Teaching Large Language Models to Maintain Contextual Faithfulness via Synthetic Tasks and Reinforcement Learning
 ssz1111
ssz1111






Abstract
CANOE improves LLM faithfulness in generation tasks using synthetic QA data and Dual-GRPO reinforcement learning without human annotations.
Teaching large language models (LLMs) to be faithful in the provided context is crucial for building reliable information-seeking systems. Therefore, we propose a systematic framework, CANOE, to improve the faithfulness of LLMs in both short-form and long-form generation tasks without human annotations. Specifically, we first synthesize short-form question-answering (QA) data with four diverse tasks to construct high-quality and easily verifiable training data without human annotation. Also, we propose Dual-GRPO, a rule-based reinforcement learning method that includes three tailored rule-based rewards derived from synthesized short-form QA data, while simultaneously optimizing both short-form and long-form response generation. Notably, Dual-GRPO eliminates the need to manually label preference data to train reward models and avoids over-optimizing short-form generation when relying only on the synthesized short-form QA data. Experimental results show that CANOE greatly improves the faithfulness of LLMs across 11 different downstream tasks, even outperforming the most advanced LLMs, e.g., GPT-4o and OpenAI o1.
Community
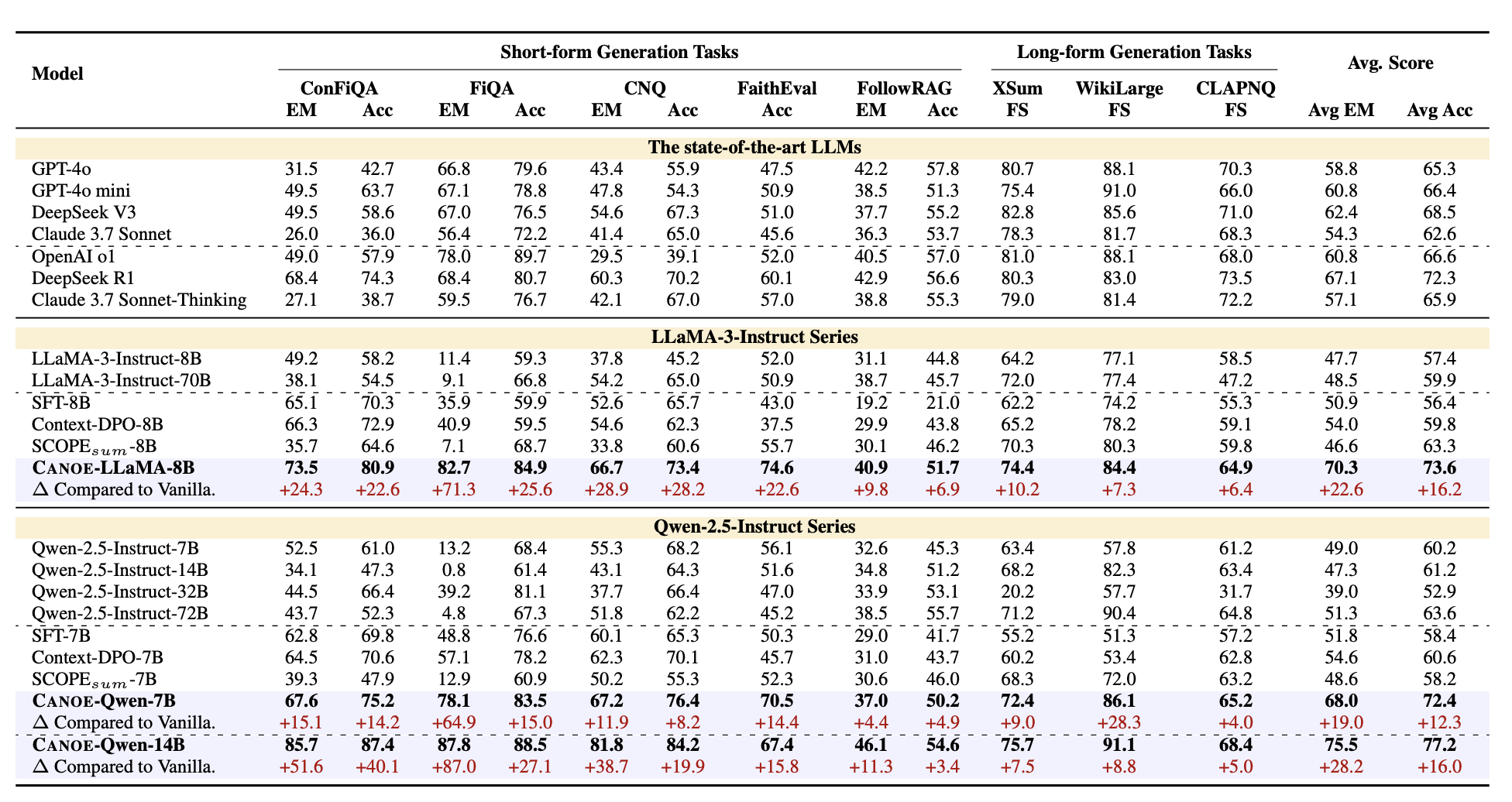
With only 7B parameters, CANOE already exceeds state-of-the-art LLMs like GPT-4o and OpenAI o1.

CANOE first synthesizes easily verifiable short-form QA data and then proposes the Dual-GRPO with designed rule-based rewards to improve the faithfulness of LLMs.
Experimental results (%) on eleven datasets. Please find more details in our paper!

This is an automated message from the Librarian Bot. I found the following papers similar to this paper.
The following papers were recommended by the Semantic Scholar API
- UNCLE: Uncertainty Expressions in Long-Form Generation (2025)
- NOVER: Incentive Training for Language Models via Verifier-Free Reinforcement Learning (2025)
- Effective and Transparent RAG: Adaptive-Reward Reinforcement Learning for Decision Traceability (2025)
- SFT or RL? An Early Investigation into Training R1-Like Reasoning Large Vision-Language Models (2025)
- Exploring the Effect of Reinforcement Learning on Video Understanding: Insights from SEED-Bench-R1 (2025)
- R1-Searcher++: Incentivizing the Dynamic Knowledge Acquisition of LLMs via Reinforcement Learning (2025)
- MT-R1-Zero: Advancing LLM-based Machine Translation via R1-Zero-like Reinforcement Learning (2025)
Please give a thumbs up to this comment if you found it helpful!
If you want recommendations for any Paper on Hugging Face checkout this Space
You can directly ask Librarian Bot for paper recommendations by tagging it in a comment:
@librarian-bot
recommend


Models citing this paper 0
No model linking this paper
Datasets citing this paper 0
No dataset linking this paper
Spaces citing this paper 0
No Space linking this paper