
Update README.md
Browse files
README.md
CHANGED
|
@@ -3,199 +3,86 @@ library_name: transformers
|
|
| 3 |
tags:
|
| 4 |
- trl
|
| 5 |
- grpo
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
|
| 8 |
-
#
|
| 9 |
|
| 10 |
-
|
| 11 |
|
|
|
|
| 12 |
|
| 13 |
-
|
| 14 |
-
## Model Details
|
| 15 |
-
|
| 16 |
-
### Model Description
|
| 17 |
-
|
| 18 |
-
<!-- Provide a longer summary of what this model is. -->
|
| 19 |
-
|
| 20 |
-
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
|
| 21 |
-
|
| 22 |
-
- **Developed by:** [More Information Needed]
|
| 23 |
-
- **Funded by [optional]:** [More Information Needed]
|
| 24 |
-
- **Shared by [optional]:** [More Information Needed]
|
| 25 |
-
- **Model type:** [More Information Needed]
|
| 26 |
-
- **Language(s) (NLP):** [More Information Needed]
|
| 27 |
-
- **License:** [More Information Needed]
|
| 28 |
-
- **Finetuned from model [optional]:** [More Information Needed]
|
| 29 |
-
|
| 30 |
-
### Model Sources [optional]
|
| 31 |
-
|
| 32 |
-
<!-- Provide the basic links for the model. -->
|
| 33 |
-
|
| 34 |
-
- **Repository:** [More Information Needed]
|
| 35 |
-
- **Paper [optional]:** [More Information Needed]
|
| 36 |
-
- **Demo [optional]:** [More Information Needed]
|
| 37 |
|
| 38 |
## Uses
|
| 39 |
|
| 40 |
-
|
| 41 |
-
|
| 42 |
-
### Direct Use
|
| 43 |
-
|
| 44 |
-
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
|
| 45 |
-
|
| 46 |
-
[More Information Needed]
|
| 47 |
-
|
| 48 |
-
### Downstream Use [optional]
|
| 49 |
-
|
| 50 |
-
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
|
| 51 |
-
|
| 52 |
-
[More Information Needed]
|
| 53 |
-
|
| 54 |
-
### Out-of-Scope Use
|
| 55 |
-
|
| 56 |
-
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
|
| 57 |
-
|
| 58 |
-
[More Information Needed]
|
| 59 |
-
|
| 60 |
-
## Bias, Risks, and Limitations
|
| 61 |
-
|
| 62 |
-
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
|
| 63 |
|
| 64 |
-
|
| 65 |
|
| 66 |
-
|
|
|
|
| 67 |
|
| 68 |
-
|
| 69 |
|
| 70 |
-
|
|
|
|
|
|
|
| 71 |
|
| 72 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 73 |
|
| 74 |
-
|
| 75 |
|
| 76 |
-
|
|
|
|
| 77 |
|
| 78 |
## Training Details
|
| 79 |
|
| 80 |
### Training Data
|
| 81 |
|
| 82 |
-
|
| 83 |
-
|
| 84 |
-
[More Information Needed]
|
| 85 |
|
| 86 |
### Training Procedure
|
| 87 |
|
| 88 |
-
|
| 89 |
-
|
| 90 |
-
|
| 91 |
-
|
| 92 |
-
|
| 93 |
-
|
| 94 |
-
|
| 95 |
-
|
| 96 |
-
|
| 97 |
-
- **
|
| 98 |
-
|
| 99 |
-
|
| 100 |
-
|
| 101 |
-
|
| 102 |
-
|
| 103 |
-
|
| 104 |
-
|
| 105 |
-
|
| 106 |
-
|
| 107 |
-
|
| 108 |
-
|
| 109 |
-
|
| 110 |
-
|
| 111 |
-
|
| 112 |
-
|
| 113 |
-
|
| 114 |
-
|
| 115 |
-
|
| 116 |
-
|
| 117 |
-
|
| 118 |
-
|
| 119 |
-
|
| 120 |
-
|
| 121 |
-
|
| 122 |
-
|
| 123 |
-
|
| 124 |
-
|
| 125 |
-
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
|
| 126 |
-
|
| 127 |
-
[More Information Needed]
|
| 128 |
-
|
| 129 |
-
### Results
|
| 130 |
-
|
| 131 |
-
[More Information Needed]
|
| 132 |
-
|
| 133 |
-
#### Summary
|
| 134 |
-
|
| 135 |
-
|
| 136 |
-
|
| 137 |
-
## Model Examination [optional]
|
| 138 |
-
|
| 139 |
-
<!-- Relevant interpretability work for the model goes here -->
|
| 140 |
-
|
| 141 |
-
[More Information Needed]
|
| 142 |
-
|
| 143 |
-
## Environmental Impact
|
| 144 |
-
|
| 145 |
-
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
|
| 146 |
-
|
| 147 |
-
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
|
| 148 |
-
|
| 149 |
-
- **Hardware Type:** [More Information Needed]
|
| 150 |
-
- **Hours used:** [More Information Needed]
|
| 151 |
-
- **Cloud Provider:** [More Information Needed]
|
| 152 |
-
- **Compute Region:** [More Information Needed]
|
| 153 |
-
- **Carbon Emitted:** [More Information Needed]
|
| 154 |
-
|
| 155 |
-
## Technical Specifications [optional]
|
| 156 |
-
|
| 157 |
-
### Model Architecture and Objective
|
| 158 |
-
|
| 159 |
-
[More Information Needed]
|
| 160 |
-
|
| 161 |
-
### Compute Infrastructure
|
| 162 |
-
|
| 163 |
-
[More Information Needed]
|
| 164 |
-
|
| 165 |
-
#### Hardware
|
| 166 |
-
|
| 167 |
-
[More Information Needed]
|
| 168 |
-
|
| 169 |
-
#### Software
|
| 170 |
-
|
| 171 |
-
[More Information Needed]
|
| 172 |
-
|
| 173 |
-
## Citation [optional]
|
| 174 |
-
|
| 175 |
-
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
|
| 176 |
-
|
| 177 |
-
**BibTeX:**
|
| 178 |
-
|
| 179 |
-
[More Information Needed]
|
| 180 |
-
|
| 181 |
-
**APA:**
|
| 182 |
-
|
| 183 |
-
[More Information Needed]
|
| 184 |
-
|
| 185 |
-
## Glossary [optional]
|
| 186 |
-
|
| 187 |
-
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
|
| 188 |
-
|
| 189 |
-
[More Information Needed]
|
| 190 |
-
|
| 191 |
-
## More Information [optional]
|
| 192 |
-
|
| 193 |
-
[More Information Needed]
|
| 194 |
-
|
| 195 |
-
## Model Card Authors [optional]
|
| 196 |
-
|
| 197 |
-
[More Information Needed]
|
| 198 |
-
|
| 199 |
-
## Model Card Contact
|
| 200 |
-
|
| 201 |
-
[More Information Needed]
|
|
|
|
| 3 |
tags:
|
| 4 |
- trl
|
| 5 |
- grpo
|
| 6 |
+
- tldr
|
| 7 |
+
- summarization
|
| 8 |
---
|
| 9 |
|
| 10 |
+
# SmolLM2-1.7B-TLDR
|
| 11 |
|
| 12 |
+
This model is a fine-tuned version of [SmolLM2-1.7B-Instruct](https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct), optimized for generating concise summaries of long texts (TL;DR - Too Long; Didn't Read). It was trained using Group Relative Policy Optimization (GRPO) to improve the model's ability to extract key information from longer documents while maintaining brevity.
|
| 13 |
|
| 14 |
+
## Demo
|
| 15 |
|
| 16 |
+
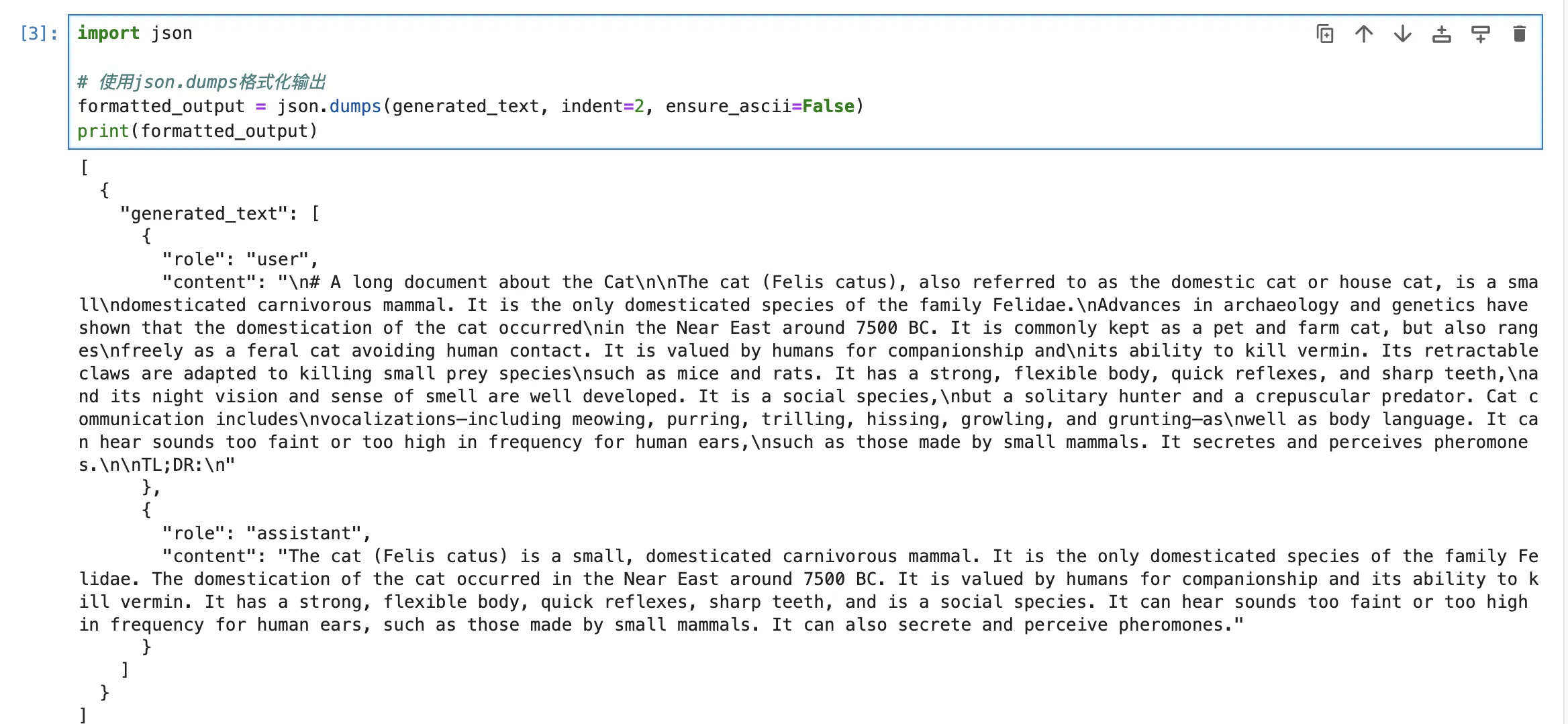
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 17 |
|
| 18 |
## Uses
|
| 19 |
|
| 20 |
+
This model is specifically designed for text summarization tasks, particularly producing TL;DR versions of longer documents. The model works best when prompted with a long text followed by "TL;DR:" to indicate where the summary should begin.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 21 |
|
| 22 |
+
Example usage:
|
| 23 |
|
| 24 |
+
```python
|
| 25 |
+
from transformers import pipeline
|
| 26 |
|
| 27 |
+
generator = pipeline("text-generation", model="real-jiakai/SmolLM2-1.7B-TLDR")
|
| 28 |
|
| 29 |
+
messages = [
|
| 30 |
+
{"role": "user", "content": "Your long text here...\n\nTL;DR:"}
|
| 31 |
+
]
|
| 32 |
|
| 33 |
+
generate_kwargs = {
|
| 34 |
+
"max_new_tokens": 256,
|
| 35 |
+
"do_sample": True,
|
| 36 |
+
"temperature": 0.5,
|
| 37 |
+
"min_p": 0.1,
|
| 38 |
+
}
|
| 39 |
|
| 40 |
+
generated_text = generator(messages, **generate_kwargs)
|
| 41 |
|
| 42 |
+
print(generated_text)
|
| 43 |
+
```
|
| 44 |
|
| 45 |
## Training Details
|
| 46 |
|
| 47 |
### Training Data
|
| 48 |
|
| 49 |
+
The model was fine-tuned on the [mlabonne/smoltldr](https://huggingface.co/datasets/mlabonne/smoltldr) dataset, which contains 2000 training samples of long-form content paired with concise summaries. Each sample consists of a prompt (long text) and a completion (summary).
|
|
|
|
|
|
|
| 50 |
|
| 51 |
### Training Procedure
|
| 52 |
|
| 53 |
+
The model was trained using the TRL (Transformer Reinforcement Learning) library's GRPOTrainer with the following configuration:
|
| 54 |
+
|
| 55 |
+
### Training Hyperparameters
|
| 56 |
+
|
| 57 |
+
- **Learning rate:** 2e-5
|
| 58 |
+
- **Batch size:** 2 per device
|
| 59 |
+
- **Gradient accumulation steps:** 8
|
| 60 |
+
- **Training epochs:** 1
|
| 61 |
+
- **Max prompt length:** 512
|
| 62 |
+
- **Max completion length:** 96
|
| 63 |
+
- **Number of generations per prompt:** 4
|
| 64 |
+
- **Optimizer:** AdamW 8-bit
|
| 65 |
+
- **Precision:** BF16
|
| 66 |
+
- **Reward function:** Length-based optimization targeting concise summaries
|
| 67 |
+
|
| 68 |
+
The training process utilized LoRA (Low-Rank Adaptation) for parameter-efficient fine-tuning with the following configuration:
|
| 69 |
+
- **LoRA rank (r):** 16
|
| 70 |
+
- **LoRA alpha:** 32
|
| 71 |
+
- **Target modules:** All linear layers
|
| 72 |
+
|
| 73 |
+
### Training Process
|
| 74 |
+
|
| 75 |
+
Training showed a progression of loss values from near-zero to approximately 0.01 over 125 steps, indicating gradual learning of the summarization task through reinforcement. The complete training process took approximately 1 hour on two NVIDIA RTX 4090 GPUs.
|
| 76 |
+
|
| 77 |
+
## Citation
|
| 78 |
+
```bash
|
| 79 |
+
@misc{allal2025smollm2smolgoesbig,
|
| 80 |
+
title={SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model},
|
| 81 |
+
author={Loubna Ben Allal and Anton Lozhkov and Elie Bakouch and Gabriel Martín Blázquez and Guilherme Penedo and Lewis Tunstall and Andrés Marafioti and Hynek Kydlíček and Agustín Piqueres Lajarín and Vaibhav Srivastav and Joshua Lochner and Caleb Fahlgren and Xuan-Son Nguyen and Clémentine Fourrier and Ben Burtenshaw and Hugo Larcher and Haojun Zhao and Cyril Zakka and Mathieu Morlon and Colin Raffel and Leandro von Werra and Thomas Wolf},
|
| 82 |
+
year={2025},
|
| 83 |
+
eprint={2502.02737},
|
| 84 |
+
archivePrefix={arXiv},
|
| 85 |
+
primaryClass={cs.CL},
|
| 86 |
+
url={https://arxiv.org/abs/2502.02737},
|
| 87 |
+
}
|
| 88 |
+
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|