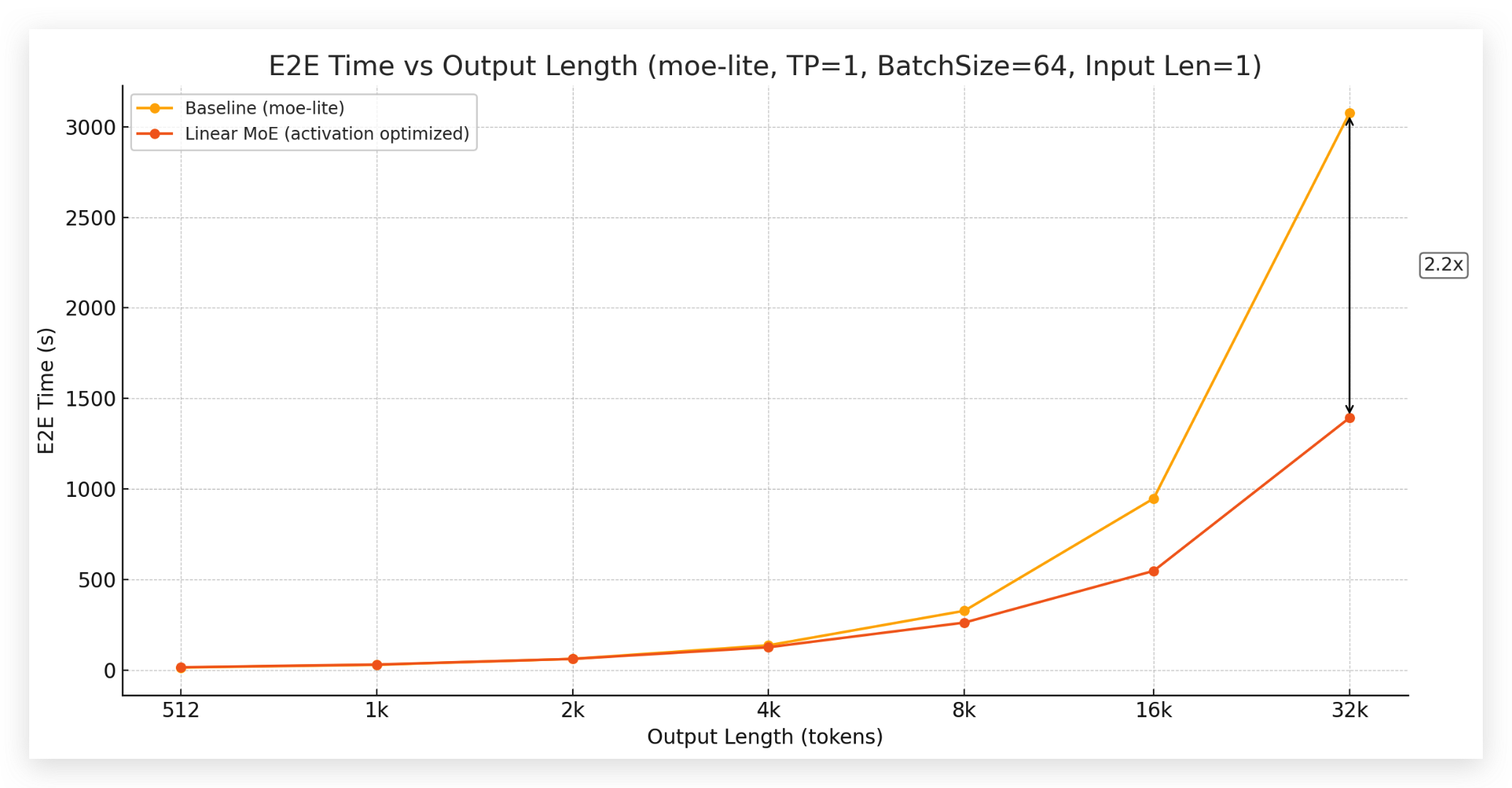
To evaluate the generation throughput, we deploy Ring-lite-linear and the softmax-attention-based Ring-lite based on vLLM on a single NVIDIA A100 GPU. We conduct two sets of experiments:
|
| 53 |
+
|
| 54 |
+
1. **Long Input Evaluation**: We measure the time-to-first-token (TTFT) with varying input sequence lengths (from 512 to 384k tokens) using batch size 1 and TP=1. As shown in the top figure, at 384k input length, Ring-lite-linear achieves 3.5× faster TTFT compared to the softmax-attention-based model.
|
| 55 |
+
|
| 56 |
+
2. **Long Output Evaluation**: We fix the input sequence length to 1 and measure the end-to-end (E2E) generation time required for generating output sequences of varying lengths (from 512 to 32k tokens) with batch size 64 and TP=1. As illustrated in the bottom figure, at 32k output length, Ring-lite-linear achieves 2.2× throughput of the softmax-attention-based Ring-lite.
|
| 57 |
+
|
| 58 |
+
These results demonstrate that our hybrid linear attention mechanism significantly improves both input processing efficiency and generation throughput, especially for long context scenarios.
|
| 59 |
+
|
| 60 |
|
| 61 |
<p align="center">
|
| 62 |
<img src="https://huggingface.co/inclusionAI/Ring-lite-linear-preview/resolve/main/throughput.png" width="600"/>
|
throughput.png
CHANGED
|
Git LFS Details
|

|
Git LFS Details
|