
Update model: Epochs 50, Val Loss 1.1906, Test BLEU 27.90
Browse files- README.md +219 -0
- config.json +36 -0
- english_tokenizer.json +0 -0
- loss_curves.png +0 -0
- luganda_tokenizer.json +0 -0
- pytorch_model.bin +3 -0
README.md
ADDED
|
@@ -0,0 +1,219 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
---
|
| 3 |
+
license: apache-2.0
|
| 4 |
+
language:
|
| 5 |
+
- en
|
| 6 |
+
- lg
|
| 7 |
+
tags:
|
| 8 |
+
- translation
|
| 9 |
+
- english
|
| 10 |
+
- luganda
|
| 11 |
+
- transformer
|
| 12 |
+
- pytorch
|
| 13 |
+
- seq2seq
|
| 14 |
+
- from-scratch
|
| 15 |
+
- low-resource-nlp
|
| 16 |
+
datasets:
|
| 17 |
+
- kambale/luganda-english-parallel-corpus
|
| 18 |
+
metrics:
|
| 19 |
+
- bleu
|
| 20 |
+
pipeline_tag: translation
|
| 21 |
+
model-index:
|
| 22 |
+
- name: Pearl Model (11M-translate)
|
| 23 |
+
results:
|
| 24 |
+
- task:
|
| 25 |
+
type: translation
|
| 26 |
+
name: Translation English to Luganda
|
| 27 |
+
dataset:
|
| 28 |
+
name: kambale/luganda-english-parallel-corpus (Test Split)
|
| 29 |
+
type: kambale/luganda-english-parallel-corpus
|
| 30 |
+
args: test
|
| 31 |
+
metrics:
|
| 32 |
+
- type: bleu
|
| 33 |
+
value: 27.90
|
| 34 |
+
name: BLEU
|
| 35 |
+
- type: loss
|
| 36 |
+
value: 1.376
|
| 37 |
+
name: Validation Loss
|
| 38 |
+
---
|
| 39 |
+
|
| 40 |
+
# Pearl Model (11M-translate): English to Luganda Translation
|
| 41 |
+
|
| 42 |
+
This is the **Pearl Model (11M-translate)**, a Transformer-based neural machine translation (NMT) model trained from scratch. It is designed to translate text from English to Luganda and contains approximately 11 million parameters.
|
| 43 |
+
|
| 44 |
+
## Model Overview
|
| 45 |
+
|
| 46 |
+
The Pearl Model is an encoder-decoder Transformer architecture implemented entirely in PyTorch. It was developed to explore NMT capabilities for English-Luganda, a relatively low-resource language pair.
|
| 47 |
+
|
| 48 |
+
- **Model Type:** Sequence-to-Sequence Transformer
|
| 49 |
+
- **Source Language:** English ('english')
|
| 50 |
+
- **Target Language:** Luganda ('luganda')
|
| 51 |
+
- **Framework:** PyTorch
|
| 52 |
+
- **Parameters:** ~11 Million
|
| 53 |
+
- **Training:** From scratch
|
| 54 |
+
|
| 55 |
+
Detailed hyperparameters, architectural specifics, and tokenizer configurations can be found in the accompanying `config.json` file.
|
| 56 |
+
|
| 57 |
+
## Intended Use
|
| 58 |
+
|
| 59 |
+
This model is intended for:
|
| 60 |
+
|
| 61 |
+
* Translating general domain text from English to Luganda.
|
| 62 |
+
* Research purposes in low-resource machine translation, Transformer architectures, and NLP for African languages.
|
| 63 |
+
* Serving as a baseline for future improvements in English-Luganda translation.
|
| 64 |
+
* Educational tool for understanding how to build and train NMT models from scratch.
|
| 65 |
+
|
| 66 |
+
**Out-of-scope:**
|
| 67 |
+
|
| 68 |
+
* Translation of highly specialized or technical jargon not present in the training data.
|
| 69 |
+
* High-stakes applications requiring perfect fluency or nuance without further fine-tuning and rigorous evaluation.
|
| 70 |
+
* Translation into English (this model is unidirectional: English to Luganda).
|
| 71 |
+
|
| 72 |
+
## Training Details
|
| 73 |
+
|
| 74 |
+
### Dataset
|
| 75 |
+
|
| 76 |
+
The model was trained exclusively on the `kambale/luganda-english-parallel-corpus` dataset available on the Hugging Face Hub. This dataset consists of parallel sentences in English and Luganda.
|
| 77 |
+
|
| 78 |
+
* **Dataset ID:** [kambale/luganda-english-parallel-corpus](https://huggingface.co/datasets/kambale/luganda-english-parallel-corpus)
|
| 79 |
+
* **Training Epochs:** 50
|
| 80 |
+
* **Tokenizers:** Byte-Pair Encoding (BPE) tokenizers were trained from scratch on the respective language portions of the training dataset.
|
| 81 |
+
* English Tokenizer: `english_tokenizer.json`
|
| 82 |
+
* Luganda Tokenizer: `luganda_tokenizer.json`
|
| 83 |
+
|
| 84 |
+
### Compute Infrastructure
|
| 85 |
+
|
| 86 |
+
* **Hardware:** 1x NVIDIA A100 40GB
|
| 87 |
+
* **Training Time:** Approx. 2 hours
|
| 88 |
+
|
| 89 |
+
## Performance & Evaluation
|
| 90 |
+
|
| 91 |
+
The model's performance was evaluated based on validation loss and BLEU score on the test split of the `kambale/luganda-english-parallel-corpus` dataset.
|
| 92 |
+
|
| 93 |
+
* **Best Validation Loss:** 1.376
|
| 94 |
+
* **Test Set BLEU Score:** 27.90
|
| 95 |
+
|
| 96 |
+
* Validation Set Examples
|
| 97 |
+
|
| 98 |
+
```bash
|
| 99 |
+
Source: Youths turned up in big numbers for the event .
|
| 100 |
+
Target (Reference): Abavubuka bazze mu bungi ku mukolo .
|
| 101 |
+
Target (Predicted): Abavubuka bazze mu bungi ku mukolo .
|
| 102 |
+
|
| 103 |
+
Source: Employers should ensure their places of work are safe for employees .
|
| 104 |
+
Target (Reference): Abakozesa basaanidde okukakasa nti ebifo abakozi baabwe we bakolera si bya bulabe eri abakozi baabwe .
|
| 105 |
+
Target (Predicted): Abakozesa balina okukakasa nti ebifo abakozi baabwe we bakolera si bya bulabe eri abakozi baabwe .
|
| 106 |
+
|
| 107 |
+
Source: We sent our cond ol ences to the family of the deceased .
|
| 108 |
+
Target (Reference): Twa weereza obubaka obu kuba gi za eri ab ' omu maka g ' omugenzi .
|
| 109 |
+
Target (Predicted): Twa sindika abe ere tu waayo mu maka gaffe omugenzi .
|
| 110 |
+
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
*(Note: BLEU scores can vary based on the exact tokenization and calculation method. The score reported here uses SacreBLEU on detokenized text.)*
|
| 114 |
+
|
| 115 |
+
### Training Loss Curve
|
| 116 |
+
|
| 117 |
+
The following graph illustrates the training and validation loss over epochs:
|
| 118 |
+
|
| 119 |
+

|
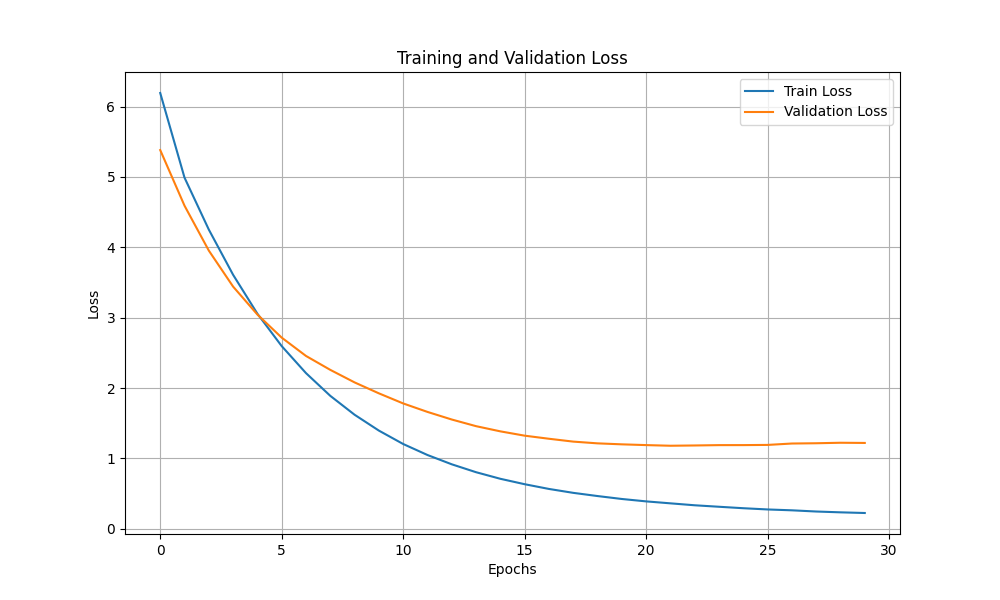
| 120 |
+
|
| 121 |
+
## How to Use
|
| 122 |
+
|
| 123 |
+
This model is provided with its PyTorch state dictionary, tokenizer files, and configuration. As it's a custom implementation, direct use with Hugging Face `AutoModelForSeq2SeqLM` might require adapting the model class definition to be compatible with the Transformers library's expectations or by loading the components manually.
|
| 124 |
+
|
| 125 |
+
### Manual Loading (Conceptual Example)
|
| 126 |
+
|
| 127 |
+
1. **Define the Model Architecture:**
|
| 128 |
+
You'll need the Python code for `Seq2SeqTransformer`, `Encoder`, `Decoder`, `MultiHeadAttentionLayer`, `PositionwiseFeedforwardLayer`, and `PositionalEncoding` classes as used during training.
|
| 129 |
+
|
| 130 |
+
2. **Load Tokenizers:**
|
| 131 |
+
```python
|
| 132 |
+
from tokenizers import Tokenizer
|
| 133 |
+
|
| 134 |
+
# Make sure these paths point to the tokenizer files in your local environment
|
| 135 |
+
# after downloading them from the Hub.
|
| 136 |
+
src_tokenizer_path = "english_tokenizer.json" # Or path to downloaded file
|
| 137 |
+
trg_tokenizer_path = "luganda_tokenizer.json" # Or path to downloaded file
|
| 138 |
+
|
| 139 |
+
src_tokenizer = Tokenizer.from_file(src_tokenizer_path)
|
| 140 |
+
trg_tokenizer = Tokenizer.from_file(trg_tokenizer_path)
|
| 141 |
+
|
| 142 |
+
# Retrieve special token IDs (ensure these match your training config)
|
| 143 |
+
SRC_PAD_IDX = src_tokenizer.token_to_id("<pad>")
|
| 144 |
+
TRG_PAD_IDX = trg_tokenizer.token_to_id("<pad>")
|
| 145 |
+
# ... and other special tokens if needed by your model class
|
| 146 |
+
```
|
| 147 |
+
|
| 148 |
+
3. **Instantiate and Load Model Weights:**
|
| 149 |
+
```python
|
| 150 |
+
import torch
|
| 151 |
+
|
| 152 |
+
# Assuming your model class definitions are available
|
| 153 |
+
# from your_model_script import Seq2SeqTransformer, Encoder, Decoder # etc.
|
| 154 |
+
|
| 155 |
+
# Retrieve model parameters from config.json or define them
|
| 156 |
+
# Example (these should match your actual model config):
|
| 157 |
+
INPUT_DIM = src_tokenizer.get_vocab_size()
|
| 158 |
+
OUTPUT_DIM = trg_tokenizer.get_vocab_size()
|
| 159 |
+
HID_DIM = 256 # Example, check config.json
|
| 160 |
+
ENC_LAYERS = 3 # Example
|
| 161 |
+
DEC_LAYERS = 3 # Example
|
| 162 |
+
ENC_HEADS = 8 # Example
|
| 163 |
+
DEC_HEADS = 8 # Example
|
| 164 |
+
ENC_PF_DIM = 512 # Example
|
| 165 |
+
DEC_PF_DIM = 512 # Example
|
| 166 |
+
ENC_DROPOUT = 0.1 # Example
|
| 167 |
+
DEC_DROPOUT = 0.1 # Example
|
| 168 |
+
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 169 |
+
MAX_LEN_MODEL = 128 # Example, max sequence length model was trained with
|
| 170 |
+
|
| 171 |
+
# Instantiate encoder and decoder
|
| 172 |
+
enc = Encoder(INPUT_DIM, HID_DIM, ENC_LAYERS, ENC_HEADS, ENC_PF_DIM, ENC_DROPOUT, DEVICE, MAX_LEN_MODEL)
|
| 173 |
+
dec = Decoder(OUTPUT_DIM, HID_DIM, DEC_LAYERS, DEC_HEADS, DEC_PF_DIM, DEC_DROPOUT, DEVICE, MAX_LEN_MODEL)
|
| 174 |
+
|
| 175 |
+
# Instantiate the main model
|
| 176 |
+
model = Seq2SeqTransformer(enc, dec, SRC_PAD_IDX, TRG_PAD_IDX, DEVICE)
|
| 177 |
+
|
| 178 |
+
# Load the state dictionary
|
| 179 |
+
model_weights_path = "pytorch_model.bin" # Or path to downloaded file
|
| 180 |
+
model.load_state_dict(torch.load(model_weights_path, map_location=DEVICE))
|
| 181 |
+
model.to(DEVICE)
|
| 182 |
+
model.eval()
|
| 183 |
+
```
|
| 184 |
+
*(The above code is illustrative. You'll need to ensure the model class and parameters correctly match those used for training, as detailed in `config.json` and your training script.)*
|
| 185 |
+
|
| 186 |
+
4. **Inference/Translation Function:**
|
| 187 |
+
You would then use your `translate_sentence` function (or a similar one) from your training notebook, passing the loaded model and tokenizers.
|
| 188 |
+
|
| 189 |
+
## Limitations and Bias
|
| 190 |
+
|
| 191 |
+
* **Low-Resource Pair:** Luganda is a low-resource language. While the `kambale/luganda-english-parallel-corpus` is a valuable asset, the overall volume of parallel data is still limited compared to high-resource language pairs. This can lead to:
|
| 192 |
+
* Difficulties in handling out-of-vocabulary (OOV) words or rare phrases.
|
| 193 |
+
* Potential for translations to be less fluent or accurate for complex sentences or nuanced expressions.
|
| 194 |
+
* The model might reflect biases present in the training data.
|
| 195 |
+
* **Data Source Bias:** The characteristics and biases of the `kambale/luganda-english-parallel-corpus` (e.g., domain, style, demographic representation) will be reflected in the model's translations.
|
| 196 |
+
* **Generalization:** The model may not generalize well to domains significantly different from the training data.
|
| 197 |
+
* **No Back-translation or Advanced Techniques:** This model was trained directly on the parallel corpus without more advanced techniques like back-translation or pre-training on monolingual data, which could further improve performance.
|
| 198 |
+
* **Greedy Decoding for Examples:** Performance metrics (BLEU) are typically calculated using beam search. The conceptual usage examples might rely on greedy decoding, which can be suboptimal.
|
| 199 |
+
|
| 200 |
+
## Ethical Considerations
|
| 201 |
+
|
| 202 |
+
* **Bias Amplification:** Machine translation models can inadvertently perpetuate or even amplify societal biases present in the training data. Users should be aware of this potential when using the translations.
|
| 203 |
+
* **Misinformation:** As with any generative model, there's a potential for misuse in generating misleading or incorrect information.
|
| 204 |
+
* **Cultural Nuance:** Automated translation may miss critical cultural nuances, potentially leading to misinterpretations. Human oversight is recommended for sensitive or important translations.
|
| 205 |
+
* **Attribution:** The training data is sourced from `kambale/luganda-english-parallel-corpus`. Please refer to the dataset card for its specific sourcing and licensing.
|
| 206 |
+
|
| 207 |
+
## Future Work & Potential Improvements
|
| 208 |
+
|
| 209 |
+
* Fine-tuning on domain-specific data.
|
| 210 |
+
* Training with a larger parallel corpus if available.
|
| 211 |
+
* Incorporating monolingual Luganda data through techniques like back-translation.
|
| 212 |
+
* Experimenting with larger model architectures or pre-trained multilingual models as a base.
|
| 213 |
+
* Implementing more sophisticated decoding strategies (e.g., beam search with length normalization).
|
| 214 |
+
* Conducting a thorough human evaluation of translation quality.
|
| 215 |
+
|
| 216 |
+
## Disclaimer
|
| 217 |
+
|
| 218 |
+
This model is provided "as-is" without warranty of any kind, express or implied. It was trained as part of an educational demonstration and may have limitations in accuracy, fluency, and robustness. Users should validate its suitability for their specific applications.
|
| 219 |
+
|
config.json
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"model_type": "seq2seq_transformer_from_scratch",
|
| 3 |
+
"architecture": "Encoder-Decoder Transformer",
|
| 4 |
+
"framework": "pytorch",
|
| 5 |
+
"source_language": "english",
|
| 6 |
+
"target_language": "luganda",
|
| 7 |
+
"pytorch_model_path": "pytorch_model.bin",
|
| 8 |
+
"src_tokenizer_file": "english_tokenizer.json",
|
| 9 |
+
"trg_tokenizer_file": "luganda_tokenizer.json",
|
| 10 |
+
"model_parameters": {
|
| 11 |
+
"input_dim_vocab_size_src": 10000,
|
| 12 |
+
"output_dim_vocab_size_trg": 10000,
|
| 13 |
+
"hidden_dim": 256,
|
| 14 |
+
"encoder_layers": 3,
|
| 15 |
+
"decoder_layers": 3,
|
| 16 |
+
"encoder_heads": 8,
|
| 17 |
+
"decoder_heads": 8,
|
| 18 |
+
"encoder_pf_dim": 512,
|
| 19 |
+
"decoder_pf_dim": 512,
|
| 20 |
+
"encoder_dropout": 0.1,
|
| 21 |
+
"decoder_dropout": 0.1,
|
| 22 |
+
"max_seq_length": 128
|
| 23 |
+
},
|
| 24 |
+
"special_token_ids": {
|
| 25 |
+
"pad_token_id": 0,
|
| 26 |
+
"sos_token_id": 1,
|
| 27 |
+
"eos_token_id": 2,
|
| 28 |
+
"unk_token_id": 3
|
| 29 |
+
},
|
| 30 |
+
"dataset_used_for_training": "kambale/luganda-english-parallel-corpus",
|
| 31 |
+
"training_epochs": 50,
|
| 32 |
+
"batch_size": 128,
|
| 33 |
+
"learning_rate": 0.0005,
|
| 34 |
+
"best_validation_loss": 1.1906119108200073,
|
| 35 |
+
"bleu_on_test_set": 27.901593935858266
|
| 36 |
+
}
|
english_tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
loss_curves.png
ADDED
|
luganda_tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8d1a76dd82bcdd2ff8a4b7a993844dbb0448a34ea56406185a7faa163829c002
|
| 3 |
+
size 46889954
|