 aycatakmaz
aycatakmaz







Abstract
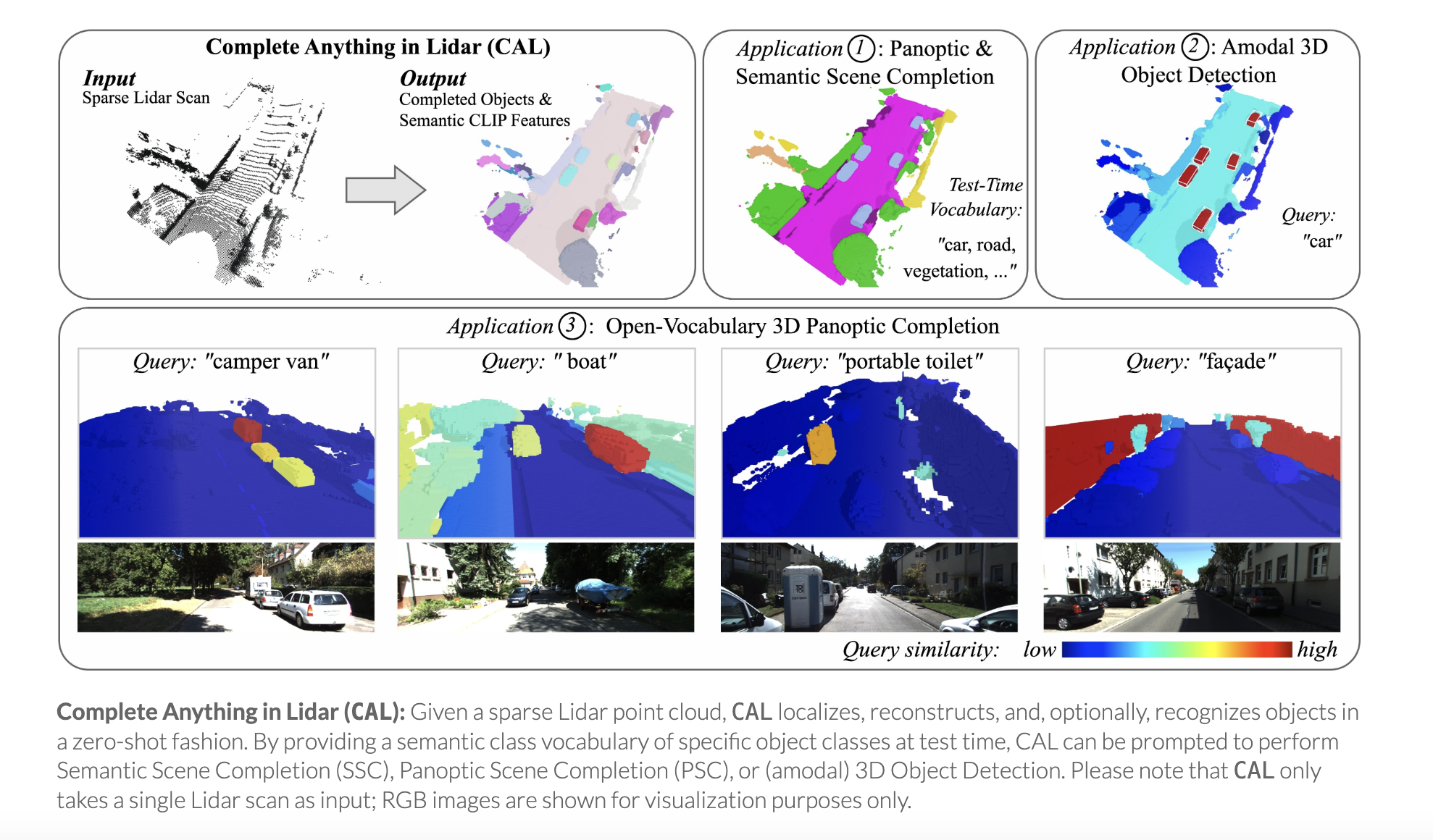
We propose CAL (Complete Anything in Lidar) for Lidar-based shape-completion in-the-wild. This is closely related to Lidar-based semantic/panoptic scene completion. However, contemporary methods can only complete and recognize objects from a closed vocabulary labeled in existing Lidar datasets. Different to that, our zero-shot approach leverages the temporal context from multi-modal sensor sequences to mine object shapes and semantic features of observed objects. These are then distilled into a Lidar-only instance-level completion and recognition model. Although we only mine partial shape completions, we find that our distilled model learns to infer full object shapes from multiple such partial observations across the dataset. We show that our model can be prompted on standard benchmarks for Semantic and Panoptic Scene Completion, localize objects as (amodal) 3D bounding boxes, and recognize objects beyond fixed class vocabularies. Our project page is https://research.nvidia.com/labs/dvl/projects/complete-anything-lidar
Community

This is an automated message from the Librarian Bot. I found the following papers similar to this paper.
The following papers were recommended by the Semantic Scholar API
- Zero-Shot 4D Lidar Panoptic Segmentation (2025)
- MinkOcc: Towards real-time label-efficient semantic occupancy prediction (2025)
- Multi-Scale Neighborhood Occupancy Masked Autoencoder for Self-Supervised Learning in LiDAR Point Clouds (2025)
- Point-based Instance Completion with Scene Constraints (2025)
- TrackOcc: Camera-based 4D Panoptic Occupancy Tracking (2025)
- LIFT-GS: Cross-Scene Render-Supervised Distillation for 3D Language Grounding (2025)
- VLScene: Vision-Language Guidance Distillation for Camera-Based 3D Semantic Scene Completion (2025)
Please give a thumbs up to this comment if you found it helpful!
If you want recommendations for any Paper on Hugging Face checkout this Space
You can directly ask Librarian Bot for paper recommendations by tagging it in a comment:
@librarian-bot
recommend

Models citing this paper 0
No model linking this paper
Datasets citing this paper 0
No dataset linking this paper
Spaces citing this paper 0
No Space linking this paper