Spaces:
Running
on
Zero

Running
on
Zero
Upload 110 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +3 -0
- .gitignore +10 -0
- EVAL.md +78 -0
- LICENSE +201 -0
- TRAIN.md +133 -0
- app.py +505 -0
- assets/arch.png +3 -0
- assets/emerging_curves.png +3 -0
- assets/teaser.webp +3 -0
- data/__init__.py +2 -0
- data/configs/example.yaml +45 -0
- data/data_utils.py +177 -0
- data/dataset_base.py +620 -0
- data/dataset_info.py +39 -0
- data/distributed_iterable_dataset.py +58 -0
- data/interleave_datasets/__init__.py +5 -0
- data/interleave_datasets/edit_dataset.py +72 -0
- data/interleave_datasets/interleave_t2i_dataset.py +212 -0
- data/parquet_utils.py +90 -0
- data/t2i_dataset.py +128 -0
- data/transforms.py +287 -0
- data/video_utils.py +165 -0
- data/vlm_dataset.py +195 -0
- eval/__init__.py +2 -0
- eval/gen/gen_images_mp.py +238 -0
- eval/gen/gen_images_mp_wise.py +365 -0
- eval/gen/geneval/evaluation/download_models.sh +20 -0
- eval/gen/geneval/evaluation/evaluate_images.py +304 -0
- eval/gen/geneval/evaluation/evaluate_images_mp.py +332 -0
- eval/gen/geneval/evaluation/object_names.txt +80 -0
- eval/gen/geneval/evaluation/summary_scores.py +64 -0
- eval/gen/geneval/prompts/create_prompts.py +194 -0
- eval/gen/geneval/prompts/evaluation_metadata.jsonl +553 -0
- eval/gen/geneval/prompts/evaluation_metadata_long.jsonl +0 -0
- eval/gen/geneval/prompts/generation_prompts.txt +553 -0
- eval/gen/geneval/prompts/object_names.txt +80 -0
- eval/gen/wise/cal_score.py +162 -0
- eval/gen/wise/final_data.json +0 -0
- eval/gen/wise/gpt_eval_mp.py +268 -0
- eval/vlm/__init__.py +2 -0
- eval/vlm/eval/mathvista/calculate_score.py +271 -0
- eval/vlm/eval/mathvista/evaluate_mathvista.py +210 -0
- eval/vlm/eval/mathvista/extract_answer.py +160 -0
- eval/vlm/eval/mathvista/extract_answer_mp.py +161 -0
- eval/vlm/eval/mathvista/prompts/ext_ans.py +51 -0
- eval/vlm/eval/mathvista/utilities.py +229 -0
- eval/vlm/eval/mmbench/evaluate_mmbench.py +283 -0
- eval/vlm/eval/mme/Your_Results/OCR.txt +40 -0
- eval/vlm/eval/mme/Your_Results/artwork.txt +400 -0
- eval/vlm/eval/mme/Your_Results/celebrity.txt +340 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/arch.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
assets/emerging_curves.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
assets/teaser.webp filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
wandb
|
| 2 |
+
__pycache__
|
| 3 |
+
.vscode
|
| 4 |
+
notebooks
|
| 5 |
+
results
|
| 6 |
+
*.ipynb_checkpoints
|
| 7 |
+
eval_results
|
| 8 |
+
tests
|
| 9 |
+
.DS_Store
|
| 10 |
+
gradio.sh
|
EVAL.md
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# VLM
|
| 2 |
+
We follow [InternVL2](https://internvl.readthedocs.io/en/latest/internvl2.0/evaluation.html) to evaluate the performance on MME, MMBench, MMMU, MMVet, MathVista and MMVP.
|
| 3 |
+
|
| 4 |
+
## Data prepration
|
| 5 |
+
Please follow the [InternVL2](https://internvl.readthedocs.io/en/latest/get_started/eval_data_preparation.html) to prepare the corresponding data. And the link the data under `vlm`.
|
| 6 |
+
|
| 7 |
+
The final directory structure is:
|
| 8 |
+
```shell
|
| 9 |
+
data
|
| 10 |
+
├── MathVista
|
| 11 |
+
├── mmbench
|
| 12 |
+
├── mme
|
| 13 |
+
├── MMMU
|
| 14 |
+
├── mm-vet
|
| 15 |
+
└── MMVP
|
| 16 |
+
```
|
| 17 |
+
|
| 18 |
+
## Evaluation
|
| 19 |
+
|
| 20 |
+
Directly run `scripts/eval/run_eval_vlm.sh` to evaluate different benchmarks. The output will be saved in `$output_path`.
|
| 21 |
+
- Set `$model_path` and `$output_path` for the path for checkpoint and log.
|
| 22 |
+
- Increase `GPUS` if you want to run faster.
|
| 23 |
+
- For MMBench, please use the official [evaluation server](https://mmbench.opencompass.org.cn/mmbench-submission).
|
| 24 |
+
- For MMVet, please use the official [evaluation server](https://huggingface.co/spaces/whyu/MM-Vet_Evaluator).
|
| 25 |
+
- For MathVista, please set `$openai_api_key` in `scripts/eval/run_eval_vlm.sh` and `your_api_url` in `eval/vlm/eval/mathvista/utilities.py`. The default GPT version is `gpt-4o-2024-11-20`.
|
| 26 |
+
- For MMMU, we use CoT in the report, which improve the accuracy by about 2%. For evaluation of the oprn-ended answer, we use GPT-4o for judgement.
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
# GenEval
|
| 30 |
+
We modify the code in [GenEval](https://github.com/djghosh13/geneval/tree/main) for faster evaluation.
|
| 31 |
+
|
| 32 |
+
## Setup
|
| 33 |
+
Install the following dependencies:
|
| 34 |
+
```shell
|
| 35 |
+
pip install open-clip-torch
|
| 36 |
+
pip install clip-benchmark
|
| 37 |
+
pip install --upgrade setuptools
|
| 38 |
+
|
| 39 |
+
sudo pip install -U openmim
|
| 40 |
+
sudo mim install mmengine mmcv-full==1.7.2
|
| 41 |
+
|
| 42 |
+
git clone https://github.com/open-mmlab/mmdetection.git
|
| 43 |
+
cd mmdetection; git checkout 2.x
|
| 44 |
+
pip install -v -e .
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
Download Detector:
|
| 48 |
+
```shell
|
| 49 |
+
cd ./eval/gen/geneval
|
| 50 |
+
mkdir model
|
| 51 |
+
|
| 52 |
+
bash ./evaluation/download_models.sh ./model
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
## Evaluation
|
| 56 |
+
Directly run `scripts/eval/run_geneval.sh` to evaluate GenEVAL. The output will be saved in `$output_path`.
|
| 57 |
+
- Set `$model_path` and `$output_path` for the path for checkpoint and log.
|
| 58 |
+
- Set `metadata_file` to `./eval/gen/geneval/prompts/evaluation_metadata.jsonl` for original GenEval prompts.
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
# WISE
|
| 62 |
+
We modify the code in [WISE](https://github.com/PKU-YuanGroup/WISE/tree/main) for faster evaluation.
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
## Evaluation
|
| 66 |
+
Directly run `scripts/eval/run_wise.sh` to evaluate WISE. The output will be saved in `$output_path`.
|
| 67 |
+
- Set `$model_path` and `$output_path` for the path for checkpoint and log.
|
| 68 |
+
- Set `$openai_api_key` in `scripts/eval/run_wise.sh` and `your_api_url` in `eval/gen/wise/gpt_eval_mp.py`. The default GPT version is `gpt-4o-2024-11-20`.
|
| 69 |
+
- Use `think` for thinking mode.
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
# GEdit-Bench
|
| 74 |
+
Please follow [GEdit-Bench](https://github.com/stepfun-ai/Step1X-Edit/blob/main/GEdit-Bench/EVAL.md) for evaluation.
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
# IntelligentBench
|
| 78 |
+
TBD
|
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
TRAIN.md
ADDED
|
@@ -0,0 +1,133 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Data prepration
|
| 2 |
+
|
| 3 |
+
We provide data examples for **T2I**, **Editing**, and **VLM** tasks. The T2I dataset is generated using [FLUX.1‑dev](https://huggingface.co/black-forest-labs/FLUX.1-dev); the editing examples are randomly sampled from [SEED‑Data‑Edit‑Part3](https://huggingface.co/datasets/AILab-CVC/SEED-Data-Edit-Part2-3); and the VLM set is sourced from [LLaVA‑OneVision‑Data](https://huggingface.co/datasets/lmms-lab/LLaVA-OneVision-Data).
|
| 4 |
+
|
| 5 |
+
We offer examples in both raw-image folder and parquet shard formats. For other data formats, you can use our dataset code as a template and extend it as needed.
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
1. **Download the sample dataset**
|
| 9 |
+
|
| 10 |
+
```bash
|
| 11 |
+
wget -O bagel_example.zip \
|
| 12 |
+
https://lf3-static.bytednsdoc.com/obj/eden-cn/nuhojubrps/bagel_example.zip
|
| 13 |
+
unzip bagel_example.zip -d /data
|
| 14 |
+
```
|
| 15 |
+
2. **Expected hierarchy**
|
| 16 |
+
|
| 17 |
+
```text
|
| 18 |
+
bagel_example
|
| 19 |
+
├── t2i/ # text-to-image (parquet)
|
| 20 |
+
├── editing/ # image editing (parquet)
|
| 21 |
+
│ ├── seedxedit_multi/
|
| 22 |
+
│ └── parquet_info/
|
| 23 |
+
└── vlm/
|
| 24 |
+
├── images/ # JPEG / PNG frames
|
| 25 |
+
└── llava_ov_si.jsonl # vision‑language SFT conversations
|
| 26 |
+
```
|
| 27 |
+
3. Edit every `your_data_path` placeholder in **`data/dataset_info.py`**.
|
| 28 |
+
4. *(Optional)* Extend `DATASET_INFO` with your own parquet shards or JSONL files to mix extra data.
|
| 29 |
+
|
| 30 |
+
---
|
| 31 |
+
|
| 32 |
+
# Training
|
| 33 |
+
|
| 34 |
+
The baseline full‑feature recipe looks like this (replace environment variables with real paths or values):
|
| 35 |
+
|
| 36 |
+
```shell
|
| 37 |
+
torchrun \
|
| 38 |
+
--nnodes=$num_nodes \
|
| 39 |
+
--node_rank=$node_rank \
|
| 40 |
+
--nproc_per_node=8 \
|
| 41 |
+
--master_addr=$master_addr \
|
| 42 |
+
--master_port=$master_port \
|
| 43 |
+
train/pretrain_unified_navit.py \
|
| 44 |
+
--dataset_config_file ./data/configs/example.yaml \
|
| 45 |
+
--llm_path $llm_path \
|
| 46 |
+
--vae_path $vae_path \
|
| 47 |
+
--vit_path $vit_path \
|
| 48 |
+
--use_flex True \
|
| 49 |
+
--resume_from $resume_from \
|
| 50 |
+
--results_dir $output_path \
|
| 51 |
+
--checkpoint_dir $ckpt_path \
|
| 52 |
+
--max_latent_size 64 # 32 for low-resolution pre-training
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
- **When fine-tuning BAGEL, please set `max_latent_size=64` to ensure the correct pretrained weights are loaded.**
|
| 56 |
+
- The sum of num_used_data should be larger than NUM_GPUS x NUM_WORKERS.
|
| 57 |
+
- For T2I-only fine-tuning, set `visual_und=False`; for VLM-only, set `visual_gen=False`.
|
| 58 |
+
|
| 59 |
+
You are encouraged to adjust any of these hyperparameters to fit your GPU budget and the scale of your dataset. If you encounter any issues, please open an issue for assistance. 🎉
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
## Model config
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
| Argument | Default | Description |
|
| 66 |
+
| ---------------------------- | ------------------------------------------- | --------------------------------------------------------------- |
|
| 67 |
+
| `llm_path` | `hf/Qwen2.5-0.5B-Instruct` | Language‑model backbone (HuggingFace repo or local folder). |
|
| 68 |
+
| `vae_path` | `flux/vae/ae.safetensors` | Pre‑trained VAE checkpoint for latent diffusion. |
|
| 69 |
+
| `vit_path` | `hf/siglip-so400m-14-980-flash-attn2-navit` | SigLIP ViT used for image understanding. |
|
| 70 |
+
| `max_latent_size` | `32` | Maximum latent grid side; defines highest generable resolution. |
|
| 71 |
+
| `latent_patch_size` | `2` | VAE pixels represented by one latent patch. |
|
| 72 |
+
| `vit_max_num_patch_per_side` | `70` | Max ViT patches per image side after resizing. |
|
| 73 |
+
| `text_cond_dropout_prob` | `0.1` | Probability to drop text conditioning while training. |
|
| 74 |
+
| `vae_cond_dropout_prob` | `0.3` | Dropout on VAE latent inputs. |
|
| 75 |
+
| `vit_cond_dropout_prob` | `0.3` | Dropout on visual features. |
|
| 76 |
+
|
| 77 |
+
*(See `ModelArguments` for many more options.)*
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
## Data config
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
| Argument | Default | Description |
|
| 84 |
+
| --------------------------- | --------------------------- | --------------------------------------------------------- |
|
| 85 |
+
| `dataset_config_file` | `data/configs/example.yaml` | YAML that groups datasets and assigns sampling weights. |
|
| 86 |
+
| `num_workers` | `4` | Background workers per rank for the PyTorch `DataLoader`. |
|
| 87 |
+
| `prefetch_factor` | `2` | Batches pre‑fetched by each worker. |
|
| 88 |
+
| `max_num_tokens_per_sample` | `16384` | Skip raw samples longer than this. |
|
| 89 |
+
| `max_num_tokens` | `36864` | Hard cap for a packed batch (prevents OOM). |
|
| 90 |
+
| `max_buffer_size` | `50` | Overflow buffer length for oversized samples. |
|
| 91 |
+
| `data_seed` | `42` | Seed for reproducible shuffling and sampling. |
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
## Training config
|
| 95 |
+
|
| 96 |
+
| Argument | Default | Description |
|
| 97 |
+
| -------------------------------------- | ---------------------- | ------------------------------------------------------ |
|
| 98 |
+
| `total_steps` | `500_000` | Optimiser steps to run. |
|
| 99 |
+
| `lr` | `1e-4` | Peak learning rate after warm‑up. |
|
| 100 |
+
| `lr_scheduler` | `constant` | Learning‑rate schedule (`constant` or `cosine`). |
|
| 101 |
+
| `warmup_steps` | `2000` | Linear warm‑up duration. |
|
| 102 |
+
| `ema` | `0.9999` | Exponential moving‑average decay for model weights. |
|
| 103 |
+
| `max_grad_norm` | `1.0` | Gradient‑clipping threshold. |
|
| 104 |
+
| `save_every` | `2000` | Checkpoint frequency (steps). |
|
| 105 |
+
| `visual_gen / visual_und` | `True` | Enable image generation / understanding branches. |
|
| 106 |
+
| `freeze_llm / freeze_vit / freeze_vae` | `False / False / True` | Freeze selected modules to save VRAM or for ablations. |
|
| 107 |
+
| `use_flex` | `True` (in example) | Enable FLEX packing for higher GPU utilisation. |
|
| 108 |
+
| `sharding_strategy` | `HYBRID_SHARD` | FSDP sharding mode. |
|
| 109 |
+
| `num_shard` | `8` | Parameter shards per rank in HYBRID mode. |
|
| 110 |
+
|
| 111 |
+
**Distributed‑launch environment variables**
|
| 112 |
+
|
| 113 |
+
| Var | Meaning |
|
| 114 |
+
| ----------------------------- | --------------------------------- |
|
| 115 |
+
| `num_nodes` / `node_rank` | Multi‑node orchestration indices. |
|
| 116 |
+
| `nproc_per_node` | Number of GPUs per node. |
|
| 117 |
+
| `master_addr` / `master_port` | NCCL rendezvous endpoint. |
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
## Logging config
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
| Argument | Default | Description |
|
| 124 |
+
| ---------------- | --------------------- | ---------------------------------------------------- |
|
| 125 |
+
| `results_dir` | `results` | Root directory for logs and metrics. |
|
| 126 |
+
| `checkpoint_dir` | `results/checkpoints` | Checkpoints are saved here. |
|
| 127 |
+
| `log_every` | `10` | Steps between console / W\&B logs. |
|
| 128 |
+
| `wandb_project` | `bagel` | Weights & Biases project name. |
|
| 129 |
+
| `wandb_name` | `run` | Run name inside the project. |
|
| 130 |
+
| `wandb_offline` | `False` | Switch to offline mode (logs locally, sync later). |
|
| 131 |
+
| `wandb_resume` | `allow` | Resumption policy if an existing run ID is detected. |
|
| 132 |
+
|
| 133 |
+
> **Tip** Export `WANDB_API_KEY` before launching if you want online dashboards.
|
app.py
ADDED
|
@@ -0,0 +1,505 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import numpy as np
|
| 3 |
+
import os
|
| 4 |
+
import torch
|
| 5 |
+
import random
|
| 6 |
+
|
| 7 |
+
from accelerate import infer_auto_device_map, load_checkpoint_and_dispatch, init_empty_weights
|
| 8 |
+
from PIL import Image
|
| 9 |
+
|
| 10 |
+
from data.data_utils import add_special_tokens, pil_img2rgb
|
| 11 |
+
from data.transforms import ImageTransform
|
| 12 |
+
from inferencer import InterleaveInferencer
|
| 13 |
+
from modeling.autoencoder import load_ae
|
| 14 |
+
from modeling.bagel.qwen2_navit import NaiveCache
|
| 15 |
+
from modeling.bagel import (
|
| 16 |
+
BagelConfig, Bagel, Qwen2Config, Qwen2ForCausalLM,
|
| 17 |
+
SiglipVisionConfig, SiglipVisionModel
|
| 18 |
+
)
|
| 19 |
+
from modeling.qwen2 import Qwen2Tokenizer
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
# Model Initialization
|
| 23 |
+
model_path = "/path/to/BAGEL-7B-MoT/weights" #Download from https://huggingface.co/ByteDance-Seed/BAGEL-7B-MoT
|
| 24 |
+
|
| 25 |
+
llm_config = Qwen2Config.from_json_file(os.path.join(model_path, "llm_config.json"))
|
| 26 |
+
llm_config.qk_norm = True
|
| 27 |
+
llm_config.tie_word_embeddings = False
|
| 28 |
+
llm_config.layer_module = "Qwen2MoTDecoderLayer"
|
| 29 |
+
|
| 30 |
+
vit_config = SiglipVisionConfig.from_json_file(os.path.join(model_path, "vit_config.json"))
|
| 31 |
+
vit_config.rope = False
|
| 32 |
+
vit_config.num_hidden_layers -= 1
|
| 33 |
+
|
| 34 |
+
vae_model, vae_config = load_ae(local_path=os.path.join(model_path, "ae.safetensors"))
|
| 35 |
+
|
| 36 |
+
config = BagelConfig(
|
| 37 |
+
visual_gen=True,
|
| 38 |
+
visual_und=True,
|
| 39 |
+
llm_config=llm_config,
|
| 40 |
+
vit_config=vit_config,
|
| 41 |
+
vae_config=vae_config,
|
| 42 |
+
vit_max_num_patch_per_side=70,
|
| 43 |
+
connector_act='gelu_pytorch_tanh',
|
| 44 |
+
latent_patch_size=2,
|
| 45 |
+
max_latent_size=64,
|
| 46 |
+
)
|
| 47 |
+
|
| 48 |
+
with init_empty_weights():
|
| 49 |
+
language_model = Qwen2ForCausalLM(llm_config)
|
| 50 |
+
vit_model = SiglipVisionModel(vit_config)
|
| 51 |
+
model = Bagel(language_model, vit_model, config)
|
| 52 |
+
model.vit_model.vision_model.embeddings.convert_conv2d_to_linear(vit_config, meta=True)
|
| 53 |
+
|
| 54 |
+
tokenizer = Qwen2Tokenizer.from_pretrained(model_path)
|
| 55 |
+
tokenizer, new_token_ids, _ = add_special_tokens(tokenizer)
|
| 56 |
+
|
| 57 |
+
vae_transform = ImageTransform(1024, 512, 16)
|
| 58 |
+
vit_transform = ImageTransform(980, 224, 14)
|
| 59 |
+
|
| 60 |
+
# Model Loading and Multi GPU Infernece Preparing
|
| 61 |
+
device_map = infer_auto_device_map(
|
| 62 |
+
model,
|
| 63 |
+
max_memory={i: "80GiB" for i in range(torch.cuda.device_count())},
|
| 64 |
+
no_split_module_classes=["Bagel", "Qwen2MoTDecoderLayer"],
|
| 65 |
+
)
|
| 66 |
+
|
| 67 |
+
same_device_modules = [
|
| 68 |
+
'language_model.model.embed_tokens',
|
| 69 |
+
'time_embedder',
|
| 70 |
+
'latent_pos_embed',
|
| 71 |
+
'vae2llm',
|
| 72 |
+
'llm2vae',
|
| 73 |
+
'connector',
|
| 74 |
+
'vit_pos_embed'
|
| 75 |
+
]
|
| 76 |
+
|
| 77 |
+
if torch.cuda.device_count() == 1:
|
| 78 |
+
first_device = device_map.get(same_device_modules[0], "cuda:0")
|
| 79 |
+
for k in same_device_modules:
|
| 80 |
+
if k in device_map:
|
| 81 |
+
device_map[k] = first_device
|
| 82 |
+
else:
|
| 83 |
+
device_map[k] = "cuda:0"
|
| 84 |
+
else:
|
| 85 |
+
first_device = device_map.get(same_device_modules[0])
|
| 86 |
+
for k in same_device_modules:
|
| 87 |
+
if k in device_map:
|
| 88 |
+
device_map[k] = first_device
|
| 89 |
+
|
| 90 |
+
model = load_checkpoint_and_dispatch(
|
| 91 |
+
model,
|
| 92 |
+
checkpoint=os.path.join(model_path, "ema.safetensors"),
|
| 93 |
+
device_map=device_map,
|
| 94 |
+
offload_buffers=True,
|
| 95 |
+
dtype=torch.bfloat16,
|
| 96 |
+
force_hooks=True,
|
| 97 |
+
).eval()
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
# Inferencer Preparing
|
| 101 |
+
inferencer = InterleaveInferencer(
|
| 102 |
+
model=model,
|
| 103 |
+
vae_model=vae_model,
|
| 104 |
+
tokenizer=tokenizer,
|
| 105 |
+
vae_transform=vae_transform,
|
| 106 |
+
vit_transform=vit_transform,
|
| 107 |
+
new_token_ids=new_token_ids,
|
| 108 |
+
)
|
| 109 |
+
|
| 110 |
+
def set_seed(seed):
|
| 111 |
+
"""Set random seeds for reproducibility"""
|
| 112 |
+
if seed > 0:
|
| 113 |
+
random.seed(seed)
|
| 114 |
+
np.random.seed(seed)
|
| 115 |
+
torch.manual_seed(seed)
|
| 116 |
+
if torch.cuda.is_available():
|
| 117 |
+
torch.cuda.manual_seed(seed)
|
| 118 |
+
torch.cuda.manual_seed_all(seed)
|
| 119 |
+
torch.backends.cudnn.deterministic = True
|
| 120 |
+
torch.backends.cudnn.benchmark = False
|
| 121 |
+
return seed
|
| 122 |
+
|
| 123 |
+
# Text to Image function with thinking option and hyperparameters
|
| 124 |
+
def text_to_image(prompt, show_thinking=False, cfg_text_scale=4.0, cfg_interval=0.4,
|
| 125 |
+
timestep_shift=3.0, num_timesteps=50,
|
| 126 |
+
cfg_renorm_min=1.0, cfg_renorm_type="global",
|
| 127 |
+
max_think_token_n=1024, do_sample=False, text_temperature=0.3,
|
| 128 |
+
seed=0, image_ratio="1:1"):
|
| 129 |
+
# Set seed for reproducibility
|
| 130 |
+
set_seed(seed)
|
| 131 |
+
|
| 132 |
+
if image_ratio == "1:1":
|
| 133 |
+
image_shapes = (1024, 1024)
|
| 134 |
+
elif image_ratio == "4:3":
|
| 135 |
+
image_shapes = (768, 1024)
|
| 136 |
+
elif image_ratio == "3:4":
|
| 137 |
+
image_shapes = (1024, 768)
|
| 138 |
+
elif image_ratio == "16:9":
|
| 139 |
+
image_shapes = (576, 1024)
|
| 140 |
+
elif image_ratio == "9:16":
|
| 141 |
+
image_shapes = (1024, 576)
|
| 142 |
+
|
| 143 |
+
# Set hyperparameters
|
| 144 |
+
inference_hyper = dict(
|
| 145 |
+
max_think_token_n=max_think_token_n if show_thinking else 1024,
|
| 146 |
+
do_sample=do_sample if show_thinking else False,
|
| 147 |
+
text_temperature=text_temperature if show_thinking else 0.3,
|
| 148 |
+
cfg_text_scale=cfg_text_scale,
|
| 149 |
+
cfg_interval=[cfg_interval, 1.0], # End fixed at 1.0
|
| 150 |
+
timestep_shift=timestep_shift,
|
| 151 |
+
num_timesteps=num_timesteps,
|
| 152 |
+
cfg_renorm_min=cfg_renorm_min,
|
| 153 |
+
cfg_renorm_type=cfg_renorm_type,
|
| 154 |
+
image_shapes=image_shapes,
|
| 155 |
+
)
|
| 156 |
+
|
| 157 |
+
# Call inferencer with or without think parameter based on user choice
|
| 158 |
+
result = inferencer(text=prompt, think=show_thinking, **inference_hyper)
|
| 159 |
+
return result["image"], result.get("text", None)
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
# Image Understanding function with thinking option and hyperparameters
|
| 163 |
+
def image_understanding(image: Image.Image, prompt: str, show_thinking=False,
|
| 164 |
+
do_sample=False, text_temperature=0.3, max_new_tokens=512):
|
| 165 |
+
if image is None:
|
| 166 |
+
return "Please upload an image."
|
| 167 |
+
|
| 168 |
+
if isinstance(image, np.ndarray):
|
| 169 |
+
image = Image.fromarray(image)
|
| 170 |
+
|
| 171 |
+
image = pil_img2rgb(image)
|
| 172 |
+
|
| 173 |
+
# Set hyperparameters
|
| 174 |
+
inference_hyper = dict(
|
| 175 |
+
do_sample=do_sample,
|
| 176 |
+
text_temperature=text_temperature,
|
| 177 |
+
max_think_token_n=max_new_tokens, # Set max_length
|
| 178 |
+
)
|
| 179 |
+
|
| 180 |
+
# Use show_thinking parameter to control thinking process
|
| 181 |
+
result = inferencer(image=image, text=prompt, think=show_thinking,
|
| 182 |
+
understanding_output=True, **inference_hyper)
|
| 183 |
+
return result["text"]
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
# Image Editing function with thinking option and hyperparameters
|
| 187 |
+
def edit_image(image: Image.Image, prompt: str, show_thinking=False, cfg_text_scale=4.0,
|
| 188 |
+
cfg_img_scale=2.0, cfg_interval=0.0,
|
| 189 |
+
timestep_shift=3.0, num_timesteps=50, cfg_renorm_min=1.0,
|
| 190 |
+
cfg_renorm_type="text_channel", max_think_token_n=1024,
|
| 191 |
+
do_sample=False, text_temperature=0.3, seed=0):
|
| 192 |
+
# Set seed for reproducibility
|
| 193 |
+
set_seed(seed)
|
| 194 |
+
|
| 195 |
+
if image is None:
|
| 196 |
+
return "Please upload an image.", ""
|
| 197 |
+
|
| 198 |
+
if isinstance(image, np.ndarray):
|
| 199 |
+
image = Image.fromarray(image)
|
| 200 |
+
|
| 201 |
+
image = pil_img2rgb(image)
|
| 202 |
+
|
| 203 |
+
# Set hyperparameters
|
| 204 |
+
inference_hyper = dict(
|
| 205 |
+
max_think_token_n=max_think_token_n if show_thinking else 1024,
|
| 206 |
+
do_sample=do_sample if show_thinking else False,
|
| 207 |
+
text_temperature=text_temperature if show_thinking else 0.3,
|
| 208 |
+
cfg_text_scale=cfg_text_scale,
|
| 209 |
+
cfg_img_scale=cfg_img_scale,
|
| 210 |
+
cfg_interval=[cfg_interval, 1.0], # End fixed at 1.0
|
| 211 |
+
timestep_shift=timestep_shift,
|
| 212 |
+
num_timesteps=num_timesteps,
|
| 213 |
+
cfg_renorm_min=cfg_renorm_min,
|
| 214 |
+
cfg_renorm_type=cfg_renorm_type,
|
| 215 |
+
)
|
| 216 |
+
|
| 217 |
+
# Include thinking parameter based on user choice
|
| 218 |
+
result = inferencer(image=image, text=prompt, think=show_thinking, **inference_hyper)
|
| 219 |
+
return result["image"], result.get("text", "")
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
# Helper function to load example images
|
| 223 |
+
def load_example_image(image_path):
|
| 224 |
+
try:
|
| 225 |
+
return Image.open(image_path)
|
| 226 |
+
except Exception as e:
|
| 227 |
+
print(f"Error loading example image: {e}")
|
| 228 |
+
return None
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
# Gradio UI
|
| 232 |
+
with gr.Blocks() as demo:
|
| 233 |
+
gr.Markdown("""
|
| 234 |
+
<div>
|
| 235 |
+
<img src="https://lf3-static.bytednsdoc.com/obj/eden-cn/nuhojubrps/banner.png" alt="BAGEL" width="380"/>
|
| 236 |
+
</div>
|
| 237 |
+
""")
|
| 238 |
+
|
| 239 |
+
with gr.Tab("📝 Text to Image"):
|
| 240 |
+
txt_input = gr.Textbox(
|
| 241 |
+
label="Prompt",
|
| 242 |
+
value="A female cosplayer portraying an ethereal fairy or elf, wearing a flowing dress made of delicate fabrics in soft, mystical colors like emerald green and silver. She has pointed ears, a gentle, enchanting expression, and her outfit is adorned with sparkling jewels and intricate patterns. The background is a magical forest with glowing plants, mystical creatures, and a serene atmosphere."
|
| 243 |
+
)
|
| 244 |
+
|
| 245 |
+
with gr.Row():
|
| 246 |
+
show_thinking = gr.Checkbox(label="Thinking", value=False)
|
| 247 |
+
|
| 248 |
+
# Add hyperparameter controls in an accordion
|
| 249 |
+
with gr.Accordion("Inference Hyperparameters", open=False):
|
| 250 |
+
# 参数一排两个布局
|
| 251 |
+
with gr.Group():
|
| 252 |
+
with gr.Row():
|
| 253 |
+
seed = gr.Slider(minimum=0, maximum=1000000, value=0, step=1,
|
| 254 |
+
label="Seed", info="0 for random seed, positive for reproducible results")
|
| 255 |
+
image_ratio = gr.Dropdown(choices=["1:1", "4:3", "3:4", "16:9", "9:16"],
|
| 256 |
+
value="1:1", label="Image Ratio",
|
| 257 |
+
info="The longer size is fixed to 1024")
|
| 258 |
+
|
| 259 |
+
with gr.Row():
|
| 260 |
+
cfg_text_scale = gr.Slider(minimum=1.0, maximum=8.0, value=4.0, step=0.1, interactive=True,
|
| 261 |
+
label="CFG Text Scale", info="Controls how strongly the model follows the text prompt (4.0-8.0)")
|
| 262 |
+
cfg_interval = gr.Slider(minimum=0.0, maximum=1.0, value=0.4, step=0.1,
|
| 263 |
+
label="CFG Interval", info="Start of CFG application interval (end is fixed at 1.0)")
|
| 264 |
+
|
| 265 |
+
with gr.Row():
|
| 266 |
+
cfg_renorm_type = gr.Dropdown(choices=["global", "local", "text_channel"],
|
| 267 |
+
value="global", label="CFG Renorm Type",
|
| 268 |
+
info="If the genrated image is blurry, use 'global'")
|
| 269 |
+
cfg_renorm_min = gr.Slider(minimum=0.0, maximum=1.0, value=0.0, step=0.1, interactive=True,
|
| 270 |
+
label="CFG Renorm Min", info="1.0 disables CFG-Renorm")
|
| 271 |
+
|
| 272 |
+
with gr.Row():
|
| 273 |
+
num_timesteps = gr.Slider(minimum=10, maximum=100, value=50, step=5, interactive=True,
|
| 274 |
+
label="Timesteps", info="Total denoising steps")
|
| 275 |
+
timestep_shift = gr.Slider(minimum=1.0, maximum=5.0, value=3.0, step=0.5, interactive=True,
|
| 276 |
+
label="Timestep Shift", info="Higher values for layout, lower for details")
|
| 277 |
+
|
| 278 |
+
# Thinking parameters in a single row
|
| 279 |
+
thinking_params = gr.Group(visible=False)
|
| 280 |
+
with thinking_params:
|
| 281 |
+
with gr.Row():
|
| 282 |
+
do_sample = gr.Checkbox(label="Sampling", value=False, info="Enable sampling for text generation")
|
| 283 |
+
max_think_token_n = gr.Slider(minimum=64, maximum=4006, value=1024, step=64, interactive=True,
|
| 284 |
+
label="Max Think Tokens", info="Maximum number of tokens for thinking")
|
| 285 |
+
text_temperature = gr.Slider(minimum=0.1, maximum=1.0, value=0.3, step=0.1, interactive=True,
|
| 286 |
+
label="Temperature", info="Controls randomness in text generation")
|
| 287 |
+
|
| 288 |
+
thinking_output = gr.Textbox(label="Thinking Process", visible=False)
|
| 289 |
+
img_output = gr.Image(label="Generated Image")
|
| 290 |
+
gen_btn = gr.Button("Generate")
|
| 291 |
+
|
| 292 |
+
# Dynamically show/hide thinking process box and parameters
|
| 293 |
+
def update_thinking_visibility(show):
|
| 294 |
+
return gr.update(visible=show), gr.update(visible=show)
|
| 295 |
+
|
| 296 |
+
show_thinking.change(
|
| 297 |
+
fn=update_thinking_visibility,
|
| 298 |
+
inputs=[show_thinking],
|
| 299 |
+
outputs=[thinking_output, thinking_params]
|
| 300 |
+
)
|
| 301 |
+
|
| 302 |
+
# Process function based on thinking option and hyperparameters
|
| 303 |
+
def process_text_to_image(prompt, show_thinking, cfg_text_scale,
|
| 304 |
+
cfg_interval, timestep_shift,
|
| 305 |
+
num_timesteps, cfg_renorm_min, cfg_renorm_type,
|
| 306 |
+
max_think_token_n, do_sample, text_temperature, seed, image_ratio):
|
| 307 |
+
image, thinking = text_to_image(
|
| 308 |
+
prompt, show_thinking, cfg_text_scale, cfg_interval,
|
| 309 |
+
timestep_shift, num_timesteps,
|
| 310 |
+
cfg_renorm_min, cfg_renorm_type,
|
| 311 |
+
max_think_token_n, do_sample, text_temperature, seed, image_ratio
|
| 312 |
+
)
|
| 313 |
+
return image, thinking if thinking else ""
|
| 314 |
+
|
| 315 |
+
gen_btn.click(
|
| 316 |
+
fn=process_text_to_image,
|
| 317 |
+
inputs=[
|
| 318 |
+
txt_input, show_thinking, cfg_text_scale,
|
| 319 |
+
cfg_interval, timestep_shift,
|
| 320 |
+
num_timesteps, cfg_renorm_min, cfg_renorm_type,
|
| 321 |
+
max_think_token_n, do_sample, text_temperature, seed, image_ratio
|
| 322 |
+
],
|
| 323 |
+
outputs=[img_output, thinking_output]
|
| 324 |
+
)
|
| 325 |
+
|
| 326 |
+
with gr.Tab("🖌️ Image Edit"):
|
| 327 |
+
with gr.Row():
|
| 328 |
+
with gr.Column(scale=1):
|
| 329 |
+
edit_image_input = gr.Image(label="Input Image", value=load_example_image('test_images/women.jpg'))
|
| 330 |
+
edit_prompt = gr.Textbox(
|
| 331 |
+
label="Prompt",
|
| 332 |
+
value="She boards a modern subway, quietly reading a folded newspaper, wearing the same clothes."
|
| 333 |
+
)
|
| 334 |
+
|
| 335 |
+
with gr.Column(scale=1):
|
| 336 |
+
edit_image_output = gr.Image(label="Result")
|
| 337 |
+
edit_thinking_output = gr.Textbox(label="Thinking Process", visible=False)
|
| 338 |
+
|
| 339 |
+
with gr.Row():
|
| 340 |
+
edit_show_thinking = gr.Checkbox(label="Thinking", value=False)
|
| 341 |
+
|
| 342 |
+
# Add hyperparameter controls in an accordion
|
| 343 |
+
with gr.Accordion("Inference Hyperparameters", open=False):
|
| 344 |
+
with gr.Group():
|
| 345 |
+
with gr.Row():
|
| 346 |
+
edit_seed = gr.Slider(minimum=0, maximum=1000000, value=0, step=1, interactive=True,
|
| 347 |
+
label="Seed", info="0 for random seed, positive for reproducible results")
|
| 348 |
+
edit_cfg_text_scale = gr.Slider(minimum=1.0, maximum=8.0, value=4.0, step=0.1, interactive=True,
|
| 349 |
+
label="CFG Text Scale", info="Controls how strongly the model follows the text prompt")
|
| 350 |
+
|
| 351 |
+
with gr.Row():
|
| 352 |
+
edit_cfg_img_scale = gr.Slider(minimum=1.0, maximum=4.0, value=2.0, step=0.1, interactive=True,
|
| 353 |
+
label="CFG Image Scale", info="Controls how much the model preserves input image details")
|
| 354 |
+
edit_cfg_interval = gr.Slider(minimum=0.0, maximum=1.0, value=0.0, step=0.1, interactive=True,
|
| 355 |
+
label="CFG Interval", info="Start of CFG application interval (end is fixed at 1.0)")
|
| 356 |
+
|
| 357 |
+
with gr.Row():
|
| 358 |
+
edit_cfg_renorm_type = gr.Dropdown(choices=["global", "local", "text_channel"],
|
| 359 |
+
value="text_channel", label="CFG Renorm Type",
|
| 360 |
+
info="If the genrated image is blurry, use 'global")
|
| 361 |
+
edit_cfg_renorm_min = gr.Slider(minimum=0.0, maximum=1.0, value=0.0, step=0.1, interactive=True,
|
| 362 |
+
label="CFG Renorm Min", info="1.0 disables CFG-Renorm")
|
| 363 |
+
|
| 364 |
+
with gr.Row():
|
| 365 |
+
edit_num_timesteps = gr.Slider(minimum=10, maximum=100, value=50, step=5, interactive=True,
|
| 366 |
+
label="Timesteps", info="Total denoising steps")
|
| 367 |
+
edit_timestep_shift = gr.Slider(minimum=1.0, maximum=10.0, value=3.0, step=0.5, interactive=True,
|
| 368 |
+
label="Timestep Shift", info="Higher values for layout, lower for details")
|
| 369 |
+
|
| 370 |
+
|
| 371 |
+
# Thinking parameters in a single row
|
| 372 |
+
edit_thinking_params = gr.Group(visible=False)
|
| 373 |
+
with edit_thinking_params:
|
| 374 |
+
with gr.Row():
|
| 375 |
+
edit_do_sample = gr.Checkbox(label="Sampling", value=False, info="Enable sampling for text generation")
|
| 376 |
+
edit_max_think_token_n = gr.Slider(minimum=64, maximum=4006, value=1024, step=64, interactive=True,
|
| 377 |
+
label="Max Think Tokens", info="Maximum number of tokens for thinking")
|
| 378 |
+
edit_text_temperature = gr.Slider(minimum=0.1, maximum=1.0, value=0.3, step=0.1, interactive=True,
|
| 379 |
+
label="Temperature", info="Controls randomness in text generation")
|
| 380 |
+
|
| 381 |
+
edit_btn = gr.Button("Submit")
|
| 382 |
+
|
| 383 |
+
# Dynamically show/hide thinking process box for editing
|
| 384 |
+
def update_edit_thinking_visibility(show):
|
| 385 |
+
return gr.update(visible=show), gr.update(visible=show)
|
| 386 |
+
|
| 387 |
+
edit_show_thinking.change(
|
| 388 |
+
fn=update_edit_thinking_visibility,
|
| 389 |
+
inputs=[edit_show_thinking],
|
| 390 |
+
outputs=[edit_thinking_output, edit_thinking_params]
|
| 391 |
+
)
|
| 392 |
+
|
| 393 |
+
# Process editing with thinking option and hyperparameters
|
| 394 |
+
def process_edit_image(image, prompt, show_thinking, cfg_text_scale,
|
| 395 |
+
cfg_img_scale, cfg_interval,
|
| 396 |
+
timestep_shift, num_timesteps, cfg_renorm_min,
|
| 397 |
+
cfg_renorm_type, max_think_token_n, do_sample,
|
| 398 |
+
text_temperature, seed):
|
| 399 |
+
edited_image, thinking = edit_image(
|
| 400 |
+
image, prompt, show_thinking, cfg_text_scale, cfg_img_scale,
|
| 401 |
+
cfg_interval, timestep_shift,
|
| 402 |
+
num_timesteps, cfg_renorm_min, cfg_renorm_type,
|
| 403 |
+
max_think_token_n, do_sample, text_temperature, seed
|
| 404 |
+
)
|
| 405 |
+
|
| 406 |
+
return edited_image, thinking if thinking else ""
|
| 407 |
+
|
| 408 |
+
edit_btn.click(
|
| 409 |
+
fn=process_edit_image,
|
| 410 |
+
inputs=[
|
| 411 |
+
edit_image_input, edit_prompt, edit_show_thinking,
|
| 412 |
+
edit_cfg_text_scale, edit_cfg_img_scale, edit_cfg_interval,
|
| 413 |
+
edit_timestep_shift, edit_num_timesteps,
|
| 414 |
+
edit_cfg_renorm_min, edit_cfg_renorm_type,
|
| 415 |
+
edit_max_think_token_n, edit_do_sample, edit_text_temperature, edit_seed
|
| 416 |
+
],
|
| 417 |
+
outputs=[edit_image_output, edit_thinking_output]
|
| 418 |
+
)
|
| 419 |
+
|
| 420 |
+
with gr.Tab("🖼️ Image Understanding"):
|
| 421 |
+
with gr.Row():
|
| 422 |
+
with gr.Column(scale=1):
|
| 423 |
+
img_input = gr.Image(label="Input Image", value=load_example_image('test_images/meme.jpg'))
|
| 424 |
+
understand_prompt = gr.Textbox(
|
| 425 |
+
label="Prompt",
|
| 426 |
+
value="Can someone explain what's funny about this meme??"
|
| 427 |
+
)
|
| 428 |
+
|
| 429 |
+
with gr.Column(scale=1):
|
| 430 |
+
txt_output = gr.Textbox(label="Result", lines=20)
|
| 431 |
+
|
| 432 |
+
with gr.Row():
|
| 433 |
+
understand_show_thinking = gr.Checkbox(label="Thinking", value=False)
|
| 434 |
+
|
| 435 |
+
# Add hyperparameter controls in an accordion
|
| 436 |
+
with gr.Accordion("Inference Hyperparameters", open=False):
|
| 437 |
+
with gr.Row():
|
| 438 |
+
understand_do_sample = gr.Checkbox(label="Sampling", value=False, info="Enable sampling for text generation")
|
| 439 |
+
understand_text_temperature = gr.Slider(minimum=0.0, maximum=1.0, value=0.3, step=0.05, interactive=True,
|
| 440 |
+
label="Temperature", info="Controls randomness in text generation (0=deterministic, 1=creative)")
|
| 441 |
+
understand_max_new_tokens = gr.Slider(minimum=64, maximum=4096, value=512, step=64, interactive=True,
|
| 442 |
+
label="Max New Tokens", info="Maximum length of generated text, including potential thinking")
|
| 443 |
+
|
| 444 |
+
img_understand_btn = gr.Button("Submit")
|
| 445 |
+
|
| 446 |
+
# Process understanding with thinking option and hyperparameters
|
| 447 |
+
def process_understanding(image, prompt, show_thinking, do_sample,
|
| 448 |
+
text_temperature, max_new_tokens):
|
| 449 |
+
result = image_understanding(
|
| 450 |
+
image, prompt, show_thinking, do_sample,
|
| 451 |
+
text_temperature, max_new_tokens
|
| 452 |
+
)
|
| 453 |
+
return result
|
| 454 |
+
|
| 455 |
+
img_understand_btn.click(
|
| 456 |
+
fn=process_understanding,
|
| 457 |
+
inputs=[
|
| 458 |
+
img_input, understand_prompt, understand_show_thinking,
|
| 459 |
+
understand_do_sample, understand_text_temperature, understand_max_new_tokens
|
| 460 |
+
],
|
| 461 |
+
outputs=txt_output
|
| 462 |
+
)
|
| 463 |
+
|
| 464 |
+
gr.Markdown("""
|
| 465 |
+
<div style="display: flex; justify-content: flex-start; flex-wrap: wrap; gap: 10px;">
|
| 466 |
+
<a href="https://bagel-ai.org/">
|
| 467 |
+
<img
|
| 468 |
+
src="https://img.shields.io/badge/BAGEL-Website-0A66C2?logo=safari&logoColor=white"
|
| 469 |
+
alt="BAGEL Website"
|
| 470 |
+
/>
|
| 471 |
+
</a>
|
| 472 |
+
<a href="https://arxiv.org/abs/2505.14683">
|
| 473 |
+
<img
|
| 474 |
+
src="https://img.shields.io/badge/BAGEL-Paper-red?logo=arxiv&logoColor=red"
|
| 475 |
+
alt="BAGEL Paper on arXiv"
|
| 476 |
+
/>
|
| 477 |
+
</a>
|
| 478 |
+
<a href="https://huggingface.co/ByteDance-Seed/BAGEL-7B-MoT">
|
| 479 |
+
<img
|
| 480 |
+
src="https://img.shields.io/badge/BAGEL-Hugging%20Face-orange?logo=huggingface&logoColor=yellow"
|
| 481 |
+
alt="BAGEL on Hugging Face"
|
| 482 |
+
/>
|
| 483 |
+
</a>
|
| 484 |
+
<a href="https://demo.bagel-ai.org/">
|
| 485 |
+
<img
|
| 486 |
+
src="https://img.shields.io/badge/BAGEL-Demo-blue?logo=googleplay&logoColor=blue"
|
| 487 |
+
alt="BAGEL Demo"
|
| 488 |
+
/>
|
| 489 |
+
</a>
|
| 490 |
+
<a href="https://discord.gg/Z836xxzy">
|
| 491 |
+
<img
|
| 492 |
+
src="https://img.shields.io/badge/BAGEL-Discord-5865F2?logo=discord&logoColor=purple"
|
| 493 |
+
alt="BAGEL Discord"
|
| 494 |
+
/>
|
| 495 |
+
</a>
|
| 496 |
+
<a href="mailto:[email protected]">
|
| 497 |
+
<img
|
| 498 |
+
src="https://img.shields.io/badge/BAGEL-Email-D14836?logo=gmail&logoColor=red"
|
| 499 |
+
alt="BAGEL Email"
|
| 500 |
+
/>
|
| 501 |
+
</a>
|
| 502 |
+
</div>
|
| 503 |
+
""")
|
| 504 |
+
|
| 505 |
+
demo.launch(share=True)
|
assets/arch.png
ADDED
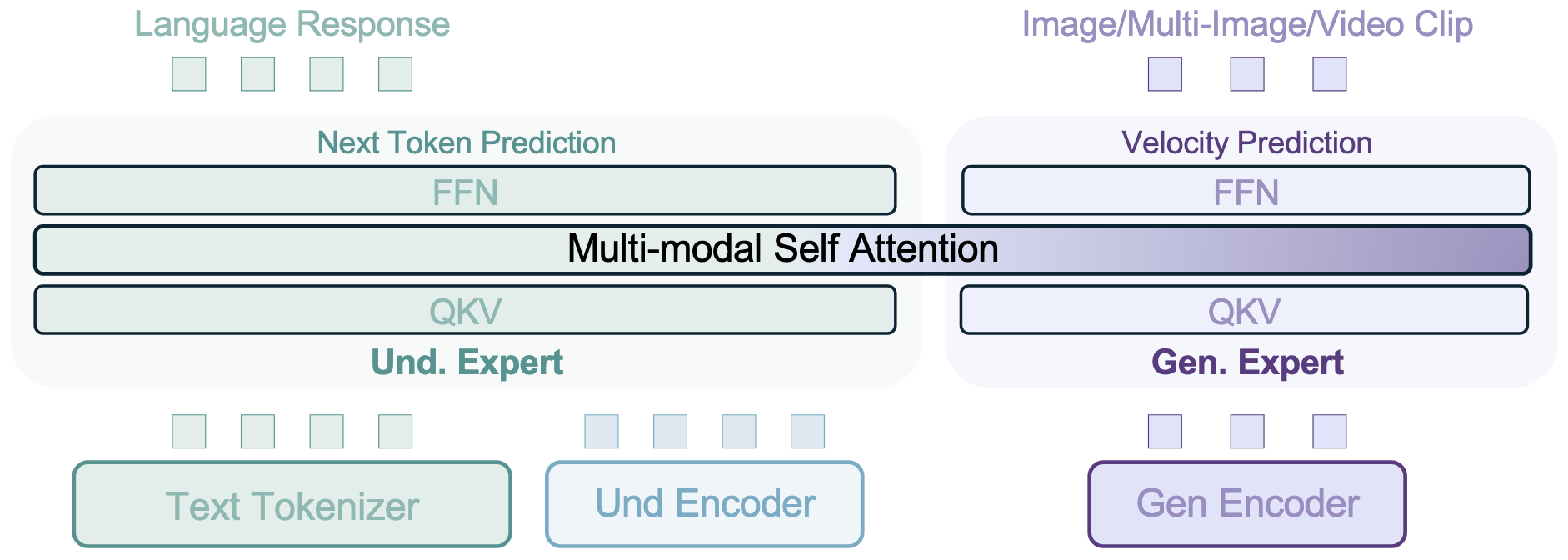
|
Git LFS Details
|
assets/emerging_curves.png
ADDED
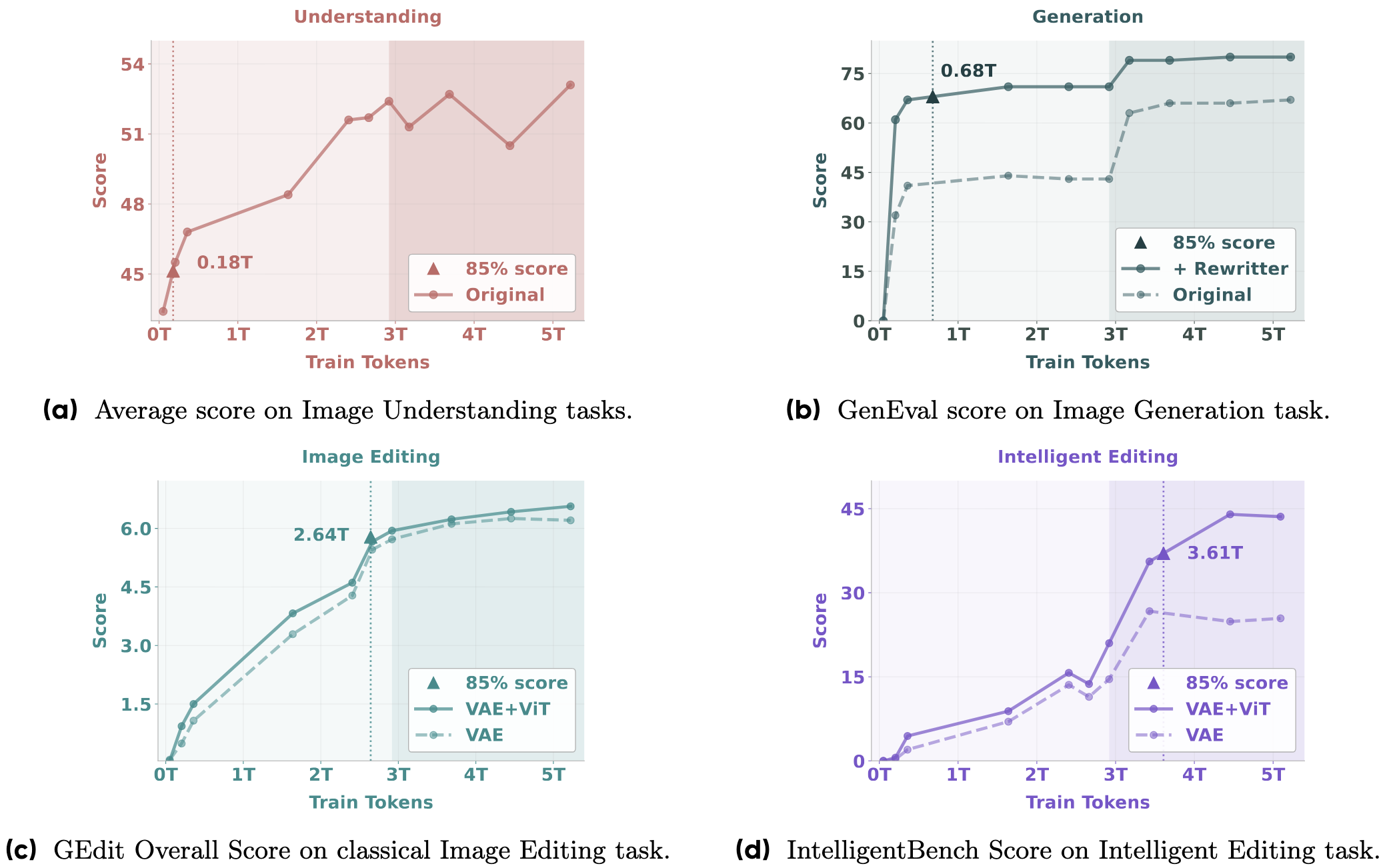
|
Git LFS Details
|
assets/teaser.webp
ADDED

|
Git LFS Details
|
data/__init__.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2025 Bytedance Ltd. and/or its affiliates.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2.0
|
data/configs/example.yaml
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
t2i_pretrain:
|
| 2 |
+
dataset_names:
|
| 3 |
+
- t2i
|
| 4 |
+
image_transform_args:
|
| 5 |
+
image_stride: 16
|
| 6 |
+
max_image_size: 1024
|
| 7 |
+
min_image_size: 512
|
| 8 |
+
is_mandatory: true
|
| 9 |
+
num_used_data: # The sum should be larger that NUM_GPUS x NUM_WORKERS
|
| 10 |
+
- 10
|
| 11 |
+
weight: 1
|
| 12 |
+
|
| 13 |
+
unified_edit:
|
| 14 |
+
dataset_names:
|
| 15 |
+
- seedxedit_multi
|
| 16 |
+
image_transform_args:
|
| 17 |
+
image_stride: 16
|
| 18 |
+
max_image_size: 1024
|
| 19 |
+
min_image_size: 512
|
| 20 |
+
vit_image_transform_args:
|
| 21 |
+
image_stride: 14
|
| 22 |
+
max_image_size: 518
|
| 23 |
+
min_image_size: 224
|
| 24 |
+
is_mandatory: false
|
| 25 |
+
num_used_data:
|
| 26 |
+
- 10
|
| 27 |
+
weight: 1
|
| 28 |
+
|
| 29 |
+
vlm_sft:
|
| 30 |
+
dataset_names:
|
| 31 |
+
- llava_ov
|
| 32 |
+
image_transform_args:
|
| 33 |
+
image_stride: 14
|
| 34 |
+
max_image_size: 980
|
| 35 |
+
min_image_size: 378
|
| 36 |
+
max_pixels: 2_007_040
|
| 37 |
+
frame_sampler_args:
|
| 38 |
+
max_num_frames: 12
|
| 39 |
+
min_num_frames: 8
|
| 40 |
+
is_mandatory: true
|
| 41 |
+
shuffle_lines: True
|
| 42 |
+
shuffle_seed: 0
|
| 43 |
+
num_used_data:
|
| 44 |
+
- 1000
|
| 45 |
+
weight: 1
|
data/data_utils.py
ADDED
|
@@ -0,0 +1,177 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2025 Bytedance Ltd. and/or its affiliates.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
import math
|
| 6 |
+
import random
|
| 7 |
+
from PIL import Image
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
from torch.nn.attention.flex_attention import or_masks, and_masks
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def create_sparse_mask(document_lens, split_lens, attn_modes, device):
|
| 14 |
+
def causal_mask(b, h, q_idx, kv_idx):
|
| 15 |
+
return q_idx >= kv_idx
|
| 16 |
+
|
| 17 |
+
def full_and_noise_mask(b, h, q_idx, kv_idx):
|
| 18 |
+
return (full_and_noise_seq_id[q_idx] == full_and_noise_seq_id[kv_idx]) & (full_and_noise_seq_id[q_idx] >= 0)
|
| 19 |
+
|
| 20 |
+
def remove_noise_mask(b, h, q_idx, kv_idx):
|
| 21 |
+
return (~((noise_seq_id[kv_idx] >= 0) & (noise_seq_id[q_idx] != noise_seq_id[kv_idx])))
|
| 22 |
+
|
| 23 |
+
def sample_mask(b, h, q_idx, kv_idx):
|
| 24 |
+
return document_id[q_idx] == document_id[kv_idx]
|
| 25 |
+
|
| 26 |
+
full_and_noise_tmp = []
|
| 27 |
+
noise_tmp = []
|
| 28 |
+
|
| 29 |
+
for i, (length, model) in enumerate(zip(split_lens, attn_modes)):
|
| 30 |
+
value = i if model in ['full', 'noise'] else -1
|
| 31 |
+
full_and_noise_tmp.extend([value] * length)
|
| 32 |
+
value_noise = i if model == 'noise' else -1
|
| 33 |
+
noise_tmp.extend([value_noise] * length)
|
| 34 |
+
|
| 35 |
+
full_and_noise_seq_id = torch.Tensor(full_and_noise_tmp).to(device)
|
| 36 |
+
noise_seq_id = torch.Tensor(noise_tmp).to(device)
|
| 37 |
+
|
| 38 |
+
document_id = torch.cat([torch.full((l,), i) for i, l in enumerate(document_lens, start=1)]).to(device)
|
| 39 |
+
|
| 40 |
+
return and_masks(or_masks(causal_mask, full_and_noise_mask), remove_noise_mask, sample_mask)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def patchify(image, patch_size):
|
| 44 |
+
p = patch_size
|
| 45 |
+
c, h, w = image.shape
|
| 46 |
+
assert h % p == 0 and w % p == 0
|
| 47 |
+
image = image.reshape(c, h // p, p, w // p, p)
|
| 48 |
+
image = torch.einsum("chpwq->hwpqc", image)
|
| 49 |
+
image = image.reshape(-1, p**2 * c)
|
| 50 |
+
return image
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def get_flattened_position_ids_extrapolate(img_h, img_w, patch_size, max_num_patches_per_side):
|
| 54 |
+
num_patches_h, num_patches_w = img_h // patch_size, img_w // patch_size
|
| 55 |
+
coords_h = torch.arange(0, num_patches_h)
|
| 56 |
+
coords_w = torch.arange(0, num_patches_w)
|
| 57 |
+
pos_ids = (coords_h[:, None] * max_num_patches_per_side + coords_w).flatten()
|
| 58 |
+
return pos_ids
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def get_flattened_position_ids_interpolate(img_h, img_w, patch_size, max_num_patches_per_side):
|
| 62 |
+
num_patches_h, num_patches_w = img_h // patch_size, img_w // patch_size
|
| 63 |
+
boundaries = torch.arange(1 / max_num_patches_per_side, 1.0, 1 / max_num_patches_per_side)
|
| 64 |
+
fractional_coords_h = torch.arange(0, 1 - 1e-6, 1 / num_patches_h)
|
| 65 |
+
fractional_coords_w = torch.arange(0, 1 - 1e-6, 1 / num_patches_w)
|
| 66 |
+
bucket_coords_h = torch.bucketize(fractional_coords_h, boundaries, right=True)
|
| 67 |
+
bucket_coords_w = torch.bucketize(fractional_coords_w, boundaries, right=True)
|
| 68 |
+
pos_ids = (bucket_coords_h[:, None] * max_num_patches_per_side + bucket_coords_w).flatten()
|
| 69 |
+
return pos_ids
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def prepare_attention_mask_per_sample(split_lens, attn_modes, device="cpu"):
|
| 73 |
+
"""
|
| 74 |
+
nested_split_lens: A list of N lists of ints. Each int indicates the length of a split within
|
| 75 |
+
a sample, where each sample contains multiple splits with different attn modes.
|
| 76 |
+
nested_attn_modes: whether to use full attn in each split.
|
| 77 |
+
"""
|
| 78 |
+
sample_len = sum(split_lens)
|
| 79 |
+
attention_mask = torch.zeros((sample_len, sample_len), dtype=torch.bool, device=device)
|
| 80 |
+
|
| 81 |
+
csum = 0
|
| 82 |
+
for s, attn_mode in zip(split_lens, attn_modes):
|
| 83 |
+
assert attn_mode in ['causal', 'full', 'noise']
|
| 84 |
+
if attn_mode == "causal":
|
| 85 |
+
attention_mask[csum:csum + s, csum:csum + s] = torch.ones((s, s), device=device).tril()
|
| 86 |
+
attention_mask[csum:csum + s, :csum] = 1
|
| 87 |
+
else:
|
| 88 |
+
attention_mask[csum:csum + s, csum:csum + s] = torch.ones((s, s))
|
| 89 |
+
attention_mask[csum:csum + s, :csum] = 1
|
| 90 |
+
csum += s
|
| 91 |
+
|
| 92 |
+
csum = 0
|
| 93 |
+
for s, attn_mode in zip(split_lens, attn_modes):
|
| 94 |
+
if attn_mode == "noise":
|
| 95 |
+
attention_mask[:, csum : csum + s] = torch.zeros((sample_len, s))
|
| 96 |
+
attention_mask[csum : csum + s, csum : csum + s] = torch.ones((s, s))
|
| 97 |
+
csum += s
|
| 98 |
+
|
| 99 |
+
attention_mask = torch.zeros_like(attention_mask, dtype=torch.float).masked_fill_(
|
| 100 |
+
~attention_mask, float("-inf")
|
| 101 |
+
)
|
| 102 |
+
|
| 103 |
+
return attention_mask
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
def split_integer_exp_decay(S, ng_sample_decay=1.0):
|
| 107 |
+
if ng_sample_decay == 1.0:
|
| 108 |
+
N = random.randint(1, S)
|
| 109 |
+
else:
|
| 110 |
+
base = (1 - ng_sample_decay) / (1 - math.pow(ng_sample_decay, S))
|
| 111 |
+
p = [base * math.pow(ng_sample_decay, i) for i in range(S)]
|
| 112 |
+
N = random.choices(list(range(1, S + 1)), p, k=1)[0]
|
| 113 |
+
cumsum = [0] + sorted(random.sample(range(1, S), N - 1)) + [S]
|
| 114 |
+
result = [cumsum[i+1] - cumsum[i] for i in range(len(cumsum) - 1)]
|
| 115 |
+
return result, cumsum
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def pil_img2rgb(image):
|
| 119 |
+
if image.mode == "RGBA" or image.info.get("transparency", None) is not None:
|
| 120 |
+
image = image.convert("RGBA")
|
| 121 |
+
white = Image.new(mode="RGB", size=image.size, color=(255, 255, 255))
|
| 122 |
+
white.paste(image, mask=image.split()[3])
|
| 123 |
+
image = white
|
| 124 |
+
else:
|
| 125 |
+
image = image.convert("RGB")
|
| 126 |
+
|
| 127 |
+
return image
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def add_special_tokens(tokenizer):
|
| 131 |
+
all_special_tokens = []
|
| 132 |
+
for k, v in tokenizer.special_tokens_map.items():
|
| 133 |
+
if isinstance(v, str):
|
| 134 |
+
all_special_tokens.append(v)
|
| 135 |
+
elif isinstance(v, list):
|
| 136 |
+
all_special_tokens += v
|
| 137 |
+
|
| 138 |
+
new_tokens = []
|
| 139 |
+
|
| 140 |
+
if '<|im_start|>' not in all_special_tokens:
|
| 141 |
+
new_tokens.append('<|im_start|>')
|
| 142 |
+
|
| 143 |
+
if '<|im_end|>' not in all_special_tokens:
|
| 144 |
+
new_tokens.append('<|im_end|>')
|
| 145 |
+
|
| 146 |
+
if '<|vision_start|>' not in all_special_tokens:
|
| 147 |
+
new_tokens.append('<|vision_start|>')
|
| 148 |
+
|
| 149 |
+
if '<|vision_end|>' not in all_special_tokens:
|
| 150 |
+
new_tokens.append('<|vision_end|>')
|
| 151 |
+
|
| 152 |
+
num_new_tokens = tokenizer.add_tokens(new_tokens)
|
| 153 |
+
bos_token_id = tokenizer.convert_tokens_to_ids('<|im_start|>')
|
| 154 |
+
eos_token_id = tokenizer.convert_tokens_to_ids('<|im_end|>')
|
| 155 |
+
start_of_image = tokenizer.convert_tokens_to_ids('<|vision_start|>')
|
| 156 |
+
end_of_image = tokenizer.convert_tokens_to_ids('<|vision_end|>')
|
| 157 |
+
|
| 158 |
+
new_token_ids = dict(
|
| 159 |
+
bos_token_id=bos_token_id,
|
| 160 |
+
eos_token_id=eos_token_id,
|
| 161 |
+
start_of_image=start_of_image,
|
| 162 |
+
end_of_image=end_of_image,
|
| 163 |
+
)
|
| 164 |
+
|
| 165 |
+
return tokenizer, new_token_ids, num_new_tokens
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
def len2weight(x, loss_reduction='square'):
|
| 169 |
+
if x == 0:
|
| 170 |
+
return x
|
| 171 |
+
if loss_reduction == 'token':
|
| 172 |
+
return 1
|
| 173 |
+
if loss_reduction == 'sample':
|
| 174 |
+
return 1 / x
|
| 175 |
+
if loss_reduction == 'square':
|
| 176 |
+
return 1 / (x ** 0.5)
|
| 177 |
+
raise NotImplementedError(loss_reduction)
|
data/dataset_base.py
ADDED
|
@@ -0,0 +1,620 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2025 Bytedance Ltd. and/or its affiliates.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
import random
|
| 6 |
+
import json
|
| 7 |
+
|
| 8 |
+
import numpy as np
|
| 9 |
+
import torch
|
| 10 |
+
|
| 11 |
+
from .data_utils import (
|
| 12 |
+
get_flattened_position_ids_interpolate,
|
| 13 |
+
get_flattened_position_ids_extrapolate,
|
| 14 |
+
len2weight,
|
| 15 |
+
patchify,
|
| 16 |
+
prepare_attention_mask_per_sample,
|
| 17 |
+
)
|
| 18 |
+
from .dataset_info import DATASET_INFO, DATASET_REGISTRY
|
| 19 |
+
from .transforms import ImageTransform
|
| 20 |
+
from .video_utils import FrameSampler
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
class DataConfig:
|
| 24 |
+
def __init__(
|
| 25 |
+
self,
|
| 26 |
+
grouped_datasets,
|
| 27 |
+
text_cond_dropout_prob=0.1,
|
| 28 |
+
vit_cond_dropout_prob=0.4,
|
| 29 |
+
vae_cond_dropout_prob=0.1,
|
| 30 |
+
vae_image_downsample=16,
|
| 31 |
+
max_latent_size=32,
|
| 32 |
+
vit_patch_size=14,
|
| 33 |
+
max_num_patch_per_side=70,
|
| 34 |
+
):
|
| 35 |
+
self.grouped_datasets = grouped_datasets
|
| 36 |
+
self.text_cond_dropout_prob = text_cond_dropout_prob
|
| 37 |
+
self.vit_cond_dropout_prob = vit_cond_dropout_prob
|
| 38 |
+
self.vit_patch_size = vit_patch_size
|
| 39 |
+
self.max_num_patch_per_side = max_num_patch_per_side
|
| 40 |
+
self.vae_cond_dropout_prob = vae_cond_dropout_prob
|
| 41 |
+
self.vae_image_downsample = vae_image_downsample
|
| 42 |
+
self.max_latent_size = max_latent_size
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class PackedDataset(torch.utils.data.IterableDataset):
|
| 46 |
+
def __init__(
|
| 47 |
+
self,
|
| 48 |
+
data_config,
|
| 49 |
+
tokenizer,
|
| 50 |
+
special_tokens,
|
| 51 |
+
local_rank,
|
| 52 |
+
world_size,
|
| 53 |
+
num_workers,
|
| 54 |
+
expected_num_tokens=32768,
|
| 55 |
+
max_num_tokens_per_sample=16384,
|
| 56 |
+
max_num_tokens=36864,
|
| 57 |
+
prefer_buffer_before=16384,
|
| 58 |
+
max_buffer_size=50,
|
| 59 |
+
interpolate_pos=False,
|
| 60 |
+
use_flex=False,
|
| 61 |
+
data_status=None,
|
| 62 |
+
):
|
| 63 |
+
super().__init__()
|
| 64 |
+
self.expected_num_tokens = expected_num_tokens
|
| 65 |
+
self.max_num_tokens_per_sample = max_num_tokens_per_sample
|
| 66 |
+
self.prefer_buffer_before = prefer_buffer_before
|
| 67 |
+
self.max_num_tokens = max_num_tokens
|
| 68 |
+
self.max_buffer_size = max_buffer_size
|
| 69 |
+
self.tokenizer = tokenizer
|
| 70 |
+
self.local_rank = local_rank
|
| 71 |
+
self.world_size = world_size
|
| 72 |
+
self.num_workers = num_workers
|
| 73 |
+
self.use_flex = use_flex
|
| 74 |
+
for k, v in special_tokens.items():
|
| 75 |
+
setattr(self, k, v)
|
| 76 |
+
|
| 77 |
+
grouped_datasets, is_mandatory, grouped_weights = self.build_datasets(
|
| 78 |
+
data_config.grouped_datasets, data_status
|
| 79 |
+
)
|
| 80 |
+
self.grouped_datasets = grouped_datasets
|
| 81 |
+
self.dataset_iters = [iter(dataset) for dataset in grouped_datasets]
|
| 82 |
+
self.is_mandatory = is_mandatory
|
| 83 |
+
self.grouped_weights = grouped_weights
|
| 84 |
+
self.data_config = data_config
|
| 85 |
+
self.interpolate_pos = interpolate_pos
|
| 86 |
+
if self.interpolate_pos:
|
| 87 |
+
self.get_flattened_position_ids = get_flattened_position_ids_interpolate
|
| 88 |
+
else:
|
| 89 |
+
self.get_flattened_position_ids = get_flattened_position_ids_extrapolate
|
| 90 |
+
|
| 91 |
+
def build_datasets(self, datasets_metainfo, data_status):
|
| 92 |
+
datasets = []
|
| 93 |
+
is_mandatory = []
|
| 94 |
+
grouped_weights = []
|
| 95 |
+
for grouped_dataset_name, dataset_args in datasets_metainfo.items():
|
| 96 |
+
is_mandatory.append(dataset_args.pop('is_mandatory', False))
|
| 97 |
+
grouped_weights.append(dataset_args.pop('weight', 0.0))
|
| 98 |
+
|
| 99 |
+
if 'frame_sampler_args' in dataset_args.keys():
|
| 100 |
+
frame_sampler = FrameSampler(**dataset_args.pop('frame_sampler_args'))
|
| 101 |
+
dataset_args['frame_sampler'] = frame_sampler
|
| 102 |
+
if 'image_transform_args' in dataset_args.keys():
|
| 103 |
+
transform = ImageTransform(**dataset_args.pop('image_transform_args'))
|
| 104 |
+
dataset_args['transform'] = transform
|
| 105 |
+
if 'vit_image_transform_args' in dataset_args.keys():
|
| 106 |
+
vit_transform = ImageTransform(**dataset_args.pop('vit_image_transform_args'))
|
| 107 |
+
dataset_args['vit_transform'] = vit_transform
|
| 108 |
+
|
| 109 |
+
assert 'dataset_names' in dataset_args.keys()
|
| 110 |
+
dataset_names = dataset_args.pop('dataset_names')
|
| 111 |
+
dataset_args['data_dir_list'] = []
|
| 112 |
+
for item in dataset_names:
|
| 113 |
+
if self.local_rank == 0:
|
| 114 |
+
print(f'Preparing Dataset {grouped_dataset_name}/{item}')
|
| 115 |
+
meta_info = DATASET_INFO[grouped_dataset_name][item]
|
| 116 |
+
dataset_args['data_dir_list'].append(meta_info['data_dir'])
|
| 117 |
+
|
| 118 |
+
if "parquet_info_path" in meta_info.keys():
|
| 119 |
+
if 'parquet_info' not in dataset_args.keys():
|
| 120 |
+
dataset_args['parquet_info'] = {}
|
| 121 |
+
with open(meta_info['parquet_info_path'], 'r') as f:
|
| 122 |
+
parquet_info = json.load(f)
|
| 123 |
+
dataset_args['parquet_info'].update(parquet_info)
|
| 124 |
+
|
| 125 |
+
if 'json_dir' in meta_info.keys():
|
| 126 |
+
# parquet/tar with json
|
| 127 |
+
if 'json_dir_list' not in dataset_args.keys():
|
| 128 |
+
dataset_args['json_dir_list'] = [meta_info['json_dir']]
|
| 129 |
+
else:
|
| 130 |
+
dataset_args['json_dir_list'].append(meta_info['json_dir'])
|
| 131 |
+
|
| 132 |
+
if 'jsonl_path' in meta_info.keys():
|
| 133 |
+
# jsonl with jpeg
|
| 134 |
+
if 'jsonl_path_list' not in dataset_args.keys():
|
| 135 |
+
dataset_args['jsonl_path_list'] = [meta_info['jsonl_path']]
|
| 136 |
+
else:
|
| 137 |
+
dataset_args['jsonl_path_list'].append(meta_info['jsonl_path'])
|
| 138 |
+
|
| 139 |
+
resume_data_status = dataset_args.pop('resume_data_status', True)
|
| 140 |
+
if data_status is not None and grouped_dataset_name in data_status.keys() and resume_data_status:
|
| 141 |
+
data_status_per_group = data_status[grouped_dataset_name]
|
| 142 |
+
else:
|
| 143 |
+
data_status_per_group = None
|
| 144 |
+
dataset = DATASET_REGISTRY[grouped_dataset_name](
|
| 145 |
+
dataset_name=grouped_dataset_name,
|
| 146 |
+
tokenizer=self.tokenizer,
|
| 147 |
+
local_rank=self.local_rank,
|
| 148 |
+
world_size=self.world_size,
|
| 149 |
+
num_workers=self.num_workers,
|
| 150 |
+
data_status=data_status_per_group,
|
| 151 |
+
**dataset_args
|
| 152 |
+
)
|
| 153 |
+
datasets.append(dataset)
|
| 154 |
+
|
| 155 |
+
return datasets, is_mandatory, grouped_weights
|
| 156 |
+
|
| 157 |
+
def set_epoch(self, seed):
|
| 158 |
+
for dataset in self.grouped_datasets:
|
| 159 |
+
dataset.set_epoch(seed)
|
| 160 |
+
|
| 161 |
+
def set_sequence_status(self):
|
| 162 |
+
sequence_status = dict(
|
| 163 |
+
curr = 0,
|
| 164 |
+
sample_lens = list(),
|
| 165 |
+
packed_position_ids = list(),
|
| 166 |
+
nested_attention_masks = list(),
|
| 167 |
+
split_lens = list(),
|
| 168 |
+
attn_modes = list(),
|
| 169 |
+
packed_text_ids = list(),
|
| 170 |
+
packed_text_indexes = list(),
|
| 171 |
+
packed_label_ids = list(),
|
| 172 |
+
ce_loss_indexes = list(),
|
| 173 |
+
ce_loss_weights = list(),
|
| 174 |
+
vae_image_tensors = list(),
|
| 175 |
+
packed_latent_position_ids = list(),
|
| 176 |
+
vae_latent_shapes = list(),
|
| 177 |
+
packed_vae_token_indexes = list(),
|
| 178 |
+
packed_timesteps = list(),
|
| 179 |
+
mse_loss_indexes = list(),
|
| 180 |
+
packed_vit_tokens = list(),
|
| 181 |
+
vit_token_seqlens = list(),
|
| 182 |
+
packed_vit_position_ids = list(),
|
| 183 |
+
packed_vit_token_indexes = list(),
|
| 184 |
+
)
|
| 185 |
+
return sequence_status
|
| 186 |
+
|
| 187 |
+
def to_tensor(self, sequence_status):
|
| 188 |
+
data = dict(
|
| 189 |
+
sequence_length=sum(sequence_status['sample_lens']),
|
| 190 |
+
sample_lens=sequence_status['sample_lens'],
|
| 191 |
+
packed_text_ids=torch.tensor(sequence_status['packed_text_ids']),
|
| 192 |
+
packed_text_indexes=torch.tensor(sequence_status['packed_text_indexes']),
|
| 193 |
+
packed_position_ids=torch.tensor(sequence_status['packed_position_ids']),
|
| 194 |
+
)
|
| 195 |
+
if not self.use_flex:
|
| 196 |
+
data['nested_attention_masks'] = sequence_status['nested_attention_masks']
|
| 197 |
+
else:
|
| 198 |
+
sequence_len = data['sequence_length']
|
| 199 |
+
pad_len = self.max_num_tokens - sequence_len
|
| 200 |
+
data['split_lens'] = sequence_status['split_lens'] + [pad_len]
|
| 201 |
+
data['attn_modes'] = sequence_status['attn_modes'] + ['causal']
|
| 202 |
+
data['sample_lens'] += [pad_len]
|
| 203 |
+
|
| 204 |
+
# if the model has a convnet vae (e.g., as visual tokenizer)
|
| 205 |
+
if len(sequence_status['vae_image_tensors']) > 0:
|
| 206 |
+
image_tensors = sequence_status.pop('vae_image_tensors')
|
| 207 |
+
image_sizes = [item.shape for item in image_tensors]
|
| 208 |
+
max_image_size = [max(item) for item in list(zip(*image_sizes))]
|
| 209 |
+
padded_images = torch.zeros(size=(len(image_tensors), *max_image_size))
|
| 210 |
+
for i, image_tensor in enumerate(image_tensors):
|
| 211 |
+
padded_images[i, :, :image_tensor.shape[1], :image_tensor.shape[2]] = image_tensor
|
| 212 |
+
|
| 213 |
+
data['padded_images'] = padded_images
|
| 214 |
+
data['patchified_vae_latent_shapes'] = sequence_status['vae_latent_shapes']
|
| 215 |
+
data['packed_latent_position_ids'] = torch.cat(sequence_status['packed_latent_position_ids'], dim=0)
|
| 216 |
+
data['packed_vae_token_indexes'] = torch.tensor(sequence_status['packed_vae_token_indexes'])
|
| 217 |
+
|
| 218 |
+
# if the model has a vit (e.g., as visual tokenizer)
|
| 219 |
+
if len(sequence_status['packed_vit_tokens']) > 0:
|
| 220 |
+
data['packed_vit_tokens'] = torch.cat(sequence_status['packed_vit_tokens'], dim=0)
|
| 221 |
+
data['packed_vit_position_ids'] = torch.cat(sequence_status['packed_vit_position_ids'], dim=0)
|
| 222 |
+
data['packed_vit_token_indexes'] = torch.tensor(sequence_status['packed_vit_token_indexes'])
|
| 223 |
+
data['vit_token_seqlens'] = torch.tensor(sequence_status['vit_token_seqlens'])
|
| 224 |
+
|
| 225 |
+
# if the model is required to perform visual generation
|
| 226 |
+
if len(sequence_status['packed_timesteps']) > 0:
|
| 227 |
+
data['packed_timesteps'] = torch.tensor(sequence_status['packed_timesteps'])
|
| 228 |
+
data['mse_loss_indexes'] = torch.tensor(sequence_status['mse_loss_indexes'])
|
| 229 |
+
|
| 230 |
+
# if the model is required to perform text generation
|
| 231 |
+
if len(sequence_status['packed_label_ids']) > 0:
|
| 232 |
+
data['packed_label_ids'] = torch.tensor(sequence_status['packed_label_ids'])
|
| 233 |
+
data['ce_loss_indexes'] = torch.tensor(sequence_status['ce_loss_indexes'])
|
| 234 |
+
data['ce_loss_weights'] = torch.tensor(sequence_status['ce_loss_weights'])
|
| 235 |
+
|
| 236 |
+
return data
|
| 237 |
+
|
| 238 |
+
def __iter__(self):
|
| 239 |
+
total_weights = sum(self.grouped_weights)
|
| 240 |
+
assert total_weights > 0.0
|
| 241 |
+
group_cumprobs = [sum(self.grouped_weights[:i + 1]) / total_weights
|
| 242 |
+
for i in range(len(self.grouped_weights))]
|
| 243 |
+
sequence_status = self.set_sequence_status()
|
| 244 |
+
batch_data_indexes = []
|
| 245 |
+
|
| 246 |
+
buffer = []
|
| 247 |
+
while True:
|
| 248 |
+
# Ensure at least one sample from each group
|
| 249 |
+
if sequence_status['curr'] == 0:
|
| 250 |
+
for group_index, group_iter in enumerate(self.dataset_iters):
|
| 251 |
+
if self.is_mandatory[group_index]:
|
| 252 |
+
while True:
|
| 253 |
+
sample = next(group_iter)
|
| 254 |
+
# if a sample is too long, skip it
|
| 255 |
+
num_tokens = sample['num_tokens'] + 2 * len(sample['sequence_plan'])
|
| 256 |
+
if num_tokens < self.max_num_tokens_per_sample:
|
| 257 |
+
sequence_status = self.pack_sequence(sample, sequence_status)
|
| 258 |
+
batch_data_indexes.append(sample['data_indexes'])
|
| 259 |
+
break
|
| 260 |
+
else:
|
| 261 |
+
print(f"skip a sample with length {num_tokens}")
|
| 262 |
+
continue
|
| 263 |
+
|
| 264 |
+
if sequence_status['curr'] < self.prefer_buffer_before and len(buffer) > 0:
|
| 265 |
+
sample = buffer.pop(0)
|
| 266 |
+
sample_from_buffer = True
|
| 267 |
+
else:
|
| 268 |
+
# sample normally across all groups
|
| 269 |
+
n = random.random()
|
| 270 |
+
group_index = 0
|
| 271 |
+
for i, cumprob in enumerate(group_cumprobs):
|
| 272 |
+
if n < cumprob:
|
| 273 |
+
group_index = i
|
| 274 |
+
break
|
| 275 |
+
sample = next(self.dataset_iters[group_index])
|
| 276 |
+
sample_from_buffer = False
|
| 277 |
+
|
| 278 |
+
# if a sample is too long, skip it
|
| 279 |
+
num_tokens = sample['num_tokens'] + 2 * len(sample['sequence_plan'])
|
| 280 |
+
if num_tokens > self.max_num_tokens_per_sample:
|
| 281 |
+
print(f"skip a sample with length {num_tokens}")
|
| 282 |
+
continue
|
| 283 |
+
|
| 284 |
+
if sequence_status['curr'] + num_tokens > self.max_num_tokens:
|
| 285 |
+
if len(buffer) < self.max_buffer_size and not sample_from_buffer:
|
| 286 |
+
buffer.append(sample)
|
| 287 |
+
else:
|
| 288 |
+
print(f"Yielding data with length {sum(sequence_status['sample_lens'])}")
|
| 289 |
+
data = self.to_tensor(sequence_status)
|
| 290 |
+
data['batch_data_indexes'] = batch_data_indexes
|
| 291 |
+
yield data
|
| 292 |
+
sequence_status = self.set_sequence_status()
|
| 293 |
+
batch_data_indexes = []
|
| 294 |
+
continue
|
| 295 |
+
|
| 296 |
+
sequence_status = self.pack_sequence(sample, sequence_status)
|
| 297 |
+
batch_data_indexes.append(sample['data_indexes'])
|
| 298 |
+
|
| 299 |
+
if sequence_status['curr'] >= self.expected_num_tokens:
|
| 300 |
+
data = self.to_tensor(sequence_status)
|
| 301 |
+
data['batch_data_indexes'] = batch_data_indexes
|
| 302 |
+
yield data
|
| 303 |
+
sequence_status = self.set_sequence_status()
|
| 304 |
+
batch_data_indexes = []
|
| 305 |
+
|
| 306 |
+
def pack_sequence(self, sample, sequence_status):
|
| 307 |
+
image_tensor_list = sample['image_tensor_list']
|
| 308 |
+
text_ids_list = sample['text_ids_list']
|
| 309 |
+
sequence_plan = sample['sequence_plan']
|
| 310 |
+
|
| 311 |
+
split_lens, attn_modes = list(), list()
|
| 312 |
+
curr = sequence_status['curr']
|
| 313 |
+
curr_rope_id = 0
|
| 314 |
+
sample_lens = 0
|
| 315 |
+
|
| 316 |
+
for item in sequence_plan:
|
| 317 |
+
split_start = item.get('split_start', True)
|
| 318 |
+
if split_start:
|
| 319 |
+
curr_split_len = 0
|
| 320 |
+
|
| 321 |
+
if item['type'] == 'text':
|
| 322 |
+
text_ids = text_ids_list.pop(0)
|
| 323 |
+
if item['enable_cfg'] == 1 and random.random() < self.data_config.text_cond_dropout_prob:
|
| 324 |
+
continue
|
| 325 |
+
|
| 326 |
+
shifted_text_ids = [self.bos_token_id] + text_ids
|
| 327 |
+
sequence_status['packed_text_ids'].extend(shifted_text_ids)
|
| 328 |
+
sequence_status['packed_text_indexes'].extend(range(curr, curr + len(shifted_text_ids)))
|
| 329 |
+
if item['loss'] == 1:
|
| 330 |
+
sequence_status['ce_loss_indexes'].extend(range(curr, curr + len(shifted_text_ids)))
|
| 331 |
+
sequence_status['ce_loss_weights'].extend(
|
| 332 |
+
[len2weight(len(shifted_text_ids))] * len(shifted_text_ids)
|
| 333 |
+
)
|
| 334 |
+
sequence_status['packed_label_ids'].extend(text_ids + [self.eos_token_id])
|
| 335 |
+
curr += len(shifted_text_ids)
|
| 336 |
+
curr_split_len += len(shifted_text_ids)
|
| 337 |
+
|
| 338 |
+
# add a <|im_end|> token
|
| 339 |
+
sequence_status['packed_text_ids'].append(self.eos_token_id)
|
| 340 |
+
sequence_status['packed_text_indexes'].append(curr)
|
| 341 |
+
if item['special_token_loss'] == 1: # <|im_end|> may have loss
|
| 342 |
+
sequence_status['ce_loss_indexes'].append(curr)
|
| 343 |
+
sequence_status['ce_loss_weights'].append(1.0)
|
| 344 |
+
sequence_status['packed_label_ids'].append(item['special_token_label'])
|
| 345 |
+
curr += 1
|
| 346 |
+
curr_split_len += 1
|
| 347 |
+
|
| 348 |
+
# update sequence status
|
| 349 |
+
attn_modes.append("causal")
|
| 350 |
+
sequence_status['packed_position_ids'].extend(range(curr_rope_id, curr_rope_id + curr_split_len))
|
| 351 |
+
curr_rope_id += curr_split_len
|
| 352 |
+
|
| 353 |
+
elif item['type'] == 'vit_image':
|
| 354 |
+
image_tensor = image_tensor_list.pop(0)
|
| 355 |
+
if item['enable_cfg'] == 1 and random.random() < self.data_config.vit_cond_dropout_prob:
|
| 356 |
+
curr_rope_id += 1
|
| 357 |
+
continue
|
| 358 |
+
|
| 359 |
+
# add a <|startofimage|> token
|
| 360 |
+
sequence_status['packed_text_ids'].append(self.start_of_image)
|
| 361 |
+
sequence_status['packed_text_indexes'].append(curr)
|
| 362 |
+
curr += 1
|
| 363 |
+
curr_split_len += 1
|
| 364 |
+
|
| 365 |
+
# preprocess image
|
| 366 |
+
vit_tokens = patchify(image_tensor, self.data_config.vit_patch_size)
|
| 367 |
+
num_img_tokens = vit_tokens.shape[0]
|
| 368 |
+
sequence_status['packed_vit_token_indexes'].extend(range(curr, curr + num_img_tokens))
|
| 369 |
+
curr += num_img_tokens
|
| 370 |
+
curr_split_len += num_img_tokens
|
| 371 |
+
|
| 372 |
+
sequence_status['packed_vit_tokens'].append(vit_tokens)
|
| 373 |
+
sequence_status['vit_token_seqlens'].append(num_img_tokens)
|
| 374 |
+
sequence_status['packed_vit_position_ids'].append(
|
| 375 |
+
self.get_flattened_position_ids(
|
| 376 |
+
image_tensor.size(1), image_tensor.size(2),
|
| 377 |
+
self.data_config.vit_patch_size,
|
| 378 |
+
max_num_patches_per_side=self.data_config.max_num_patch_per_side
|
| 379 |
+
)
|
| 380 |
+
)
|
| 381 |
+
|
| 382 |
+
# add a <|endofimage|> token
|
| 383 |
+
sequence_status['packed_text_ids'].append(self.end_of_image)
|
| 384 |
+
sequence_status['packed_text_indexes'].append(curr)
|
| 385 |
+
if item['special_token_loss'] == 1: # <|endofimage|> may have loss
|
| 386 |
+
sequence_status['ce_loss_indexes'].append(curr)
|
| 387 |
+
sequence_status['ce_loss_weights'].append(1.0)
|
| 388 |
+
sequence_status['packed_label_ids'].append(item['special_token_label'])
|
| 389 |
+
curr += 1
|
| 390 |
+
curr_split_len += 1
|
| 391 |
+
|
| 392 |
+
# update sequence status
|
| 393 |
+
attn_modes.append("full")
|
| 394 |
+
sequence_status['packed_position_ids'].extend([curr_rope_id] * curr_split_len)
|
| 395 |
+
curr_rope_id += 1
|
| 396 |
+
|
| 397 |
+
elif item['type'] == 'vae_image':
|
| 398 |
+
image_tensor = image_tensor_list.pop(0)
|
| 399 |
+
if item['enable_cfg'] == 1 and random.random() < self.data_config.vae_cond_dropout_prob:
|
| 400 |
+
# FIXME fix vae dropout in video2video setting.
|
| 401 |
+
curr_rope_id += 1
|
| 402 |
+
continue
|
| 403 |
+
|
| 404 |
+
# add a <|startofimage|> token
|
| 405 |
+
sequence_status['packed_text_ids'].append(self.start_of_image)
|
| 406 |
+
sequence_status['packed_text_indexes'].append(curr)
|
| 407 |
+
curr += 1
|
| 408 |
+
curr_split_len += 1
|
| 409 |
+
|
| 410 |
+
# preprocess image
|
| 411 |
+
sequence_status['vae_image_tensors'].append(image_tensor)
|
| 412 |
+
sequence_status['packed_latent_position_ids'].append(
|
| 413 |
+
self.get_flattened_position_ids(
|
| 414 |
+
image_tensor.size(1), image_tensor.size(2),
|
| 415 |
+
self.data_config.vae_image_downsample,
|
| 416 |
+
max_num_patches_per_side=self.data_config.max_latent_size
|
| 417 |
+
)
|
| 418 |
+
)
|
| 419 |
+
H, W = image_tensor.shape[1:]
|
| 420 |
+
h = H // self.data_config.vae_image_downsample
|
| 421 |
+
w = W // self.data_config.vae_image_downsample
|
| 422 |
+
sequence_status['vae_latent_shapes'].append((h, w))
|
| 423 |
+
|
| 424 |
+
num_img_tokens = w * h
|
| 425 |
+
sequence_status['packed_vae_token_indexes'].extend(range(curr, curr + num_img_tokens))
|
| 426 |
+
if item['loss'] == 1:
|
| 427 |
+
sequence_status['mse_loss_indexes'].extend(range(curr, curr + num_img_tokens))
|
| 428 |
+
if split_start:
|
| 429 |
+
timestep = np.random.randn()
|
| 430 |
+
else:
|
| 431 |
+
timestep = float('-inf')
|
| 432 |
+
|
| 433 |
+
sequence_status['packed_timesteps'].extend([timestep] * num_img_tokens)
|
| 434 |
+
curr += num_img_tokens
|
| 435 |
+
curr_split_len += num_img_tokens
|
| 436 |
+
|
| 437 |
+
# add a <|endofimage|> token
|
| 438 |
+
sequence_status['packed_text_ids'].append(self.end_of_image)
|
| 439 |
+
sequence_status['packed_text_indexes'].append(curr)
|
| 440 |
+
# <|endofimage|> may have loss
|
| 441 |
+
if item['special_token_loss'] == 1:
|
| 442 |
+
sequence_status['ce_loss_indexes'].append(curr)
|
| 443 |
+
sequence_status['ce_loss_weights'].append(1.0)
|
| 444 |
+
sequence_status['packed_label_ids'].append(item['special_token_label'])
|
| 445 |
+
curr += 1
|
| 446 |
+
curr_split_len += 1
|
| 447 |
+
|
| 448 |
+
# update sequence status
|
| 449 |
+
if split_start:
|
| 450 |
+
if item['loss'] == 1 and 'frame_delta' not in item.keys():
|
| 451 |
+
attn_modes.append("noise")
|
| 452 |
+
else:
|
| 453 |
+
attn_modes.append("full")
|
| 454 |
+
sequence_status['packed_position_ids'].extend([curr_rope_id] * (num_img_tokens + 2))
|
| 455 |
+
if 'frame_delta' in item.keys():
|
| 456 |
+
curr_rope_id += item['frame_delta']
|
| 457 |
+
elif item['loss'] == 0:
|
| 458 |
+
curr_rope_id += 1
|
| 459 |
+
|
| 460 |
+
if item.get('split_end', True):
|
| 461 |
+
split_lens.append(curr_split_len)
|
| 462 |
+
sample_lens += curr_split_len
|
| 463 |
+
|
| 464 |
+
sequence_status['curr'] = curr
|
| 465 |
+
sequence_status['sample_lens'].append(sample_lens)
|
| 466 |
+
# prepare attention mask
|
| 467 |
+
if not self.use_flex:
|
| 468 |
+
sequence_status['nested_attention_masks'].append(
|
| 469 |
+
prepare_attention_mask_per_sample(split_lens, attn_modes)
|
| 470 |
+
)
|
| 471 |
+
else:
|
| 472 |
+
sequence_status['split_lens'].extend(split_lens)
|
| 473 |
+
sequence_status['attn_modes'].extend(attn_modes)
|
| 474 |
+
|
| 475 |
+
return sequence_status
|
| 476 |
+
|
| 477 |
+
|
| 478 |
+
class SimpleCustomBatch:
|
| 479 |
+
def __init__(self, batch):
|
| 480 |
+
data = batch[0]
|
| 481 |
+
self.batch_data_indexes = data['batch_data_indexes']
|
| 482 |
+
self.sequence_length = data["sequence_length"]
|
| 483 |
+
self.sample_lens = data["sample_lens"]
|
| 484 |
+
self.packed_text_ids = data["packed_text_ids"]
|
| 485 |
+
self.packed_text_indexes = data["packed_text_indexes"]
|
| 486 |
+
self.packed_position_ids = data["packed_position_ids"]
|
| 487 |
+
|
| 488 |
+
self.use_flex = "nested_attention_masks" not in data.keys()
|
| 489 |
+
|
| 490 |
+
if self.use_flex:
|
| 491 |
+
self.split_lens = data["split_lens"]
|
| 492 |
+
self.attn_modes = data["attn_modes"]
|
| 493 |
+
else:
|
| 494 |
+
self.nested_attention_masks = data["nested_attention_masks"]
|
| 495 |
+
|
| 496 |
+
if "padded_images" in data.keys():
|
| 497 |
+
self.padded_images = data["padded_images"]
|
| 498 |
+
self.patchified_vae_latent_shapes = data["patchified_vae_latent_shapes"]
|
| 499 |
+
self.packed_latent_position_ids = data["packed_latent_position_ids"]
|
| 500 |
+
self.packed_vae_token_indexes = data["packed_vae_token_indexes"]
|
| 501 |
+
|
| 502 |
+
if "packed_vit_tokens" in data.keys():
|
| 503 |
+
self.packed_vit_tokens = data["packed_vit_tokens"]
|
| 504 |
+
self.packed_vit_position_ids = data["packed_vit_position_ids"]
|
| 505 |
+
self.packed_vit_token_indexes = data["packed_vit_token_indexes"]
|
| 506 |
+
self.vit_token_seqlens = data["vit_token_seqlens"]
|
| 507 |
+
|
| 508 |
+
if "packed_timesteps" in data.keys():
|
| 509 |
+
self.packed_timesteps = data["packed_timesteps"]
|
| 510 |
+
self.mse_loss_indexes = data["mse_loss_indexes"]
|
| 511 |
+
|
| 512 |
+
if "packed_label_ids" in data.keys():
|
| 513 |
+
self.packed_label_ids = data["packed_label_ids"]
|
| 514 |
+
self.ce_loss_indexes = data["ce_loss_indexes"]
|
| 515 |
+
self.ce_loss_weights = data["ce_loss_weights"]
|
| 516 |
+
|
| 517 |
+
def pin_memory(self):
|
| 518 |
+
self.packed_text_ids = self.packed_text_ids.pin_memory()
|
| 519 |
+
self.packed_text_indexes = self.packed_text_indexes.pin_memory()
|
| 520 |
+
self.packed_position_ids = self.packed_position_ids.pin_memory()
|
| 521 |
+
|
| 522 |
+
if not self.use_flex:
|
| 523 |
+
self.nested_attention_masks = [item.pin_memory() for item in self.nested_attention_masks]
|
| 524 |
+
|
| 525 |
+
if hasattr(self, 'padded_images'):
|
| 526 |
+
self.padded_images = self.padded_images.pin_memory()
|
| 527 |
+
self.packed_vae_token_indexes = self.packed_vae_token_indexes.pin_memory()
|
| 528 |
+
self.packed_latent_position_ids = self.packed_latent_position_ids.pin_memory()
|
| 529 |
+
|
| 530 |
+
if hasattr(self, 'packed_timesteps'):
|
| 531 |
+
self.packed_timesteps = self.packed_timesteps.pin_memory()
|
| 532 |
+
self.mse_loss_indexes = self.mse_loss_indexes.pin_memory()
|
| 533 |
+
|
| 534 |
+
if hasattr(self, 'packed_vit_tokens'):
|
| 535 |
+
self.packed_vit_tokens = self.packed_vit_tokens.pin_memory()
|
| 536 |
+
self.packed_vit_position_ids = self.packed_vit_position_ids.pin_memory()
|
| 537 |
+
self.packed_vit_token_indexes = self.packed_vit_token_indexes.pin_memory()
|
| 538 |
+
self.vit_token_seqlens = self.vit_token_seqlens.pin_memory()
|
| 539 |
+
|
| 540 |
+
if hasattr(self, 'packed_label_ids'):
|
| 541 |
+
self.packed_label_ids = self.packed_label_ids.pin_memory()
|
| 542 |
+
self.ce_loss_indexes = self.ce_loss_indexes.pin_memory()
|
| 543 |
+
self.ce_loss_weights = self.ce_loss_weights.pin_memory()
|
| 544 |
+
|
| 545 |
+
return self
|
| 546 |
+
|
| 547 |
+
def cuda(self, device):
|
| 548 |
+
self.packed_text_ids = self.packed_text_ids.to(device)
|
| 549 |
+
self.packed_text_indexes = self.packed_text_indexes.to(device)
|
| 550 |
+
self.packed_position_ids = self.packed_position_ids.to(device)
|
| 551 |
+
|
| 552 |
+
if not self.use_flex:
|
| 553 |
+
self.nested_attention_masks = [item.to(device) for item in self.nested_attention_masks]
|
| 554 |
+
|
| 555 |
+
if hasattr(self, 'padded_images'):
|
| 556 |
+
self.padded_images = self.padded_images.to(device)
|
| 557 |
+
self.packed_vae_token_indexes = self.packed_vae_token_indexes.to(device)
|
| 558 |
+
self.packed_latent_position_ids = self.packed_latent_position_ids.to(device)
|
| 559 |
+
|
| 560 |
+
if hasattr(self, 'packed_timesteps'):
|
| 561 |
+
self.packed_timesteps = self.packed_timesteps.to(device)
|
| 562 |
+
self.mse_loss_indexes = self.mse_loss_indexes.to(device)
|
| 563 |
+
|
| 564 |
+
if hasattr(self, 'packed_vit_tokens'):
|
| 565 |
+
self.packed_vit_tokens = self.packed_vit_tokens.to(device)
|
| 566 |
+
self.packed_vit_position_ids = self.packed_vit_position_ids.to(device)
|
| 567 |
+
self.packed_vit_token_indexes = self.packed_vit_token_indexes.to(device)
|
| 568 |
+
self.vit_token_seqlens = self.vit_token_seqlens.to(device)
|
| 569 |
+
|
| 570 |
+
if hasattr(self, 'packed_label_ids'):
|
| 571 |
+
self.packed_label_ids = self.packed_label_ids.to(device)
|
| 572 |
+
self.ce_loss_indexes = self.ce_loss_indexes.to(device)
|
| 573 |
+
self.ce_loss_weights = self.ce_loss_weights.to(device)
|
| 574 |
+
|
| 575 |
+
return self
|
| 576 |
+
|
| 577 |
+
def to_dict(self):
|
| 578 |
+
data = dict(
|
| 579 |
+
sequence_length = self.sequence_length,
|
| 580 |
+
sample_lens = self.sample_lens,
|
| 581 |
+
packed_text_ids = self.packed_text_ids,
|
| 582 |
+
packed_text_indexes = self.packed_text_indexes,
|
| 583 |
+
packed_position_ids = self.packed_position_ids,
|
| 584 |
+
batch_data_indexes = self.batch_data_indexes,
|
| 585 |
+
)
|
| 586 |
+
|
| 587 |
+
if not self.use_flex:
|
| 588 |
+
data['nested_attention_masks'] = self.nested_attention_masks
|
| 589 |
+
else:
|
| 590 |
+
data['split_lens'] = self.split_lens
|
| 591 |
+
data['attn_modes'] = self.attn_modes
|
| 592 |
+
|
| 593 |
+
if hasattr(self, 'padded_images'):
|
| 594 |
+
data['padded_images'] = self.padded_images
|
| 595 |
+
data['patchified_vae_latent_shapes'] = self.patchified_vae_latent_shapes
|
| 596 |
+
data['packed_latent_position_ids'] = self.packed_latent_position_ids
|
| 597 |
+
data['packed_vae_token_indexes'] = self.packed_vae_token_indexes
|
| 598 |
+
|
| 599 |
+
if hasattr(self, 'packed_vit_tokens'):
|
| 600 |
+
data['packed_vit_tokens'] = self.packed_vit_tokens
|
| 601 |
+
data['packed_vit_position_ids'] = self.packed_vit_position_ids
|
| 602 |
+
data['packed_vit_token_indexes'] = self.packed_vit_token_indexes
|
| 603 |
+
data['vit_token_seqlens'] = self.vit_token_seqlens
|
| 604 |
+
|
| 605 |
+
if hasattr(self, 'packed_timesteps'):
|
| 606 |
+
data['packed_timesteps'] = self.packed_timesteps
|
| 607 |
+
data['mse_loss_indexes'] = self.mse_loss_indexes
|
| 608 |
+
|
| 609 |
+
if hasattr(self, 'packed_label_ids'):
|
| 610 |
+
data['packed_label_ids'] = self.packed_label_ids
|
| 611 |
+
data['ce_loss_indexes'] = self.ce_loss_indexes
|
| 612 |
+
data['ce_loss_weights'] = self.ce_loss_weights
|
| 613 |
+
|
| 614 |
+
return data
|
| 615 |
+
|
| 616 |
+
|
| 617 |
+
def collate_wrapper():
|
| 618 |
+
def collate_fn(batch):
|
| 619 |
+
return SimpleCustomBatch(batch)
|
| 620 |
+
return collate_fn
|
data/dataset_info.py
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2025 Bytedance Ltd. and/or its affiliates.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 3 |
+
|
| 4 |
+
from .interleave_datasets import UnifiedEditIterableDataset
|
| 5 |
+
from .t2i_dataset import T2IIterableDataset
|
| 6 |
+
from .vlm_dataset import SftJSONLIterableDataset
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
DATASET_REGISTRY = {
|
| 10 |
+
't2i_pretrain': T2IIterableDataset,
|
| 11 |
+
'vlm_sft': SftJSONLIterableDataset,
|
| 12 |
+
'unified_edit': UnifiedEditIterableDataset,
|
| 13 |
+
}
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
DATASET_INFO = {
|
| 17 |
+
't2i_pretrain': {
|
| 18 |
+
't2i': {
|
| 19 |
+
'data_dir': 'your_data_path/bagel_example/t2i', # path of the parquet files
|
| 20 |
+
'num_files': 10, # number of data units to be sharded across all ranks and workers
|
| 21 |
+
'num_total_samples': 1000, # number of total samples in the dataset
|
| 22 |
+
},
|
| 23 |
+
},
|
| 24 |
+
'unified_edit':{
|
| 25 |
+
'seedxedit_multi': {
|
| 26 |
+
'data_dir': 'your_data_path/bagel_example/editing/seedxedit_multi',
|
| 27 |
+
'num_files': 10,
|
| 28 |
+
'num_total_samples': 1000,
|
| 29 |
+
"parquet_info_path": 'your_data_path/bagel_example/editing/parquet_info/seedxedit_multi_nas.json', # information of the parquet files
|
| 30 |
+
},
|
| 31 |
+
},
|
| 32 |
+
'vlm_sft': {
|
| 33 |
+
'llava_ov': {
|
| 34 |
+
'data_dir': 'your_data_path/bagel_example/vlm/images',
|
| 35 |
+
'jsonl_path': 'your_data_path/bagel_example/vlm/llava_ov_si.jsonl',
|
| 36 |
+
'num_total_samples': 1000
|
| 37 |
+
},
|
| 38 |
+
},
|
| 39 |
+
}
|
data/distributed_iterable_dataset.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2025 Bytedance Ltd. and/or its affiliates.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 3 |
+
|
| 4 |
+
import random
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class DistributedIterableDataset(torch.utils.data.IterableDataset):
|
| 9 |
+
def __init__(self, dataset_name, local_rank=0, world_size=1, num_workers=8):
|
| 10 |
+
self.dataset_name = dataset_name
|
| 11 |
+
self.local_rank = local_rank
|
| 12 |
+
self.world_size = world_size
|
| 13 |
+
self.num_workers = num_workers
|
| 14 |
+
self.rng = random.Random()
|
| 15 |
+
self.data_paths = None
|
| 16 |
+
|
| 17 |
+
def get_data_paths(self, *args, **kwargs):
|
| 18 |
+
raise NotImplementedError
|
| 19 |
+
|
| 20 |
+
def set_epoch(self, seed=42):
|
| 21 |
+
if self.data_paths is None:
|
| 22 |
+
return
|
| 23 |
+
|
| 24 |
+
if isinstance(self.data_paths[0], tuple):
|
| 25 |
+
data_paths = sorted(self.data_paths, key=lambda x: (x[0], x[1]))
|
| 26 |
+
elif isinstance(self.data_paths[0], str):
|
| 27 |
+
data_paths = sorted(self.data_paths)
|
| 28 |
+
else:
|
| 29 |
+
raise ValueError(f"Unknown data_paths type: {type(self.data_paths[0])}")
|
| 30 |
+
|
| 31 |
+
self.rng.seed(seed)
|
| 32 |
+
self.rng.shuffle(data_paths)
|
| 33 |
+
|
| 34 |
+
num_files_per_rank = len(data_paths) // self.world_size
|
| 35 |
+
local_start = self.local_rank * num_files_per_rank
|
| 36 |
+
local_end = (self.local_rank + 1) * num_files_per_rank
|
| 37 |
+
self.num_files_per_rank = num_files_per_rank
|
| 38 |
+
self.data_paths_per_rank = data_paths[local_start:local_end]
|
| 39 |
+
|
| 40 |
+
def get_data_paths_per_worker(self):
|
| 41 |
+
if self.data_paths is None:
|
| 42 |
+
return None
|
| 43 |
+
|
| 44 |
+
info = torch.utils.data.get_worker_info()
|
| 45 |
+
if info is None:
|
| 46 |
+
# Single worker: Use all files assigned to the rank
|
| 47 |
+
return self.data_paths_per_rank, 0
|
| 48 |
+
|
| 49 |
+
worker_id = info.id
|
| 50 |
+
num_files_per_worker = self.num_files_per_rank // info.num_workers
|
| 51 |
+
start = num_files_per_worker * worker_id
|
| 52 |
+
end = num_files_per_worker * (worker_id + 1)
|
| 53 |
+
data_paths_per_worker = self.data_paths_per_rank[start:end]
|
| 54 |
+
|
| 55 |
+
return data_paths_per_worker[::-1], worker_id
|
| 56 |
+
|
| 57 |
+
def __iter__(self):
|
| 58 |
+
raise NotImplementedError
|
data/interleave_datasets/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2025 Bytedance Ltd. and/or its affiliates.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 3 |
+
|
| 4 |
+
from .edit_dataset import UnifiedEditIterableDataset
|
| 5 |
+
|
data/interleave_datasets/edit_dataset.py
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2025 Bytedance Ltd. and/or its affiliates.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 3 |
+
|
| 4 |
+
import io
|
| 5 |
+
import random
|
| 6 |
+
from PIL import Image, ImageFile, PngImagePlugin
|
| 7 |
+
|
| 8 |
+
from .interleave_t2i_dataset import InterleavedBaseIterableDataset, ParquetStandardIterableDataset
|
| 9 |
+
from ..data_utils import pil_img2rgb
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
Image.MAX_IMAGE_PIXELS = 200000000
|
| 13 |
+
ImageFile.LOAD_TRUNCATED_IMAGES = True
|
| 14 |
+
MaximumDecompressedSize = 1024
|
| 15 |
+
MegaByte = 2 ** 20
|
| 16 |
+
PngImagePlugin.MAX_TEXT_CHUNK = MaximumDecompressedSize * MegaByte
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class UnifiedEditIterableDataset(InterleavedBaseIterableDataset, ParquetStandardIterableDataset):
|
| 20 |
+
|
| 21 |
+
def parse_row(self, row):
|
| 22 |
+
image_num = len(row["image_list"])
|
| 23 |
+
# randomly choose start and end, return [0, 1] when only two images
|
| 24 |
+
start_idx = random.choice(range(image_num - 1))
|
| 25 |
+
max_end = min(start_idx + 3, image_num)
|
| 26 |
+
end_idx = random.choice(range(start_idx + 1, max_end))
|
| 27 |
+
|
| 28 |
+
data = self._init_data()
|
| 29 |
+
data = self._add_image(
|
| 30 |
+
data,
|
| 31 |
+
pil_img2rgb(Image.open(io.BytesIO(row["image_list"][start_idx]))),
|
| 32 |
+
need_loss=False,
|
| 33 |
+
need_vae=True,
|
| 34 |
+
need_vit=True,
|
| 35 |
+
)
|
| 36 |
+
|
| 37 |
+
if end_idx - start_idx > 1 and random.random() < 0.5: # concat multiple insturction
|
| 38 |
+
if end_idx == image_num - 1:
|
| 39 |
+
end_idx -= 1
|
| 40 |
+
|
| 41 |
+
instruction = ""
|
| 42 |
+
for idx in range(start_idx + 1, end_idx + 1):
|
| 43 |
+
instruction += random.choice(row["instruction_list"][idx-1]) + ". "
|
| 44 |
+
data = self._add_text(data, instruction.rstrip(), need_loss=False)
|
| 45 |
+
data = self._add_image(
|
| 46 |
+
data,
|
| 47 |
+
pil_img2rgb(Image.open(io.BytesIO(row["image_list"][end_idx]))),
|
| 48 |
+
need_loss=True,
|
| 49 |
+
need_vae=False,
|
| 50 |
+
need_vit=False,
|
| 51 |
+
)
|
| 52 |
+
else:
|
| 53 |
+
for idx in range(start_idx + 1, end_idx + 1):
|
| 54 |
+
instruction = random.choice(row["instruction_list"][idx-1])
|
| 55 |
+
data = self._add_text(data, instruction, need_loss=False)
|
| 56 |
+
if idx != end_idx:
|
| 57 |
+
data = self._add_image(
|
| 58 |
+
data,
|
| 59 |
+
pil_img2rgb(Image.open(io.BytesIO(row["image_list"][idx]))),
|
| 60 |
+
need_loss=True,
|
| 61 |
+
need_vae=True,
|
| 62 |
+
need_vit=True,
|
| 63 |
+
)
|
| 64 |
+
else:
|
| 65 |
+
data = self._add_image(
|
| 66 |
+
data,
|
| 67 |
+
pil_img2rgb(Image.open(io.BytesIO(row["image_list"][idx]))),
|
| 68 |
+
need_loss=True,
|
| 69 |
+
need_vae=False,
|
| 70 |
+
need_vit=False,
|
| 71 |
+
)
|
| 72 |
+
return data
|
data/interleave_datasets/interleave_t2i_dataset.py
ADDED
|
@@ -0,0 +1,212 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2025 Bytedance Ltd. and/or its affiliates.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 3 |
+
|
| 4 |
+
import pyarrow.parquet as pq
|
| 5 |
+
|
| 6 |
+
from ..distributed_iterable_dataset import DistributedIterableDataset
|
| 7 |
+
from ..parquet_utils import get_parquet_data_paths, init_arrow_pf_fs
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class InterleavedBaseIterableDataset(DistributedIterableDataset):
|
| 11 |
+
|
| 12 |
+
def _init_data(self):
|
| 13 |
+
data = {
|
| 14 |
+
'sequence_plan': [],
|
| 15 |
+
'text_ids_list': [],
|
| 16 |
+
'image_tensor_list': [],
|
| 17 |
+
'num_tokens': 0,
|
| 18 |
+
}
|
| 19 |
+
return data
|
| 20 |
+
|
| 21 |
+
def _add_text(self, data, text, need_loss, enable_cfg=True):
|
| 22 |
+
text_ids = self.tokenizer.encode(text)
|
| 23 |
+
data['num_tokens'] += len(text_ids)
|
| 24 |
+
data['text_ids_list'].append(text_ids)
|
| 25 |
+
data['sequence_plan'].append(
|
| 26 |
+
{
|
| 27 |
+
'type': 'text',
|
| 28 |
+
'enable_cfg': int(enable_cfg),
|
| 29 |
+
'loss': int(need_loss),
|
| 30 |
+
'special_token_loss': 0,
|
| 31 |
+
'special_token_label': None,
|
| 32 |
+
}
|
| 33 |
+
)
|
| 34 |
+
return data
|
| 35 |
+
|
| 36 |
+
def _add_image(self, data, image, need_loss, need_vae, need_vit, enable_cfg=True):
|
| 37 |
+
assert need_loss or need_vae or need_vit
|
| 38 |
+
|
| 39 |
+
if need_loss:
|
| 40 |
+
data['sequence_plan'].append(
|
| 41 |
+
{
|
| 42 |
+
'type': 'vae_image',
|
| 43 |
+
'enable_cfg': 0,
|
| 44 |
+
'loss': 1,
|
| 45 |
+
'special_token_loss': 0,
|
| 46 |
+
'special_token_label': None,
|
| 47 |
+
}
|
| 48 |
+
)
|
| 49 |
+
|
| 50 |
+
image_tensor = self.transform(image)
|
| 51 |
+
height, width = image_tensor.shape[1:]
|
| 52 |
+
data['num_tokens'] += width * height // self.transform.stride ** 2
|
| 53 |
+
data['image_tensor_list'].append(image_tensor)
|
| 54 |
+
|
| 55 |
+
if need_vae:
|
| 56 |
+
data['sequence_plan'].append(
|
| 57 |
+
{
|
| 58 |
+
'type': 'vae_image',
|
| 59 |
+
'enable_cfg': int(enable_cfg),
|
| 60 |
+
'loss': 0,
|
| 61 |
+
'special_token_loss': 0,
|
| 62 |
+
'special_token_label': None,
|
| 63 |
+
}
|
| 64 |
+
)
|
| 65 |
+
|
| 66 |
+
image_tensor = self.transform(image)
|
| 67 |
+
height, width = image_tensor.shape[1:]
|
| 68 |
+
data['num_tokens'] += width * height // self.transform.stride ** 2
|
| 69 |
+
data['image_tensor_list'].append(image_tensor.clone())
|
| 70 |
+
|
| 71 |
+
if need_vit:
|
| 72 |
+
data['sequence_plan'].append(
|
| 73 |
+
{
|
| 74 |
+
'type': 'vit_image',
|
| 75 |
+
'enable_cfg': int(enable_cfg),
|
| 76 |
+
'loss': 0,
|
| 77 |
+
'special_token_loss': 0,
|
| 78 |
+
'special_token_label': None,
|
| 79 |
+
},
|
| 80 |
+
)
|
| 81 |
+
vit_image_tensor = self.vit_transform(image)
|
| 82 |
+
height, width = vit_image_tensor.shape[1:]
|
| 83 |
+
data['num_tokens'] += width * height // self.vit_transform.stride ** 2
|
| 84 |
+
data['image_tensor_list'].append(vit_image_tensor)
|
| 85 |
+
|
| 86 |
+
return data
|
| 87 |
+
|
| 88 |
+
def _add_video(self, data, frames, frame_indexes, need_loss, need_vae, enable_cfg=True):
|
| 89 |
+
assert int(need_loss) + int(need_vae) == 1
|
| 90 |
+
|
| 91 |
+
if need_loss:
|
| 92 |
+
for idx, (image, frame_idx) in enumerate(zip(frames, frame_indexes)):
|
| 93 |
+
current_sequence_plan = {
|
| 94 |
+
'type': 'vae_image',
|
| 95 |
+
'enable_cfg': 0,
|
| 96 |
+
'loss': 1,
|
| 97 |
+
'special_token_loss': 0,
|
| 98 |
+
'special_token_label': None,
|
| 99 |
+
'split_start': idx == 0,
|
| 100 |
+
'split_end': idx == len(frames) - 1,
|
| 101 |
+
}
|
| 102 |
+
if idx < len(frame_indexes) - 1:
|
| 103 |
+
current_sequence_plan['frame_delta'] = frame_indexes[idx + 1] - frame_idx
|
| 104 |
+
data['sequence_plan'].append(current_sequence_plan)
|
| 105 |
+
image_tensor = self.transform(image)
|
| 106 |
+
height, width = image_tensor.shape[1:]
|
| 107 |
+
data['image_tensor_list'].append(image_tensor)
|
| 108 |
+
data['num_tokens'] += width * height // self.transform.stride ** 2
|
| 109 |
+
|
| 110 |
+
elif need_vae:
|
| 111 |
+
for idx, (image, frame_idx) in enumerate(zip(frames, frame_indexes)):
|
| 112 |
+
current_sequence_plan = {
|
| 113 |
+
'type': 'vae_image',
|
| 114 |
+
'enable_cfg': int(enable_cfg),
|
| 115 |
+
'loss': 0,
|
| 116 |
+
'special_token_loss': 0,
|
| 117 |
+
'special_token_label': None,
|
| 118 |
+
'split_start': idx == 0,
|
| 119 |
+
'split_end': idx == len(frames) - 1,
|
| 120 |
+
}
|
| 121 |
+
if idx < len(frame_indexes) - 1:
|
| 122 |
+
current_sequence_plan['frame_delta'] = frame_indexes[idx + 1] - frame_idx
|
| 123 |
+
data['sequence_plan'].append(current_sequence_plan)
|
| 124 |
+
image_tensor = self.transform(image)
|
| 125 |
+
height, width = image_tensor.shape[1:]
|
| 126 |
+
data['image_tensor_list'].append(image_tensor)
|
| 127 |
+
data['num_tokens'] += width * height // self.transform.stride ** 2
|
| 128 |
+
|
| 129 |
+
return data
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
class ParquetStandardIterableDataset(DistributedIterableDataset):
|
| 133 |
+
|
| 134 |
+
def __init__(
|
| 135 |
+
self, dataset_name, transform, tokenizer, vit_transform,
|
| 136 |
+
data_dir_list, num_used_data, parquet_info,
|
| 137 |
+
local_rank=0, world_size=1, num_workers=8, data_status=None,
|
| 138 |
+
):
|
| 139 |
+
"""
|
| 140 |
+
data_dir_list: list of data directories contains parquet files
|
| 141 |
+
num_used_data: list of number of sampled data paths for each data directory
|
| 142 |
+
vit_transform: input transform for vit model.
|
| 143 |
+
"""
|
| 144 |
+
super().__init__(dataset_name, local_rank, world_size, num_workers)
|
| 145 |
+
self.transform = transform
|
| 146 |
+
self.vit_transform = vit_transform
|
| 147 |
+
self.tokenizer = tokenizer
|
| 148 |
+
self.data_status = data_status
|
| 149 |
+
self.data_paths = self.get_data_paths(data_dir_list, num_used_data, parquet_info)
|
| 150 |
+
self.set_epoch()
|
| 151 |
+
|
| 152 |
+
def get_data_paths(self, data_dir_list, num_used_data, parquet_info):
|
| 153 |
+
row_groups = []
|
| 154 |
+
for data_dir, num_data_path in zip(data_dir_list, num_used_data):
|
| 155 |
+
data_paths = get_parquet_data_paths([data_dir], [num_data_path])
|
| 156 |
+
for data_path in data_paths:
|
| 157 |
+
if data_path in parquet_info.keys():
|
| 158 |
+
num_row_groups = parquet_info[data_path]['num_row_groups']
|
| 159 |
+
for rg_idx in range(num_row_groups):
|
| 160 |
+
row_groups.append((data_path, rg_idx))
|
| 161 |
+
return row_groups
|
| 162 |
+
|
| 163 |
+
def parse_row(self, row):
|
| 164 |
+
raise NotImplementedError
|
| 165 |
+
|
| 166 |
+
def __iter__(self):
|
| 167 |
+
file_paths_per_worker, worker_id = self.get_data_paths_per_worker()
|
| 168 |
+
if self.data_status is not None:
|
| 169 |
+
global_row_group_start_id = self.data_status[worker_id][0]
|
| 170 |
+
row_start_id = self.data_status[worker_id][1] + 1
|
| 171 |
+
else:
|
| 172 |
+
global_row_group_start_id = 0
|
| 173 |
+
row_start_id = 0
|
| 174 |
+
|
| 175 |
+
print(
|
| 176 |
+
f"rank-{self.local_rank} worker-{worker_id} dataset-{self.dataset_name}: "
|
| 177 |
+
f"resuming data at global_rg#{global_row_group_start_id}, row#{row_start_id}"
|
| 178 |
+
)
|
| 179 |
+
|
| 180 |
+
while True:
|
| 181 |
+
file_paths_per_worker_ = file_paths_per_worker[global_row_group_start_id:]
|
| 182 |
+
for global_row_group_idx, (parquet_file_path, row_group_id) in enumerate(
|
| 183 |
+
file_paths_per_worker_, start=global_row_group_start_id
|
| 184 |
+
):
|
| 185 |
+
fs = init_arrow_pf_fs(parquet_file_path)
|
| 186 |
+
with fs.open_input_file(parquet_file_path) as f:
|
| 187 |
+
try:
|
| 188 |
+
fr = pq.ParquetFile(f)
|
| 189 |
+
df = fr.read_row_group(row_group_id).to_pandas()
|
| 190 |
+
df = df.iloc[row_start_id:]
|
| 191 |
+
except Exception as e:
|
| 192 |
+
print(f'Error {e} in rg#{row_group_id}, {parquet_file_path}')
|
| 193 |
+
continue
|
| 194 |
+
|
| 195 |
+
for row_idx, row in df.iterrows():
|
| 196 |
+
try:
|
| 197 |
+
data = self.parse_row(row)
|
| 198 |
+
if len(data) == 0:
|
| 199 |
+
continue
|
| 200 |
+
data['data_indexes'] = {
|
| 201 |
+
"data_indexes": [global_row_group_idx, row_idx],
|
| 202 |
+
"worker_id": worker_id,
|
| 203 |
+
"dataset_name": self.dataset_name,
|
| 204 |
+
}
|
| 205 |
+
except Exception as e:
|
| 206 |
+
print(f'Error {e} in rg#{row_group_id}, {parquet_file_path}')
|
| 207 |
+
continue
|
| 208 |
+
yield data
|
| 209 |
+
|
| 210 |
+
row_start_id = 0
|
| 211 |
+
global_row_group_start_id = 0
|
| 212 |
+
print(f"{self.dataset_name} repeat in rank-{self.local_rank} worker-{worker_id}")
|
data/parquet_utils.py
ADDED
|
@@ -0,0 +1,90 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2025 Bytedance Ltd. and/or its affiliates.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
import os
|
| 6 |
+
import xml.etree.ElementTree as ET
|
| 7 |
+
import subprocess
|
| 8 |
+
import logging
|
| 9 |
+
|
| 10 |
+
import pyarrow.fs as pf
|
| 11 |
+
import torch.distributed as dist
|
| 12 |
+
|
| 13 |
+
logger = logging.getLogger(__name__)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def get_parquet_data_paths(data_dir_list, num_sampled_data_paths, rank=0, world_size=1):
|
| 17 |
+
num_data_dirs = len(data_dir_list)
|
| 18 |
+
if world_size > 1:
|
| 19 |
+
chunk_size = (num_data_dirs + world_size - 1) // world_size
|
| 20 |
+
start_idx = rank * chunk_size
|
| 21 |
+
end_idx = min(start_idx + chunk_size, num_data_dirs)
|
| 22 |
+
local_data_dir_list = data_dir_list[start_idx:end_idx]
|
| 23 |
+
local_num_sampled_data_paths = num_sampled_data_paths[start_idx:end_idx]
|
| 24 |
+
else:
|
| 25 |
+
local_data_dir_list = data_dir_list
|
| 26 |
+
local_num_sampled_data_paths = num_sampled_data_paths
|
| 27 |
+
|
| 28 |
+
local_data_paths = []
|
| 29 |
+
for data_dir, num_data_path in zip(local_data_dir_list, local_num_sampled_data_paths):
|
| 30 |
+
if data_dir.startswith("hdfs://"):
|
| 31 |
+
files = hdfs_ls_cmd(data_dir)
|
| 32 |
+
data_paths_per_dir = [
|
| 33 |
+
file for file in files if file.endswith(".parquet")
|
| 34 |
+
]
|
| 35 |
+
else:
|
| 36 |
+
files = os.listdir(data_dir)
|
| 37 |
+
data_paths_per_dir = [
|
| 38 |
+
os.path.join(data_dir, name)
|
| 39 |
+
for name in files
|
| 40 |
+
if name.endswith(".parquet")
|
| 41 |
+
]
|
| 42 |
+
repeat = num_data_path // len(data_paths_per_dir)
|
| 43 |
+
data_paths_per_dir = data_paths_per_dir * (repeat + 1)
|
| 44 |
+
local_data_paths.extend(data_paths_per_dir[:num_data_path])
|
| 45 |
+
|
| 46 |
+
if world_size > 1:
|
| 47 |
+
gather_list = [None] * world_size
|
| 48 |
+
dist.all_gather_object(gather_list, local_data_paths)
|
| 49 |
+
|
| 50 |
+
combined_chunks = []
|
| 51 |
+
for chunk_list in gather_list:
|
| 52 |
+
if chunk_list is not None:
|
| 53 |
+
combined_chunks.extend(chunk_list)
|
| 54 |
+
else:
|
| 55 |
+
combined_chunks = local_data_paths
|
| 56 |
+
|
| 57 |
+
return combined_chunks
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
# NOTE: cumtomize this function for your cluster
|
| 61 |
+
def get_hdfs_host():
|
| 62 |
+
return "hdfs://xxx"
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
# NOTE: cumtomize this function for your cluster
|
| 66 |
+
def get_hdfs_block_size():
|
| 67 |
+
return 134217728
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
# NOTE: cumtomize this function for your cluster
|
| 71 |
+
def get_hdfs_extra_conf():
|
| 72 |
+
return None
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def init_arrow_pf_fs(parquet_file_path):
|
| 76 |
+
if parquet_file_path.startswith("hdfs://"):
|
| 77 |
+
fs = pf.HadoopFileSystem(
|
| 78 |
+
host=get_hdfs_host(),
|
| 79 |
+
port=0,
|
| 80 |
+
buffer_size=get_hdfs_block_size(),
|
| 81 |
+
extra_conf=get_hdfs_extra_conf(),
|
| 82 |
+
)
|
| 83 |
+
else:
|
| 84 |
+
fs = pf.LocalFileSystem()
|
| 85 |
+
return fs
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def hdfs_ls_cmd(dir):
|
| 89 |
+
result = subprocess.run(["hdfs", "dfs", "ls", dir], capture_output=True, text=True).stdout
|
| 90 |
+
return ['hdfs://' + i.split('hdfs://')[-1].strip() for i in result.split('\n') if 'hdfs://' in i]
|
data/t2i_dataset.py
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2025 Bytedance Ltd. and/or its affiliates.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 3 |
+
|
| 4 |
+
import io
|
| 5 |
+
import json
|
| 6 |
+
import pyarrow.parquet as pq
|
| 7 |
+
import random
|
| 8 |
+
from PIL import Image
|
| 9 |
+
|
| 10 |
+
from .data_utils import pil_img2rgb
|
| 11 |
+
from .distributed_iterable_dataset import DistributedIterableDataset
|
| 12 |
+
from .parquet_utils import get_parquet_data_paths, init_arrow_pf_fs
|
| 13 |
+
|
| 14 |
+
Image.MAX_IMAGE_PIXELS = 20_000_000
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class T2IIterableDataset(DistributedIterableDataset):
|
| 18 |
+
def __init__(
|
| 19 |
+
self, dataset_name, transform, tokenizer, data_dir_list, num_used_data,
|
| 20 |
+
local_rank=0, world_size=1, num_workers=8, data_status=None,
|
| 21 |
+
):
|
| 22 |
+
"""
|
| 23 |
+
data_dir_list: list of data directories contains parquet files
|
| 24 |
+
num_used_data: list of number of sampled data paths for each data directory
|
| 25 |
+
"""
|
| 26 |
+
super().__init__(dataset_name, local_rank, world_size, num_workers)
|
| 27 |
+
self.transform = transform
|
| 28 |
+
self.tokenizer = tokenizer
|
| 29 |
+
self.data_status = data_status
|
| 30 |
+
self.data_paths = self.get_data_paths(data_dir_list, num_used_data)
|
| 31 |
+
self.set_epoch()
|
| 32 |
+
|
| 33 |
+
def get_data_paths(self, data_dir_list, num_used_data):
|
| 34 |
+
return get_parquet_data_paths(data_dir_list, num_used_data)
|
| 35 |
+
|
| 36 |
+
def __iter__(self):
|
| 37 |
+
data_paths_per_worker, worker_id = self.get_data_paths_per_worker()
|
| 38 |
+
if self.data_status is not None:
|
| 39 |
+
parquet_start_id = self.data_status[worker_id][0]
|
| 40 |
+
row_group_start_id = self.data_status[worker_id][1]
|
| 41 |
+
row_start_id = self.data_status[worker_id][2] + 1
|
| 42 |
+
else:
|
| 43 |
+
parquet_start_id = 0
|
| 44 |
+
row_group_start_id = 0
|
| 45 |
+
row_start_id = 0
|
| 46 |
+
transform_stride = self.transform.stride
|
| 47 |
+
|
| 48 |
+
print(
|
| 49 |
+
f"rank-{self.local_rank} worker-{worker_id} dataset-{self.dataset_name}: "
|
| 50 |
+
f"resuming data at parquet#{parquet_start_id}, rg#{row_group_start_id}, row#{row_start_id}"
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
while True:
|
| 54 |
+
data_paths_per_worker_ = data_paths_per_worker[parquet_start_id:]
|
| 55 |
+
for parquet_idx, parquet_file_path in enumerate(data_paths_per_worker_, start=parquet_start_id):
|
| 56 |
+
fs = init_arrow_pf_fs(parquet_file_path)
|
| 57 |
+
with fs.open_input_file(parquet_file_path) as f:
|
| 58 |
+
fr = pq.ParquetFile(f)
|
| 59 |
+
row_group_ids = list(range(fr.num_row_groups))
|
| 60 |
+
row_group_ids_ = row_group_ids[row_group_start_id:]
|
| 61 |
+
|
| 62 |
+
for row_group_id in row_group_ids_:
|
| 63 |
+
df = fr.read_row_group(row_group_id).to_pandas()
|
| 64 |
+
df = df.iloc[row_start_id:]
|
| 65 |
+
|
| 66 |
+
for row_idx, row in df.iterrows():
|
| 67 |
+
num_tokens = 0
|
| 68 |
+
try:
|
| 69 |
+
image_byte = row['image']
|
| 70 |
+
image = pil_img2rgb(Image.open(io.BytesIO(image_byte)))
|
| 71 |
+
except Exception as e:
|
| 72 |
+
print(f'Error: {e} in rg#{row_group_id}, {parquet_file_path}')
|
| 73 |
+
continue
|
| 74 |
+
image_tensor = self.transform(image)
|
| 75 |
+
height, width = image_tensor.shape[1:]
|
| 76 |
+
num_tokens += width * height // transform_stride ** 2
|
| 77 |
+
|
| 78 |
+
try:
|
| 79 |
+
caption_dict = row['captions']
|
| 80 |
+
caption_dict = json.loads(caption_dict)
|
| 81 |
+
except Exception as e:
|
| 82 |
+
print(f'Error: {e} in rg#{row_group_id}, {parquet_file_path}')
|
| 83 |
+
continue
|
| 84 |
+
|
| 85 |
+
caps_token = [self.tokenizer.encode(v) for _, v in caption_dict.items()]
|
| 86 |
+
if len(caps_token) == 0:
|
| 87 |
+
print(f'no caption in rg#{row_group_id}, {parquet_file_path}')
|
| 88 |
+
caption_token = self.tokenizer.encode(' ')
|
| 89 |
+
else:
|
| 90 |
+
caption_token = random.choice(caps_token)
|
| 91 |
+
|
| 92 |
+
sequence_plan, text_ids_list = [], []
|
| 93 |
+
text_ids = caption_token
|
| 94 |
+
num_tokens += len(caption_token)
|
| 95 |
+
text_ids_list.append(text_ids)
|
| 96 |
+
sequence_plan.append({
|
| 97 |
+
'type': 'text',
|
| 98 |
+
'enable_cfg': 1,
|
| 99 |
+
'loss': 0,
|
| 100 |
+
'special_token_loss': 0,
|
| 101 |
+
'special_token_label': None,
|
| 102 |
+
})
|
| 103 |
+
|
| 104 |
+
sequence_plan.append({
|
| 105 |
+
'type': 'vae_image',
|
| 106 |
+
'enable_cfg': 0,
|
| 107 |
+
'loss': 1,
|
| 108 |
+
'special_token_loss': 0,
|
| 109 |
+
'special_token_label': None,
|
| 110 |
+
})
|
| 111 |
+
|
| 112 |
+
sample = dict(
|
| 113 |
+
image_tensor_list=[image_tensor],
|
| 114 |
+
text_ids_list=text_ids_list,
|
| 115 |
+
num_tokens=num_tokens,
|
| 116 |
+
sequence_plan=sequence_plan,
|
| 117 |
+
data_indexes={
|
| 118 |
+
"data_indexes": [parquet_idx, row_group_id, row_idx],
|
| 119 |
+
"worker_id": worker_id,
|
| 120 |
+
"dataset_name": self.dataset_name,
|
| 121 |
+
}
|
| 122 |
+
)
|
| 123 |
+
yield sample
|
| 124 |
+
|
| 125 |
+
row_start_id = 0
|
| 126 |
+
row_group_start_id = 0
|
| 127 |
+
parquet_start_id = 0
|
| 128 |
+
print(f"{self.dataset_name} repeat in rank-{self.local_rank} worker-{worker_id}")
|
data/transforms.py
ADDED
|
@@ -0,0 +1,287 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2025 Bytedance Ltd. and/or its affiliates.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 3 |
+
|
| 4 |
+
import random
|
| 5 |
+
from PIL import Image
|
| 6 |
+
|
| 7 |
+
import cv2
|
| 8 |
+
import numpy as np
|
| 9 |
+
import torch
|
| 10 |
+
from torchvision import transforms
|
| 11 |
+
from torchvision.transforms import functional as F
|
| 12 |
+
from torchvision.transforms import InterpolationMode
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class MaxLongEdgeMinShortEdgeResize(torch.nn.Module):
|
| 16 |
+
"""Resize the input image so that its longest side and shortest side are within a specified range,
|
| 17 |
+
ensuring that both sides are divisible by a specified stride.
|
| 18 |
+
|
| 19 |
+
Args:
|
| 20 |
+
max_size (int): Maximum size for the longest edge of the image.
|
| 21 |
+
min_size (int): Minimum size for the shortest edge of the image.
|
| 22 |
+
stride (int): Value by which the height and width of the image must be divisible.
|
| 23 |
+
max_pixels (int): Maximum pixels for the full image.
|
| 24 |
+
interpolation (InterpolationMode): Desired interpolation enum defined by
|
| 25 |
+
:class:`torchvision.transforms.InterpolationMode`. Default is ``InterpolationMode.BILINEAR``.
|
| 26 |
+
If input is Tensor, only ``InterpolationMode.NEAREST``, ``InterpolationMode.NEAREST_EXACT``,
|
| 27 |
+
``InterpolationMode.BILINEAR``, and ``InterpolationMode.BICUBIC`` are supported.
|
| 28 |
+
The corresponding Pillow integer constants, e.g., ``PIL.Image.BILINEAR`` are also accepted.
|
| 29 |
+
antialias (bool, optional): Whether to apply antialiasing (default is True).
|
| 30 |
+
"""
|
| 31 |
+
|
| 32 |
+
def __init__(
|
| 33 |
+
self,
|
| 34 |
+
max_size: int,
|
| 35 |
+
min_size: int,
|
| 36 |
+
stride: int,
|
| 37 |
+
max_pixels: int,
|
| 38 |
+
interpolation=InterpolationMode.BICUBIC,
|
| 39 |
+
antialias=True
|
| 40 |
+
):
|
| 41 |
+
super().__init__()
|
| 42 |
+
self.max_size = max_size
|
| 43 |
+
self.min_size = min_size
|
| 44 |
+
self.stride = stride
|
| 45 |
+
self.max_pixels = max_pixels
|
| 46 |
+
self.interpolation = interpolation
|
| 47 |
+
self.antialias = antialias
|
| 48 |
+
|
| 49 |
+
def _make_divisible(self, value, stride):
|
| 50 |
+
"""Ensure the value is divisible by the stride."""
|
| 51 |
+
return max(stride, int(round(value / stride) * stride))
|
| 52 |
+
|
| 53 |
+
def _apply_scale(self, width, height, scale):
|
| 54 |
+
new_width = round(width * scale)
|
| 55 |
+
new_height = round(height * scale)
|
| 56 |
+
new_width = self._make_divisible(new_width, self.stride)
|
| 57 |
+
new_height = self._make_divisible(new_height, self.stride)
|
| 58 |
+
return new_width, new_height
|
| 59 |
+
|
| 60 |
+
def forward(self, img, img_num=1):
|
| 61 |
+
"""
|
| 62 |
+
Args:
|
| 63 |
+
img (PIL Image): Image to be resized.
|
| 64 |
+
img_num (int): Number of images, used to change max_tokens.
|
| 65 |
+
Returns:
|
| 66 |
+
PIL Image or Tensor: Rescaled image with divisible dimensions.
|
| 67 |
+
"""
|
| 68 |
+
if isinstance(img, torch.Tensor):
|
| 69 |
+
height, width = img.shape[-2:]
|
| 70 |
+
else:
|
| 71 |
+
width, height = img.size
|
| 72 |
+
|
| 73 |
+
scale = min(self.max_size / max(width, height), 1.0)
|
| 74 |
+
scale = max(scale, self.min_size / min(width, height))
|
| 75 |
+
new_width, new_height = self._apply_scale(width, height, scale)
|
| 76 |
+
|
| 77 |
+
# Ensure the number of pixels does not exceed max_pixels
|
| 78 |
+
if new_width * new_height > self.max_pixels / img_num:
|
| 79 |
+
scale = self.max_pixels / img_num / (new_width * new_height)
|
| 80 |
+
new_width, new_height = self._apply_scale(new_width, new_height, scale)
|
| 81 |
+
|
| 82 |
+
# Ensure longest edge does not exceed max_size
|
| 83 |
+
if max(new_width, new_height) > self.max_size:
|
| 84 |
+
scale = self.max_size / max(new_width, new_height)
|
| 85 |
+
new_width, new_height = self._apply_scale(new_width, new_height, scale)
|
| 86 |
+
|
| 87 |
+
return F.resize(img, (new_height, new_width), self.interpolation, antialias=self.antialias)
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
class ImageTransform:
|
| 91 |
+
def __init__(
|
| 92 |
+
self,
|
| 93 |
+
max_image_size,
|
| 94 |
+
min_image_size,
|
| 95 |
+
image_stride,
|
| 96 |
+
max_pixels=14*14*9*1024,
|
| 97 |
+
image_mean=[0.5, 0.5, 0.5],
|
| 98 |
+
image_std=[0.5, 0.5, 0.5]
|
| 99 |
+
):
|
| 100 |
+
self.stride = image_stride
|
| 101 |
+
|
| 102 |
+
self.resize_transform = MaxLongEdgeMinShortEdgeResize(
|
| 103 |
+
max_size=max_image_size,
|
| 104 |
+
min_size=min_image_size,
|
| 105 |
+
stride=image_stride,
|
| 106 |
+
max_pixels=max_pixels,
|
| 107 |
+
)
|
| 108 |
+
self.to_tensor_transform = transforms.ToTensor()
|
| 109 |
+
self.normalize_transform = transforms.Normalize(mean=image_mean, std=image_std, inplace=True)
|
| 110 |
+
|
| 111 |
+
def __call__(self, img, img_num=1):
|
| 112 |
+
img = self.resize_transform(img, img_num=img_num)
|
| 113 |
+
img = self.to_tensor_transform(img)
|
| 114 |
+
img = self.normalize_transform(img)
|
| 115 |
+
return img
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def decolorization(image):
|
| 119 |
+
gray_image = image.convert('L')
|
| 120 |
+
return Image.merge(image.mode, [gray_image] * 3) if image.mode in ('RGB', 'L') else gray_image
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
def downscale(image, scale_factor):
|
| 124 |
+
new_width = int(round(image.width * scale_factor))
|
| 125 |
+
new_height = int(round(image.height * scale_factor))
|
| 126 |
+
new_width = max(1, new_width)
|
| 127 |
+
new_height = max(1, new_height)
|
| 128 |
+
return image.resize((new_width, new_height), resample=Image.BICUBIC)
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
def crop(image, crop_factors):
|
| 132 |
+
target_h, target_w = crop_factors
|
| 133 |
+
img_w, img_h = image.size
|
| 134 |
+
|
| 135 |
+
if target_h > img_h or target_w > img_w:
|
| 136 |
+
raise ValueError("Crop size exceeds image dimensions")
|
| 137 |
+
|
| 138 |
+
x = random.randint(0, img_w - target_w)
|
| 139 |
+
y = random.randint(0, img_h - target_h)
|
| 140 |
+
|
| 141 |
+
return image.crop((x, y, x + target_w, y + target_h)), [[x, y], [x + target_w, y + target_h]]
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
def motion_blur_opencv(image, kernel_size=15, angle=0):
|
| 145 |
+
# 线性核
|
| 146 |
+
kernel = np.zeros((kernel_size, kernel_size), dtype=np.float32)
|
| 147 |
+
kernel[kernel_size // 2, :] = np.ones(kernel_size, dtype=np.float32)
|
| 148 |
+
|
| 149 |
+
# 旋转核
|
| 150 |
+
center = (kernel_size / 2 - 0.5, kernel_size / 2 - 0.5)
|
| 151 |
+
M = cv2.getRotationMatrix2D(center, angle, 1)
|
| 152 |
+
rotated_kernel = cv2.warpAffine(kernel, M, (kernel_size, kernel_size))
|
| 153 |
+
|
| 154 |
+
# 归一化核
|
| 155 |
+
rotated_kernel /= rotated_kernel.sum() if rotated_kernel.sum() != 0 else 1
|
| 156 |
+
|
| 157 |
+
img = np.array(image)
|
| 158 |
+
if img.ndim == 2:
|
| 159 |
+
blurred = cv2.filter2D(img, -1, rotated_kernel, borderType=cv2.BORDER_REFLECT)
|
| 160 |
+
else:
|
| 161 |
+
# 对于彩色图像,各通道独立卷积
|
| 162 |
+
blurred = np.zeros_like(img)
|
| 163 |
+
for c in range(img.shape[2]):
|
| 164 |
+
blurred[..., c] = cv2.filter2D(img[..., c], -1, rotated_kernel, borderType=cv2.BORDER_REFLECT)
|
| 165 |
+
|
| 166 |
+
return Image.fromarray(blurred.astype(np.uint8))
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
def shuffle_patch(image, num_splits, gap_size=2):
|
| 170 |
+
"""将图像分割为块(允许尺寸不整除),随机打乱后拼接,块间保留间隙"""
|
| 171 |
+
h_splits, w_splits = num_splits
|
| 172 |
+
img_w, img_h = image.size
|
| 173 |
+
|
| 174 |
+
base_patch_h = img_h // h_splits
|
| 175 |
+
patch_heights = [base_patch_h] * (h_splits - 1)
|
| 176 |
+
patch_heights.append(img_h - sum(patch_heights))
|
| 177 |
+
|
| 178 |
+
base_patch_w = img_w // w_splits
|
| 179 |
+
patch_widths = [base_patch_w] * (w_splits - 1)
|
| 180 |
+
patch_widths.append(img_w - sum(patch_widths))
|
| 181 |
+
|
| 182 |
+
patches = []
|
| 183 |
+
current_y = 0
|
| 184 |
+
for i in range(h_splits):
|
| 185 |
+
current_x = 0
|
| 186 |
+
patch_h = patch_heights[i]
|
| 187 |
+
for j in range(w_splits):
|
| 188 |
+
patch_w = patch_widths[j]
|
| 189 |
+
patch = image.crop((current_x, current_y, current_x + patch_w, current_y + patch_h))
|
| 190 |
+
patches.append(patch)
|
| 191 |
+
current_x += patch_w
|
| 192 |
+
current_y += patch_h
|
| 193 |
+
|
| 194 |
+
random.shuffle(patches)
|
| 195 |
+
|
| 196 |
+
total_width = sum(patch_widths) + (w_splits - 1) * gap_size
|
| 197 |
+
total_height = sum(patch_heights) + (h_splits - 1) * gap_size
|
| 198 |
+
new_image = Image.new(image.mode, (total_width, total_height), color=(255, 255, 255))
|
| 199 |
+
|
| 200 |
+
current_y = 0 # 当前行的起始 Y 坐标
|
| 201 |
+
patch_idx = 0 # 当前处理的块索引
|
| 202 |
+
for i in range(h_splits):
|
| 203 |
+
current_x = 0 # 当前列的起始 X 坐标
|
| 204 |
+
patch_h = patch_heights[i] # 当前行块的高度
|
| 205 |
+
for j in range(w_splits):
|
| 206 |
+
# 取出打乱后的块
|
| 207 |
+
patch = patches[patch_idx]
|
| 208 |
+
patch_w = patch_widths[j] # 当前列块的宽度
|
| 209 |
+
# 粘贴块(左上角坐标为 (current_x, current_y))
|
| 210 |
+
new_image.paste(patch, (current_x, current_y))
|
| 211 |
+
# 更新 X 坐标(下一个块的起始位置 = 当前块宽度 + 间隙)
|
| 212 |
+
current_x += patch_w + gap_size
|
| 213 |
+
patch_idx += 1
|
| 214 |
+
# 更新 Y 坐标(下一行的起始位置 = 当前行高度 + 间隙)
|
| 215 |
+
current_y += patch_h + gap_size
|
| 216 |
+
|
| 217 |
+
return new_image
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
def inpainting(image, num_splits, blank_ratio=0.3, blank_color=(255, 255, 255)):
|
| 221 |
+
"""
|
| 222 |
+
图像分割后随机空白部分patch,用于inpainting任务
|
| 223 |
+
|
| 224 |
+
参数:
|
| 225 |
+
image: PIL.Image 输入图像(RGB模式)
|
| 226 |
+
h_splits: int 行分割数(垂直方向分割块数)
|
| 227 |
+
w_splits: int 列分割数(水平方向分割块数)
|
| 228 |
+
blank_ratio: float 空白patch的比例(0~1)
|
| 229 |
+
blank_color: tuple 空白区域的颜色(RGB,如白色(255,255,255))
|
| 230 |
+
|
| 231 |
+
返回:
|
| 232 |
+
PIL.Image 处理后拼接的图像
|
| 233 |
+
"""
|
| 234 |
+
h_splits, w_splits = num_splits
|
| 235 |
+
img_w, img_h = image.size
|
| 236 |
+
|
| 237 |
+
base_patch_h = img_h // h_splits
|
| 238 |
+
patch_heights = [base_patch_h] * (h_splits - 1)
|
| 239 |
+
patch_heights.append(img_h - sum(patch_heights))
|
| 240 |
+
|
| 241 |
+
base_patch_w = img_w // w_splits
|
| 242 |
+
patch_widths = [base_patch_w] * (w_splits - 1)
|
| 243 |
+
patch_widths.append(img_w - sum(patch_widths))
|
| 244 |
+
|
| 245 |
+
patches = []
|
| 246 |
+
current_y = 0
|
| 247 |
+
for i in range(h_splits):
|
| 248 |
+
current_x = 0
|
| 249 |
+
patch_h = patch_heights[i]
|
| 250 |
+
for j in range(w_splits):
|
| 251 |
+
patch_w = patch_widths[j]
|
| 252 |
+
patch = image.crop((current_x, current_y, current_x + patch_w, current_y + patch_h))
|
| 253 |
+
patches.append(patch)
|
| 254 |
+
current_x += patch_w
|
| 255 |
+
current_y += patch_h
|
| 256 |
+
|
| 257 |
+
total_patches = h_splits * w_splits
|
| 258 |
+
num_blank = int(total_patches * blank_ratio)
|
| 259 |
+
num_blank = max(0, min(num_blank, total_patches))
|
| 260 |
+
blank_indices = random.sample(range(total_patches), num_blank)
|
| 261 |
+
|
| 262 |
+
processed_patches = []
|
| 263 |
+
for idx, patch in enumerate(patches):
|
| 264 |
+
if idx in blank_indices:
|
| 265 |
+
blank_patch = Image.new("RGB", patch.size, color=blank_color)
|
| 266 |
+
processed_patches.append(blank_patch)
|
| 267 |
+
else:
|
| 268 |
+
processed_patches.append(patch)
|
| 269 |
+
|
| 270 |
+
# 创建结果图像(尺寸与原图一致)
|
| 271 |
+
result_image = Image.new("RGB", (img_w, img_h))
|
| 272 |
+
current_y = 0
|
| 273 |
+
patch_idx = 0
|
| 274 |
+
for i in range(h_splits):
|
| 275 |
+
current_x = 0
|
| 276 |
+
patch_h = patch_heights[i]
|
| 277 |
+
for j in range(w_splits):
|
| 278 |
+
# 取出处理后的patch
|
| 279 |
+
patch = processed_patches[patch_idx]
|
| 280 |
+
patch_w = patch_widths[j]
|
| 281 |
+
# 粘贴到原位置
|
| 282 |
+
result_image.paste(patch, (current_x, current_y))
|
| 283 |
+
current_x += patch_w
|
| 284 |
+
patch_idx += 1
|
| 285 |
+
current_y += patch_h
|
| 286 |
+
|
| 287 |
+
return result_image
|
data/video_utils.py
ADDED
|
@@ -0,0 +1,165 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023 OpenGVLab
|
| 2 |
+
# Copyright (c) 2025 Bytedance Ltd. and/or its affiliates.
|
| 3 |
+
# SPDX-License-Identifier: MIT
|
| 4 |
+
#
|
| 5 |
+
# This file has been modified by ByteDance Ltd. and/or its affiliates. on 2025-05-20.
|
| 6 |
+
#
|
| 7 |
+
# Original file was released under MIT, with the full license text
|
| 8 |
+
# available at https://github.com/OpenGVLab/InternVL/blob/main/LICENSE.
|
| 9 |
+
#
|
| 10 |
+
# This modified file is released under the same license.
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
import io
|
| 14 |
+
import os
|
| 15 |
+
import random
|
| 16 |
+
import re
|
| 17 |
+
|
| 18 |
+
import numpy as np
|
| 19 |
+
import decord
|
| 20 |
+
from PIL import Image
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def get_frame_indices(num_frames, vlen, sample='rand', fix_start=None, input_fps=1, max_num_frames=-1):
|
| 24 |
+
if sample in ['rand', 'middle']: # uniform sampling
|
| 25 |
+
acc_samples = min(num_frames, vlen)
|
| 26 |
+
# split the video into `acc_samples` intervals, and sample from each interval.
|
| 27 |
+
intervals = np.linspace(start=0, stop=vlen, num=acc_samples + 1).astype(int)
|
| 28 |
+
ranges = []
|
| 29 |
+
for idx, interv in enumerate(intervals[:-1]):
|
| 30 |
+
ranges.append((interv, intervals[idx + 1] - 1))
|
| 31 |
+
if sample == 'rand':
|
| 32 |
+
try:
|
| 33 |
+
frame_indices = [random.choice(range(x[0], x[1])) for x in ranges]
|
| 34 |
+
except:
|
| 35 |
+
frame_indices = np.random.permutation(vlen)[:acc_samples]
|
| 36 |
+
frame_indices.sort()
|
| 37 |
+
frame_indices = list(frame_indices)
|
| 38 |
+
elif fix_start is not None:
|
| 39 |
+
frame_indices = [x[0] + fix_start for x in ranges]
|
| 40 |
+
elif sample == 'middle':
|
| 41 |
+
frame_indices = [(x[0] + x[1]) // 2 for x in ranges]
|
| 42 |
+
else:
|
| 43 |
+
raise NotImplementedError
|
| 44 |
+
|
| 45 |
+
if len(frame_indices) < num_frames: # padded with last frame
|
| 46 |
+
padded_frame_indices = [frame_indices[-1]] * num_frames
|
| 47 |
+
padded_frame_indices[:len(frame_indices)] = frame_indices
|
| 48 |
+
frame_indices = padded_frame_indices
|
| 49 |
+
elif 'fps' in sample: # fps0.5, sequentially sample frames at 0.5 fps
|
| 50 |
+
output_fps = float(sample[3:])
|
| 51 |
+
duration = float(vlen) / input_fps
|
| 52 |
+
delta = 1 / output_fps # gap between frames, this is also the clip length each frame represents
|
| 53 |
+
frame_seconds = np.arange(0 + delta / 2, duration + delta / 2, delta)
|
| 54 |
+
frame_indices = np.around(frame_seconds * input_fps).astype(int)
|
| 55 |
+
frame_indices = [e for e in frame_indices if e < vlen]
|
| 56 |
+
if max_num_frames > 0 and len(frame_indices) > max_num_frames:
|
| 57 |
+
frame_indices = frame_indices[:max_num_frames]
|
| 58 |
+
else:
|
| 59 |
+
raise ValueError
|
| 60 |
+
return frame_indices
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def read_frames_decord(video_path, num_frames, sample='rand', fix_start=None, clip=None, min_num_frames=4):
|
| 64 |
+
video_reader = decord.VideoReader(video_path, num_threads=1)
|
| 65 |
+
vlen = len(video_reader)
|
| 66 |
+
fps = video_reader.get_avg_fps()
|
| 67 |
+
duration = vlen / float(fps)
|
| 68 |
+
if clip:
|
| 69 |
+
start, end = clip
|
| 70 |
+
duration = end - start
|
| 71 |
+
vlen = int(duration * fps)
|
| 72 |
+
start_index = int(start * fps)
|
| 73 |
+
|
| 74 |
+
t_num_frames = np.random.randint(min_num_frames, num_frames + 1)
|
| 75 |
+
|
| 76 |
+
frame_indices = get_frame_indices(
|
| 77 |
+
t_num_frames, vlen, sample=sample, fix_start=fix_start,
|
| 78 |
+
input_fps=fps
|
| 79 |
+
)
|
| 80 |
+
if clip:
|
| 81 |
+
frame_indices = [f + start_index for f in frame_indices]
|
| 82 |
+
frames = video_reader.get_batch(frame_indices).asnumpy() # (T, H, W, C), np.uint8
|
| 83 |
+
frames = [Image.fromarray(frames[i]) for i in range(frames.shape[0])]
|
| 84 |
+
return frames
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
def extract_frame_number(filename):
|
| 88 |
+
# Extract the numeric part from the filename using regular expressions
|
| 89 |
+
match = re.search(r'_(\d+).jpg$', filename)
|
| 90 |
+
return int(match.group(1)) if match else -1
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def sort_frames(frame_paths):
|
| 94 |
+
# Extract filenames from each path and sort by their numeric part
|
| 95 |
+
return sorted(frame_paths, key=lambda x: extract_frame_number(os.path.basename(x)))
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
def read_frames_folder(video_path, num_frames, sample='rand', fix_start=None, min_num_frames=4):
|
| 99 |
+
image_list = sort_frames(list(os.listdir(video_path)))
|
| 100 |
+
frames = []
|
| 101 |
+
for image in image_list:
|
| 102 |
+
fp = os.path.join(video_path, image)
|
| 103 |
+
frame = Image.open(fp).convert('RGB')
|
| 104 |
+
frames.append(frame)
|
| 105 |
+
vlen = len(frames)
|
| 106 |
+
|
| 107 |
+
t_num_frames = np.random.randint(min_num_frames, num_frames + 1)
|
| 108 |
+
|
| 109 |
+
if vlen > t_num_frames:
|
| 110 |
+
frame_indices = get_frame_indices(
|
| 111 |
+
t_num_frames, vlen, sample=sample, fix_start=fix_start
|
| 112 |
+
)
|
| 113 |
+
frames = [frames[i] for i in frame_indices]
|
| 114 |
+
return frames
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
class FrameSampler:
|
| 118 |
+
def __init__(self, max_num_frames=-1, min_num_frames=8, sample='rand'):
|
| 119 |
+
self.max_num_frames = max_num_frames
|
| 120 |
+
self.min_num_frames = min_num_frames
|
| 121 |
+
self.sample = sample
|
| 122 |
+
|
| 123 |
+
def __call__(self, file_name):
|
| 124 |
+
fn = read_frames_folder if file_name.endswith('/') else read_frames_decord
|
| 125 |
+
frames = fn(file_name, num_frames=self.max_num_frames, min_num_frames=self.min_num_frames, sample=self.sample)
|
| 126 |
+
return frames
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
def decode_video_byte(video_bytes):
|
| 130 |
+
video_stream = io.BytesIO(video_bytes)
|
| 131 |
+
vr = decord.VideoReader(video_stream)
|
| 132 |
+
return vr
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
def sample_mp4_frames(mp4_p, n_frames=None, fps=None, return_frame_indices=False, random_sample=False):
|
| 136 |
+
if isinstance(mp4_p, str):
|
| 137 |
+
vr = decord.VideoReader(mp4_p, num_threads=1)
|
| 138 |
+
elif isinstance(mp4_p, decord.video_reader.VideoReader):
|
| 139 |
+
vr = mp4_p
|
| 140 |
+
video_fps = vr.get_avg_fps() # 获取视频的帧率
|
| 141 |
+
video_duration = len(vr) / video_fps
|
| 142 |
+
if n_frames is not None:
|
| 143 |
+
if random_sample:
|
| 144 |
+
frame_indices = sorted(random.sample(range(len(vr)), n_frames))
|
| 145 |
+
else:
|
| 146 |
+
frame_indices = np.linspace(0, len(vr)-1, n_frames, dtype=int).tolist()
|
| 147 |
+
else:
|
| 148 |
+
frame_indices = [int(i) for i in np.arange(0, len(vr)-1, video_fps/fps)]
|
| 149 |
+
frames = vr.get_batch(frame_indices).asnumpy() # 转换为 numpy 数组
|
| 150 |
+
frames = [Image.fromarray(frame).convert("RGB") for frame in frames]
|
| 151 |
+
if not return_frame_indices:
|
| 152 |
+
return frames, video_duration
|
| 153 |
+
else:
|
| 154 |
+
return frames, video_duration, frame_indices
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
def sample_mp4_frames_by_indices(mp4_p, frame_indices: list):
|
| 158 |
+
if isinstance(mp4_p, str):
|
| 159 |
+
vr = decord.VideoReader(mp4_p, num_threads=1)
|
| 160 |
+
elif isinstance(mp4_p, decord.video_reader.VideoReader):
|
| 161 |
+
vr = mp4_p
|
| 162 |
+
# sample the frames in frame_indices
|
| 163 |
+
frames = vr.get_batch(frame_indices).asnumpy() # 转换为 numpy 数组
|
| 164 |
+
frames = [Image.fromarray(frame).convert("RGB") for frame in frames]
|
| 165 |
+
return frames
|
data/vlm_dataset.py
ADDED
|
@@ -0,0 +1,195 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2025 Bytedance Ltd. and/or its affiliates.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 3 |
+
|
| 4 |
+
import json
|
| 5 |
+
import os
|
| 6 |
+
import traceback
|
| 7 |
+
from PIL import Image, ImageFile, PngImagePlugin
|
| 8 |
+
|
| 9 |
+
from .data_utils import pil_img2rgb
|
| 10 |
+
from .distributed_iterable_dataset import DistributedIterableDataset
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
Image.MAX_IMAGE_PIXELS = 200000000
|
| 14 |
+
ImageFile.LOAD_TRUNCATED_IMAGES = True
|
| 15 |
+
MaximumDecompressedSize = 1024
|
| 16 |
+
MegaByte = 2 ** 20
|
| 17 |
+
PngImagePlugin.MAX_TEXT_CHUNK = MaximumDecompressedSize * MegaByte
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class SftJSONLIterableDataset(DistributedIterableDataset):
|
| 21 |
+
def __init__(
|
| 22 |
+
self, dataset_name, transform, tokenizer, frame_sampler,
|
| 23 |
+
jsonl_path_list, data_dir_list, num_used_data,
|
| 24 |
+
local_rank=0, world_size=1, num_workers=8, data_status=None,
|
| 25 |
+
shuffle_lines=False, shuffle_seed=0,
|
| 26 |
+
):
|
| 27 |
+
"""
|
| 28 |
+
jsonl_path_list: list of jsonl file paths
|
| 29 |
+
data_dir_list: list of image directories containing the images of each jsonl file
|
| 30 |
+
num_used_data: list of number of sampled data points for each jsonl
|
| 31 |
+
"""
|
| 32 |
+
super().__init__(dataset_name, local_rank, world_size, num_workers)
|
| 33 |
+
self.transform = transform
|
| 34 |
+
self.tokenizer = tokenizer
|
| 35 |
+
self.frame_sampler = frame_sampler
|
| 36 |
+
self.data_status = data_status
|
| 37 |
+
self.data_paths = self.get_data_paths(
|
| 38 |
+
jsonl_path_list,
|
| 39 |
+
data_dir_list,
|
| 40 |
+
num_used_data,
|
| 41 |
+
shuffle_lines,
|
| 42 |
+
shuffle_seed,
|
| 43 |
+
)
|
| 44 |
+
self.set_epoch()
|
| 45 |
+
|
| 46 |
+
def get_data_paths(
|
| 47 |
+
self,
|
| 48 |
+
jsonl_path_list,
|
| 49 |
+
data_dir_list,
|
| 50 |
+
num_used_data,
|
| 51 |
+
shuffle_lines,
|
| 52 |
+
shuffle_seed,
|
| 53 |
+
):
|
| 54 |
+
data_paths = []
|
| 55 |
+
for jsonl_path, image_dir, num_data_point in zip(
|
| 56 |
+
jsonl_path_list, data_dir_list, num_used_data
|
| 57 |
+
):
|
| 58 |
+
with open(jsonl_path, 'r') as f:
|
| 59 |
+
raw_data = f.readlines()
|
| 60 |
+
if shuffle_lines:
|
| 61 |
+
self.rng.seed(shuffle_seed)
|
| 62 |
+
self.rng.shuffle(raw_data)
|
| 63 |
+
raw_data = raw_data[:num_data_point]
|
| 64 |
+
data_paths.extend([(json_data, image_dir) for json_data in raw_data])
|
| 65 |
+
return data_paths
|
| 66 |
+
|
| 67 |
+
def change_format(self, data, num_images):
|
| 68 |
+
elements = []
|
| 69 |
+
for conversation in data['conversations']:
|
| 70 |
+
if conversation['from'] == 'human':
|
| 71 |
+
if '<image>' not in conversation['value']:
|
| 72 |
+
elements.append({
|
| 73 |
+
'type': 'text',
|
| 74 |
+
'has_loss': 0,
|
| 75 |
+
'text': conversation['value'],
|
| 76 |
+
})
|
| 77 |
+
else:
|
| 78 |
+
text_list = conversation['value'].split('<image>')
|
| 79 |
+
for idx, text in enumerate(text_list):
|
| 80 |
+
if text.strip() != '':
|
| 81 |
+
elements.append({
|
| 82 |
+
'type': 'text',
|
| 83 |
+
'has_loss': 0,
|
| 84 |
+
'text': text.strip(),
|
| 85 |
+
})
|
| 86 |
+
if (idx != len(text_list) - 1) and (idx < num_images):
|
| 87 |
+
elements.append({'type': 'image',})
|
| 88 |
+
elif conversation['from'] == 'gpt':
|
| 89 |
+
elements.append({
|
| 90 |
+
'type': 'text',
|
| 91 |
+
'has_loss': 1,
|
| 92 |
+
'text': conversation['value'],
|
| 93 |
+
})
|
| 94 |
+
return elements
|
| 95 |
+
|
| 96 |
+
def __iter__(self):
|
| 97 |
+
data_paths_per_worker, worker_id = self.get_data_paths_per_worker()
|
| 98 |
+
if self.data_status is not None:
|
| 99 |
+
row_start_id = self.data_status[worker_id] + 1
|
| 100 |
+
else:
|
| 101 |
+
row_start_id = 0
|
| 102 |
+
transform_stride = self.transform.stride
|
| 103 |
+
|
| 104 |
+
print(
|
| 105 |
+
f"rank-{self.local_rank} worker-{worker_id} dataset-{self.dataset_name}: "
|
| 106 |
+
f"resuming data at row#{row_start_id}"
|
| 107 |
+
)
|
| 108 |
+
|
| 109 |
+
while True:
|
| 110 |
+
data_paths_per_worker_ = data_paths_per_worker[row_start_id:]
|
| 111 |
+
for row_idx, (data, image_dir) in enumerate(data_paths_per_worker_, start=row_start_id):
|
| 112 |
+
num_tokens = 0
|
| 113 |
+
image_tensor_list = []
|
| 114 |
+
text_ids_list = []
|
| 115 |
+
sequence_plan = []
|
| 116 |
+
|
| 117 |
+
try:
|
| 118 |
+
data_item = json.loads(data)
|
| 119 |
+
raw_images = None
|
| 120 |
+
if 'image' in data_item:
|
| 121 |
+
if type(data_item['image']) == list:
|
| 122 |
+
raw_images = [
|
| 123 |
+
pil_img2rgb(Image.open(os.path.join(image_dir, image)))
|
| 124 |
+
for image in data_item['image']
|
| 125 |
+
]
|
| 126 |
+
else:
|
| 127 |
+
raw_images = [
|
| 128 |
+
pil_img2rgb(Image.open(os.path.join(image_dir, data_item['image'])))
|
| 129 |
+
]
|
| 130 |
+
elif 'video' in data_item:
|
| 131 |
+
raw_images = self.frame_sampler(os.path.join(image_dir, data_item['video']))
|
| 132 |
+
special_tokens = '<image>' * len(raw_images)
|
| 133 |
+
for item in data_item['conversations']:
|
| 134 |
+
if '<video>' in item['value']:
|
| 135 |
+
item['value'] = item['value'].replace('<video>', special_tokens)
|
| 136 |
+
break
|
| 137 |
+
else:
|
| 138 |
+
raise ValueError("Cannot find <video> in the conversation!")
|
| 139 |
+
except:
|
| 140 |
+
traceback.print_exc()
|
| 141 |
+
continue
|
| 142 |
+
|
| 143 |
+
if raw_images:
|
| 144 |
+
for raw_image in raw_images:
|
| 145 |
+
image_tensor = self.transform(raw_image, img_num=len(raw_images))
|
| 146 |
+
image_tensor_list.append(image_tensor)
|
| 147 |
+
height, width = image_tensor.shape[1:]
|
| 148 |
+
num_tokens += width * height // transform_stride ** 2
|
| 149 |
+
|
| 150 |
+
elements = self.change_format(data_item, len(image_tensor_list))
|
| 151 |
+
|
| 152 |
+
for item in elements:
|
| 153 |
+
if item['type'] == 'text':
|
| 154 |
+
text_data = item['text']
|
| 155 |
+
text_ids = self.tokenizer.encode(text_data)
|
| 156 |
+
if len(text_ids) > 0:
|
| 157 |
+
text_ids_list.append(text_ids)
|
| 158 |
+
num_tokens += len(text_ids)
|
| 159 |
+
current_plan = {
|
| 160 |
+
'type': 'text',
|
| 161 |
+
'enable_cfg': 0,
|
| 162 |
+
'loss': item['has_loss'],
|
| 163 |
+
'special_token_loss': 0,
|
| 164 |
+
'special_token_label': None,
|
| 165 |
+
}
|
| 166 |
+
sequence_plan.append(current_plan)
|
| 167 |
+
elif item['type'] == 'image':
|
| 168 |
+
current_plan = {
|
| 169 |
+
'type': 'vit_image',
|
| 170 |
+
'enable_cfg': 0,
|
| 171 |
+
'loss': 0,
|
| 172 |
+
'special_token_loss': 0,
|
| 173 |
+
'special_token_label': None,
|
| 174 |
+
}
|
| 175 |
+
sequence_plan.append(current_plan)
|
| 176 |
+
|
| 177 |
+
has_loss = [item['loss'] for item in sequence_plan]
|
| 178 |
+
if sum(has_loss) == 0:
|
| 179 |
+
print(f'No loss defined, skipped.')
|
| 180 |
+
continue
|
| 181 |
+
|
| 182 |
+
yield dict(
|
| 183 |
+
image_tensor_list=image_tensor_list,
|
| 184 |
+
text_ids_list=text_ids_list,
|
| 185 |
+
sequence_plan=sequence_plan,
|
| 186 |
+
num_tokens=num_tokens,
|
| 187 |
+
data_indexes={
|
| 188 |
+
"data_indexes": row_idx,
|
| 189 |
+
"worker_id": worker_id,
|
| 190 |
+
"dataset_name": self.dataset_name,
|
| 191 |
+
}
|
| 192 |
+
)
|
| 193 |
+
|
| 194 |
+
row_start_id = 0
|
| 195 |
+
print(f"{self.dataset_name} repeat in rank-{self.local_rank} worker-{worker_id}")
|
eval/__init__.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2025 Bytedance Ltd. and/or its affiliates.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2.0
|
eval/gen/gen_images_mp.py
ADDED
|
@@ -0,0 +1,238 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2025 Bytedance Ltd. and/or its affiliates.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 3 |
+
|
| 4 |
+
import os
|
| 5 |
+
import json
|
| 6 |
+
import argparse
|
| 7 |
+
from safetensors.torch import load_file
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
import torch.distributed as dist
|
| 11 |
+
from data.data_utils import add_special_tokens
|
| 12 |
+
from modeling.bagel import (
|
| 13 |
+
BagelConfig, Bagel, Qwen2Config, Qwen2ForCausalLM, SiglipVisionConfig, SiglipVisionModel
|
| 14 |
+
)
|
| 15 |
+
from modeling.qwen2 import Qwen2Tokenizer
|
| 16 |
+
from modeling.autoencoder import load_ae
|
| 17 |
+
|
| 18 |
+
from PIL import Image
|
| 19 |
+
from modeling.bagel.qwen2_navit import NaiveCache
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def move_generation_input_to_device(generation_input, device):
|
| 23 |
+
# Utility to move all tensors in generation_input to device
|
| 24 |
+
for k, v in generation_input.items():
|
| 25 |
+
if isinstance(v, torch.Tensor):
|
| 26 |
+
generation_input[k] = v.to(device)
|
| 27 |
+
return generation_input
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def setup_distributed():
|
| 31 |
+
dist.init_process_group(backend="nccl")
|
| 32 |
+
torch.cuda.set_device(int(os.environ["LOCAL_RANK"]))
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def generate_image(prompt, num_timesteps=50, cfg_scale=10.0, cfg_interval=[0, 1.0], cfg_renorm_min=0., timestep_shift=1.0, num_images=4, resolution=512, device=None): # 添加device参数
|
| 36 |
+
past_key_values = NaiveCache(gen_model.config.llm_config.num_hidden_layers)
|
| 37 |
+
newlens = [0] * num_images
|
| 38 |
+
new_rope = [0] * num_images
|
| 39 |
+
|
| 40 |
+
generation_input, newlens, new_rope = gen_model.prepare_prompts(
|
| 41 |
+
curr_kvlens=newlens,
|
| 42 |
+
curr_rope=new_rope,
|
| 43 |
+
prompts=[prompt] * num_images,
|
| 44 |
+
tokenizer=tokenizer,
|
| 45 |
+
new_token_ids=new_token_ids,
|
| 46 |
+
)
|
| 47 |
+
generation_input = move_generation_input_to_device(generation_input, device)
|
| 48 |
+
|
| 49 |
+
with torch.no_grad():
|
| 50 |
+
with torch.amp.autocast("cuda", enabled=True, dtype=torch.float16):
|
| 51 |
+
past_key_values = gen_model.forward_cache_update_text(past_key_values, **generation_input)
|
| 52 |
+
|
| 53 |
+
generation_input = gen_model.prepare_vae_latent(
|
| 54 |
+
curr_kvlens=newlens,
|
| 55 |
+
curr_rope=new_rope,
|
| 56 |
+
image_sizes=[(resolution, resolution)] * num_images,
|
| 57 |
+
new_token_ids=new_token_ids,
|
| 58 |
+
)
|
| 59 |
+
generation_input = move_generation_input_to_device(generation_input, device)
|
| 60 |
+
|
| 61 |
+
cfg_past_key_values = NaiveCache(gen_model.config.llm_config.num_hidden_layers)
|
| 62 |
+
cfg_newlens = [0] * num_images
|
| 63 |
+
cfg_new_rope = [0] * num_images
|
| 64 |
+
|
| 65 |
+
generation_input_cfg = model.prepare_vae_latent_cfg(
|
| 66 |
+
curr_kvlens=cfg_newlens,
|
| 67 |
+
curr_rope=cfg_new_rope,
|
| 68 |
+
image_sizes=[(resolution, resolution)] * num_images,
|
| 69 |
+
)
|
| 70 |
+
generation_input_cfg = move_generation_input_to_device(generation_input_cfg, device)
|
| 71 |
+
|
| 72 |
+
with torch.no_grad():
|
| 73 |
+
with torch.amp.autocast("cuda", enabled=True, dtype=torch.bfloat16):
|
| 74 |
+
unpacked_latent = gen_model.generate_image(
|
| 75 |
+
past_key_values=past_key_values,
|
| 76 |
+
num_timesteps=num_timesteps,
|
| 77 |
+
cfg_text_scale=cfg_scale,
|
| 78 |
+
cfg_interval=cfg_interval,
|
| 79 |
+
cfg_renorm_min=cfg_renorm_min,
|
| 80 |
+
timestep_shift=timestep_shift,
|
| 81 |
+
cfg_text_past_key_values=cfg_past_key_values,
|
| 82 |
+
cfg_text_packed_position_ids=generation_input_cfg["cfg_packed_position_ids"],
|
| 83 |
+
cfg_text_key_values_lens=generation_input_cfg["cfg_key_values_lens"],
|
| 84 |
+
cfg_text_packed_query_indexes=generation_input_cfg["cfg_packed_query_indexes"],
|
| 85 |
+
cfg_text_packed_key_value_indexes=generation_input_cfg["cfg_packed_key_value_indexes"],
|
| 86 |
+
**generation_input,
|
| 87 |
+
)
|
| 88 |
+
|
| 89 |
+
image_list = []
|
| 90 |
+
for latent in unpacked_latent:
|
| 91 |
+
latent = latent.reshape(1, resolution//16, resolution//16, 2, 2, 16)
|
| 92 |
+
latent = torch.einsum("nhwpqc->nchpwq", latent)
|
| 93 |
+
latent = latent.reshape(1, 16, resolution//8, resolution//8)
|
| 94 |
+
image = vae_model.decode(latent.to(device))
|
| 95 |
+
tmpimage = ((image * 0.5 + 0.5).clamp(0, 1)[0].permute(1, 2, 0) * 255).to(torch.uint8).cpu().numpy()
|
| 96 |
+
tmpimage = Image.fromarray(tmpimage)
|
| 97 |
+
image_list.append(tmpimage)
|
| 98 |
+
|
| 99 |
+
return image_list
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
if __name__ == "__main__":
|
| 103 |
+
parser = argparse.ArgumentParser(description="Generate images using Bagel model.")
|
| 104 |
+
parser.add_argument("--output_dir", type=str, required=True, help="Directory to save the generated images.")
|
| 105 |
+
parser.add_argument("--metadata_file", type=str, required=True, help="JSONL file containing lines of metadata for each prompt.")
|
| 106 |
+
parser.add_argument("--num_images", type=int, default=4)
|
| 107 |
+
parser.add_argument("--batch_size", type=int, default=4)
|
| 108 |
+
parser.add_argument("--cfg_scale", type=float, default=4)
|
| 109 |
+
parser.add_argument("--resolution", type=int, default=1024)
|
| 110 |
+
parser.add_argument("--max_latent_size", type=int, default=64)
|
| 111 |
+
parser.add_argument('--model-path', type=str, default='hf/BAGEL-7B-MoT/')
|
| 112 |
+
args = parser.parse_args()
|
| 113 |
+
|
| 114 |
+
seed = 42
|
| 115 |
+
if seed is not None:
|
| 116 |
+
import random
|
| 117 |
+
import numpy as np
|
| 118 |
+
random.seed(seed)
|
| 119 |
+
np.random.seed(seed)
|
| 120 |
+
torch.manual_seed(seed)
|
| 121 |
+
if torch.cuda.is_available():
|
| 122 |
+
torch.cuda.manual_seed(seed)
|
| 123 |
+
torch.cuda.manual_seed_all(seed)
|
| 124 |
+
torch.backends.cudnn.deterministic = True
|
| 125 |
+
torch.backends.cudnn.benchmark = False
|
| 126 |
+
|
| 127 |
+
setup_distributed()
|
| 128 |
+
rank = dist.get_rank()
|
| 129 |
+
world_size = dist.get_world_size()
|
| 130 |
+
device = f"cuda:{rank}"
|
| 131 |
+
|
| 132 |
+
output_dir = args.output_dir
|
| 133 |
+
os.makedirs(output_dir, exist_ok=True)
|
| 134 |
+
if rank == 0:
|
| 135 |
+
print(f"Output images are saved in {output_dir}")
|
| 136 |
+
|
| 137 |
+
llm_config = Qwen2Config.from_json_file(os.path.join(args.model_path, "llm_config.json"))
|
| 138 |
+
llm_config.qk_norm = True
|
| 139 |
+
llm_config.tie_word_embeddings = False
|
| 140 |
+
llm_config.layer_module = "Qwen2MoTDecoderLayer"
|
| 141 |
+
|
| 142 |
+
vit_config = SiglipVisionConfig.from_json_file(os.path.join(args.model_path, "vit_config.json"))
|
| 143 |
+
vit_config.rope = False
|
| 144 |
+
vit_config.num_hidden_layers = vit_config.num_hidden_layers - 1
|
| 145 |
+
|
| 146 |
+
vae_model, vae_config = load_ae(local_path=os.path.join(args.model_path, "ae.safetensors"))
|
| 147 |
+
|
| 148 |
+
config = BagelConfig(
|
| 149 |
+
visual_gen=True,
|
| 150 |
+
visual_und=True,
|
| 151 |
+
llm_config=llm_config,
|
| 152 |
+
vit_config=vit_config,
|
| 153 |
+
vae_config=vae_config,
|
| 154 |
+
vit_max_num_patch_per_side=70,
|
| 155 |
+
connector_act='gelu_pytorch_tanh',
|
| 156 |
+
latent_patch_size=2,
|
| 157 |
+
max_latent_size=args.max_latent_size,
|
| 158 |
+
)
|
| 159 |
+
language_model = Qwen2ForCausalLM(llm_config)
|
| 160 |
+
vit_model = SiglipVisionModel(vit_config)
|
| 161 |
+
model = Bagel(language_model, vit_model, config)
|
| 162 |
+
model.vit_model.vision_model.embeddings.convert_conv2d_to_linear(vit_config)
|
| 163 |
+
|
| 164 |
+
tokenizer = Qwen2Tokenizer.from_pretrained(args.model_path)
|
| 165 |
+
tokenizer, new_token_ids, _ = add_special_tokens(tokenizer)
|
| 166 |
+
|
| 167 |
+
model_state_dict_path = os.path.join(args.model_path, "ema.safetensors")
|
| 168 |
+
model_state_dict = load_file(model_state_dict_path, device="cpu")
|
| 169 |
+
msg = model.load_state_dict(model_state_dict, strict=False)
|
| 170 |
+
if rank == 0:
|
| 171 |
+
print(msg)
|
| 172 |
+
del model_state_dict
|
| 173 |
+
|
| 174 |
+
model = model.to(device).eval()
|
| 175 |
+
vae_model = vae_model.to(device).eval()
|
| 176 |
+
gen_model = model
|
| 177 |
+
|
| 178 |
+
cfg_scale = args.cfg_scale
|
| 179 |
+
cfg_interval = [0, 1.0]
|
| 180 |
+
timestep_shift = 3.0
|
| 181 |
+
num_timesteps = 50
|
| 182 |
+
cfg_renorm_min = 0.0
|
| 183 |
+
|
| 184 |
+
with open(args.metadata_file, "r", encoding="utf-8") as fp:
|
| 185 |
+
metadatas = [json.loads(line) for line in fp]
|
| 186 |
+
total_metadatas = len(metadatas)
|
| 187 |
+
|
| 188 |
+
prompts_per_gpu = (total_metadatas + world_size - 1) // world_size
|
| 189 |
+
start = rank * prompts_per_gpu
|
| 190 |
+
end = min(start + prompts_per_gpu, total_metadatas)
|
| 191 |
+
print(f"GPU {rank}: Processing {end - start} prompts (indices {start} to {end - 1})")
|
| 192 |
+
|
| 193 |
+
for idx in range(start, end):
|
| 194 |
+
metadata = metadatas[idx]
|
| 195 |
+
outpath = os.path.join(output_dir, f"{idx:0>5}")
|
| 196 |
+
os.makedirs(outpath, exist_ok=True)
|
| 197 |
+
prompt = metadata['prompt']
|
| 198 |
+
print(f"GPU {rank} processing prompt {idx - start + 1}/{end - start}: '{prompt}'")
|
| 199 |
+
|
| 200 |
+
sample_path = os.path.join(outpath, "samples")
|
| 201 |
+
os.makedirs(sample_path, exist_ok=True)
|
| 202 |
+
|
| 203 |
+
flag = True
|
| 204 |
+
for idx in range(args.num_images):
|
| 205 |
+
if not os.path.exists(os.path.join(sample_path, f"{idx:05}.png")):
|
| 206 |
+
flag = False
|
| 207 |
+
break
|
| 208 |
+
if flag:
|
| 209 |
+
print(f"GPU {rank} skipping generation for prompt: {prompt}")
|
| 210 |
+
continue
|
| 211 |
+
|
| 212 |
+
with open(os.path.join(outpath, "metadata.jsonl"), "w", encoding="utf-8") as fp:
|
| 213 |
+
json.dump(metadata, fp)
|
| 214 |
+
|
| 215 |
+
image_list = []
|
| 216 |
+
|
| 217 |
+
for i in range(args.num_images // args.batch_size):
|
| 218 |
+
tmp_image_list = generate_image(
|
| 219 |
+
prompt=prompt,
|
| 220 |
+
cfg_scale=cfg_scale,
|
| 221 |
+
cfg_interval=cfg_interval,
|
| 222 |
+
cfg_renorm_min=cfg_renorm_min,
|
| 223 |
+
timestep_shift=timestep_shift,
|
| 224 |
+
num_timesteps=num_timesteps,
|
| 225 |
+
num_images=args.batch_size,
|
| 226 |
+
resolution=args.resolution,
|
| 227 |
+
device=device,
|
| 228 |
+
)
|
| 229 |
+
image_list.extend(tmp_image_list)
|
| 230 |
+
|
| 231 |
+
sample_count = 0
|
| 232 |
+
for sample in image_list:
|
| 233 |
+
sample = sample.crop(sample.getbbox())
|
| 234 |
+
sample.save(os.path.join(sample_path, f"{sample_count:05}.png"))
|
| 235 |
+
sample_count += 1
|
| 236 |
+
|
| 237 |
+
print(f"GPU {rank} has completed all tasks")
|
| 238 |
+
dist.barrier()
|
eval/gen/gen_images_mp_wise.py
ADDED
|
@@ -0,0 +1,365 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2025 Bytedance Ltd. and/or its affiliates.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 3 |
+
|
| 4 |
+
import os
|
| 5 |
+
import json
|
| 6 |
+
import argparse
|
| 7 |
+
from safetensors.torch import load_file
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
import torch.distributed as dist
|
| 11 |
+
from data.data_utils import add_special_tokens
|
| 12 |
+
from modeling.bagel import (
|
| 13 |
+
BagelConfig, Bagel, Qwen2Config, Qwen2ForCausalLM, SiglipVisionConfig, SiglipVisionModel
|
| 14 |
+
)
|
| 15 |
+
from modeling.qwen2 import Qwen2Tokenizer
|
| 16 |
+
from modeling.autoencoder import load_ae
|
| 17 |
+
|
| 18 |
+
import copy
|
| 19 |
+
from PIL import Image
|
| 20 |
+
from modeling.bagel.qwen2_navit import NaiveCache
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def setup_distributed():
|
| 24 |
+
dist.init_process_group(backend="nccl")
|
| 25 |
+
torch.cuda.set_device(int(os.environ["LOCAL_RANK"]))
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
SYSTEM_PROMPT = '''You should first think about the planning process in the mind and then generate the image.
|
| 29 |
+
The planning process is enclosed within <think> </think> tags, i.e. <think> planning process here </think> image here'''
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def move_generation_input_to_device(generation_input, device):
|
| 33 |
+
# Utility to move all tensors in generation_input to device
|
| 34 |
+
for k, v in generation_input.items():
|
| 35 |
+
if isinstance(v, torch.Tensor):
|
| 36 |
+
generation_input[k] = v.to(device)
|
| 37 |
+
return generation_input
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def generate_image_with_think(
|
| 41 |
+
prompt, num_timesteps=50, cfg_scale=4.0, cfg_interval=[0, 1.0], cfg_renorm_min=0., timestep_shift=4.0, resolution=1024,
|
| 42 |
+
max_length=2048, simple_think=False, device=None
|
| 43 |
+
):
|
| 44 |
+
h, w = resolution, resolution
|
| 45 |
+
|
| 46 |
+
past_key_values = NaiveCache(model.config.llm_config.num_hidden_layers)
|
| 47 |
+
newlens = [0]
|
| 48 |
+
new_rope = [0]
|
| 49 |
+
|
| 50 |
+
# system prompt
|
| 51 |
+
generation_input, newlens, new_rope = model.prepare_prompts(
|
| 52 |
+
curr_kvlens=newlens,
|
| 53 |
+
curr_rope=new_rope,
|
| 54 |
+
prompts=[SYSTEM_PROMPT],
|
| 55 |
+
tokenizer=tokenizer,
|
| 56 |
+
new_token_ids=new_token_ids,
|
| 57 |
+
)
|
| 58 |
+
generation_input = move_generation_input_to_device(generation_input, device)
|
| 59 |
+
with torch.amp.autocast("cuda", enabled=True, dtype=torch.bfloat16):
|
| 60 |
+
past_key_values = model.forward_cache_update_text(past_key_values, **generation_input)
|
| 61 |
+
|
| 62 |
+
########## cfg
|
| 63 |
+
generation_input_cfg = model.prepare_vae_latent_cfg(
|
| 64 |
+
curr_kvlens=newlens,
|
| 65 |
+
curr_rope=new_rope,
|
| 66 |
+
image_sizes=[(h, w)],
|
| 67 |
+
)
|
| 68 |
+
generation_input_cfg = move_generation_input_to_device(generation_input_cfg, device)
|
| 69 |
+
########## cfg
|
| 70 |
+
|
| 71 |
+
generation_input, newlens, new_rope = model.prepare_prompts(
|
| 72 |
+
curr_kvlens=newlens,
|
| 73 |
+
curr_rope=new_rope,
|
| 74 |
+
prompts=[prompt],
|
| 75 |
+
tokenizer=tokenizer,
|
| 76 |
+
new_token_ids=new_token_ids,
|
| 77 |
+
)
|
| 78 |
+
generation_input = move_generation_input_to_device(generation_input, device)
|
| 79 |
+
with torch.amp.autocast("cuda", enabled=True, dtype=torch.bfloat16):
|
| 80 |
+
past_key_values = model.forward_cache_update_text(past_key_values, **generation_input)
|
| 81 |
+
|
| 82 |
+
########## think
|
| 83 |
+
tmp_past_key_values = copy.deepcopy(past_key_values)
|
| 84 |
+
tmp_newlens = copy.deepcopy(newlens)
|
| 85 |
+
tmp_new_rope = copy.deepcopy(new_rope)
|
| 86 |
+
tmp_generation_input, tmp_newlens, tmp_new_rope = model.prepare_prompts(
|
| 87 |
+
curr_kvlens=tmp_newlens,
|
| 88 |
+
curr_rope=tmp_new_rope,
|
| 89 |
+
prompts=[prompt],
|
| 90 |
+
tokenizer=tokenizer,
|
| 91 |
+
new_token_ids=new_token_ids,
|
| 92 |
+
)
|
| 93 |
+
tmp_generation_input = move_generation_input_to_device(tmp_generation_input, device)
|
| 94 |
+
with torch.amp.autocast("cuda", enabled=True, dtype=torch.bfloat16):
|
| 95 |
+
tmp_past_key_values = model.forward_cache_update_text(tmp_past_key_values, **tmp_generation_input)
|
| 96 |
+
|
| 97 |
+
tmp_generation_input = model.prepare_start_tokens(tmp_newlens, tmp_new_rope, new_token_ids)
|
| 98 |
+
tmp_generation_input = move_generation_input_to_device(tmp_generation_input, device)
|
| 99 |
+
with torch.amp.autocast("cuda", enabled=True, dtype=torch.bfloat16):
|
| 100 |
+
unpacked_latent = model.generate_text(
|
| 101 |
+
past_key_values=tmp_past_key_values,
|
| 102 |
+
max_length=max_length,
|
| 103 |
+
do_sample=True,
|
| 104 |
+
temperature=0.3,
|
| 105 |
+
end_token_id=new_token_ids['eos_token_id'],
|
| 106 |
+
**tmp_generation_input,
|
| 107 |
+
)
|
| 108 |
+
output = tokenizer.decode(unpacked_latent[:,0])
|
| 109 |
+
think_output = output.split('<|im_end|>')[0].split('<|im_start|>')[1]
|
| 110 |
+
|
| 111 |
+
print("="*30, "original think", "="*30)
|
| 112 |
+
print(think_output)
|
| 113 |
+
if simple_think:
|
| 114 |
+
think_output_list = think_output.split("</think>")
|
| 115 |
+
if think_output_list[1] != "":
|
| 116 |
+
think_output = think_output_list[1].strip()
|
| 117 |
+
print("="*30, "processed think", "="*30)
|
| 118 |
+
print(think_output)
|
| 119 |
+
########## think
|
| 120 |
+
|
| 121 |
+
generation_input, newlens, new_rope = model.prepare_prompts(
|
| 122 |
+
curr_kvlens=newlens,
|
| 123 |
+
curr_rope=new_rope,
|
| 124 |
+
prompts=[think_output],
|
| 125 |
+
tokenizer=tokenizer,
|
| 126 |
+
new_token_ids=new_token_ids,
|
| 127 |
+
)
|
| 128 |
+
generation_input = move_generation_input_to_device(generation_input, device)
|
| 129 |
+
with torch.amp.autocast("cuda", enabled=True, dtype=torch.bfloat16):
|
| 130 |
+
past_key_values = model.forward_cache_update_text(past_key_values, **generation_input)
|
| 131 |
+
|
| 132 |
+
generation_input = model.prepare_vae_latent(
|
| 133 |
+
curr_kvlens=newlens,
|
| 134 |
+
curr_rope=new_rope,
|
| 135 |
+
image_sizes=[(h, w)],
|
| 136 |
+
new_token_ids=new_token_ids,
|
| 137 |
+
)
|
| 138 |
+
generation_input = move_generation_input_to_device(generation_input, device)
|
| 139 |
+
|
| 140 |
+
########## generate image
|
| 141 |
+
with torch.amp.autocast("cuda", enabled=True, dtype=torch.bfloat16):
|
| 142 |
+
unpacked_latent = model.generate_image(
|
| 143 |
+
past_key_values=past_key_values,
|
| 144 |
+
num_timesteps=num_timesteps,
|
| 145 |
+
cfg_text_scale=cfg_scale,
|
| 146 |
+
cfg_interval=cfg_interval,
|
| 147 |
+
timestep_shift=timestep_shift,
|
| 148 |
+
cfg_renorm_min=cfg_renorm_min,
|
| 149 |
+
cfg_renorm_type="global",
|
| 150 |
+
cfg_text_past_key_values=None,
|
| 151 |
+
cfg_text_packed_position_ids=generation_input_cfg["cfg_packed_position_ids"],
|
| 152 |
+
cfg_text_key_values_lens=generation_input_cfg["cfg_key_values_lens"],
|
| 153 |
+
cfg_text_packed_query_indexes=generation_input_cfg["cfg_packed_query_indexes"],
|
| 154 |
+
cfg_text_packed_key_value_indexes=generation_input_cfg["cfg_packed_key_value_indexes"],
|
| 155 |
+
**generation_input,
|
| 156 |
+
)
|
| 157 |
+
|
| 158 |
+
latent0 = unpacked_latent[0]
|
| 159 |
+
latent0 = latent0.reshape(1, h//16, w//16, 2, 2, 16)
|
| 160 |
+
latent0 = torch.einsum("nhwpqc->nchpwq", latent0)
|
| 161 |
+
latent0 = latent0.reshape(1, 16, h//8, w//8)
|
| 162 |
+
image = vae_model.decode(latent0.to(device))
|
| 163 |
+
tmpimage = ((image * 0.5 + 0.5).clamp(0, 1)[0].permute(1, 2, 0) * 255).to(torch.uint8).cpu().numpy()
|
| 164 |
+
tmpimage = Image.fromarray(tmpimage)
|
| 165 |
+
|
| 166 |
+
return tmpimage, think_output
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
def generate_image(prompt, num_timesteps=50, cfg_scale=4.0, cfg_interval=[0, 1.0], cfg_renorm_min=0., timestep_shift=1.0, resolution=1024, device=None):
|
| 170 |
+
past_key_values = NaiveCache(gen_model.config.llm_config.num_hidden_layers)
|
| 171 |
+
newlens = [0]
|
| 172 |
+
new_rope = [0]
|
| 173 |
+
|
| 174 |
+
generation_input, newlens, new_rope = gen_model.prepare_prompts(
|
| 175 |
+
curr_kvlens=newlens,
|
| 176 |
+
curr_rope=new_rope,
|
| 177 |
+
prompts=[prompt],
|
| 178 |
+
tokenizer=tokenizer,
|
| 179 |
+
new_token_ids=new_token_ids,
|
| 180 |
+
)
|
| 181 |
+
generation_input = move_generation_input_to_device(generation_input, device)
|
| 182 |
+
|
| 183 |
+
with torch.no_grad():
|
| 184 |
+
with torch.amp.autocast("cuda", enabled=True, dtype=torch.float16):
|
| 185 |
+
past_key_values = gen_model.forward_cache_update_text(past_key_values, **generation_input)
|
| 186 |
+
|
| 187 |
+
generation_input = gen_model.prepare_vae_latent(
|
| 188 |
+
curr_kvlens=newlens,
|
| 189 |
+
curr_rope=new_rope,
|
| 190 |
+
image_sizes=[(resolution, resolution)],
|
| 191 |
+
new_token_ids=new_token_ids,
|
| 192 |
+
)
|
| 193 |
+
generation_input = move_generation_input_to_device(generation_input, device)
|
| 194 |
+
|
| 195 |
+
cfg_past_key_values = NaiveCache(gen_model.config.llm_config.num_hidden_layers)
|
| 196 |
+
cfg_newlens = [0]
|
| 197 |
+
cfg_new_rope = [0]
|
| 198 |
+
|
| 199 |
+
generation_input_cfg = model.prepare_vae_latent_cfg(
|
| 200 |
+
curr_kvlens=cfg_newlens,
|
| 201 |
+
curr_rope=cfg_new_rope,
|
| 202 |
+
image_sizes=[(resolution, resolution)],
|
| 203 |
+
)
|
| 204 |
+
generation_input_cfg = move_generation_input_to_device(generation_input_cfg, device)
|
| 205 |
+
with torch.no_grad():
|
| 206 |
+
with torch.amp.autocast("cuda", enabled=True, dtype=torch.bfloat16):
|
| 207 |
+
unpacked_latent = gen_model.generate_image(
|
| 208 |
+
past_key_values=past_key_values,
|
| 209 |
+
num_timesteps=num_timesteps,
|
| 210 |
+
cfg_text_scale=cfg_scale,
|
| 211 |
+
cfg_interval=cfg_interval,
|
| 212 |
+
cfg_renorm_min=cfg_renorm_min,
|
| 213 |
+
timestep_shift=timestep_shift,
|
| 214 |
+
cfg_text_past_key_values=cfg_past_key_values,
|
| 215 |
+
cfg_text_packed_position_ids=generation_input_cfg["cfg_packed_position_ids"],
|
| 216 |
+
cfg_text_key_values_lens=generation_input_cfg["cfg_key_values_lens"],
|
| 217 |
+
cfg_text_packed_query_indexes=generation_input_cfg["cfg_packed_query_indexes"],
|
| 218 |
+
cfg_text_packed_key_value_indexes=generation_input_cfg["cfg_packed_key_value_indexes"],
|
| 219 |
+
**generation_input,
|
| 220 |
+
)
|
| 221 |
+
|
| 222 |
+
latent = unpacked_latent[0]
|
| 223 |
+
latent = latent.reshape(1, resolution//16, resolution//16, 2, 2, 16)
|
| 224 |
+
latent = torch.einsum("nhwpqc->nchpwq", latent)
|
| 225 |
+
latent = latent.reshape(1, 16, resolution//8, resolution//8)
|
| 226 |
+
image = vae_model.decode(latent.to(device))
|
| 227 |
+
tmpimage = ((image * 0.5 + 0.5).clamp(0, 1)[0].permute(1, 2, 0) * 255).to(torch.uint8).cpu().numpy()
|
| 228 |
+
tmpimage = Image.fromarray(tmpimage)
|
| 229 |
+
|
| 230 |
+
return tmpimage
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
if __name__ == "__main__":
|
| 234 |
+
parser = argparse.ArgumentParser(description="Generate images using Bagel model.")
|
| 235 |
+
parser.add_argument("--output_dir", type=str, required=True, help="Directory to save the generated images.")
|
| 236 |
+
parser.add_argument("--metadata_file", type=str, required=True, help="JSON file containing lines of metadata for each prompt.")
|
| 237 |
+
parser.add_argument("--cfg_scale", type=float, default=4)
|
| 238 |
+
parser.add_argument("--resolution", type=int, default=1024)
|
| 239 |
+
parser.add_argument("--max_latent_size", type=int, default=64)
|
| 240 |
+
parser.add_argument("--think", action="store_true")
|
| 241 |
+
parser.add_argument('--model-path', type=str, default='hf/BAGEL-7B-MoT/')
|
| 242 |
+
args = parser.parse_args()
|
| 243 |
+
|
| 244 |
+
seed = 42
|
| 245 |
+
if seed is not None:
|
| 246 |
+
import random
|
| 247 |
+
import numpy as np
|
| 248 |
+
random.seed(seed)
|
| 249 |
+
np.random.seed(seed)
|
| 250 |
+
torch.manual_seed(seed)
|
| 251 |
+
if torch.cuda.is_available():
|
| 252 |
+
torch.cuda.manual_seed(seed)
|
| 253 |
+
torch.cuda.manual_seed_all(seed)
|
| 254 |
+
torch.backends.cudnn.deterministic = True
|
| 255 |
+
torch.backends.cudnn.benchmark = False
|
| 256 |
+
|
| 257 |
+
setup_distributed()
|
| 258 |
+
rank = dist.get_rank()
|
| 259 |
+
world_size = dist.get_world_size()
|
| 260 |
+
device = f"cuda:{rank}"
|
| 261 |
+
|
| 262 |
+
output_dir = args.output_dir
|
| 263 |
+
os.makedirs(output_dir, exist_ok=True)
|
| 264 |
+
if rank == 0:
|
| 265 |
+
print(f"Output images are saved in {output_dir}")
|
| 266 |
+
|
| 267 |
+
llm_config = Qwen2Config.from_json_file(os.path.join(args.model_path, "llm_config.json"))
|
| 268 |
+
llm_config.qk_norm = True
|
| 269 |
+
llm_config.tie_word_embeddings = False
|
| 270 |
+
llm_config.layer_module = "Qwen2MoTDecoderLayer"
|
| 271 |
+
|
| 272 |
+
vit_config = SiglipVisionConfig.from_json_file(os.path.join(args.model_path, "vit_config.json"))
|
| 273 |
+
vit_config.rope = False
|
| 274 |
+
vit_config.num_hidden_layers = vit_config.num_hidden_layers - 1
|
| 275 |
+
|
| 276 |
+
vae_model, vae_config = load_ae(local_path=os.path.join(args.model_path, "ae.safetensors"))
|
| 277 |
+
|
| 278 |
+
config = BagelConfig(
|
| 279 |
+
visual_gen=True,
|
| 280 |
+
visual_und=True,
|
| 281 |
+
llm_config=llm_config,
|
| 282 |
+
vit_config=vit_config,
|
| 283 |
+
vae_config=vae_config,
|
| 284 |
+
vit_max_num_patch_per_side=70,
|
| 285 |
+
connector_act='gelu_pytorch_tanh',
|
| 286 |
+
latent_patch_size=2,
|
| 287 |
+
max_latent_size=args.max_latent_size,
|
| 288 |
+
)
|
| 289 |
+
language_model = Qwen2ForCausalLM(llm_config)
|
| 290 |
+
vit_model = SiglipVisionModel(vit_config)
|
| 291 |
+
model = Bagel(language_model, vit_model, config)
|
| 292 |
+
model.vit_model.vision_model.embeddings.convert_conv2d_to_linear(vit_config)
|
| 293 |
+
|
| 294 |
+
tokenizer = Qwen2Tokenizer.from_pretrained(args.model_path)
|
| 295 |
+
tokenizer, new_token_ids, _ = add_special_tokens(tokenizer)
|
| 296 |
+
|
| 297 |
+
model_state_dict_path = os.path.join(args.model_path, "ema.safetensors")
|
| 298 |
+
model_state_dict = load_file(model_state_dict_path, device="cpu")
|
| 299 |
+
msg = model.load_state_dict(model_state_dict, strict=False)
|
| 300 |
+
if rank == 0:
|
| 301 |
+
print(msg)
|
| 302 |
+
|
| 303 |
+
del model_state_dict
|
| 304 |
+
model = model.to(device).eval()
|
| 305 |
+
vae_model = vae_model.to(device).eval()
|
| 306 |
+
gen_model = model
|
| 307 |
+
|
| 308 |
+
cfg_scale = args.cfg_scale
|
| 309 |
+
cfg_interval = [0.4, 1.0]
|
| 310 |
+
timestep_shift = 3.0
|
| 311 |
+
num_timesteps = 50
|
| 312 |
+
cfg_renorm_min = 0.0
|
| 313 |
+
|
| 314 |
+
with open(args.metadata_file, "r") as f:
|
| 315 |
+
metadatas = json.load(f)
|
| 316 |
+
total_metadatas = len(metadatas)
|
| 317 |
+
|
| 318 |
+
prompts_per_gpu = (total_metadatas + world_size - 1) // world_size
|
| 319 |
+
start = rank * prompts_per_gpu
|
| 320 |
+
end = min(start + prompts_per_gpu, total_metadatas)
|
| 321 |
+
print(f"GPU {rank}: Processing {end - start} prompts (indices {start} to {end - 1})")
|
| 322 |
+
|
| 323 |
+
for idx in range(start, end):
|
| 324 |
+
metadata = metadatas[idx]
|
| 325 |
+
prompt = metadata['Prompt']
|
| 326 |
+
prompt_id = metadata['prompt_id']
|
| 327 |
+
outpath = os.path.join(output_dir, f"{prompt_id}.png")
|
| 328 |
+
print(f"GPU {rank} processing prompt {idx - start + 1}/{end - start}: '{prompt}'")
|
| 329 |
+
|
| 330 |
+
if os.path.exists(outpath):
|
| 331 |
+
print(f"GPU {rank} skipping generation for prompt: {prompt}")
|
| 332 |
+
continue
|
| 333 |
+
|
| 334 |
+
if args.think:
|
| 335 |
+
tmpimage, think_output = generate_image_with_think(
|
| 336 |
+
prompt=prompt,
|
| 337 |
+
cfg_scale=cfg_scale,
|
| 338 |
+
cfg_interval=cfg_interval,
|
| 339 |
+
cfg_renorm_min=cfg_renorm_min,
|
| 340 |
+
timestep_shift=timestep_shift,
|
| 341 |
+
num_timesteps=num_timesteps,
|
| 342 |
+
resolution=args.resolution,
|
| 343 |
+
max_length=2048,
|
| 344 |
+
simple_think=False,
|
| 345 |
+
device=device,
|
| 346 |
+
)
|
| 347 |
+
with open(outpath.replace(".png", ".txt"), "w") as f:
|
| 348 |
+
f.write(think_output)
|
| 349 |
+
else:
|
| 350 |
+
tmpimage = generate_image(
|
| 351 |
+
prompt=prompt,
|
| 352 |
+
cfg_scale=cfg_scale,
|
| 353 |
+
cfg_interval=cfg_interval,
|
| 354 |
+
cfg_renorm_min=cfg_renorm_min,
|
| 355 |
+
timestep_shift=timestep_shift,
|
| 356 |
+
num_timesteps=num_timesteps,
|
| 357 |
+
resolution=args.resolution,
|
| 358 |
+
device=device,
|
| 359 |
+
)
|
| 360 |
+
|
| 361 |
+
tmpimage = tmpimage.crop(tmpimage.getbbox())
|
| 362 |
+
tmpimage.save(outpath)
|
| 363 |
+
|
| 364 |
+
print(f"GPU {rank} has completed all tasks")
|
| 365 |
+
dist.barrier()
|
eval/gen/geneval/evaluation/download_models.sh
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023 Dhruba Ghosh
|
| 2 |
+
# Copyright (c) 2025 Bytedance Ltd. and/or its affiliates.
|
| 3 |
+
# SPDX-License-Identifier: MIT
|
| 4 |
+
#
|
| 5 |
+
# This file has been modified by ByteDance Ltd. and/or its affiliates. on 2025-05-20.
|
| 6 |
+
#
|
| 7 |
+
# Original file was released under MIT, with the full license text
|
| 8 |
+
# available at https://github.com/djghosh13/geneval/blob/main/LICENSE.
|
| 9 |
+
#
|
| 10 |
+
# This modified file is released under the same license.
|
| 11 |
+
|
| 12 |
+
#!/bin/bash
|
| 13 |
+
|
| 14 |
+
# Download Mask2Former object detection config and weights
|
| 15 |
+
|
| 16 |
+
if [ ! -z "$1" ]
|
| 17 |
+
then
|
| 18 |
+
mkdir -p "$1"
|
| 19 |
+
wget https://download.openmmlab.com/mmdetection/v2.0/mask2former/mask2former_swin-s-p4-w7-224_lsj_8x2_50e_coco/mask2former_swin-s-p4-w7-224_lsj_8x2_50e_coco_20220504_001756-743b7d99.pth -O "$1/mask2former_swin-s-p4-w7-224_lsj_8x2_50e_coco.pth"
|
| 20 |
+
fi
|
eval/gen/geneval/evaluation/evaluate_images.py
ADDED
|
@@ -0,0 +1,304 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023 Dhruba Ghosh
|
| 2 |
+
# Copyright (c) 2025 Bytedance Ltd. and/or its affiliates.
|
| 3 |
+
# SPDX-License-Identifier: MIT
|
| 4 |
+
#
|
| 5 |
+
# This file has been modified by ByteDance Ltd. and/or its affiliates. on 2025-05-20.
|
| 6 |
+
#
|
| 7 |
+
# Original file was released under MIT, with the full license text
|
| 8 |
+
# available at https://github.com/djghosh13/geneval/blob/main/LICENSE.
|
| 9 |
+
#
|
| 10 |
+
# This modified file is released under the same license.
|
| 11 |
+
|
| 12 |
+
"""
|
| 13 |
+
Evaluate generated images using Mask2Former (or other object detector model)
|
| 14 |
+
"""
|
| 15 |
+
|
| 16 |
+
import argparse
|
| 17 |
+
import json
|
| 18 |
+
import os
|
| 19 |
+
import re
|
| 20 |
+
import sys
|
| 21 |
+
import time
|
| 22 |
+
from tqdm import tqdm
|
| 23 |
+
|
| 24 |
+
import warnings
|
| 25 |
+
warnings.filterwarnings("ignore")
|
| 26 |
+
|
| 27 |
+
import numpy as np
|
| 28 |
+
import pandas as pd
|
| 29 |
+
from PIL import Image, ImageOps
|
| 30 |
+
import torch
|
| 31 |
+
import mmdet
|
| 32 |
+
from mmdet.apis import inference_detector, init_detector
|
| 33 |
+
|
| 34 |
+
import open_clip
|
| 35 |
+
from clip_benchmark.metrics import zeroshot_classification as zsc
|
| 36 |
+
zsc.tqdm = lambda it, *args, **kwargs: it
|
| 37 |
+
|
| 38 |
+
# Get directory path
|
| 39 |
+
|
| 40 |
+
def parse_args():
|
| 41 |
+
parser = argparse.ArgumentParser()
|
| 42 |
+
parser.add_argument("imagedir", type=str)
|
| 43 |
+
parser.add_argument("--outfile", type=str, default="results.jsonl")
|
| 44 |
+
parser.add_argument("--model-config", type=str, default=None)
|
| 45 |
+
parser.add_argument("--model-path", type=str, default="./")
|
| 46 |
+
# Other arguments
|
| 47 |
+
parser.add_argument("--options", nargs="*", type=str, default=[])
|
| 48 |
+
args = parser.parse_args()
|
| 49 |
+
args.options = dict(opt.split("=", 1) for opt in args.options)
|
| 50 |
+
if args.model_config is None:
|
| 51 |
+
args.model_config = os.path.join(
|
| 52 |
+
os.path.dirname(mmdet.__file__),
|
| 53 |
+
"../configs/mask2former/mask2former_swin-s-p4-w7-224_lsj_8x2_50e_coco.py"
|
| 54 |
+
)
|
| 55 |
+
return args
|
| 56 |
+
|
| 57 |
+
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
|
| 58 |
+
assert DEVICE == "cuda"
|
| 59 |
+
|
| 60 |
+
def timed(fn):
|
| 61 |
+
def wrapper(*args, **kwargs):
|
| 62 |
+
startt = time.time()
|
| 63 |
+
result = fn(*args, **kwargs)
|
| 64 |
+
endt = time.time()
|
| 65 |
+
print(f'Function {fn.__name__!r} executed in {endt - startt:.3f}s', file=sys.stderr)
|
| 66 |
+
return result
|
| 67 |
+
return wrapper
|
| 68 |
+
|
| 69 |
+
# Load models
|
| 70 |
+
|
| 71 |
+
@timed
|
| 72 |
+
def load_models(args):
|
| 73 |
+
CONFIG_PATH = args.model_config
|
| 74 |
+
OBJECT_DETECTOR = args.options.get('model', "mask2former_swin-s-p4-w7-224_lsj_8x2_50e_coco")
|
| 75 |
+
CKPT_PATH = os.path.join(args.model_path, f"{OBJECT_DETECTOR}.pth")
|
| 76 |
+
object_detector = init_detector(CONFIG_PATH, CKPT_PATH, device=DEVICE)
|
| 77 |
+
|
| 78 |
+
clip_arch = args.options.get('clip_model', "ViT-L-14")
|
| 79 |
+
clip_model, _, transform = open_clip.create_model_and_transforms(clip_arch, pretrained="openai", device=DEVICE)
|
| 80 |
+
tokenizer = open_clip.get_tokenizer(clip_arch)
|
| 81 |
+
|
| 82 |
+
with open(os.path.join(os.path.dirname(__file__), "object_names.txt")) as cls_file:
|
| 83 |
+
classnames = [line.strip() for line in cls_file]
|
| 84 |
+
|
| 85 |
+
return object_detector, (clip_model, transform, tokenizer), classnames
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
COLORS = ["red", "orange", "yellow", "green", "blue", "purple", "pink", "brown", "black", "white"]
|
| 89 |
+
COLOR_CLASSIFIERS = {}
|
| 90 |
+
|
| 91 |
+
# Evaluation parts
|
| 92 |
+
|
| 93 |
+
class ImageCrops(torch.utils.data.Dataset):
|
| 94 |
+
def __init__(self, image: Image.Image, objects):
|
| 95 |
+
self._image = image.convert("RGB")
|
| 96 |
+
bgcolor = args.options.get('bgcolor', "#999")
|
| 97 |
+
if bgcolor == "original":
|
| 98 |
+
self._blank = self._image.copy()
|
| 99 |
+
else:
|
| 100 |
+
self._blank = Image.new("RGB", image.size, color=bgcolor)
|
| 101 |
+
self._objects = objects
|
| 102 |
+
|
| 103 |
+
def __len__(self):
|
| 104 |
+
return len(self._objects)
|
| 105 |
+
|
| 106 |
+
def __getitem__(self, index):
|
| 107 |
+
box, mask = self._objects[index]
|
| 108 |
+
if mask is not None:
|
| 109 |
+
assert tuple(self._image.size[::-1]) == tuple(mask.shape), (index, self._image.size[::-1], mask.shape)
|
| 110 |
+
image = Image.composite(self._image, self._blank, Image.fromarray(mask))
|
| 111 |
+
else:
|
| 112 |
+
image = self._image
|
| 113 |
+
if args.options.get('crop', '1') == '1':
|
| 114 |
+
image = image.crop(box[:4])
|
| 115 |
+
# if args.save:
|
| 116 |
+
# base_count = len(os.listdir(args.save))
|
| 117 |
+
# image.save(os.path.join(args.save, f"cropped_{base_count:05}.png"))
|
| 118 |
+
return (transform(image), 0)
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def color_classification(image, bboxes, classname):
|
| 122 |
+
if classname not in COLOR_CLASSIFIERS:
|
| 123 |
+
COLOR_CLASSIFIERS[classname] = zsc.zero_shot_classifier(
|
| 124 |
+
clip_model, tokenizer, COLORS,
|
| 125 |
+
[
|
| 126 |
+
f"a photo of a {{c}} {classname}",
|
| 127 |
+
f"a photo of a {{c}}-colored {classname}",
|
| 128 |
+
f"a photo of a {{c}} object"
|
| 129 |
+
],
|
| 130 |
+
DEVICE
|
| 131 |
+
)
|
| 132 |
+
clf = COLOR_CLASSIFIERS[classname]
|
| 133 |
+
dataloader = torch.utils.data.DataLoader(
|
| 134 |
+
ImageCrops(image, bboxes),
|
| 135 |
+
batch_size=16, num_workers=4
|
| 136 |
+
)
|
| 137 |
+
with torch.no_grad():
|
| 138 |
+
pred, _ = zsc.run_classification(clip_model, clf, dataloader, DEVICE)
|
| 139 |
+
return [COLORS[index.item()] for index in pred.argmax(1)]
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def compute_iou(box_a, box_b):
|
| 143 |
+
area_fn = lambda box: max(box[2] - box[0] + 1, 0) * max(box[3] - box[1] + 1, 0)
|
| 144 |
+
i_area = area_fn([
|
| 145 |
+
max(box_a[0], box_b[0]), max(box_a[1], box_b[1]),
|
| 146 |
+
min(box_a[2], box_b[2]), min(box_a[3], box_b[3])
|
| 147 |
+
])
|
| 148 |
+
u_area = area_fn(box_a) + area_fn(box_b) - i_area
|
| 149 |
+
return i_area / u_area if u_area else 0
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
def relative_position(obj_a, obj_b):
|
| 153 |
+
"""Give position of A relative to B, factoring in object dimensions"""
|
| 154 |
+
boxes = np.array([obj_a[0], obj_b[0]])[:, :4].reshape(2, 2, 2)
|
| 155 |
+
center_a, center_b = boxes.mean(axis=-2)
|
| 156 |
+
dim_a, dim_b = np.abs(np.diff(boxes, axis=-2))[..., 0, :]
|
| 157 |
+
offset = center_a - center_b
|
| 158 |
+
#
|
| 159 |
+
revised_offset = np.maximum(np.abs(offset) - POSITION_THRESHOLD * (dim_a + dim_b), 0) * np.sign(offset)
|
| 160 |
+
if np.all(np.abs(revised_offset) < 1e-3):
|
| 161 |
+
return set()
|
| 162 |
+
#
|
| 163 |
+
dx, dy = revised_offset / np.linalg.norm(offset)
|
| 164 |
+
relations = set()
|
| 165 |
+
if dx < -0.5: relations.add("left of")
|
| 166 |
+
if dx > 0.5: relations.add("right of")
|
| 167 |
+
if dy < -0.5: relations.add("above")
|
| 168 |
+
if dy > 0.5: relations.add("below")
|
| 169 |
+
return relations
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
def evaluate(image, objects, metadata):
|
| 173 |
+
"""
|
| 174 |
+
Evaluate given image using detected objects on the global metadata specifications.
|
| 175 |
+
Assumptions:
|
| 176 |
+
* Metadata combines 'include' clauses with AND, and 'exclude' clauses with OR
|
| 177 |
+
* All clauses are independent, i.e., duplicating a clause has no effect on the correctness
|
| 178 |
+
* CHANGED: Color and position will only be evaluated on the most confidently predicted objects;
|
| 179 |
+
therefore, objects are expected to appear in sorted order
|
| 180 |
+
"""
|
| 181 |
+
correct = True
|
| 182 |
+
reason = []
|
| 183 |
+
matched_groups = []
|
| 184 |
+
# Check for expected objects
|
| 185 |
+
for req in metadata.get('include', []):
|
| 186 |
+
classname = req['class']
|
| 187 |
+
matched = True
|
| 188 |
+
found_objects = objects.get(classname, [])[:req['count']]
|
| 189 |
+
if len(found_objects) < req['count']:
|
| 190 |
+
correct = matched = False
|
| 191 |
+
reason.append(f"expected {classname}>={req['count']}, found {len(found_objects)}")
|
| 192 |
+
else:
|
| 193 |
+
if 'color' in req:
|
| 194 |
+
# Color check
|
| 195 |
+
colors = color_classification(image, found_objects, classname)
|
| 196 |
+
if colors.count(req['color']) < req['count']:
|
| 197 |
+
correct = matched = False
|
| 198 |
+
reason.append(
|
| 199 |
+
f"expected {req['color']} {classname}>={req['count']}, found " +
|
| 200 |
+
f"{colors.count(req['color'])} {req['color']}; and " +
|
| 201 |
+
", ".join(f"{colors.count(c)} {c}" for c in COLORS if c in colors)
|
| 202 |
+
)
|
| 203 |
+
if 'position' in req and matched:
|
| 204 |
+
# Relative position check
|
| 205 |
+
expected_rel, target_group = req['position']
|
| 206 |
+
if matched_groups[target_group] is None:
|
| 207 |
+
correct = matched = False
|
| 208 |
+
reason.append(f"no target for {classname} to be {expected_rel}")
|
| 209 |
+
else:
|
| 210 |
+
for obj in found_objects:
|
| 211 |
+
for target_obj in matched_groups[target_group]:
|
| 212 |
+
true_rels = relative_position(obj, target_obj)
|
| 213 |
+
if expected_rel not in true_rels:
|
| 214 |
+
correct = matched = False
|
| 215 |
+
reason.append(
|
| 216 |
+
f"expected {classname} {expected_rel} target, found " +
|
| 217 |
+
f"{' and '.join(true_rels)} target"
|
| 218 |
+
)
|
| 219 |
+
break
|
| 220 |
+
if not matched:
|
| 221 |
+
break
|
| 222 |
+
if matched:
|
| 223 |
+
matched_groups.append(found_objects)
|
| 224 |
+
else:
|
| 225 |
+
matched_groups.append(None)
|
| 226 |
+
# Check for non-expected objects
|
| 227 |
+
for req in metadata.get('exclude', []):
|
| 228 |
+
classname = req['class']
|
| 229 |
+
if len(objects.get(classname, [])) >= req['count']:
|
| 230 |
+
correct = False
|
| 231 |
+
reason.append(f"expected {classname}<{req['count']}, found {len(objects[classname])}")
|
| 232 |
+
return correct, "\n".join(reason)
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
def evaluate_image(filepath, metadata):
|
| 236 |
+
result = inference_detector(object_detector, filepath)
|
| 237 |
+
bbox = result[0] if isinstance(result, tuple) else result
|
| 238 |
+
segm = result[1] if isinstance(result, tuple) and len(result) > 1 else None
|
| 239 |
+
image = ImageOps.exif_transpose(Image.open(filepath))
|
| 240 |
+
detected = {}
|
| 241 |
+
# Determine bounding boxes to keep
|
| 242 |
+
confidence_threshold = THRESHOLD if metadata['tag'] != "counting" else COUNTING_THRESHOLD
|
| 243 |
+
for index, classname in enumerate(classnames):
|
| 244 |
+
ordering = np.argsort(bbox[index][:, 4])[::-1]
|
| 245 |
+
ordering = ordering[bbox[index][ordering, 4] > confidence_threshold] # Threshold
|
| 246 |
+
ordering = ordering[:MAX_OBJECTS].tolist() # Limit number of detected objects per class
|
| 247 |
+
detected[classname] = []
|
| 248 |
+
while ordering:
|
| 249 |
+
max_obj = ordering.pop(0)
|
| 250 |
+
detected[classname].append((bbox[index][max_obj], None if segm is None else segm[index][max_obj]))
|
| 251 |
+
ordering = [
|
| 252 |
+
obj for obj in ordering
|
| 253 |
+
if NMS_THRESHOLD == 1 or compute_iou(bbox[index][max_obj], bbox[index][obj]) < NMS_THRESHOLD
|
| 254 |
+
]
|
| 255 |
+
if not detected[classname]:
|
| 256 |
+
del detected[classname]
|
| 257 |
+
# Evaluate
|
| 258 |
+
is_correct, reason = evaluate(image, detected, metadata)
|
| 259 |
+
return {
|
| 260 |
+
'filename': filepath,
|
| 261 |
+
'tag': metadata['tag'],
|
| 262 |
+
'prompt': metadata['prompt'],
|
| 263 |
+
'correct': is_correct,
|
| 264 |
+
'reason': reason,
|
| 265 |
+
'metadata': json.dumps(metadata),
|
| 266 |
+
'details': json.dumps({
|
| 267 |
+
key: [box.tolist() for box, _ in value]
|
| 268 |
+
for key, value in detected.items()
|
| 269 |
+
})
|
| 270 |
+
}
|
| 271 |
+
|
| 272 |
+
|
| 273 |
+
def main(args):
|
| 274 |
+
full_results = []
|
| 275 |
+
for subfolder in tqdm(os.listdir(args.imagedir)):
|
| 276 |
+
folderpath = os.path.join(args.imagedir, subfolder)
|
| 277 |
+
if not os.path.isdir(folderpath) or not subfolder.isdigit():
|
| 278 |
+
continue
|
| 279 |
+
with open(os.path.join(folderpath, "metadata.jsonl")) as fp:
|
| 280 |
+
metadata = json.load(fp)
|
| 281 |
+
# Evaluate each image
|
| 282 |
+
for imagename in os.listdir(os.path.join(folderpath, "samples")):
|
| 283 |
+
imagepath = os.path.join(folderpath, "samples", imagename)
|
| 284 |
+
if not os.path.isfile(imagepath) or not re.match(r"\d+\.png", imagename):
|
| 285 |
+
continue
|
| 286 |
+
result = evaluate_image(imagepath, metadata)
|
| 287 |
+
full_results.append(result)
|
| 288 |
+
# Save results
|
| 289 |
+
if os.path.dirname(args.outfile):
|
| 290 |
+
os.makedirs(os.path.dirname(args.outfile), exist_ok=True)
|
| 291 |
+
with open(args.outfile, "w") as fp:
|
| 292 |
+
pd.DataFrame(full_results).to_json(fp, orient="records", lines=True)
|
| 293 |
+
|
| 294 |
+
|
| 295 |
+
if __name__ == "__main__":
|
| 296 |
+
args = parse_args()
|
| 297 |
+
object_detector, (clip_model, transform, tokenizer), classnames = load_models(args)
|
| 298 |
+
THRESHOLD = float(args.options.get('threshold', 0.3))
|
| 299 |
+
COUNTING_THRESHOLD = float(args.options.get('counting_threshold', 0.9))
|
| 300 |
+
MAX_OBJECTS = int(args.options.get('max_objects', 16))
|
| 301 |
+
NMS_THRESHOLD = float(args.options.get('max_overlap', 1.0))
|
| 302 |
+
POSITION_THRESHOLD = float(args.options.get('position_threshold', 0.1))
|
| 303 |
+
|
| 304 |
+
main(args)
|
eval/gen/geneval/evaluation/evaluate_images_mp.py
ADDED
|
@@ -0,0 +1,332 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023 Dhruba Ghosh
|
| 2 |
+
# Copyright (c) 2025 Bytedance Ltd. and/or its affiliates.
|
| 3 |
+
# SPDX-License-Identifier: MIT
|
| 4 |
+
#
|
| 5 |
+
# This file has been modified by ByteDance Ltd. and/or its affiliates. on 2025-05-20.
|
| 6 |
+
#
|
| 7 |
+
# Original file was released under MIT, with the full license text
|
| 8 |
+
# available at https://github.com/djghosh13/geneval/blob/main/LICENSE.
|
| 9 |
+
#
|
| 10 |
+
# This modified file is released under the same license.
|
| 11 |
+
|
| 12 |
+
import argparse
|
| 13 |
+
import json
|
| 14 |
+
import os
|
| 15 |
+
import re
|
| 16 |
+
import sys
|
| 17 |
+
import time
|
| 18 |
+
from tqdm import tqdm
|
| 19 |
+
|
| 20 |
+
import warnings
|
| 21 |
+
warnings.filterwarnings("ignore")
|
| 22 |
+
|
| 23 |
+
import numpy as np
|
| 24 |
+
import pandas as pd
|
| 25 |
+
from PIL import Image, ImageOps
|
| 26 |
+
import torch
|
| 27 |
+
import torch.distributed as dist
|
| 28 |
+
import mmdet
|
| 29 |
+
from mmdet.apis import inference_detector, init_detector
|
| 30 |
+
|
| 31 |
+
import open_clip
|
| 32 |
+
from clip_benchmark.metrics import zeroshot_classification as zsc
|
| 33 |
+
zsc.tqdm = lambda it, *args, **kwargs: it
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def setup_distributed():
|
| 37 |
+
"""初始化分布式环境"""
|
| 38 |
+
dist.init_process_group(backend="nccl")
|
| 39 |
+
torch.cuda.set_device(int(os.environ["LOCAL_RANK"]))
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
# Get directory path
|
| 43 |
+
|
| 44 |
+
def parse_args():
|
| 45 |
+
parser = argparse.ArgumentParser()
|
| 46 |
+
parser.add_argument("imagedir", type=str)
|
| 47 |
+
parser.add_argument("--outfile", type=str, default="results.jsonl")
|
| 48 |
+
parser.add_argument("--model-config", type=str, default=None)
|
| 49 |
+
parser.add_argument("--model-path", type=str, default="./")
|
| 50 |
+
# Other arguments
|
| 51 |
+
parser.add_argument("--options", nargs="*", type=str, default=[])
|
| 52 |
+
args = parser.parse_args()
|
| 53 |
+
args.options = dict(opt.split("=", 1) for opt in args.options)
|
| 54 |
+
if args.model_config is None:
|
| 55 |
+
args.model_config = os.path.join(
|
| 56 |
+
os.path.dirname(mmdet.__file__),
|
| 57 |
+
"../configs/mask2former/mask2former_swin-s-p4-w7-224_lsj_8x2_50e_coco.py"
|
| 58 |
+
)
|
| 59 |
+
return args
|
| 60 |
+
|
| 61 |
+
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
|
| 62 |
+
assert DEVICE == "cuda"
|
| 63 |
+
|
| 64 |
+
def timed(fn):
|
| 65 |
+
def wrapper(*args, **kwargs):
|
| 66 |
+
startt = time.time()
|
| 67 |
+
result = fn(*args, **kwargs)
|
| 68 |
+
endt = time.time()
|
| 69 |
+
print(f'Function {fn.__name__!r} executed in {endt - startt:.3f}s', file=sys.stderr)
|
| 70 |
+
return result
|
| 71 |
+
return wrapper
|
| 72 |
+
|
| 73 |
+
# Load models
|
| 74 |
+
|
| 75 |
+
@timed
|
| 76 |
+
def load_models(args):
|
| 77 |
+
CONFIG_PATH = args.model_config
|
| 78 |
+
OBJECT_DETECTOR = args.options.get('model', "mask2former_swin-s-p4-w7-224_lsj_8x2_50e_coco")
|
| 79 |
+
CKPT_PATH = os.path.join(args.model_path, f"{OBJECT_DETECTOR}.pth")
|
| 80 |
+
object_detector = init_detector(CONFIG_PATH, CKPT_PATH, device=DEVICE)
|
| 81 |
+
|
| 82 |
+
clip_arch = args.options.get('clip_model', "ViT-L-14")
|
| 83 |
+
clip_model, _, transform = open_clip.create_model_and_transforms(clip_arch, pretrained="openai", device=DEVICE)
|
| 84 |
+
tokenizer = open_clip.get_tokenizer(clip_arch)
|
| 85 |
+
|
| 86 |
+
with open(os.path.join(os.path.dirname(__file__), "object_names.txt")) as cls_file:
|
| 87 |
+
classnames = [line.strip() for line in cls_file]
|
| 88 |
+
|
| 89 |
+
return object_detector, (clip_model, transform, tokenizer), classnames
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
COLORS = ["red", "orange", "yellow", "green", "blue", "purple", "pink", "brown", "black", "white"]
|
| 93 |
+
COLOR_CLASSIFIERS = {}
|
| 94 |
+
|
| 95 |
+
# Evaluation parts
|
| 96 |
+
|
| 97 |
+
class ImageCrops(torch.utils.data.Dataset):
|
| 98 |
+
def __init__(self, image: Image.Image, objects):
|
| 99 |
+
self._image = image.convert("RGB")
|
| 100 |
+
bgcolor = args.options.get('bgcolor', "#999")
|
| 101 |
+
if bgcolor == "original":
|
| 102 |
+
self._blank = self._image.copy()
|
| 103 |
+
else:
|
| 104 |
+
self._blank = Image.new("RGB", image.size, color=bgcolor)
|
| 105 |
+
self._objects = objects
|
| 106 |
+
|
| 107 |
+
def __len__(self):
|
| 108 |
+
return len(self._objects)
|
| 109 |
+
|
| 110 |
+
def __getitem__(self, index):
|
| 111 |
+
box, mask = self._objects[index]
|
| 112 |
+
if mask is not None:
|
| 113 |
+
assert tuple(self._image.size[::-1]) == tuple(mask.shape), (index, self._image.size[::-1], mask.shape)
|
| 114 |
+
image = Image.composite(self._image, self._blank, Image.fromarray(mask))
|
| 115 |
+
else:
|
| 116 |
+
image = self._image
|
| 117 |
+
if args.options.get('crop', '1') == '1':
|
| 118 |
+
image = image.crop(box[:4])
|
| 119 |
+
# if args.save:
|
| 120 |
+
# base_count = len(os.listdir(args.save))
|
| 121 |
+
# image.save(os.path.join(args.save, f"cropped_{base_count:05}.png"))
|
| 122 |
+
return (transform(image), 0)
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
def color_classification(image, bboxes, classname):
|
| 126 |
+
if classname not in COLOR_CLASSIFIERS:
|
| 127 |
+
COLOR_CLASSIFIERS[classname] = zsc.zero_shot_classifier(
|
| 128 |
+
clip_model, tokenizer, COLORS,
|
| 129 |
+
[
|
| 130 |
+
f"a photo of a {{c}} {classname}",
|
| 131 |
+
f"a photo of a {{c}}-colored {classname}",
|
| 132 |
+
f"a photo of a {{c}} object"
|
| 133 |
+
],
|
| 134 |
+
DEVICE
|
| 135 |
+
)
|
| 136 |
+
clf = COLOR_CLASSIFIERS[classname]
|
| 137 |
+
dataloader = torch.utils.data.DataLoader(
|
| 138 |
+
ImageCrops(image, bboxes),
|
| 139 |
+
batch_size=16, num_workers=4
|
| 140 |
+
)
|
| 141 |
+
with torch.no_grad():
|
| 142 |
+
pred, _ = zsc.run_classification(clip_model, clf, dataloader, DEVICE)
|
| 143 |
+
return [COLORS[index.item()] for index in pred.argmax(1)]
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def compute_iou(box_a, box_b):
|
| 147 |
+
area_fn = lambda box: max(box[2] - box[0] + 1, 0) * max(box[3] - box[1] + 1, 0)
|
| 148 |
+
i_area = area_fn([
|
| 149 |
+
max(box_a[0], box_b[0]), max(box_a[1], box_b[1]),
|
| 150 |
+
min(box_a[2], box_b[2]), min(box_a[3], box_b[3])
|
| 151 |
+
])
|
| 152 |
+
u_area = area_fn(box_a) + area_fn(box_b) - i_area
|
| 153 |
+
return i_area / u_area if u_area else 0
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
def relative_position(obj_a, obj_b):
|
| 157 |
+
"""Give position of A relative to B, factoring in object dimensions"""
|
| 158 |
+
boxes = np.array([obj_a[0], obj_b[0]])[:, :4].reshape(2, 2, 2)
|
| 159 |
+
center_a, center_b = boxes.mean(axis=-2)
|
| 160 |
+
dim_a, dim_b = np.abs(np.diff(boxes, axis=-2))[..., 0, :]
|
| 161 |
+
offset = center_a - center_b
|
| 162 |
+
#
|
| 163 |
+
revised_offset = np.maximum(np.abs(offset) - POSITION_THRESHOLD * (dim_a + dim_b), 0) * np.sign(offset)
|
| 164 |
+
if np.all(np.abs(revised_offset) < 1e-3):
|
| 165 |
+
return set()
|
| 166 |
+
#
|
| 167 |
+
dx, dy = revised_offset / np.linalg.norm(offset)
|
| 168 |
+
relations = set()
|
| 169 |
+
if dx < -0.5: relations.add("left of")
|
| 170 |
+
if dx > 0.5: relations.add("right of")
|
| 171 |
+
if dy < -0.5: relations.add("above")
|
| 172 |
+
if dy > 0.5: relations.add("below")
|
| 173 |
+
return relations
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
def evaluate(image, objects, metadata):
|
| 177 |
+
"""
|
| 178 |
+
Evaluate given image using detected objects on the global metadata specifications.
|
| 179 |
+
Assumptions:
|
| 180 |
+
* Metadata combines 'include' clauses with AND, and 'exclude' clauses with OR
|
| 181 |
+
* All clauses are independent, i.e., duplicating a clause has no effect on the correctness
|
| 182 |
+
* CHANGED: Color and position will only be evaluated on the most confidently predicted objects;
|
| 183 |
+
therefore, objects are expected to appear in sorted order
|
| 184 |
+
"""
|
| 185 |
+
correct = True
|
| 186 |
+
reason = []
|
| 187 |
+
matched_groups = []
|
| 188 |
+
# Check for expected objects
|
| 189 |
+
for req in metadata.get('include', []):
|
| 190 |
+
classname = req['class']
|
| 191 |
+
matched = True
|
| 192 |
+
found_objects = objects.get(classname, [])[:req['count']]
|
| 193 |
+
if len(found_objects) < req['count']:
|
| 194 |
+
correct = matched = False
|
| 195 |
+
reason.append(f"expected {classname}>={req['count']}, found {len(found_objects)}")
|
| 196 |
+
else:
|
| 197 |
+
if 'color' in req:
|
| 198 |
+
# Color check
|
| 199 |
+
colors = color_classification(image, found_objects, classname)
|
| 200 |
+
if colors.count(req['color']) < req['count']:
|
| 201 |
+
correct = matched = False
|
| 202 |
+
reason.append(
|
| 203 |
+
f"expected {req['color']} {classname}>={req['count']}, found " +
|
| 204 |
+
f"{colors.count(req['color'])} {req['color']}; and " +
|
| 205 |
+
", ".join(f"{colors.count(c)} {c}" for c in COLORS if c in colors)
|
| 206 |
+
)
|
| 207 |
+
if 'position' in req and matched:
|
| 208 |
+
# Relative position check
|
| 209 |
+
expected_rel, target_group = req['position']
|
| 210 |
+
if matched_groups[target_group] is None:
|
| 211 |
+
correct = matched = False
|
| 212 |
+
reason.append(f"no target for {classname} to be {expected_rel}")
|
| 213 |
+
else:
|
| 214 |
+
for obj in found_objects:
|
| 215 |
+
for target_obj in matched_groups[target_group]:
|
| 216 |
+
true_rels = relative_position(obj, target_obj)
|
| 217 |
+
if expected_rel not in true_rels:
|
| 218 |
+
correct = matched = False
|
| 219 |
+
reason.append(
|
| 220 |
+
f"expected {classname} {expected_rel} target, found " +
|
| 221 |
+
f"{' and '.join(true_rels)} target"
|
| 222 |
+
)
|
| 223 |
+
break
|
| 224 |
+
if not matched:
|
| 225 |
+
break
|
| 226 |
+
if matched:
|
| 227 |
+
matched_groups.append(found_objects)
|
| 228 |
+
else:
|
| 229 |
+
matched_groups.append(None)
|
| 230 |
+
# Check for non-expected objects
|
| 231 |
+
for req in metadata.get('exclude', []):
|
| 232 |
+
classname = req['class']
|
| 233 |
+
if len(objects.get(classname, [])) >= req['count']:
|
| 234 |
+
correct = False
|
| 235 |
+
reason.append(f"expected {classname}<{req['count']}, found {len(objects[classname])}")
|
| 236 |
+
return correct, "\n".join(reason)
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
def evaluate_image(filepath, metadata):
|
| 240 |
+
result = inference_detector(object_detector, filepath)
|
| 241 |
+
bbox = result[0] if isinstance(result, tuple) else result
|
| 242 |
+
segm = result[1] if isinstance(result, tuple) and len(result) > 1 else None
|
| 243 |
+
image = ImageOps.exif_transpose(Image.open(filepath))
|
| 244 |
+
detected = {}
|
| 245 |
+
# Determine bounding boxes to keep
|
| 246 |
+
confidence_threshold = THRESHOLD if metadata['tag'] != "counting" else COUNTING_THRESHOLD
|
| 247 |
+
for index, classname in enumerate(classnames):
|
| 248 |
+
ordering = np.argsort(bbox[index][:, 4])[::-1]
|
| 249 |
+
ordering = ordering[bbox[index][ordering, 4] > confidence_threshold] # Threshold
|
| 250 |
+
ordering = ordering[:MAX_OBJECTS].tolist() # Limit number of detected objects per class
|
| 251 |
+
detected[classname] = []
|
| 252 |
+
while ordering:
|
| 253 |
+
max_obj = ordering.pop(0)
|
| 254 |
+
detected[classname].append((bbox[index][max_obj], None if segm is None else segm[index][max_obj]))
|
| 255 |
+
ordering = [
|
| 256 |
+
obj for obj in ordering
|
| 257 |
+
if NMS_THRESHOLD == 1 or compute_iou(bbox[index][max_obj], bbox[index][obj]) < NMS_THRESHOLD
|
| 258 |
+
]
|
| 259 |
+
if not detected[classname]:
|
| 260 |
+
del detected[classname]
|
| 261 |
+
# Evaluate
|
| 262 |
+
is_correct, reason = evaluate(image, detected, metadata)
|
| 263 |
+
return {
|
| 264 |
+
'filename': filepath,
|
| 265 |
+
'tag': metadata['tag'],
|
| 266 |
+
'prompt': metadata['prompt'],
|
| 267 |
+
'correct': is_correct,
|
| 268 |
+
'reason': reason,
|
| 269 |
+
'metadata': json.dumps(metadata),
|
| 270 |
+
'details': json.dumps({
|
| 271 |
+
key: [box.tolist() for box, _ in value]
|
| 272 |
+
for key, value in detected.items()
|
| 273 |
+
})
|
| 274 |
+
}
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
if __name__ == "__main__":
|
| 278 |
+
args = parse_args()
|
| 279 |
+
THRESHOLD = float(args.options.get('threshold', 0.3))
|
| 280 |
+
COUNTING_THRESHOLD = float(args.options.get('counting_threshold', 0.9))
|
| 281 |
+
MAX_OBJECTS = int(args.options.get('max_objects', 16))
|
| 282 |
+
NMS_THRESHOLD = float(args.options.get('max_overlap', 1.0))
|
| 283 |
+
POSITION_THRESHOLD = float(args.options.get('position_threshold', 0.1))
|
| 284 |
+
|
| 285 |
+
# Initialize distributed environment
|
| 286 |
+
setup_distributed()
|
| 287 |
+
rank = dist.get_rank()
|
| 288 |
+
world_size = dist.get_world_size()
|
| 289 |
+
device = f"cuda:{rank}"
|
| 290 |
+
|
| 291 |
+
# Load models
|
| 292 |
+
if rank == 0:
|
| 293 |
+
print(f"[Rank 0] Loading model...")
|
| 294 |
+
object_detector, (clip_model, transform, tokenizer), classnames = load_models(args)
|
| 295 |
+
|
| 296 |
+
full_results = []
|
| 297 |
+
subfolders = [f for f in os.listdir(args.imagedir) if os.path.isdir(os.path.join(args.imagedir, f)) and f.isdigit()]
|
| 298 |
+
total_subfolders = len(subfolders)
|
| 299 |
+
# Divide subfolders to process by GPU
|
| 300 |
+
subfolders_per_gpu = (total_subfolders + world_size - 1) // world_size
|
| 301 |
+
start = rank * subfolders_per_gpu
|
| 302 |
+
end = min(start + subfolders_per_gpu, total_subfolders)
|
| 303 |
+
print(f"GPU {rank}: Processing {end - start} subfolders (index {start} to {end - 1})")
|
| 304 |
+
|
| 305 |
+
for subfolder in tqdm(subfolders[start:end]):
|
| 306 |
+
folderpath = os.path.join(args.imagedir, subfolder)
|
| 307 |
+
with open(os.path.join(folderpath, "metadata.jsonl")) as fp:
|
| 308 |
+
metadata = json.load(fp)
|
| 309 |
+
# Evaluate each image
|
| 310 |
+
for imagename in os.listdir(os.path.join(folderpath, "samples")):
|
| 311 |
+
imagepath = os.path.join(folderpath, "samples", imagename)
|
| 312 |
+
if not os.path.isfile(imagepath) or not re.match(r"\d+\.png", imagename):
|
| 313 |
+
continue
|
| 314 |
+
result = evaluate_image(imagepath, metadata)
|
| 315 |
+
full_results.append(result)
|
| 316 |
+
|
| 317 |
+
# Synchronize results from all GPUs
|
| 318 |
+
all_results = [None] * world_size
|
| 319 |
+
dist.all_gather_object(all_results, full_results)
|
| 320 |
+
if rank == 0:
|
| 321 |
+
# Merge results from all GPUs
|
| 322 |
+
final_results = []
|
| 323 |
+
for results in all_results:
|
| 324 |
+
final_results.extend(results)
|
| 325 |
+
# Save results
|
| 326 |
+
if os.path.dirname(args.outfile):
|
| 327 |
+
os.makedirs(os.path.dirname(args.outfile), exist_ok=True)
|
| 328 |
+
with open(args.outfile, "w") as fp:
|
| 329 |
+
pd.DataFrame(final_results).to_json(fp, orient="records", lines=True)
|
| 330 |
+
print("All GPUs have completed their tasks and the final results have been saved.")
|
| 331 |
+
else:
|
| 332 |
+
print(f"GPU {rank} has completed all tasks")
|
eval/gen/geneval/evaluation/object_names.txt
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
person
|
| 2 |
+
bicycle
|
| 3 |
+
car
|
| 4 |
+
motorcycle
|
| 5 |
+
airplane
|
| 6 |
+
bus
|
| 7 |
+
train
|
| 8 |
+
truck
|
| 9 |
+
boat
|
| 10 |
+
traffic light
|
| 11 |
+
fire hydrant
|
| 12 |
+
stop sign
|
| 13 |
+
parking meter
|
| 14 |
+
bench
|
| 15 |
+
bird
|
| 16 |
+
cat
|
| 17 |
+
dog
|
| 18 |
+
horse
|
| 19 |
+
sheep
|
| 20 |
+
cow
|
| 21 |
+
elephant
|
| 22 |
+
bear
|
| 23 |
+
zebra
|
| 24 |
+
giraffe
|
| 25 |
+
backpack
|
| 26 |
+
umbrella
|
| 27 |
+
handbag
|
| 28 |
+
tie
|
| 29 |
+
suitcase
|
| 30 |
+
frisbee
|
| 31 |
+
skis
|
| 32 |
+
snowboard
|
| 33 |
+
sports ball
|
| 34 |
+
kite
|
| 35 |
+
baseball bat
|
| 36 |
+
baseball glove
|
| 37 |
+
skateboard
|
| 38 |
+
surfboard
|
| 39 |
+
tennis racket
|
| 40 |
+
bottle
|
| 41 |
+
wine glass
|
| 42 |
+
cup
|
| 43 |
+
fork
|
| 44 |
+
knife
|
| 45 |
+
spoon
|
| 46 |
+
bowl
|
| 47 |
+
banana
|
| 48 |
+
apple
|
| 49 |
+
sandwich
|
| 50 |
+
orange
|
| 51 |
+
broccoli
|
| 52 |
+
carrot
|
| 53 |
+
hot dog
|
| 54 |
+
pizza
|
| 55 |
+
donut
|
| 56 |
+
cake
|
| 57 |
+
chair
|
| 58 |
+
couch
|
| 59 |
+
potted plant
|
| 60 |
+
bed
|
| 61 |
+
dining table
|
| 62 |
+
toilet
|
| 63 |
+
tv
|
| 64 |
+
laptop
|
| 65 |
+
computer mouse
|
| 66 |
+
tv remote
|
| 67 |
+
computer keyboard
|
| 68 |
+
cell phone
|
| 69 |
+
microwave
|
| 70 |
+
oven
|
| 71 |
+
toaster
|
| 72 |
+
sink
|
| 73 |
+
refrigerator
|
| 74 |
+
book
|
| 75 |
+
clock
|
| 76 |
+
vase
|
| 77 |
+
scissors
|
| 78 |
+
teddy bear
|
| 79 |
+
hair drier
|
| 80 |
+
toothbrush
|
eval/gen/geneval/evaluation/summary_scores.py
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023 Dhruba Ghosh
|
| 2 |
+
# Copyright (c) 2025 Bytedance Ltd. and/or its affiliates.
|
| 3 |
+
# SPDX-License-Identifier: MIT
|
| 4 |
+
#
|
| 5 |
+
# This file has been modified by ByteDance Ltd. and/or its affiliates. on 2025-05-20.
|
| 6 |
+
#
|
| 7 |
+
# Original file was released under MIT, with the full license text
|
| 8 |
+
# available at https://github.com/djghosh13/geneval/blob/main/LICENSE.
|
| 9 |
+
#
|
| 10 |
+
# This modified file is released under the same license.
|
| 11 |
+
|
| 12 |
+
import argparse
|
| 13 |
+
import os
|
| 14 |
+
|
| 15 |
+
import numpy as np
|
| 16 |
+
import pandas as pd
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
parser = argparse.ArgumentParser()
|
| 20 |
+
parser.add_argument("filename", type=str)
|
| 21 |
+
args = parser.parse_args()
|
| 22 |
+
|
| 23 |
+
# Load classnames
|
| 24 |
+
|
| 25 |
+
with open(os.path.join(os.path.dirname(__file__), "object_names.txt")) as cls_file:
|
| 26 |
+
classnames = [line.strip() for line in cls_file]
|
| 27 |
+
cls_to_idx = {"_".join(cls.split()):idx for idx, cls in enumerate(classnames)}
|
| 28 |
+
|
| 29 |
+
# Load results
|
| 30 |
+
|
| 31 |
+
df = pd.read_json(args.filename, orient="records", lines=True)
|
| 32 |
+
|
| 33 |
+
# Measure overall success
|
| 34 |
+
|
| 35 |
+
print("Summary")
|
| 36 |
+
print("=======")
|
| 37 |
+
print(f"Total images: {len(df)}")
|
| 38 |
+
print(f"Total prompts: {len(df.groupby('metadata'))}")
|
| 39 |
+
print(f"% correct images: {df['correct'].mean():.2%}")
|
| 40 |
+
print(f"% correct prompts: {df.groupby('metadata')['correct'].any().mean():.2%}")
|
| 41 |
+
print()
|
| 42 |
+
|
| 43 |
+
# By group
|
| 44 |
+
|
| 45 |
+
task_scores = []
|
| 46 |
+
|
| 47 |
+
print("Task breakdown")
|
| 48 |
+
print("==============")
|
| 49 |
+
for tag, task_df in df.groupby('tag', sort=False):
|
| 50 |
+
task_scores.append(task_df['correct'].mean())
|
| 51 |
+
print(f"{tag:<16} = {task_df['correct'].mean():.2%} ({task_df['correct'].sum()} / {len(task_df)})")
|
| 52 |
+
print()
|
| 53 |
+
|
| 54 |
+
print(f"Overall score (avg. over tasks): {np.mean(task_scores):.5f}")
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
print("\n\n==============")
|
| 58 |
+
output_info = "SO TO CT CL POS ATTR ALL\n"
|
| 59 |
+
for score in task_scores:
|
| 60 |
+
output_info += f"{score:.2f} "
|
| 61 |
+
output_info += f"{np.mean(task_scores):.2f}" + "\n"
|
| 62 |
+
print(output_info)
|
| 63 |
+
with open(os.path.join(os.path.dirname(args.filename), "geneval_results.txt"), "w") as f:
|
| 64 |
+
f.write(output_info)
|
eval/gen/geneval/prompts/create_prompts.py
ADDED
|
@@ -0,0 +1,194 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023 Dhruba Ghosh
|
| 2 |
+
# Copyright (c) 2025 Bytedance Ltd. and/or its affiliates.
|
| 3 |
+
# SPDX-License-Identifier: MIT
|
| 4 |
+
#
|
| 5 |
+
# This file has been modified by ByteDance Ltd. and/or its affiliates. on 2025-05-20.
|
| 6 |
+
#
|
| 7 |
+
# Original file was released under MIT, with the full license text
|
| 8 |
+
# available at https://github.com/djghosh13/geneval/blob/main/LICENSE.
|
| 9 |
+
#
|
| 10 |
+
# This modified file is released under the same license.
|
| 11 |
+
|
| 12 |
+
"""
|
| 13 |
+
Generate prompts for evaluation
|
| 14 |
+
"""
|
| 15 |
+
|
| 16 |
+
import argparse
|
| 17 |
+
import json
|
| 18 |
+
import os
|
| 19 |
+
import yaml
|
| 20 |
+
|
| 21 |
+
import numpy as np
|
| 22 |
+
|
| 23 |
+
# Load classnames
|
| 24 |
+
|
| 25 |
+
with open("object_names.txt") as cls_file:
|
| 26 |
+
classnames = [line.strip() for line in cls_file]
|
| 27 |
+
|
| 28 |
+
# Proper a vs an
|
| 29 |
+
|
| 30 |
+
def with_article(name: str):
|
| 31 |
+
if name[0] in "aeiou":
|
| 32 |
+
return f"an {name}"
|
| 33 |
+
return f"a {name}"
|
| 34 |
+
|
| 35 |
+
# Proper plural
|
| 36 |
+
|
| 37 |
+
def make_plural(name: str):
|
| 38 |
+
if name[-1] in "s":
|
| 39 |
+
return f"{name}es"
|
| 40 |
+
return f"{name}s"
|
| 41 |
+
|
| 42 |
+
# Generates single object samples
|
| 43 |
+
|
| 44 |
+
def generate_single_object_sample(rng: np.random.Generator, size: int = None):
|
| 45 |
+
TAG = "single_object"
|
| 46 |
+
if size > len(classnames):
|
| 47 |
+
size = len(classnames)
|
| 48 |
+
print(f"Not enough distinct classes, generating only {size} samples")
|
| 49 |
+
return_scalar = size is None
|
| 50 |
+
size = size or 1
|
| 51 |
+
idxs = rng.choice(len(classnames), size=size, replace=False)
|
| 52 |
+
samples = [dict(
|
| 53 |
+
tag=TAG,
|
| 54 |
+
include=[
|
| 55 |
+
{"class": classnames[idx], "count": 1}
|
| 56 |
+
],
|
| 57 |
+
prompt=f"a photo of {with_article(classnames[idx])}"
|
| 58 |
+
) for idx in idxs]
|
| 59 |
+
if return_scalar:
|
| 60 |
+
return samples[0]
|
| 61 |
+
return samples
|
| 62 |
+
|
| 63 |
+
# Generate two object samples
|
| 64 |
+
|
| 65 |
+
def generate_two_object_sample(rng: np.random.Generator):
|
| 66 |
+
TAG = "two_object"
|
| 67 |
+
idx_a, idx_b = rng.choice(len(classnames), size=2, replace=False)
|
| 68 |
+
return dict(
|
| 69 |
+
tag=TAG,
|
| 70 |
+
include=[
|
| 71 |
+
{"class": classnames[idx_a], "count": 1},
|
| 72 |
+
{"class": classnames[idx_b], "count": 1}
|
| 73 |
+
],
|
| 74 |
+
prompt=f"a photo of {with_article(classnames[idx_a])} and {with_article(classnames[idx_b])}"
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
# Generate counting samples
|
| 78 |
+
|
| 79 |
+
numbers = ["zero", "one", "two", "three", "four", "five", "six", "seven", "eight", "nine", "ten"]
|
| 80 |
+
|
| 81 |
+
def generate_counting_sample(rng: np.random.Generator, max_count=4):
|
| 82 |
+
TAG = "counting"
|
| 83 |
+
idx = rng.choice(len(classnames))
|
| 84 |
+
num = int(rng.integers(2, max_count, endpoint=True))
|
| 85 |
+
return dict(
|
| 86 |
+
tag=TAG,
|
| 87 |
+
include=[
|
| 88 |
+
{"class": classnames[idx], "count": num}
|
| 89 |
+
],
|
| 90 |
+
exclude=[
|
| 91 |
+
{"class": classnames[idx], "count": num + 1}
|
| 92 |
+
],
|
| 93 |
+
prompt=f"a photo of {numbers[num]} {make_plural(classnames[idx])}"
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
# Generate color samples
|
| 97 |
+
|
| 98 |
+
colors = ["red", "orange", "yellow", "green", "blue", "purple", "pink", "brown", "black", "white"]
|
| 99 |
+
|
| 100 |
+
def generate_color_sample(rng: np.random.Generator):
|
| 101 |
+
TAG = "colors"
|
| 102 |
+
idx = rng.choice(len(classnames) - 1) + 1
|
| 103 |
+
idx = (idx + classnames.index("person")) % len(classnames) # No "[COLOR] person" prompts
|
| 104 |
+
color = colors[rng.choice(len(colors))]
|
| 105 |
+
return dict(
|
| 106 |
+
tag=TAG,
|
| 107 |
+
include=[
|
| 108 |
+
{"class": classnames[idx], "count": 1, "color": color}
|
| 109 |
+
],
|
| 110 |
+
prompt=f"a photo of {with_article(color)} {classnames[idx]}"
|
| 111 |
+
)
|
| 112 |
+
|
| 113 |
+
# Generate position samples
|
| 114 |
+
|
| 115 |
+
positions = ["left of", "right of", "above", "below"]
|
| 116 |
+
|
| 117 |
+
def generate_position_sample(rng: np.random.Generator):
|
| 118 |
+
TAG = "position"
|
| 119 |
+
idx_a, idx_b = rng.choice(len(classnames), size=2, replace=False)
|
| 120 |
+
position = positions[rng.choice(len(positions))]
|
| 121 |
+
return dict(
|
| 122 |
+
tag=TAG,
|
| 123 |
+
include=[
|
| 124 |
+
{"class": classnames[idx_b], "count": 1},
|
| 125 |
+
{"class": classnames[idx_a], "count": 1, "position": (position, 0)}
|
| 126 |
+
],
|
| 127 |
+
prompt=f"a photo of {with_article(classnames[idx_a])} {position} {with_article(classnames[idx_b])}"
|
| 128 |
+
)
|
| 129 |
+
|
| 130 |
+
# Generate color attribution samples
|
| 131 |
+
|
| 132 |
+
def generate_color_attribution_sample(rng: np.random.Generator):
|
| 133 |
+
TAG = "color_attr"
|
| 134 |
+
idxs = rng.choice(len(classnames) - 1, size=2, replace=False) + 1
|
| 135 |
+
idx_a, idx_b = (idxs + classnames.index("person")) % len(classnames) # No "[COLOR] person" prompts
|
| 136 |
+
cidx_a, cidx_b = rng.choice(len(colors), size=2, replace=False)
|
| 137 |
+
return dict(
|
| 138 |
+
tag=TAG,
|
| 139 |
+
include=[
|
| 140 |
+
{"class": classnames[idx_a], "count": 1, "color": colors[cidx_a]},
|
| 141 |
+
{"class": classnames[idx_b], "count": 1, "color": colors[cidx_b]}
|
| 142 |
+
],
|
| 143 |
+
prompt=f"a photo of {with_article(colors[cidx_a])} {classnames[idx_a]} and {with_article(colors[cidx_b])} {classnames[idx_b]}"
|
| 144 |
+
)
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
# Generate evaluation suite
|
| 148 |
+
|
| 149 |
+
def generate_suite(rng: np.random.Generator, n: int = 100, output_path: str = ""):
|
| 150 |
+
samples = []
|
| 151 |
+
# Generate single object samples for all COCO classnames
|
| 152 |
+
samples.extend(generate_single_object_sample(rng, size=len(classnames)))
|
| 153 |
+
# Generate two object samples (~100)
|
| 154 |
+
for _ in range(n):
|
| 155 |
+
samples.append(generate_two_object_sample(rng))
|
| 156 |
+
# Generate counting samples
|
| 157 |
+
for _ in range(n):
|
| 158 |
+
samples.append(generate_counting_sample(rng, max_count=4))
|
| 159 |
+
# Generate color samples
|
| 160 |
+
for _ in range(n):
|
| 161 |
+
samples.append(generate_color_sample(rng))
|
| 162 |
+
# Generate position samples
|
| 163 |
+
for _ in range(n):
|
| 164 |
+
samples.append(generate_position_sample(rng))
|
| 165 |
+
# Generate color attribution samples
|
| 166 |
+
for _ in range(n):
|
| 167 |
+
samples.append(generate_color_attribution_sample(rng))
|
| 168 |
+
# De-duplicate
|
| 169 |
+
unique_samples, used_samples = [], set()
|
| 170 |
+
for sample in samples:
|
| 171 |
+
sample_text = yaml.safe_dump(sample)
|
| 172 |
+
if sample_text not in used_samples:
|
| 173 |
+
unique_samples.append(sample)
|
| 174 |
+
used_samples.add(sample_text)
|
| 175 |
+
|
| 176 |
+
# Write to files
|
| 177 |
+
os.makedirs(output_path, exist_ok=True)
|
| 178 |
+
with open(os.path.join(output_path, "generation_prompts.txt"), "w") as fp:
|
| 179 |
+
for sample in unique_samples:
|
| 180 |
+
print(sample['prompt'], file=fp)
|
| 181 |
+
with open(os.path.join(output_path, "evaluation_metadata.jsonl"), "w") as fp:
|
| 182 |
+
for sample in unique_samples:
|
| 183 |
+
print(json.dumps(sample), file=fp)
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
if __name__ == "__main__":
|
| 187 |
+
parser = argparse.ArgumentParser()
|
| 188 |
+
parser.add_argument("--seed", type=int, default=43, help="generation seed (default: 43)")
|
| 189 |
+
parser.add_argument("--num-prompts", "-n", type=int, default=100, help="number of prompts per task (default: 100)")
|
| 190 |
+
parser.add_argument("--output-path", "-o", type=str, default="prompts", help="output folder for prompts and metadata (default: 'prompts/')")
|
| 191 |
+
args = parser.parse_args()
|
| 192 |
+
rng = np.random.default_rng(args.seed)
|
| 193 |
+
generate_suite(rng, args.num_prompts, args.output_path)
|
| 194 |
+
|
eval/gen/geneval/prompts/evaluation_metadata.jsonl
ADDED
|
@@ -0,0 +1,553 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"tag": "single_object", "include": [{"class": "bench", "count": 1}], "prompt": "a photo of a bench"}
|
| 2 |
+
{"tag": "single_object", "include": [{"class": "cow", "count": 1}], "prompt": "a photo of a cow"}
|
| 3 |
+
{"tag": "single_object", "include": [{"class": "bicycle", "count": 1}], "prompt": "a photo of a bicycle"}
|
| 4 |
+
{"tag": "single_object", "include": [{"class": "clock", "count": 1}], "prompt": "a photo of a clock"}
|
| 5 |
+
{"tag": "single_object", "include": [{"class": "carrot", "count": 1}], "prompt": "a photo of a carrot"}
|
| 6 |
+
{"tag": "single_object", "include": [{"class": "suitcase", "count": 1}], "prompt": "a photo of a suitcase"}
|
| 7 |
+
{"tag": "single_object", "include": [{"class": "fork", "count": 1}], "prompt": "a photo of a fork"}
|
| 8 |
+
{"tag": "single_object", "include": [{"class": "surfboard", "count": 1}], "prompt": "a photo of a surfboard"}
|
| 9 |
+
{"tag": "single_object", "include": [{"class": "refrigerator", "count": 1}], "prompt": "a photo of a refrigerator"}
|
| 10 |
+
{"tag": "single_object", "include": [{"class": "cup", "count": 1}], "prompt": "a photo of a cup"}
|
| 11 |
+
{"tag": "single_object", "include": [{"class": "microwave", "count": 1}], "prompt": "a photo of a microwave"}
|
| 12 |
+
{"tag": "single_object", "include": [{"class": "potted plant", "count": 1}], "prompt": "a photo of a potted plant"}
|
| 13 |
+
{"tag": "single_object", "include": [{"class": "snowboard", "count": 1}], "prompt": "a photo of a snowboard"}
|
| 14 |
+
{"tag": "single_object", "include": [{"class": "zebra", "count": 1}], "prompt": "a photo of a zebra"}
|
| 15 |
+
{"tag": "single_object", "include": [{"class": "parking meter", "count": 1}], "prompt": "a photo of a parking meter"}
|
| 16 |
+
{"tag": "single_object", "include": [{"class": "spoon", "count": 1}], "prompt": "a photo of a spoon"}
|
| 17 |
+
{"tag": "single_object", "include": [{"class": "skateboard", "count": 1}], "prompt": "a photo of a skateboard"}
|
| 18 |
+
{"tag": "single_object", "include": [{"class": "car", "count": 1}], "prompt": "a photo of a car"}
|
| 19 |
+
{"tag": "single_object", "include": [{"class": "motorcycle", "count": 1}], "prompt": "a photo of a motorcycle"}
|
| 20 |
+
{"tag": "single_object", "include": [{"class": "traffic light", "count": 1}], "prompt": "a photo of a traffic light"}
|
| 21 |
+
{"tag": "single_object", "include": [{"class": "book", "count": 1}], "prompt": "a photo of a book"}
|
| 22 |
+
{"tag": "single_object", "include": [{"class": "couch", "count": 1}], "prompt": "a photo of a couch"}
|
| 23 |
+
{"tag": "single_object", "include": [{"class": "backpack", "count": 1}], "prompt": "a photo of a backpack"}
|
| 24 |
+
{"tag": "single_object", "include": [{"class": "computer keyboard", "count": 1}], "prompt": "a photo of a computer keyboard"}
|
| 25 |
+
{"tag": "single_object", "include": [{"class": "toaster", "count": 1}], "prompt": "a photo of a toaster"}
|
| 26 |
+
{"tag": "single_object", "include": [{"class": "bird", "count": 1}], "prompt": "a photo of a bird"}
|
| 27 |
+
{"tag": "single_object", "include": [{"class": "bowl", "count": 1}], "prompt": "a photo of a bowl"}
|
| 28 |
+
{"tag": "single_object", "include": [{"class": "dog", "count": 1}], "prompt": "a photo of a dog"}
|
| 29 |
+
{"tag": "single_object", "include": [{"class": "tie", "count": 1}], "prompt": "a photo of a tie"}
|
| 30 |
+
{"tag": "single_object", "include": [{"class": "laptop", "count": 1}], "prompt": "a photo of a laptop"}
|
| 31 |
+
{"tag": "single_object", "include": [{"class": "computer mouse", "count": 1}], "prompt": "a photo of a computer mouse"}
|
| 32 |
+
{"tag": "single_object", "include": [{"class": "sandwich", "count": 1}], "prompt": "a photo of a sandwich"}
|
| 33 |
+
{"tag": "single_object", "include": [{"class": "baseball bat", "count": 1}], "prompt": "a photo of a baseball bat"}
|
| 34 |
+
{"tag": "single_object", "include": [{"class": "train", "count": 1}], "prompt": "a photo of a train"}
|
| 35 |
+
{"tag": "single_object", "include": [{"class": "cell phone", "count": 1}], "prompt": "a photo of a cell phone"}
|
| 36 |
+
{"tag": "single_object", "include": [{"class": "chair", "count": 1}], "prompt": "a photo of a chair"}
|
| 37 |
+
{"tag": "single_object", "include": [{"class": "tv", "count": 1}], "prompt": "a photo of a tv"}
|
| 38 |
+
{"tag": "single_object", "include": [{"class": "broccoli", "count": 1}], "prompt": "a photo of a broccoli"}
|
| 39 |
+
{"tag": "single_object", "include": [{"class": "bed", "count": 1}], "prompt": "a photo of a bed"}
|
| 40 |
+
{"tag": "single_object", "include": [{"class": "skis", "count": 1}], "prompt": "a photo of a skis"}
|
| 41 |
+
{"tag": "single_object", "include": [{"class": "handbag", "count": 1}], "prompt": "a photo of a handbag"}
|
| 42 |
+
{"tag": "single_object", "include": [{"class": "pizza", "count": 1}], "prompt": "a photo of a pizza"}
|
| 43 |
+
{"tag": "single_object", "include": [{"class": "frisbee", "count": 1}], "prompt": "a photo of a frisbee"}
|
| 44 |
+
{"tag": "single_object", "include": [{"class": "scissors", "count": 1}], "prompt": "a photo of a scissors"}
|
| 45 |
+
{"tag": "single_object", "include": [{"class": "bottle", "count": 1}], "prompt": "a photo of a bottle"}
|
| 46 |
+
{"tag": "single_object", "include": [{"class": "elephant", "count": 1}], "prompt": "a photo of an elephant"}
|
| 47 |
+
{"tag": "single_object", "include": [{"class": "toilet", "count": 1}], "prompt": "a photo of a toilet"}
|
| 48 |
+
{"tag": "single_object", "include": [{"class": "oven", "count": 1}], "prompt": "a photo of an oven"}
|
| 49 |
+
{"tag": "single_object", "include": [{"class": "orange", "count": 1}], "prompt": "a photo of an orange"}
|
| 50 |
+
{"tag": "single_object", "include": [{"class": "person", "count": 1}], "prompt": "a photo of a person"}
|
| 51 |
+
{"tag": "single_object", "include": [{"class": "teddy bear", "count": 1}], "prompt": "a photo of a teddy bear"}
|
| 52 |
+
{"tag": "single_object", "include": [{"class": "vase", "count": 1}], "prompt": "a photo of a vase"}
|
| 53 |
+
{"tag": "single_object", "include": [{"class": "banana", "count": 1}], "prompt": "a photo of a banana"}
|
| 54 |
+
{"tag": "single_object", "include": [{"class": "toothbrush", "count": 1}], "prompt": "a photo of a toothbrush"}
|
| 55 |
+
{"tag": "single_object", "include": [{"class": "tv remote", "count": 1}], "prompt": "a photo of a tv remote"}
|
| 56 |
+
{"tag": "single_object", "include": [{"class": "dining table", "count": 1}], "prompt": "a photo of a dining table"}
|
| 57 |
+
{"tag": "single_object", "include": [{"class": "stop sign", "count": 1}], "prompt": "a photo of a stop sign"}
|
| 58 |
+
{"tag": "single_object", "include": [{"class": "sheep", "count": 1}], "prompt": "a photo of a sheep"}
|
| 59 |
+
{"tag": "single_object", "include": [{"class": "fire hydrant", "count": 1}], "prompt": "a photo of a fire hydrant"}
|
| 60 |
+
{"tag": "single_object", "include": [{"class": "airplane", "count": 1}], "prompt": "a photo of an airplane"}
|
| 61 |
+
{"tag": "single_object", "include": [{"class": "giraffe", "count": 1}], "prompt": "a photo of a giraffe"}
|
| 62 |
+
{"tag": "single_object", "include": [{"class": "horse", "count": 1}], "prompt": "a photo of a horse"}
|
| 63 |
+
{"tag": "single_object", "include": [{"class": "cat", "count": 1}], "prompt": "a photo of a cat"}
|
| 64 |
+
{"tag": "single_object", "include": [{"class": "donut", "count": 1}], "prompt": "a photo of a donut"}
|
| 65 |
+
{"tag": "single_object", "include": [{"class": "boat", "count": 1}], "prompt": "a photo of a boat"}
|
| 66 |
+
{"tag": "single_object", "include": [{"class": "baseball glove", "count": 1}], "prompt": "a photo of a baseball glove"}
|
| 67 |
+
{"tag": "single_object", "include": [{"class": "hair drier", "count": 1}], "prompt": "a photo of a hair drier"}
|
| 68 |
+
{"tag": "single_object", "include": [{"class": "sink", "count": 1}], "prompt": "a photo of a sink"}
|
| 69 |
+
{"tag": "single_object", "include": [{"class": "cake", "count": 1}], "prompt": "a photo of a cake"}
|
| 70 |
+
{"tag": "single_object", "include": [{"class": "wine glass", "count": 1}], "prompt": "a photo of a wine glass"}
|
| 71 |
+
{"tag": "single_object", "include": [{"class": "apple", "count": 1}], "prompt": "a photo of an apple"}
|
| 72 |
+
{"tag": "single_object", "include": [{"class": "bus", "count": 1}], "prompt": "a photo of a bus"}
|
| 73 |
+
{"tag": "single_object", "include": [{"class": "tennis racket", "count": 1}], "prompt": "a photo of a tennis racket"}
|
| 74 |
+
{"tag": "single_object", "include": [{"class": "knife", "count": 1}], "prompt": "a photo of a knife"}
|
| 75 |
+
{"tag": "single_object", "include": [{"class": "hot dog", "count": 1}], "prompt": "a photo of a hot dog"}
|
| 76 |
+
{"tag": "single_object", "include": [{"class": "truck", "count": 1}], "prompt": "a photo of a truck"}
|
| 77 |
+
{"tag": "single_object", "include": [{"class": "umbrella", "count": 1}], "prompt": "a photo of an umbrella"}
|
| 78 |
+
{"tag": "single_object", "include": [{"class": "sports ball", "count": 1}], "prompt": "a photo of a sports ball"}
|
| 79 |
+
{"tag": "single_object", "include": [{"class": "bear", "count": 1}], "prompt": "a photo of a bear"}
|
| 80 |
+
{"tag": "single_object", "include": [{"class": "kite", "count": 1}], "prompt": "a photo of a kite"}
|
| 81 |
+
{"tag": "two_object", "include": [{"class": "bench", "count": 1}, {"class": "sports ball", "count": 1}], "prompt": "a photo of a bench and a sports ball"}
|
| 82 |
+
{"tag": "two_object", "include": [{"class": "toothbrush", "count": 1}, {"class": "snowboard", "count": 1}], "prompt": "a photo of a toothbrush and a snowboard"}
|
| 83 |
+
{"tag": "two_object", "include": [{"class": "toaster", "count": 1}, {"class": "oven", "count": 1}], "prompt": "a photo of a toaster and an oven"}
|
| 84 |
+
{"tag": "two_object", "include": [{"class": "broccoli", "count": 1}, {"class": "vase", "count": 1}], "prompt": "a photo of a broccoli and a vase"}
|
| 85 |
+
{"tag": "two_object", "include": [{"class": "tennis racket", "count": 1}, {"class": "wine glass", "count": 1}], "prompt": "a photo of a tennis racket and a wine glass"}
|
| 86 |
+
{"tag": "two_object", "include": [{"class": "fork", "count": 1}, {"class": "knife", "count": 1}], "prompt": "a photo of a fork and a knife"}
|
| 87 |
+
{"tag": "two_object", "include": [{"class": "hair drier", "count": 1}, {"class": "cake", "count": 1}], "prompt": "a photo of a hair drier and a cake"}
|
| 88 |
+
{"tag": "two_object", "include": [{"class": "horse", "count": 1}, {"class": "giraffe", "count": 1}], "prompt": "a photo of a horse and a giraffe"}
|
| 89 |
+
{"tag": "two_object", "include": [{"class": "horse", "count": 1}, {"class": "computer keyboard", "count": 1}], "prompt": "a photo of a horse and a computer keyboard"}
|
| 90 |
+
{"tag": "two_object", "include": [{"class": "toothbrush", "count": 1}, {"class": "carrot", "count": 1}], "prompt": "a photo of a toothbrush and a carrot"}
|
| 91 |
+
{"tag": "two_object", "include": [{"class": "cake", "count": 1}, {"class": "zebra", "count": 1}], "prompt": "a photo of a cake and a zebra"}
|
| 92 |
+
{"tag": "two_object", "include": [{"class": "hair drier", "count": 1}, {"class": "bear", "count": 1}], "prompt": "a photo of a hair drier and a bear"}
|
| 93 |
+
{"tag": "two_object", "include": [{"class": "knife", "count": 1}, {"class": "zebra", "count": 1}], "prompt": "a photo of a knife and a zebra"}
|
| 94 |
+
{"tag": "two_object", "include": [{"class": "couch", "count": 1}, {"class": "wine glass", "count": 1}], "prompt": "a photo of a couch and a wine glass"}
|
| 95 |
+
{"tag": "two_object", "include": [{"class": "frisbee", "count": 1}, {"class": "vase", "count": 1}], "prompt": "a photo of a frisbee and a vase"}
|
| 96 |
+
{"tag": "two_object", "include": [{"class": "book", "count": 1}, {"class": "laptop", "count": 1}], "prompt": "a photo of a book and a laptop"}
|
| 97 |
+
{"tag": "two_object", "include": [{"class": "dining table", "count": 1}, {"class": "bear", "count": 1}], "prompt": "a photo of a dining table and a bear"}
|
| 98 |
+
{"tag": "two_object", "include": [{"class": "frisbee", "count": 1}, {"class": "couch", "count": 1}], "prompt": "a photo of a frisbee and a couch"}
|
| 99 |
+
{"tag": "two_object", "include": [{"class": "couch", "count": 1}, {"class": "horse", "count": 1}], "prompt": "a photo of a couch and a horse"}
|
| 100 |
+
{"tag": "two_object", "include": [{"class": "toilet", "count": 1}, {"class": "computer mouse", "count": 1}], "prompt": "a photo of a toilet and a computer mouse"}
|
| 101 |
+
{"tag": "two_object", "include": [{"class": "bottle", "count": 1}, {"class": "refrigerator", "count": 1}], "prompt": "a photo of a bottle and a refrigerator"}
|
| 102 |
+
{"tag": "two_object", "include": [{"class": "potted plant", "count": 1}, {"class": "backpack", "count": 1}], "prompt": "a photo of a potted plant and a backpack"}
|
| 103 |
+
{"tag": "two_object", "include": [{"class": "skateboard", "count": 1}, {"class": "cake", "count": 1}], "prompt": "a photo of a skateboard and a cake"}
|
| 104 |
+
{"tag": "two_object", "include": [{"class": "broccoli", "count": 1}, {"class": "parking meter", "count": 1}], "prompt": "a photo of a broccoli and a parking meter"}
|
| 105 |
+
{"tag": "two_object", "include": [{"class": "zebra", "count": 1}, {"class": "bed", "count": 1}], "prompt": "a photo of a zebra and a bed"}
|
| 106 |
+
{"tag": "two_object", "include": [{"class": "oven", "count": 1}, {"class": "bed", "count": 1}], "prompt": "a photo of an oven and a bed"}
|
| 107 |
+
{"tag": "two_object", "include": [{"class": "baseball bat", "count": 1}, {"class": "fork", "count": 1}], "prompt": "a photo of a baseball bat and a fork"}
|
| 108 |
+
{"tag": "two_object", "include": [{"class": "vase", "count": 1}, {"class": "spoon", "count": 1}], "prompt": "a photo of a vase and a spoon"}
|
| 109 |
+
{"tag": "two_object", "include": [{"class": "skateboard", "count": 1}, {"class": "sink", "count": 1}], "prompt": "a photo of a skateboard and a sink"}
|
| 110 |
+
{"tag": "two_object", "include": [{"class": "pizza", "count": 1}, {"class": "bench", "count": 1}], "prompt": "a photo of a pizza and a bench"}
|
| 111 |
+
{"tag": "two_object", "include": [{"class": "bowl", "count": 1}, {"class": "pizza", "count": 1}], "prompt": "a photo of a bowl and a pizza"}
|
| 112 |
+
{"tag": "two_object", "include": [{"class": "tennis racket", "count": 1}, {"class": "bird", "count": 1}], "prompt": "a photo of a tennis racket and a bird"}
|
| 113 |
+
{"tag": "two_object", "include": [{"class": "wine glass", "count": 1}, {"class": "bear", "count": 1}], "prompt": "a photo of a wine glass and a bear"}
|
| 114 |
+
{"tag": "two_object", "include": [{"class": "fork", "count": 1}, {"class": "book", "count": 1}], "prompt": "a photo of a fork and a book"}
|
| 115 |
+
{"tag": "two_object", "include": [{"class": "scissors", "count": 1}, {"class": "bowl", "count": 1}], "prompt": "a photo of a scissors and a bowl"}
|
| 116 |
+
{"tag": "two_object", "include": [{"class": "laptop", "count": 1}, {"class": "carrot", "count": 1}], "prompt": "a photo of a laptop and a carrot"}
|
| 117 |
+
{"tag": "two_object", "include": [{"class": "stop sign", "count": 1}, {"class": "bottle", "count": 1}], "prompt": "a photo of a stop sign and a bottle"}
|
| 118 |
+
{"tag": "two_object", "include": [{"class": "microwave", "count": 1}, {"class": "truck", "count": 1}], "prompt": "a photo of a microwave and a truck"}
|
| 119 |
+
{"tag": "two_object", "include": [{"class": "person", "count": 1}, {"class": "bear", "count": 1}], "prompt": "a photo of a person and a bear"}
|
| 120 |
+
{"tag": "two_object", "include": [{"class": "frisbee", "count": 1}, {"class": "cell phone", "count": 1}], "prompt": "a photo of a frisbee and a cell phone"}
|
| 121 |
+
{"tag": "two_object", "include": [{"class": "parking meter", "count": 1}, {"class": "teddy bear", "count": 1}], "prompt": "a photo of a parking meter and a teddy bear"}
|
| 122 |
+
{"tag": "two_object", "include": [{"class": "tennis racket", "count": 1}, {"class": "bicycle", "count": 1}], "prompt": "a photo of a tennis racket and a bicycle"}
|
| 123 |
+
{"tag": "two_object", "include": [{"class": "stop sign", "count": 1}, {"class": "motorcycle", "count": 1}], "prompt": "a photo of a stop sign and a motorcycle"}
|
| 124 |
+
{"tag": "two_object", "include": [{"class": "fire hydrant", "count": 1}, {"class": "tennis racket", "count": 1}], "prompt": "a photo of a fire hydrant and a tennis racket"}
|
| 125 |
+
{"tag": "two_object", "include": [{"class": "scissors", "count": 1}, {"class": "sandwich", "count": 1}], "prompt": "a photo of a scissors and a sandwich"}
|
| 126 |
+
{"tag": "two_object", "include": [{"class": "pizza", "count": 1}, {"class": "book", "count": 1}], "prompt": "a photo of a pizza and a book"}
|
| 127 |
+
{"tag": "two_object", "include": [{"class": "giraffe", "count": 1}, {"class": "computer mouse", "count": 1}], "prompt": "a photo of a giraffe and a computer mouse"}
|
| 128 |
+
{"tag": "two_object", "include": [{"class": "stop sign", "count": 1}, {"class": "toaster", "count": 1}], "prompt": "a photo of a stop sign and a toaster"}
|
| 129 |
+
{"tag": "two_object", "include": [{"class": "computer mouse", "count": 1}, {"class": "zebra", "count": 1}], "prompt": "a photo of a computer mouse and a zebra"}
|
| 130 |
+
{"tag": "two_object", "include": [{"class": "chair", "count": 1}, {"class": "bench", "count": 1}], "prompt": "a photo of a chair and a bench"}
|
| 131 |
+
{"tag": "two_object", "include": [{"class": "tv", "count": 1}, {"class": "carrot", "count": 1}], "prompt": "a photo of a tv and a carrot"}
|
| 132 |
+
{"tag": "two_object", "include": [{"class": "surfboard", "count": 1}, {"class": "suitcase", "count": 1}], "prompt": "a photo of a surfboard and a suitcase"}
|
| 133 |
+
{"tag": "two_object", "include": [{"class": "computer keyboard", "count": 1}, {"class": "laptop", "count": 1}], "prompt": "a photo of a computer keyboard and a laptop"}
|
| 134 |
+
{"tag": "two_object", "include": [{"class": "computer keyboard", "count": 1}, {"class": "microwave", "count": 1}], "prompt": "a photo of a computer keyboard and a microwave"}
|
| 135 |
+
{"tag": "two_object", "include": [{"class": "scissors", "count": 1}, {"class": "bird", "count": 1}], "prompt": "a photo of a scissors and a bird"}
|
| 136 |
+
{"tag": "two_object", "include": [{"class": "person", "count": 1}, {"class": "snowboard", "count": 1}], "prompt": "a photo of a person and a snowboard"}
|
| 137 |
+
{"tag": "two_object", "include": [{"class": "cow", "count": 1}, {"class": "horse", "count": 1}], "prompt": "a photo of a cow and a horse"}
|
| 138 |
+
{"tag": "two_object", "include": [{"class": "handbag", "count": 1}, {"class": "refrigerator", "count": 1}], "prompt": "a photo of a handbag and a refrigerator"}
|
| 139 |
+
{"tag": "two_object", "include": [{"class": "chair", "count": 1}, {"class": "laptop", "count": 1}], "prompt": "a photo of a chair and a laptop"}
|
| 140 |
+
{"tag": "two_object", "include": [{"class": "toothbrush", "count": 1}, {"class": "bench", "count": 1}], "prompt": "a photo of a toothbrush and a bench"}
|
| 141 |
+
{"tag": "two_object", "include": [{"class": "book", "count": 1}, {"class": "baseball bat", "count": 1}], "prompt": "a photo of a book and a baseball bat"}
|
| 142 |
+
{"tag": "two_object", "include": [{"class": "horse", "count": 1}, {"class": "train", "count": 1}], "prompt": "a photo of a horse and a train"}
|
| 143 |
+
{"tag": "two_object", "include": [{"class": "bench", "count": 1}, {"class": "vase", "count": 1}], "prompt": "a photo of a bench and a vase"}
|
| 144 |
+
{"tag": "two_object", "include": [{"class": "traffic light", "count": 1}, {"class": "backpack", "count": 1}], "prompt": "a photo of a traffic light and a backpack"}
|
| 145 |
+
{"tag": "two_object", "include": [{"class": "sports ball", "count": 1}, {"class": "cow", "count": 1}], "prompt": "a photo of a sports ball and a cow"}
|
| 146 |
+
{"tag": "two_object", "include": [{"class": "computer mouse", "count": 1}, {"class": "spoon", "count": 1}], "prompt": "a photo of a computer mouse and a spoon"}
|
| 147 |
+
{"tag": "two_object", "include": [{"class": "tv", "count": 1}, {"class": "bicycle", "count": 1}], "prompt": "a photo of a tv and a bicycle"}
|
| 148 |
+
{"tag": "two_object", "include": [{"class": "bench", "count": 1}, {"class": "snowboard", "count": 1}], "prompt": "a photo of a bench and a snowboard"}
|
| 149 |
+
{"tag": "two_object", "include": [{"class": "toothbrush", "count": 1}, {"class": "toilet", "count": 1}], "prompt": "a photo of a toothbrush and a toilet"}
|
| 150 |
+
{"tag": "two_object", "include": [{"class": "person", "count": 1}, {"class": "apple", "count": 1}], "prompt": "a photo of a person and an apple"}
|
| 151 |
+
{"tag": "two_object", "include": [{"class": "sink", "count": 1}, {"class": "sports ball", "count": 1}], "prompt": "a photo of a sink and a sports ball"}
|
| 152 |
+
{"tag": "two_object", "include": [{"class": "stop sign", "count": 1}, {"class": "dog", "count": 1}], "prompt": "a photo of a stop sign and a dog"}
|
| 153 |
+
{"tag": "two_object", "include": [{"class": "knife", "count": 1}, {"class": "stop sign", "count": 1}], "prompt": "a photo of a knife and a stop sign"}
|
| 154 |
+
{"tag": "two_object", "include": [{"class": "wine glass", "count": 1}, {"class": "handbag", "count": 1}], "prompt": "a photo of a wine glass and a handbag"}
|
| 155 |
+
{"tag": "two_object", "include": [{"class": "bowl", "count": 1}, {"class": "skis", "count": 1}], "prompt": "a photo of a bowl and a skis"}
|
| 156 |
+
{"tag": "two_object", "include": [{"class": "frisbee", "count": 1}, {"class": "apple", "count": 1}], "prompt": "a photo of a frisbee and an apple"}
|
| 157 |
+
{"tag": "two_object", "include": [{"class": "computer keyboard", "count": 1}, {"class": "cell phone", "count": 1}], "prompt": "a photo of a computer keyboard and a cell phone"}
|
| 158 |
+
{"tag": "two_object", "include": [{"class": "stop sign", "count": 1}, {"class": "fork", "count": 1}], "prompt": "a photo of a stop sign and a fork"}
|
| 159 |
+
{"tag": "two_object", "include": [{"class": "potted plant", "count": 1}, {"class": "boat", "count": 1}], "prompt": "a photo of a potted plant and a boat"}
|
| 160 |
+
{"tag": "two_object", "include": [{"class": "tv", "count": 1}, {"class": "cell phone", "count": 1}], "prompt": "a photo of a tv and a cell phone"}
|
| 161 |
+
{"tag": "two_object", "include": [{"class": "tie", "count": 1}, {"class": "broccoli", "count": 1}], "prompt": "a photo of a tie and a broccoli"}
|
| 162 |
+
{"tag": "two_object", "include": [{"class": "potted plant", "count": 1}, {"class": "donut", "count": 1}], "prompt": "a photo of a potted plant and a donut"}
|
| 163 |
+
{"tag": "two_object", "include": [{"class": "person", "count": 1}, {"class": "sink", "count": 1}], "prompt": "a photo of a person and a sink"}
|
| 164 |
+
{"tag": "two_object", "include": [{"class": "couch", "count": 1}, {"class": "snowboard", "count": 1}], "prompt": "a photo of a couch and a snowboard"}
|
| 165 |
+
{"tag": "two_object", "include": [{"class": "fork", "count": 1}, {"class": "baseball glove", "count": 1}], "prompt": "a photo of a fork and a baseball glove"}
|
| 166 |
+
{"tag": "two_object", "include": [{"class": "apple", "count": 1}, {"class": "toothbrush", "count": 1}], "prompt": "a photo of an apple and a toothbrush"}
|
| 167 |
+
{"tag": "two_object", "include": [{"class": "bus", "count": 1}, {"class": "baseball glove", "count": 1}], "prompt": "a photo of a bus and a baseball glove"}
|
| 168 |
+
{"tag": "two_object", "include": [{"class": "person", "count": 1}, {"class": "stop sign", "count": 1}], "prompt": "a photo of a person and a stop sign"}
|
| 169 |
+
{"tag": "two_object", "include": [{"class": "carrot", "count": 1}, {"class": "couch", "count": 1}], "prompt": "a photo of a carrot and a couch"}
|
| 170 |
+
{"tag": "two_object", "include": [{"class": "baseball bat", "count": 1}, {"class": "bear", "count": 1}], "prompt": "a photo of a baseball bat and a bear"}
|
| 171 |
+
{"tag": "two_object", "include": [{"class": "fire hydrant", "count": 1}, {"class": "train", "count": 1}], "prompt": "a photo of a fire hydrant and a train"}
|
| 172 |
+
{"tag": "two_object", "include": [{"class": "baseball glove", "count": 1}, {"class": "carrot", "count": 1}], "prompt": "a photo of a baseball glove and a carrot"}
|
| 173 |
+
{"tag": "two_object", "include": [{"class": "microwave", "count": 1}, {"class": "bench", "count": 1}], "prompt": "a photo of a microwave and a bench"}
|
| 174 |
+
{"tag": "two_object", "include": [{"class": "cake", "count": 1}, {"class": "stop sign", "count": 1}], "prompt": "a photo of a cake and a stop sign"}
|
| 175 |
+
{"tag": "two_object", "include": [{"class": "car", "count": 1}, {"class": "computer mouse", "count": 1}], "prompt": "a photo of a car and a computer mouse"}
|
| 176 |
+
{"tag": "two_object", "include": [{"class": "suitcase", "count": 1}, {"class": "dining table", "count": 1}], "prompt": "a photo of a suitcase and a dining table"}
|
| 177 |
+
{"tag": "two_object", "include": [{"class": "person", "count": 1}, {"class": "traffic light", "count": 1}], "prompt": "a photo of a person and a traffic light"}
|
| 178 |
+
{"tag": "two_object", "include": [{"class": "cell phone", "count": 1}, {"class": "horse", "count": 1}], "prompt": "a photo of a cell phone and a horse"}
|
| 179 |
+
{"tag": "two_object", "include": [{"class": "baseball bat", "count": 1}, {"class": "giraffe", "count": 1}], "prompt": "a photo of a baseball bat and a giraffe"}
|
| 180 |
+
{"tag": "counting", "include": [{"class": "clock", "count": 2}], "exclude": [{"class": "clock", "count": 3}], "prompt": "a photo of two clocks"}
|
| 181 |
+
{"tag": "counting", "include": [{"class": "backpack", "count": 2}], "exclude": [{"class": "backpack", "count": 3}], "prompt": "a photo of two backpacks"}
|
| 182 |
+
{"tag": "counting", "include": [{"class": "handbag", "count": 4}], "exclude": [{"class": "handbag", "count": 5}], "prompt": "a photo of four handbags"}
|
| 183 |
+
{"tag": "counting", "include": [{"class": "frisbee", "count": 2}], "exclude": [{"class": "frisbee", "count": 3}], "prompt": "a photo of two frisbees"}
|
| 184 |
+
{"tag": "counting", "include": [{"class": "sports ball", "count": 3}], "exclude": [{"class": "sports ball", "count": 4}], "prompt": "a photo of three sports balls"}
|
| 185 |
+
{"tag": "counting", "include": [{"class": "bear", "count": 2}], "exclude": [{"class": "bear", "count": 3}], "prompt": "a photo of two bears"}
|
| 186 |
+
{"tag": "counting", "include": [{"class": "tie", "count": 2}], "exclude": [{"class": "tie", "count": 3}], "prompt": "a photo of two ties"}
|
| 187 |
+
{"tag": "counting", "include": [{"class": "sink", "count": 4}], "exclude": [{"class": "sink", "count": 5}], "prompt": "a photo of four sinks"}
|
| 188 |
+
{"tag": "counting", "include": [{"class": "toothbrush", "count": 2}], "exclude": [{"class": "toothbrush", "count": 3}], "prompt": "a photo of two toothbrushs"}
|
| 189 |
+
{"tag": "counting", "include": [{"class": "person", "count": 3}], "exclude": [{"class": "person", "count": 4}], "prompt": "a photo of three persons"}
|
| 190 |
+
{"tag": "counting", "include": [{"class": "tennis racket", "count": 3}], "exclude": [{"class": "tennis racket", "count": 4}], "prompt": "a photo of three tennis rackets"}
|
| 191 |
+
{"tag": "counting", "include": [{"class": "bowl", "count": 4}], "exclude": [{"class": "bowl", "count": 5}], "prompt": "a photo of four bowls"}
|
| 192 |
+
{"tag": "counting", "include": [{"class": "vase", "count": 4}], "exclude": [{"class": "vase", "count": 5}], "prompt": "a photo of four vases"}
|
| 193 |
+
{"tag": "counting", "include": [{"class": "cup", "count": 3}], "exclude": [{"class": "cup", "count": 4}], "prompt": "a photo of three cups"}
|
| 194 |
+
{"tag": "counting", "include": [{"class": "computer keyboard", "count": 4}], "exclude": [{"class": "computer keyboard", "count": 5}], "prompt": "a photo of four computer keyboards"}
|
| 195 |
+
{"tag": "counting", "include": [{"class": "sink", "count": 3}], "exclude": [{"class": "sink", "count": 4}], "prompt": "a photo of three sinks"}
|
| 196 |
+
{"tag": "counting", "include": [{"class": "oven", "count": 2}], "exclude": [{"class": "oven", "count": 3}], "prompt": "a photo of two ovens"}
|
| 197 |
+
{"tag": "counting", "include": [{"class": "toilet", "count": 2}], "exclude": [{"class": "toilet", "count": 3}], "prompt": "a photo of two toilets"}
|
| 198 |
+
{"tag": "counting", "include": [{"class": "bicycle", "count": 2}], "exclude": [{"class": "bicycle", "count": 3}], "prompt": "a photo of two bicycles"}
|
| 199 |
+
{"tag": "counting", "include": [{"class": "train", "count": 2}], "exclude": [{"class": "train", "count": 3}], "prompt": "a photo of two trains"}
|
| 200 |
+
{"tag": "counting", "include": [{"class": "orange", "count": 3}], "exclude": [{"class": "orange", "count": 4}], "prompt": "a photo of three oranges"}
|
| 201 |
+
{"tag": "counting", "include": [{"class": "bus", "count": 3}], "exclude": [{"class": "bus", "count": 4}], "prompt": "a photo of three buses"}
|
| 202 |
+
{"tag": "counting", "include": [{"class": "handbag", "count": 3}], "exclude": [{"class": "handbag", "count": 4}], "prompt": "a photo of three handbags"}
|
| 203 |
+
{"tag": "counting", "include": [{"class": "snowboard", "count": 3}], "exclude": [{"class": "snowboard", "count": 4}], "prompt": "a photo of three snowboards"}
|
| 204 |
+
{"tag": "counting", "include": [{"class": "snowboard", "count": 2}], "exclude": [{"class": "snowboard", "count": 3}], "prompt": "a photo of two snowboards"}
|
| 205 |
+
{"tag": "counting", "include": [{"class": "dog", "count": 4}], "exclude": [{"class": "dog", "count": 5}], "prompt": "a photo of four dogs"}
|
| 206 |
+
{"tag": "counting", "include": [{"class": "apple", "count": 3}], "exclude": [{"class": "apple", "count": 4}], "prompt": "a photo of three apples"}
|
| 207 |
+
{"tag": "counting", "include": [{"class": "sheep", "count": 2}], "exclude": [{"class": "sheep", "count": 3}], "prompt": "a photo of two sheeps"}
|
| 208 |
+
{"tag": "counting", "include": [{"class": "hot dog", "count": 3}], "exclude": [{"class": "hot dog", "count": 4}], "prompt": "a photo of three hot dogs"}
|
| 209 |
+
{"tag": "counting", "include": [{"class": "zebra", "count": 3}], "exclude": [{"class": "zebra", "count": 4}], "prompt": "a photo of three zebras"}
|
| 210 |
+
{"tag": "counting", "include": [{"class": "kite", "count": 3}], "exclude": [{"class": "kite", "count": 4}], "prompt": "a photo of three kites"}
|
| 211 |
+
{"tag": "counting", "include": [{"class": "apple", "count": 4}], "exclude": [{"class": "apple", "count": 5}], "prompt": "a photo of four apples"}
|
| 212 |
+
{"tag": "counting", "include": [{"class": "cell phone", "count": 3}], "exclude": [{"class": "cell phone", "count": 4}], "prompt": "a photo of three cell phones"}
|
| 213 |
+
{"tag": "counting", "include": [{"class": "baseball glove", "count": 4}], "exclude": [{"class": "baseball glove", "count": 5}], "prompt": "a photo of four baseball gloves"}
|
| 214 |
+
{"tag": "counting", "include": [{"class": "computer keyboard", "count": 3}], "exclude": [{"class": "computer keyboard", "count": 4}], "prompt": "a photo of three computer keyboards"}
|
| 215 |
+
{"tag": "counting", "include": [{"class": "bed", "count": 2}], "exclude": [{"class": "bed", "count": 3}], "prompt": "a photo of two beds"}
|
| 216 |
+
{"tag": "counting", "include": [{"class": "tv remote", "count": 2}], "exclude": [{"class": "tv remote", "count": 3}], "prompt": "a photo of two tv remotes"}
|
| 217 |
+
{"tag": "counting", "include": [{"class": "fire hydrant", "count": 3}], "exclude": [{"class": "fire hydrant", "count": 4}], "prompt": "a photo of three fire hydrants"}
|
| 218 |
+
{"tag": "counting", "include": [{"class": "book", "count": 3}], "exclude": [{"class": "book", "count": 4}], "prompt": "a photo of three books"}
|
| 219 |
+
{"tag": "counting", "include": [{"class": "giraffe", "count": 4}], "exclude": [{"class": "giraffe", "count": 5}], "prompt": "a photo of four giraffes"}
|
| 220 |
+
{"tag": "counting", "include": [{"class": "vase", "count": 2}], "exclude": [{"class": "vase", "count": 3}], "prompt": "a photo of two vases"}
|
| 221 |
+
{"tag": "counting", "include": [{"class": "donut", "count": 4}], "exclude": [{"class": "donut", "count": 5}], "prompt": "a photo of four donuts"}
|
| 222 |
+
{"tag": "counting", "include": [{"class": "chair", "count": 4}], "exclude": [{"class": "chair", "count": 5}], "prompt": "a photo of four chairs"}
|
| 223 |
+
{"tag": "counting", "include": [{"class": "baseball bat", "count": 3}], "exclude": [{"class": "baseball bat", "count": 4}], "prompt": "a photo of three baseball bats"}
|
| 224 |
+
{"tag": "counting", "include": [{"class": "stop sign", "count": 4}], "exclude": [{"class": "stop sign", "count": 5}], "prompt": "a photo of four stop signs"}
|
| 225 |
+
{"tag": "counting", "include": [{"class": "pizza", "count": 2}], "exclude": [{"class": "pizza", "count": 3}], "prompt": "a photo of two pizzas"}
|
| 226 |
+
{"tag": "counting", "include": [{"class": "refrigerator", "count": 3}], "exclude": [{"class": "refrigerator", "count": 4}], "prompt": "a photo of three refrigerators"}
|
| 227 |
+
{"tag": "counting", "include": [{"class": "fire hydrant", "count": 2}], "exclude": [{"class": "fire hydrant", "count": 3}], "prompt": "a photo of two fire hydrants"}
|
| 228 |
+
{"tag": "counting", "include": [{"class": "giraffe", "count": 3}], "exclude": [{"class": "giraffe", "count": 4}], "prompt": "a photo of three giraffes"}
|
| 229 |
+
{"tag": "counting", "include": [{"class": "tv", "count": 4}], "exclude": [{"class": "tv", "count": 5}], "prompt": "a photo of four tvs"}
|
| 230 |
+
{"tag": "counting", "include": [{"class": "wine glass", "count": 3}], "exclude": [{"class": "wine glass", "count": 4}], "prompt": "a photo of three wine glasses"}
|
| 231 |
+
{"tag": "counting", "include": [{"class": "broccoli", "count": 4}], "exclude": [{"class": "broccoli", "count": 5}], "prompt": "a photo of four broccolis"}
|
| 232 |
+
{"tag": "counting", "include": [{"class": "truck", "count": 3}], "exclude": [{"class": "truck", "count": 4}], "prompt": "a photo of three trucks"}
|
| 233 |
+
{"tag": "counting", "include": [{"class": "truck", "count": 2}], "exclude": [{"class": "truck", "count": 3}], "prompt": "a photo of two trucks"}
|
| 234 |
+
{"tag": "counting", "include": [{"class": "carrot", "count": 2}], "exclude": [{"class": "carrot", "count": 3}], "prompt": "a photo of two carrots"}
|
| 235 |
+
{"tag": "counting", "include": [{"class": "sandwich", "count": 2}], "exclude": [{"class": "sandwich", "count": 3}], "prompt": "a photo of two sandwichs"}
|
| 236 |
+
{"tag": "counting", "include": [{"class": "traffic light", "count": 4}], "exclude": [{"class": "traffic light", "count": 5}], "prompt": "a photo of four traffic lights"}
|
| 237 |
+
{"tag": "counting", "include": [{"class": "clock", "count": 4}], "exclude": [{"class": "clock", "count": 5}], "prompt": "a photo of four clocks"}
|
| 238 |
+
{"tag": "counting", "include": [{"class": "car", "count": 2}], "exclude": [{"class": "car", "count": 3}], "prompt": "a photo of two cars"}
|
| 239 |
+
{"tag": "counting", "include": [{"class": "banana", "count": 2}], "exclude": [{"class": "banana", "count": 3}], "prompt": "a photo of two bananas"}
|
| 240 |
+
{"tag": "counting", "include": [{"class": "wine glass", "count": 2}], "exclude": [{"class": "wine glass", "count": 3}], "prompt": "a photo of two wine glasses"}
|
| 241 |
+
{"tag": "counting", "include": [{"class": "pizza", "count": 3}], "exclude": [{"class": "pizza", "count": 4}], "prompt": "a photo of three pizzas"}
|
| 242 |
+
{"tag": "counting", "include": [{"class": "knife", "count": 4}], "exclude": [{"class": "knife", "count": 5}], "prompt": "a photo of four knifes"}
|
| 243 |
+
{"tag": "counting", "include": [{"class": "suitcase", "count": 3}], "exclude": [{"class": "suitcase", "count": 4}], "prompt": "a photo of three suitcases"}
|
| 244 |
+
{"tag": "counting", "include": [{"class": "zebra", "count": 4}], "exclude": [{"class": "zebra", "count": 5}], "prompt": "a photo of four zebras"}
|
| 245 |
+
{"tag": "counting", "include": [{"class": "teddy bear", "count": 2}], "exclude": [{"class": "teddy bear", "count": 3}], "prompt": "a photo of two teddy bears"}
|
| 246 |
+
{"tag": "counting", "include": [{"class": "skateboard", "count": 4}], "exclude": [{"class": "skateboard", "count": 5}], "prompt": "a photo of four skateboards"}
|
| 247 |
+
{"tag": "counting", "include": [{"class": "hot dog", "count": 4}], "exclude": [{"class": "hot dog", "count": 5}], "prompt": "a photo of four hot dogs"}
|
| 248 |
+
{"tag": "counting", "include": [{"class": "bird", "count": 3}], "exclude": [{"class": "bird", "count": 4}], "prompt": "a photo of three birds"}
|
| 249 |
+
{"tag": "counting", "include": [{"class": "boat", "count": 4}], "exclude": [{"class": "boat", "count": 5}], "prompt": "a photo of four boats"}
|
| 250 |
+
{"tag": "counting", "include": [{"class": "microwave", "count": 4}], "exclude": [{"class": "microwave", "count": 5}], "prompt": "a photo of four microwaves"}
|
| 251 |
+
{"tag": "counting", "include": [{"class": "hair drier", "count": 2}], "exclude": [{"class": "hair drier", "count": 3}], "prompt": "a photo of two hair driers"}
|
| 252 |
+
{"tag": "counting", "include": [{"class": "laptop", "count": 3}], "exclude": [{"class": "laptop", "count": 4}], "prompt": "a photo of three laptops"}
|
| 253 |
+
{"tag": "counting", "include": [{"class": "cow", "count": 3}], "exclude": [{"class": "cow", "count": 4}], "prompt": "a photo of three cows"}
|
| 254 |
+
{"tag": "counting", "include": [{"class": "parking meter", "count": 2}], "exclude": [{"class": "parking meter", "count": 3}], "prompt": "a photo of two parking meters"}
|
| 255 |
+
{"tag": "counting", "include": [{"class": "bench", "count": 4}], "exclude": [{"class": "bench", "count": 5}], "prompt": "a photo of four benchs"}
|
| 256 |
+
{"tag": "counting", "include": [{"class": "bench", "count": 3}], "exclude": [{"class": "bench", "count": 4}], "prompt": "a photo of three benchs"}
|
| 257 |
+
{"tag": "counting", "include": [{"class": "frisbee", "count": 4}], "exclude": [{"class": "frisbee", "count": 5}], "prompt": "a photo of four frisbees"}
|
| 258 |
+
{"tag": "counting", "include": [{"class": "book", "count": 4}], "exclude": [{"class": "book", "count": 5}], "prompt": "a photo of four books"}
|
| 259 |
+
{"tag": "counting", "include": [{"class": "bus", "count": 4}], "exclude": [{"class": "bus", "count": 5}], "prompt": "a photo of four buses"}
|
| 260 |
+
{"tag": "colors", "include": [{"class": "fire hydrant", "count": 1, "color": "blue"}], "prompt": "a photo of a blue fire hydrant"}
|
| 261 |
+
{"tag": "colors", "include": [{"class": "car", "count": 1, "color": "pink"}], "prompt": "a photo of a pink car"}
|
| 262 |
+
{"tag": "colors", "include": [{"class": "cup", "count": 1, "color": "purple"}], "prompt": "a photo of a purple cup"}
|
| 263 |
+
{"tag": "colors", "include": [{"class": "cow", "count": 1, "color": "blue"}], "prompt": "a photo of a blue cow"}
|
| 264 |
+
{"tag": "colors", "include": [{"class": "boat", "count": 1, "color": "yellow"}], "prompt": "a photo of a yellow boat"}
|
| 265 |
+
{"tag": "colors", "include": [{"class": "umbrella", "count": 1, "color": "blue"}], "prompt": "a photo of a blue umbrella"}
|
| 266 |
+
{"tag": "colors", "include": [{"class": "elephant", "count": 1, "color": "blue"}], "prompt": "a photo of a blue elephant"}
|
| 267 |
+
{"tag": "colors", "include": [{"class": "elephant", "count": 1, "color": "yellow"}], "prompt": "a photo of a yellow elephant"}
|
| 268 |
+
{"tag": "colors", "include": [{"class": "bicycle", "count": 1, "color": "red"}], "prompt": "a photo of a red bicycle"}
|
| 269 |
+
{"tag": "colors", "include": [{"class": "suitcase", "count": 1, "color": "purple"}], "prompt": "a photo of a purple suitcase"}
|
| 270 |
+
{"tag": "colors", "include": [{"class": "hair drier", "count": 1, "color": "purple"}], "prompt": "a photo of a purple hair drier"}
|
| 271 |
+
{"tag": "colors", "include": [{"class": "sandwich", "count": 1, "color": "white"}], "prompt": "a photo of a white sandwich"}
|
| 272 |
+
{"tag": "colors", "include": [{"class": "elephant", "count": 1, "color": "purple"}], "prompt": "a photo of a purple elephant"}
|
| 273 |
+
{"tag": "colors", "include": [{"class": "microwave", "count": 1, "color": "green"}], "prompt": "a photo of a green microwave"}
|
| 274 |
+
{"tag": "colors", "include": [{"class": "zebra", "count": 1, "color": "red"}], "prompt": "a photo of a red zebra"}
|
| 275 |
+
{"tag": "colors", "include": [{"class": "apple", "count": 1, "color": "red"}], "prompt": "a photo of a red apple"}
|
| 276 |
+
{"tag": "colors", "include": [{"class": "tv remote", "count": 1, "color": "yellow"}], "prompt": "a photo of a yellow tv remote"}
|
| 277 |
+
{"tag": "colors", "include": [{"class": "toilet", "count": 1, "color": "blue"}], "prompt": "a photo of a blue toilet"}
|
| 278 |
+
{"tag": "colors", "include": [{"class": "orange", "count": 1, "color": "orange"}], "prompt": "a photo of an orange orange"}
|
| 279 |
+
{"tag": "colors", "include": [{"class": "donut", "count": 1, "color": "black"}], "prompt": "a photo of a black donut"}
|
| 280 |
+
{"tag": "colors", "include": [{"class": "vase", "count": 1, "color": "red"}], "prompt": "a photo of a red vase"}
|
| 281 |
+
{"tag": "colors", "include": [{"class": "pizza", "count": 1, "color": "purple"}], "prompt": "a photo of a purple pizza"}
|
| 282 |
+
{"tag": "colors", "include": [{"class": "skateboard", "count": 1, "color": "pink"}], "prompt": "a photo of a pink skateboard"}
|
| 283 |
+
{"tag": "colors", "include": [{"class": "skateboard", "count": 1, "color": "green"}], "prompt": "a photo of a green skateboard"}
|
| 284 |
+
{"tag": "colors", "include": [{"class": "bear", "count": 1, "color": "purple"}], "prompt": "a photo of a purple bear"}
|
| 285 |
+
{"tag": "colors", "include": [{"class": "chair", "count": 1, "color": "brown"}], "prompt": "a photo of a brown chair"}
|
| 286 |
+
{"tag": "colors", "include": [{"class": "computer keyboard", "count": 1, "color": "brown"}], "prompt": "a photo of a brown computer keyboard"}
|
| 287 |
+
{"tag": "colors", "include": [{"class": "cow", "count": 1, "color": "orange"}], "prompt": "a photo of an orange cow"}
|
| 288 |
+
{"tag": "colors", "include": [{"class": "skis", "count": 1, "color": "brown"}], "prompt": "a photo of a brown skis"}
|
| 289 |
+
{"tag": "colors", "include": [{"class": "kite", "count": 1, "color": "white"}], "prompt": "a photo of a white kite"}
|
| 290 |
+
{"tag": "colors", "include": [{"class": "dog", "count": 1, "color": "red"}], "prompt": "a photo of a red dog"}
|
| 291 |
+
{"tag": "colors", "include": [{"class": "couch", "count": 1, "color": "green"}], "prompt": "a photo of a green couch"}
|
| 292 |
+
{"tag": "colors", "include": [{"class": "airplane", "count": 1, "color": "yellow"}], "prompt": "a photo of a yellow airplane"}
|
| 293 |
+
{"tag": "colors", "include": [{"class": "tv", "count": 1, "color": "orange"}], "prompt": "a photo of an orange tv"}
|
| 294 |
+
{"tag": "colors", "include": [{"class": "scissors", "count": 1, "color": "white"}], "prompt": "a photo of a white scissors"}
|
| 295 |
+
{"tag": "colors", "include": [{"class": "cell phone", "count": 1, "color": "pink"}], "prompt": "a photo of a pink cell phone"}
|
| 296 |
+
{"tag": "colors", "include": [{"class": "surfboard", "count": 1, "color": "green"}], "prompt": "a photo of a green surfboard"}
|
| 297 |
+
{"tag": "colors", "include": [{"class": "fire hydrant", "count": 1, "color": "white"}], "prompt": "a photo of a white fire hydrant"}
|
| 298 |
+
{"tag": "colors", "include": [{"class": "bicycle", "count": 1, "color": "black"}], "prompt": "a photo of a black bicycle"}
|
| 299 |
+
{"tag": "colors", "include": [{"class": "carrot", "count": 1, "color": "purple"}], "prompt": "a photo of a purple carrot"}
|
| 300 |
+
{"tag": "colors", "include": [{"class": "dining table", "count": 1, "color": "black"}], "prompt": "a photo of a black dining table"}
|
| 301 |
+
{"tag": "colors", "include": [{"class": "potted plant", "count": 1, "color": "purple"}], "prompt": "a photo of a purple potted plant"}
|
| 302 |
+
{"tag": "colors", "include": [{"class": "backpack", "count": 1, "color": "purple"}], "prompt": "a photo of a purple backpack"}
|
| 303 |
+
{"tag": "colors", "include": [{"class": "train", "count": 1, "color": "yellow"}], "prompt": "a photo of a yellow train"}
|
| 304 |
+
{"tag": "colors", "include": [{"class": "potted plant", "count": 1, "color": "pink"}], "prompt": "a photo of a pink potted plant"}
|
| 305 |
+
{"tag": "colors", "include": [{"class": "giraffe", "count": 1, "color": "red"}], "prompt": "a photo of a red giraffe"}
|
| 306 |
+
{"tag": "colors", "include": [{"class": "bear", "count": 1, "color": "brown"}], "prompt": "a photo of a brown bear"}
|
| 307 |
+
{"tag": "colors", "include": [{"class": "train", "count": 1, "color": "black"}], "prompt": "a photo of a black train"}
|
| 308 |
+
{"tag": "colors", "include": [{"class": "laptop", "count": 1, "color": "orange"}], "prompt": "a photo of an orange laptop"}
|
| 309 |
+
{"tag": "colors", "include": [{"class": "hot dog", "count": 1, "color": "green"}], "prompt": "a photo of a green hot dog"}
|
| 310 |
+
{"tag": "colors", "include": [{"class": "parking meter", "count": 1, "color": "yellow"}], "prompt": "a photo of a yellow parking meter"}
|
| 311 |
+
{"tag": "colors", "include": [{"class": "potted plant", "count": 1, "color": "red"}], "prompt": "a photo of a red potted plant"}
|
| 312 |
+
{"tag": "colors", "include": [{"class": "traffic light", "count": 1, "color": "green"}], "prompt": "a photo of a green traffic light"}
|
| 313 |
+
{"tag": "colors", "include": [{"class": "tv", "count": 1, "color": "blue"}], "prompt": "a photo of a blue tv"}
|
| 314 |
+
{"tag": "colors", "include": [{"class": "refrigerator", "count": 1, "color": "brown"}], "prompt": "a photo of a brown refrigerator"}
|
| 315 |
+
{"tag": "colors", "include": [{"class": "tv remote", "count": 1, "color": "black"}], "prompt": "a photo of a black tv remote"}
|
| 316 |
+
{"tag": "colors", "include": [{"class": "scissors", "count": 1, "color": "purple"}], "prompt": "a photo of a purple scissors"}
|
| 317 |
+
{"tag": "colors", "include": [{"class": "orange", "count": 1, "color": "yellow"}], "prompt": "a photo of a yellow orange"}
|
| 318 |
+
{"tag": "colors", "include": [{"class": "toaster", "count": 1, "color": "brown"}], "prompt": "a photo of a brown toaster"}
|
| 319 |
+
{"tag": "colors", "include": [{"class": "parking meter", "count": 1, "color": "red"}], "prompt": "a photo of a red parking meter"}
|
| 320 |
+
{"tag": "colors", "include": [{"class": "orange", "count": 1, "color": "brown"}], "prompt": "a photo of a brown orange"}
|
| 321 |
+
{"tag": "colors", "include": [{"class": "clock", "count": 1, "color": "green"}], "prompt": "a photo of a green clock"}
|
| 322 |
+
{"tag": "colors", "include": [{"class": "sheep", "count": 1, "color": "white"}], "prompt": "a photo of a white sheep"}
|
| 323 |
+
{"tag": "colors", "include": [{"class": "oven", "count": 1, "color": "yellow"}], "prompt": "a photo of a yellow oven"}
|
| 324 |
+
{"tag": "colors", "include": [{"class": "vase", "count": 1, "color": "green"}], "prompt": "a photo of a green vase"}
|
| 325 |
+
{"tag": "colors", "include": [{"class": "teddy bear", "count": 1, "color": "black"}], "prompt": "a photo of a black teddy bear"}
|
| 326 |
+
{"tag": "colors", "include": [{"class": "carrot", "count": 1, "color": "yellow"}], "prompt": "a photo of a yellow carrot"}
|
| 327 |
+
{"tag": "colors", "include": [{"class": "hot dog", "count": 1, "color": "black"}], "prompt": "a photo of a black hot dog"}
|
| 328 |
+
{"tag": "colors", "include": [{"class": "scissors", "count": 1, "color": "red"}], "prompt": "a photo of a red scissors"}
|
| 329 |
+
{"tag": "colors", "include": [{"class": "teddy bear", "count": 1, "color": "white"}], "prompt": "a photo of a white teddy bear"}
|
| 330 |
+
{"tag": "colors", "include": [{"class": "skis", "count": 1, "color": "black"}], "prompt": "a photo of a black skis"}
|
| 331 |
+
{"tag": "colors", "include": [{"class": "dining table", "count": 1, "color": "blue"}], "prompt": "a photo of a blue dining table"}
|
| 332 |
+
{"tag": "colors", "include": [{"class": "refrigerator", "count": 1, "color": "black"}], "prompt": "a photo of a black refrigerator"}
|
| 333 |
+
{"tag": "colors", "include": [{"class": "dog", "count": 1, "color": "white"}], "prompt": "a photo of a white dog"}
|
| 334 |
+
{"tag": "colors", "include": [{"class": "scissors", "count": 1, "color": "orange"}], "prompt": "a photo of an orange scissors"}
|
| 335 |
+
{"tag": "colors", "include": [{"class": "cell phone", "count": 1, "color": "red"}], "prompt": "a photo of a red cell phone"}
|
| 336 |
+
{"tag": "colors", "include": [{"class": "orange", "count": 1, "color": "white"}], "prompt": "a photo of a white orange"}
|
| 337 |
+
{"tag": "colors", "include": [{"class": "clock", "count": 1, "color": "blue"}], "prompt": "a photo of a blue clock"}
|
| 338 |
+
{"tag": "colors", "include": [{"class": "carrot", "count": 1, "color": "blue"}], "prompt": "a photo of a blue carrot"}
|
| 339 |
+
{"tag": "colors", "include": [{"class": "motorcycle", "count": 1, "color": "green"}], "prompt": "a photo of a green motorcycle"}
|
| 340 |
+
{"tag": "colors", "include": [{"class": "stop sign", "count": 1, "color": "pink"}], "prompt": "a photo of a pink stop sign"}
|
| 341 |
+
{"tag": "colors", "include": [{"class": "vase", "count": 1, "color": "black"}], "prompt": "a photo of a black vase"}
|
| 342 |
+
{"tag": "colors", "include": [{"class": "backpack", "count": 1, "color": "black"}], "prompt": "a photo of a black backpack"}
|
| 343 |
+
{"tag": "colors", "include": [{"class": "car", "count": 1, "color": "red"}], "prompt": "a photo of a red car"}
|
| 344 |
+
{"tag": "colors", "include": [{"class": "computer mouse", "count": 1, "color": "green"}], "prompt": "a photo of a green computer mouse"}
|
| 345 |
+
{"tag": "colors", "include": [{"class": "backpack", "count": 1, "color": "red"}], "prompt": "a photo of a red backpack"}
|
| 346 |
+
{"tag": "colors", "include": [{"class": "bus", "count": 1, "color": "green"}], "prompt": "a photo of a green bus"}
|
| 347 |
+
{"tag": "colors", "include": [{"class": "toaster", "count": 1, "color": "orange"}], "prompt": "a photo of an orange toaster"}
|
| 348 |
+
{"tag": "colors", "include": [{"class": "fork", "count": 1, "color": "yellow"}], "prompt": "a photo of a yellow fork"}
|
| 349 |
+
{"tag": "colors", "include": [{"class": "parking meter", "count": 1, "color": "pink"}], "prompt": "a photo of a pink parking meter"}
|
| 350 |
+
{"tag": "colors", "include": [{"class": "book", "count": 1, "color": "blue"}], "prompt": "a photo of a blue book"}
|
| 351 |
+
{"tag": "colors", "include": [{"class": "broccoli", "count": 1, "color": "yellow"}], "prompt": "a photo of a yellow broccoli"}
|
| 352 |
+
{"tag": "colors", "include": [{"class": "computer mouse", "count": 1, "color": "orange"}], "prompt": "a photo of an orange computer mouse"}
|
| 353 |
+
{"tag": "colors", "include": [{"class": "cake", "count": 1, "color": "red"}], "prompt": "a photo of a red cake"}
|
| 354 |
+
{"tag": "position", "include": [{"class": "teddy bear", "count": 1}, {"class": "dog", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a dog right of a teddy bear"}
|
| 355 |
+
{"tag": "position", "include": [{"class": "kite", "count": 1}, {"class": "wine glass", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a wine glass above a kite"}
|
| 356 |
+
{"tag": "position", "include": [{"class": "cup", "count": 1}, {"class": "couch", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a couch below a cup"}
|
| 357 |
+
{"tag": "position", "include": [{"class": "cow", "count": 1}, {"class": "laptop", "count": 1, "position": ["left of", 0]}], "prompt": "a photo of a laptop left of a cow"}
|
| 358 |
+
{"tag": "position", "include": [{"class": "hair drier", "count": 1}, {"class": "fork", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a fork above a hair drier"}
|
| 359 |
+
{"tag": "position", "include": [{"class": "baseball bat", "count": 1}, {"class": "tie", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a tie right of a baseball bat"}
|
| 360 |
+
{"tag": "position", "include": [{"class": "fork", "count": 1}, {"class": "stop sign", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a stop sign above a fork"}
|
| 361 |
+
{"tag": "position", "include": [{"class": "skateboard", "count": 1}, {"class": "bird", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a bird below a skateboard"}
|
| 362 |
+
{"tag": "position", "include": [{"class": "tv", "count": 1}, {"class": "apple", "count": 1, "position": ["above", 0]}], "prompt": "a photo of an apple above a tv"}
|
| 363 |
+
{"tag": "position", "include": [{"class": "potted plant", "count": 1}, {"class": "train", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a train above a potted plant"}
|
| 364 |
+
{"tag": "position", "include": [{"class": "refrigerator", "count": 1}, {"class": "truck", "count": 1, "position": ["left of", 0]}], "prompt": "a photo of a truck left of a refrigerator"}
|
| 365 |
+
{"tag": "position", "include": [{"class": "cow", "count": 1}, {"class": "tv remote", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a tv remote below a cow"}
|
| 366 |
+
{"tag": "position", "include": [{"class": "train", "count": 1}, {"class": "bottle", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a bottle right of a train"}
|
| 367 |
+
{"tag": "position", "include": [{"class": "cow", "count": 1}, {"class": "dog", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a dog above a cow"}
|
| 368 |
+
{"tag": "position", "include": [{"class": "person", "count": 1}, {"class": "skateboard", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a skateboard above a person"}
|
| 369 |
+
{"tag": "position", "include": [{"class": "umbrella", "count": 1}, {"class": "baseball glove", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a baseball glove below an umbrella"}
|
| 370 |
+
{"tag": "position", "include": [{"class": "oven", "count": 1}, {"class": "dining table", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a dining table right of an oven"}
|
| 371 |
+
{"tag": "position", "include": [{"class": "suitcase", "count": 1}, {"class": "hot dog", "count": 1, "position": ["left of", 0]}], "prompt": "a photo of a hot dog left of a suitcase"}
|
| 372 |
+
{"tag": "position", "include": [{"class": "toothbrush", "count": 1}, {"class": "bus", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a bus below a toothbrush"}
|
| 373 |
+
{"tag": "position", "include": [{"class": "sandwich", "count": 1}, {"class": "backpack", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a backpack right of a sandwich"}
|
| 374 |
+
{"tag": "position", "include": [{"class": "baseball bat", "count": 1}, {"class": "cake", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a cake below a baseball bat"}
|
| 375 |
+
{"tag": "position", "include": [{"class": "tie", "count": 1}, {"class": "dog", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a dog right of a tie"}
|
| 376 |
+
{"tag": "position", "include": [{"class": "boat", "count": 1}, {"class": "suitcase", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a suitcase right of a boat"}
|
| 377 |
+
{"tag": "position", "include": [{"class": "clock", "count": 1}, {"class": "bear", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a bear above a clock"}
|
| 378 |
+
{"tag": "position", "include": [{"class": "umbrella", "count": 1}, {"class": "tv remote", "count": 1, "position": ["left of", 0]}], "prompt": "a photo of a tv remote left of an umbrella"}
|
| 379 |
+
{"tag": "position", "include": [{"class": "umbrella", "count": 1}, {"class": "sports ball", "count": 1, "position": ["left of", 0]}], "prompt": "a photo of a sports ball left of an umbrella"}
|
| 380 |
+
{"tag": "position", "include": [{"class": "dining table", "count": 1}, {"class": "train", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a train right of a dining table"}
|
| 381 |
+
{"tag": "position", "include": [{"class": "elephant", "count": 1}, {"class": "hair drier", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a hair drier below an elephant"}
|
| 382 |
+
{"tag": "position", "include": [{"class": "spoon", "count": 1}, {"class": "tennis racket", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a tennis racket right of a spoon"}
|
| 383 |
+
{"tag": "position", "include": [{"class": "hot dog", "count": 1}, {"class": "wine glass", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a wine glass right of a hot dog"}
|
| 384 |
+
{"tag": "position", "include": [{"class": "bench", "count": 1}, {"class": "computer mouse", "count": 1, "position": ["left of", 0]}], "prompt": "a photo of a computer mouse left of a bench"}
|
| 385 |
+
{"tag": "position", "include": [{"class": "orange", "count": 1}, {"class": "carrot", "count": 1, "position": ["left of", 0]}], "prompt": "a photo of a carrot left of an orange"}
|
| 386 |
+
{"tag": "position", "include": [{"class": "toothbrush", "count": 1}, {"class": "kite", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a kite above a toothbrush"}
|
| 387 |
+
{"tag": "position", "include": [{"class": "traffic light", "count": 1}, {"class": "toaster", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a toaster below a traffic light"}
|
| 388 |
+
{"tag": "position", "include": [{"class": "baseball glove", "count": 1}, {"class": "cat", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a cat below a baseball glove"}
|
| 389 |
+
{"tag": "position", "include": [{"class": "zebra", "count": 1}, {"class": "skis", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a skis right of a zebra"}
|
| 390 |
+
{"tag": "position", "include": [{"class": "chair", "count": 1}, {"class": "stop sign", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a stop sign above a chair"}
|
| 391 |
+
{"tag": "position", "include": [{"class": "parking meter", "count": 1}, {"class": "stop sign", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a stop sign above a parking meter"}
|
| 392 |
+
{"tag": "position", "include": [{"class": "skateboard", "count": 1}, {"class": "hot dog", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a hot dog right of a skateboard"}
|
| 393 |
+
{"tag": "position", "include": [{"class": "computer keyboard", "count": 1}, {"class": "pizza", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a pizza below a computer keyboard"}
|
| 394 |
+
{"tag": "position", "include": [{"class": "toilet", "count": 1}, {"class": "hair drier", "count": 1, "position": ["left of", 0]}], "prompt": "a photo of a hair drier left of a toilet"}
|
| 395 |
+
{"tag": "position", "include": [{"class": "stop sign", "count": 1}, {"class": "cow", "count": 1, "position": ["left of", 0]}], "prompt": "a photo of a cow left of a stop sign"}
|
| 396 |
+
{"tag": "position", "include": [{"class": "skis", "count": 1}, {"class": "suitcase", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a suitcase above a skis"}
|
| 397 |
+
{"tag": "position", "include": [{"class": "laptop", "count": 1}, {"class": "book", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a book above a laptop"}
|
| 398 |
+
{"tag": "position", "include": [{"class": "pizza", "count": 1}, {"class": "toothbrush", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a toothbrush below a pizza"}
|
| 399 |
+
{"tag": "position", "include": [{"class": "kite", "count": 1}, {"class": "toilet", "count": 1, "position": ["left of", 0]}], "prompt": "a photo of a toilet left of a kite"}
|
| 400 |
+
{"tag": "position", "include": [{"class": "sink", "count": 1}, {"class": "tie", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a tie above a sink"}
|
| 401 |
+
{"tag": "position", "include": [{"class": "couch", "count": 1}, {"class": "bird", "count": 1, "position": ["left of", 0]}], "prompt": "a photo of a bird left of a couch"}
|
| 402 |
+
{"tag": "position", "include": [{"class": "sports ball", "count": 1}, {"class": "bed", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a bed right of a sports ball"}
|
| 403 |
+
{"tag": "position", "include": [{"class": "surfboard", "count": 1}, {"class": "elephant", "count": 1, "position": ["below", 0]}], "prompt": "a photo of an elephant below a surfboard"}
|
| 404 |
+
{"tag": "position", "include": [{"class": "motorcycle", "count": 1}, {"class": "frisbee", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a frisbee right of a motorcycle"}
|
| 405 |
+
{"tag": "position", "include": [{"class": "fire hydrant", "count": 1}, {"class": "vase", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a vase above a fire hydrant"}
|
| 406 |
+
{"tag": "position", "include": [{"class": "elephant", "count": 1}, {"class": "zebra", "count": 1, "position": ["left of", 0]}], "prompt": "a photo of a zebra left of an elephant"}
|
| 407 |
+
{"tag": "position", "include": [{"class": "bear", "count": 1}, {"class": "bench", "count": 1, "position": ["left of", 0]}], "prompt": "a photo of a bench left of a bear"}
|
| 408 |
+
{"tag": "position", "include": [{"class": "bench", "count": 1}, {"class": "donut", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a donut right of a bench"}
|
| 409 |
+
{"tag": "position", "include": [{"class": "horse", "count": 1}, {"class": "frisbee", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a frisbee below a horse"}
|
| 410 |
+
{"tag": "position", "include": [{"class": "snowboard", "count": 1}, {"class": "computer keyboard", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a computer keyboard above a snowboard"}
|
| 411 |
+
{"tag": "position", "include": [{"class": "cow", "count": 1}, {"class": "tv", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a tv below a cow"}
|
| 412 |
+
{"tag": "position", "include": [{"class": "horse", "count": 1}, {"class": "elephant", "count": 1, "position": ["below", 0]}], "prompt": "a photo of an elephant below a horse"}
|
| 413 |
+
{"tag": "position", "include": [{"class": "banana", "count": 1}, {"class": "suitcase", "count": 1, "position": ["left of", 0]}], "prompt": "a photo of a suitcase left of a banana"}
|
| 414 |
+
{"tag": "position", "include": [{"class": "airplane", "count": 1}, {"class": "train", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a train below an airplane"}
|
| 415 |
+
{"tag": "position", "include": [{"class": "backpack", "count": 1}, {"class": "cat", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a cat below a backpack"}
|
| 416 |
+
{"tag": "position", "include": [{"class": "cake", "count": 1}, {"class": "backpack", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a backpack below a cake"}
|
| 417 |
+
{"tag": "position", "include": [{"class": "knife", "count": 1}, {"class": "sandwich", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a sandwich below a knife"}
|
| 418 |
+
{"tag": "position", "include": [{"class": "parking meter", "count": 1}, {"class": "bicycle", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a bicycle above a parking meter"}
|
| 419 |
+
{"tag": "position", "include": [{"class": "suitcase", "count": 1}, {"class": "knife", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a knife right of a suitcase"}
|
| 420 |
+
{"tag": "position", "include": [{"class": "knife", "count": 1}, {"class": "hot dog", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a hot dog above a knife"}
|
| 421 |
+
{"tag": "position", "include": [{"class": "parking meter", "count": 1}, {"class": "zebra", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a zebra right of a parking meter"}
|
| 422 |
+
{"tag": "position", "include": [{"class": "zebra", "count": 1}, {"class": "chair", "count": 1, "position": ["left of", 0]}], "prompt": "a photo of a chair left of a zebra"}
|
| 423 |
+
{"tag": "position", "include": [{"class": "airplane", "count": 1}, {"class": "cow", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a cow below an airplane"}
|
| 424 |
+
{"tag": "position", "include": [{"class": "umbrella", "count": 1}, {"class": "cup", "count": 1, "position": ["left of", 0]}], "prompt": "a photo of a cup left of an umbrella"}
|
| 425 |
+
{"tag": "position", "include": [{"class": "computer keyboard", "count": 1}, {"class": "zebra", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a zebra below a computer keyboard"}
|
| 426 |
+
{"tag": "position", "include": [{"class": "broccoli", "count": 1}, {"class": "zebra", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a zebra below a broccoli"}
|
| 427 |
+
{"tag": "position", "include": [{"class": "sports ball", "count": 1}, {"class": "laptop", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a laptop below a sports ball"}
|
| 428 |
+
{"tag": "position", "include": [{"class": "baseball bat", "count": 1}, {"class": "truck", "count": 1, "position": ["left of", 0]}], "prompt": "a photo of a truck left of a baseball bat"}
|
| 429 |
+
{"tag": "position", "include": [{"class": "baseball bat", "count": 1}, {"class": "refrigerator", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a refrigerator above a baseball bat"}
|
| 430 |
+
{"tag": "position", "include": [{"class": "baseball bat", "count": 1}, {"class": "tv", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a tv above a baseball bat"}
|
| 431 |
+
{"tag": "position", "include": [{"class": "bear", "count": 1}, {"class": "baseball glove", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a baseball glove right of a bear"}
|
| 432 |
+
{"tag": "position", "include": [{"class": "scissors", "count": 1}, {"class": "refrigerator", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a refrigerator below a scissors"}
|
| 433 |
+
{"tag": "position", "include": [{"class": "suitcase", "count": 1}, {"class": "dining table", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a dining table above a suitcase"}
|
| 434 |
+
{"tag": "position", "include": [{"class": "broccoli", "count": 1}, {"class": "parking meter", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a parking meter above a broccoli"}
|
| 435 |
+
{"tag": "position", "include": [{"class": "truck", "count": 1}, {"class": "frisbee", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a frisbee above a truck"}
|
| 436 |
+
{"tag": "position", "include": [{"class": "banana", "count": 1}, {"class": "pizza", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a pizza right of a banana"}
|
| 437 |
+
{"tag": "position", "include": [{"class": "boat", "count": 1}, {"class": "bus", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a bus above a boat"}
|
| 438 |
+
{"tag": "position", "include": [{"class": "tennis racket", "count": 1}, {"class": "cell phone", "count": 1, "position": ["left of", 0]}], "prompt": "a photo of a cell phone left of a tennis racket"}
|
| 439 |
+
{"tag": "position", "include": [{"class": "broccoli", "count": 1}, {"class": "horse", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a horse right of a broccoli"}
|
| 440 |
+
{"tag": "position", "include": [{"class": "bottle", "count": 1}, {"class": "broccoli", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a broccoli above a bottle"}
|
| 441 |
+
{"tag": "position", "include": [{"class": "horse", "count": 1}, {"class": "vase", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a vase right of a horse"}
|
| 442 |
+
{"tag": "position", "include": [{"class": "spoon", "count": 1}, {"class": "bear", "count": 1, "position": ["above", 0]}], "prompt": "a photo of a bear above a spoon"}
|
| 443 |
+
{"tag": "position", "include": [{"class": "bed", "count": 1}, {"class": "zebra", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a zebra right of a bed"}
|
| 444 |
+
{"tag": "position", "include": [{"class": "laptop", "count": 1}, {"class": "cow", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a cow right of a laptop"}
|
| 445 |
+
{"tag": "position", "include": [{"class": "frisbee", "count": 1}, {"class": "bed", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a bed right of a frisbee"}
|
| 446 |
+
{"tag": "position", "include": [{"class": "motorcycle", "count": 1}, {"class": "tie", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a tie right of a motorcycle"}
|
| 447 |
+
{"tag": "position", "include": [{"class": "tv", "count": 1}, {"class": "laptop", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a laptop right of a tv"}
|
| 448 |
+
{"tag": "position", "include": [{"class": "chair", "count": 1}, {"class": "cell phone", "count": 1, "position": ["right of", 0]}], "prompt": "a photo of a cell phone right of a chair"}
|
| 449 |
+
{"tag": "position", "include": [{"class": "potted plant", "count": 1}, {"class": "couch", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a couch below a potted plant"}
|
| 450 |
+
{"tag": "position", "include": [{"class": "tv", "count": 1}, {"class": "clock", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a clock below a tv"}
|
| 451 |
+
{"tag": "position", "include": [{"class": "vase", "count": 1}, {"class": "couch", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a couch below a vase"}
|
| 452 |
+
{"tag": "position", "include": [{"class": "cat", "count": 1}, {"class": "donut", "count": 1, "position": ["below", 0]}], "prompt": "a photo of a donut below a cat"}
|
| 453 |
+
{"tag": "position", "include": [{"class": "toaster", "count": 1}, {"class": "couch", "count": 1, "position": ["left of", 0]}], "prompt": "a photo of a couch left of a toaster"}
|
| 454 |
+
{"tag": "color_attr", "include": [{"class": "wine glass", "count": 1, "color": "purple"}, {"class": "apple", "count": 1, "color": "black"}], "prompt": "a photo of a purple wine glass and a black apple"}
|
| 455 |
+
{"tag": "color_attr", "include": [{"class": "bus", "count": 1, "color": "green"}, {"class": "microwave", "count": 1, "color": "purple"}], "prompt": "a photo of a green bus and a purple microwave"}
|
| 456 |
+
{"tag": "color_attr", "include": [{"class": "skis", "count": 1, "color": "green"}, {"class": "airplane", "count": 1, "color": "brown"}], "prompt": "a photo of a green skis and a brown airplane"}
|
| 457 |
+
{"tag": "color_attr", "include": [{"class": "computer keyboard", "count": 1, "color": "yellow"}, {"class": "sink", "count": 1, "color": "black"}], "prompt": "a photo of a yellow computer keyboard and a black sink"}
|
| 458 |
+
{"tag": "color_attr", "include": [{"class": "oven", "count": 1, "color": "pink"}, {"class": "motorcycle", "count": 1, "color": "green"}], "prompt": "a photo of a pink oven and a green motorcycle"}
|
| 459 |
+
{"tag": "color_attr", "include": [{"class": "parking meter", "count": 1, "color": "purple"}, {"class": "laptop", "count": 1, "color": "red"}], "prompt": "a photo of a purple parking meter and a red laptop"}
|
| 460 |
+
{"tag": "color_attr", "include": [{"class": "skateboard", "count": 1, "color": "yellow"}, {"class": "computer mouse", "count": 1, "color": "orange"}], "prompt": "a photo of a yellow skateboard and an orange computer mouse"}
|
| 461 |
+
{"tag": "color_attr", "include": [{"class": "skis", "count": 1, "color": "red"}, {"class": "tie", "count": 1, "color": "brown"}], "prompt": "a photo of a red skis and a brown tie"}
|
| 462 |
+
{"tag": "color_attr", "include": [{"class": "skateboard", "count": 1, "color": "pink"}, {"class": "train", "count": 1, "color": "black"}], "prompt": "a photo of a pink skateboard and a black train"}
|
| 463 |
+
{"tag": "color_attr", "include": [{"class": "handbag", "count": 1, "color": "white"}, {"class": "bed", "count": 1, "color": "purple"}], "prompt": "a photo of a white handbag and a purple bed"}
|
| 464 |
+
{"tag": "color_attr", "include": [{"class": "elephant", "count": 1, "color": "purple"}, {"class": "sports ball", "count": 1, "color": "brown"}], "prompt": "a photo of a purple elephant and a brown sports ball"}
|
| 465 |
+
{"tag": "color_attr", "include": [{"class": "dog", "count": 1, "color": "purple"}, {"class": "dining table", "count": 1, "color": "black"}], "prompt": "a photo of a purple dog and a black dining table"}
|
| 466 |
+
{"tag": "color_attr", "include": [{"class": "dining table", "count": 1, "color": "white"}, {"class": "car", "count": 1, "color": "red"}], "prompt": "a photo of a white dining table and a red car"}
|
| 467 |
+
{"tag": "color_attr", "include": [{"class": "cell phone", "count": 1, "color": "blue"}, {"class": "apple", "count": 1, "color": "green"}], "prompt": "a photo of a blue cell phone and a green apple"}
|
| 468 |
+
{"tag": "color_attr", "include": [{"class": "car", "count": 1, "color": "red"}, {"class": "potted plant", "count": 1, "color": "orange"}], "prompt": "a photo of a red car and an orange potted plant"}
|
| 469 |
+
{"tag": "color_attr", "include": [{"class": "carrot", "count": 1, "color": "brown"}, {"class": "potted plant", "count": 1, "color": "white"}], "prompt": "a photo of a brown carrot and a white potted plant"}
|
| 470 |
+
{"tag": "color_attr", "include": [{"class": "kite", "count": 1, "color": "black"}, {"class": "bear", "count": 1, "color": "green"}], "prompt": "a photo of a black kite and a green bear"}
|
| 471 |
+
{"tag": "color_attr", "include": [{"class": "laptop", "count": 1, "color": "blue"}, {"class": "bear", "count": 1, "color": "brown"}], "prompt": "a photo of a blue laptop and a brown bear"}
|
| 472 |
+
{"tag": "color_attr", "include": [{"class": "teddy bear", "count": 1, "color": "green"}, {"class": "kite", "count": 1, "color": "brown"}], "prompt": "a photo of a green teddy bear and a brown kite"}
|
| 473 |
+
{"tag": "color_attr", "include": [{"class": "stop sign", "count": 1, "color": "yellow"}, {"class": "potted plant", "count": 1, "color": "blue"}], "prompt": "a photo of a yellow stop sign and a blue potted plant"}
|
| 474 |
+
{"tag": "color_attr", "include": [{"class": "snowboard", "count": 1, "color": "orange"}, {"class": "cat", "count": 1, "color": "green"}], "prompt": "a photo of an orange snowboard and a green cat"}
|
| 475 |
+
{"tag": "color_attr", "include": [{"class": "truck", "count": 1, "color": "orange"}, {"class": "sink", "count": 1, "color": "pink"}], "prompt": "a photo of an orange truck and a pink sink"}
|
| 476 |
+
{"tag": "color_attr", "include": [{"class": "hot dog", "count": 1, "color": "brown"}, {"class": "pizza", "count": 1, "color": "purple"}], "prompt": "a photo of a brown hot dog and a purple pizza"}
|
| 477 |
+
{"tag": "color_attr", "include": [{"class": "couch", "count": 1, "color": "green"}, {"class": "umbrella", "count": 1, "color": "orange"}], "prompt": "a photo of a green couch and an orange umbrella"}
|
| 478 |
+
{"tag": "color_attr", "include": [{"class": "bed", "count": 1, "color": "brown"}, {"class": "cell phone", "count": 1, "color": "pink"}], "prompt": "a photo of a brown bed and a pink cell phone"}
|
| 479 |
+
{"tag": "color_attr", "include": [{"class": "broccoli", "count": 1, "color": "black"}, {"class": "cake", "count": 1, "color": "yellow"}], "prompt": "a photo of a black broccoli and a yellow cake"}
|
| 480 |
+
{"tag": "color_attr", "include": [{"class": "train", "count": 1, "color": "red"}, {"class": "bear", "count": 1, "color": "purple"}], "prompt": "a photo of a red train and a purple bear"}
|
| 481 |
+
{"tag": "color_attr", "include": [{"class": "tennis racket", "count": 1, "color": "purple"}, {"class": "sink", "count": 1, "color": "black"}], "prompt": "a photo of a purple tennis racket and a black sink"}
|
| 482 |
+
{"tag": "color_attr", "include": [{"class": "vase", "count": 1, "color": "blue"}, {"class": "banana", "count": 1, "color": "black"}], "prompt": "a photo of a blue vase and a black banana"}
|
| 483 |
+
{"tag": "color_attr", "include": [{"class": "clock", "count": 1, "color": "blue"}, {"class": "cup", "count": 1, "color": "white"}], "prompt": "a photo of a blue clock and a white cup"}
|
| 484 |
+
{"tag": "color_attr", "include": [{"class": "umbrella", "count": 1, "color": "red"}, {"class": "couch", "count": 1, "color": "blue"}], "prompt": "a photo of a red umbrella and a blue couch"}
|
| 485 |
+
{"tag": "color_attr", "include": [{"class": "handbag", "count": 1, "color": "white"}, {"class": "giraffe", "count": 1, "color": "red"}], "prompt": "a photo of a white handbag and a red giraffe"}
|
| 486 |
+
{"tag": "color_attr", "include": [{"class": "tv remote", "count": 1, "color": "pink"}, {"class": "airplane", "count": 1, "color": "blue"}], "prompt": "a photo of a pink tv remote and a blue airplane"}
|
| 487 |
+
{"tag": "color_attr", "include": [{"class": "handbag", "count": 1, "color": "pink"}, {"class": "scissors", "count": 1, "color": "black"}], "prompt": "a photo of a pink handbag and a black scissors"}
|
| 488 |
+
{"tag": "color_attr", "include": [{"class": "car", "count": 1, "color": "brown"}, {"class": "hair drier", "count": 1, "color": "pink"}], "prompt": "a photo of a brown car and a pink hair drier"}
|
| 489 |
+
{"tag": "color_attr", "include": [{"class": "bus", "count": 1, "color": "black"}, {"class": "cell phone", "count": 1, "color": "brown"}], "prompt": "a photo of a black bus and a brown cell phone"}
|
| 490 |
+
{"tag": "color_attr", "include": [{"class": "sheep", "count": 1, "color": "purple"}, {"class": "banana", "count": 1, "color": "pink"}], "prompt": "a photo of a purple sheep and a pink banana"}
|
| 491 |
+
{"tag": "color_attr", "include": [{"class": "handbag", "count": 1, "color": "blue"}, {"class": "cell phone", "count": 1, "color": "white"}], "prompt": "a photo of a blue handbag and a white cell phone"}
|
| 492 |
+
{"tag": "color_attr", "include": [{"class": "pizza", "count": 1, "color": "white"}, {"class": "umbrella", "count": 1, "color": "green"}], "prompt": "a photo of a white pizza and a green umbrella"}
|
| 493 |
+
{"tag": "color_attr", "include": [{"class": "tie", "count": 1, "color": "white"}, {"class": "skateboard", "count": 1, "color": "purple"}], "prompt": "a photo of a white tie and a purple skateboard"}
|
| 494 |
+
{"tag": "color_attr", "include": [{"class": "sports ball", "count": 1, "color": "yellow"}, {"class": "boat", "count": 1, "color": "green"}], "prompt": "a photo of a yellow sports ball and a green boat"}
|
| 495 |
+
{"tag": "color_attr", "include": [{"class": "wine glass", "count": 1, "color": "white"}, {"class": "giraffe", "count": 1, "color": "brown"}], "prompt": "a photo of a white wine glass and a brown giraffe"}
|
| 496 |
+
{"tag": "color_attr", "include": [{"class": "bowl", "count": 1, "color": "yellow"}, {"class": "baseball glove", "count": 1, "color": "white"}], "prompt": "a photo of a yellow bowl and a white baseball glove"}
|
| 497 |
+
{"tag": "color_attr", "include": [{"class": "microwave", "count": 1, "color": "orange"}, {"class": "spoon", "count": 1, "color": "black"}], "prompt": "a photo of an orange microwave and a black spoon"}
|
| 498 |
+
{"tag": "color_attr", "include": [{"class": "skateboard", "count": 1, "color": "orange"}, {"class": "bowl", "count": 1, "color": "pink"}], "prompt": "a photo of an orange skateboard and a pink bowl"}
|
| 499 |
+
{"tag": "color_attr", "include": [{"class": "toilet", "count": 1, "color": "blue"}, {"class": "suitcase", "count": 1, "color": "white"}], "prompt": "a photo of a blue toilet and a white suitcase"}
|
| 500 |
+
{"tag": "color_attr", "include": [{"class": "boat", "count": 1, "color": "white"}, {"class": "hot dog", "count": 1, "color": "orange"}], "prompt": "a photo of a white boat and an orange hot dog"}
|
| 501 |
+
{"tag": "color_attr", "include": [{"class": "dining table", "count": 1, "color": "yellow"}, {"class": "dog", "count": 1, "color": "pink"}], "prompt": "a photo of a yellow dining table and a pink dog"}
|
| 502 |
+
{"tag": "color_attr", "include": [{"class": "cake", "count": 1, "color": "red"}, {"class": "chair", "count": 1, "color": "purple"}], "prompt": "a photo of a red cake and a purple chair"}
|
| 503 |
+
{"tag": "color_attr", "include": [{"class": "tie", "count": 1, "color": "blue"}, {"class": "dining table", "count": 1, "color": "pink"}], "prompt": "a photo of a blue tie and a pink dining table"}
|
| 504 |
+
{"tag": "color_attr", "include": [{"class": "cow", "count": 1, "color": "blue"}, {"class": "computer keyboard", "count": 1, "color": "black"}], "prompt": "a photo of a blue cow and a black computer keyboard"}
|
| 505 |
+
{"tag": "color_attr", "include": [{"class": "pizza", "count": 1, "color": "yellow"}, {"class": "oven", "count": 1, "color": "green"}], "prompt": "a photo of a yellow pizza and a green oven"}
|
| 506 |
+
{"tag": "color_attr", "include": [{"class": "laptop", "count": 1, "color": "red"}, {"class": "car", "count": 1, "color": "brown"}], "prompt": "a photo of a red laptop and a brown car"}
|
| 507 |
+
{"tag": "color_attr", "include": [{"class": "computer keyboard", "count": 1, "color": "purple"}, {"class": "scissors", "count": 1, "color": "blue"}], "prompt": "a photo of a purple computer keyboard and a blue scissors"}
|
| 508 |
+
{"tag": "color_attr", "include": [{"class": "surfboard", "count": 1, "color": "green"}, {"class": "oven", "count": 1, "color": "orange"}], "prompt": "a photo of a green surfboard and an orange oven"}
|
| 509 |
+
{"tag": "color_attr", "include": [{"class": "parking meter", "count": 1, "color": "yellow"}, {"class": "refrigerator", "count": 1, "color": "pink"}], "prompt": "a photo of a yellow parking meter and a pink refrigerator"}
|
| 510 |
+
{"tag": "color_attr", "include": [{"class": "computer mouse", "count": 1, "color": "brown"}, {"class": "bottle", "count": 1, "color": "purple"}], "prompt": "a photo of a brown computer mouse and a purple bottle"}
|
| 511 |
+
{"tag": "color_attr", "include": [{"class": "umbrella", "count": 1, "color": "red"}, {"class": "cow", "count": 1, "color": "green"}], "prompt": "a photo of a red umbrella and a green cow"}
|
| 512 |
+
{"tag": "color_attr", "include": [{"class": "giraffe", "count": 1, "color": "red"}, {"class": "cell phone", "count": 1, "color": "black"}], "prompt": "a photo of a red giraffe and a black cell phone"}
|
| 513 |
+
{"tag": "color_attr", "include": [{"class": "oven", "count": 1, "color": "brown"}, {"class": "train", "count": 1, "color": "purple"}], "prompt": "a photo of a brown oven and a purple train"}
|
| 514 |
+
{"tag": "color_attr", "include": [{"class": "baseball bat", "count": 1, "color": "blue"}, {"class": "book", "count": 1, "color": "pink"}], "prompt": "a photo of a blue baseball bat and a pink book"}
|
| 515 |
+
{"tag": "color_attr", "include": [{"class": "cup", "count": 1, "color": "green"}, {"class": "bowl", "count": 1, "color": "yellow"}], "prompt": "a photo of a green cup and a yellow bowl"}
|
| 516 |
+
{"tag": "color_attr", "include": [{"class": "suitcase", "count": 1, "color": "yellow"}, {"class": "bus", "count": 1, "color": "brown"}], "prompt": "a photo of a yellow suitcase and a brown bus"}
|
| 517 |
+
{"tag": "color_attr", "include": [{"class": "motorcycle", "count": 1, "color": "orange"}, {"class": "donut", "count": 1, "color": "pink"}], "prompt": "a photo of an orange motorcycle and a pink donut"}
|
| 518 |
+
{"tag": "color_attr", "include": [{"class": "giraffe", "count": 1, "color": "orange"}, {"class": "baseball glove", "count": 1, "color": "white"}], "prompt": "a photo of an orange giraffe and a white baseball glove"}
|
| 519 |
+
{"tag": "color_attr", "include": [{"class": "handbag", "count": 1, "color": "orange"}, {"class": "carrot", "count": 1, "color": "green"}], "prompt": "a photo of an orange handbag and a green carrot"}
|
| 520 |
+
{"tag": "color_attr", "include": [{"class": "bottle", "count": 1, "color": "black"}, {"class": "refrigerator", "count": 1, "color": "white"}], "prompt": "a photo of a black bottle and a white refrigerator"}
|
| 521 |
+
{"tag": "color_attr", "include": [{"class": "dog", "count": 1, "color": "white"}, {"class": "potted plant", "count": 1, "color": "blue"}], "prompt": "a photo of a white dog and a blue potted plant"}
|
| 522 |
+
{"tag": "color_attr", "include": [{"class": "handbag", "count": 1, "color": "orange"}, {"class": "car", "count": 1, "color": "red"}], "prompt": "a photo of an orange handbag and a red car"}
|
| 523 |
+
{"tag": "color_attr", "include": [{"class": "stop sign", "count": 1, "color": "red"}, {"class": "book", "count": 1, "color": "blue"}], "prompt": "a photo of a red stop sign and a blue book"}
|
| 524 |
+
{"tag": "color_attr", "include": [{"class": "car", "count": 1, "color": "yellow"}, {"class": "toothbrush", "count": 1, "color": "orange"}], "prompt": "a photo of a yellow car and an orange toothbrush"}
|
| 525 |
+
{"tag": "color_attr", "include": [{"class": "potted plant", "count": 1, "color": "black"}, {"class": "toilet", "count": 1, "color": "yellow"}], "prompt": "a photo of a black potted plant and a yellow toilet"}
|
| 526 |
+
{"tag": "color_attr", "include": [{"class": "dining table", "count": 1, "color": "brown"}, {"class": "suitcase", "count": 1, "color": "white"}], "prompt": "a photo of a brown dining table and a white suitcase"}
|
| 527 |
+
{"tag": "color_attr", "include": [{"class": "donut", "count": 1, "color": "orange"}, {"class": "stop sign", "count": 1, "color": "yellow"}], "prompt": "a photo of an orange donut and a yellow stop sign"}
|
| 528 |
+
{"tag": "color_attr", "include": [{"class": "suitcase", "count": 1, "color": "green"}, {"class": "boat", "count": 1, "color": "blue"}], "prompt": "a photo of a green suitcase and a blue boat"}
|
| 529 |
+
{"tag": "color_attr", "include": [{"class": "tennis racket", "count": 1, "color": "orange"}, {"class": "sports ball", "count": 1, "color": "yellow"}], "prompt": "a photo of an orange tennis racket and a yellow sports ball"}
|
| 530 |
+
{"tag": "color_attr", "include": [{"class": "computer keyboard", "count": 1, "color": "purple"}, {"class": "chair", "count": 1, "color": "red"}], "prompt": "a photo of a purple computer keyboard and a red chair"}
|
| 531 |
+
{"tag": "color_attr", "include": [{"class": "suitcase", "count": 1, "color": "purple"}, {"class": "pizza", "count": 1, "color": "orange"}], "prompt": "a photo of a purple suitcase and an orange pizza"}
|
| 532 |
+
{"tag": "color_attr", "include": [{"class": "bottle", "count": 1, "color": "white"}, {"class": "sheep", "count": 1, "color": "blue"}], "prompt": "a photo of a white bottle and a blue sheep"}
|
| 533 |
+
{"tag": "color_attr", "include": [{"class": "backpack", "count": 1, "color": "purple"}, {"class": "umbrella", "count": 1, "color": "white"}], "prompt": "a photo of a purple backpack and a white umbrella"}
|
| 534 |
+
{"tag": "color_attr", "include": [{"class": "potted plant", "count": 1, "color": "orange"}, {"class": "spoon", "count": 1, "color": "black"}], "prompt": "a photo of an orange potted plant and a black spoon"}
|
| 535 |
+
{"tag": "color_attr", "include": [{"class": "tennis racket", "count": 1, "color": "green"}, {"class": "dog", "count": 1, "color": "black"}], "prompt": "a photo of a green tennis racket and a black dog"}
|
| 536 |
+
{"tag": "color_attr", "include": [{"class": "handbag", "count": 1, "color": "yellow"}, {"class": "refrigerator", "count": 1, "color": "blue"}], "prompt": "a photo of a yellow handbag and a blue refrigerator"}
|
| 537 |
+
{"tag": "color_attr", "include": [{"class": "broccoli", "count": 1, "color": "pink"}, {"class": "sink", "count": 1, "color": "red"}], "prompt": "a photo of a pink broccoli and a red sink"}
|
| 538 |
+
{"tag": "color_attr", "include": [{"class": "bowl", "count": 1, "color": "red"}, {"class": "sink", "count": 1, "color": "pink"}], "prompt": "a photo of a red bowl and a pink sink"}
|
| 539 |
+
{"tag": "color_attr", "include": [{"class": "toilet", "count": 1, "color": "white"}, {"class": "apple", "count": 1, "color": "red"}], "prompt": "a photo of a white toilet and a red apple"}
|
| 540 |
+
{"tag": "color_attr", "include": [{"class": "dining table", "count": 1, "color": "pink"}, {"class": "sandwich", "count": 1, "color": "black"}], "prompt": "a photo of a pink dining table and a black sandwich"}
|
| 541 |
+
{"tag": "color_attr", "include": [{"class": "car", "count": 1, "color": "black"}, {"class": "parking meter", "count": 1, "color": "green"}], "prompt": "a photo of a black car and a green parking meter"}
|
| 542 |
+
{"tag": "color_attr", "include": [{"class": "bird", "count": 1, "color": "yellow"}, {"class": "motorcycle", "count": 1, "color": "black"}], "prompt": "a photo of a yellow bird and a black motorcycle"}
|
| 543 |
+
{"tag": "color_attr", "include": [{"class": "giraffe", "count": 1, "color": "brown"}, {"class": "stop sign", "count": 1, "color": "white"}], "prompt": "a photo of a brown giraffe and a white stop sign"}
|
| 544 |
+
{"tag": "color_attr", "include": [{"class": "banana", "count": 1, "color": "white"}, {"class": "elephant", "count": 1, "color": "black"}], "prompt": "a photo of a white banana and a black elephant"}
|
| 545 |
+
{"tag": "color_attr", "include": [{"class": "cow", "count": 1, "color": "orange"}, {"class": "sandwich", "count": 1, "color": "purple"}], "prompt": "a photo of an orange cow and a purple sandwich"}
|
| 546 |
+
{"tag": "color_attr", "include": [{"class": "clock", "count": 1, "color": "red"}, {"class": "cell phone", "count": 1, "color": "black"}], "prompt": "a photo of a red clock and a black cell phone"}
|
| 547 |
+
{"tag": "color_attr", "include": [{"class": "knife", "count": 1, "color": "brown"}, {"class": "donut", "count": 1, "color": "blue"}], "prompt": "a photo of a brown knife and a blue donut"}
|
| 548 |
+
{"tag": "color_attr", "include": [{"class": "cup", "count": 1, "color": "red"}, {"class": "handbag", "count": 1, "color": "pink"}], "prompt": "a photo of a red cup and a pink handbag"}
|
| 549 |
+
{"tag": "color_attr", "include": [{"class": "bicycle", "count": 1, "color": "yellow"}, {"class": "motorcycle", "count": 1, "color": "red"}], "prompt": "a photo of a yellow bicycle and a red motorcycle"}
|
| 550 |
+
{"tag": "color_attr", "include": [{"class": "orange", "count": 1, "color": "red"}, {"class": "broccoli", "count": 1, "color": "purple"}], "prompt": "a photo of a red orange and a purple broccoli"}
|
| 551 |
+
{"tag": "color_attr", "include": [{"class": "traffic light", "count": 1, "color": "orange"}, {"class": "toilet", "count": 1, "color": "white"}], "prompt": "a photo of an orange traffic light and a white toilet"}
|
| 552 |
+
{"tag": "color_attr", "include": [{"class": "cup", "count": 1, "color": "green"}, {"class": "pizza", "count": 1, "color": "red"}], "prompt": "a photo of a green cup and a red pizza"}
|
| 553 |
+
{"tag": "color_attr", "include": [{"class": "pizza", "count": 1, "color": "blue"}, {"class": "baseball glove", "count": 1, "color": "yellow"}], "prompt": "a photo of a blue pizza and a yellow baseball glove"}
|
eval/gen/geneval/prompts/evaluation_metadata_long.jsonl
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
eval/gen/geneval/prompts/generation_prompts.txt
ADDED
|
@@ -0,0 +1,553 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
a photo of a bench
|
| 2 |
+
a photo of a cow
|
| 3 |
+
a photo of a bicycle
|
| 4 |
+
a photo of a clock
|
| 5 |
+
a photo of a carrot
|
| 6 |
+
a photo of a suitcase
|
| 7 |
+
a photo of a fork
|
| 8 |
+
a photo of a surfboard
|
| 9 |
+
a photo of a refrigerator
|
| 10 |
+
a photo of a cup
|
| 11 |
+
a photo of a microwave
|
| 12 |
+
a photo of a potted plant
|
| 13 |
+
a photo of a snowboard
|
| 14 |
+
a photo of a zebra
|
| 15 |
+
a photo of a parking meter
|
| 16 |
+
a photo of a spoon
|
| 17 |
+
a photo of a skateboard
|
| 18 |
+
a photo of a car
|
| 19 |
+
a photo of a motorcycle
|
| 20 |
+
a photo of a traffic light
|
| 21 |
+
a photo of a book
|
| 22 |
+
a photo of a couch
|
| 23 |
+
a photo of a backpack
|
| 24 |
+
a photo of a computer keyboard
|
| 25 |
+
a photo of a toaster
|
| 26 |
+
a photo of a bird
|
| 27 |
+
a photo of a bowl
|
| 28 |
+
a photo of a dog
|
| 29 |
+
a photo of a tie
|
| 30 |
+
a photo of a laptop
|
| 31 |
+
a photo of a computer mouse
|
| 32 |
+
a photo of a sandwich
|
| 33 |
+
a photo of a baseball bat
|
| 34 |
+
a photo of a train
|
| 35 |
+
a photo of a cell phone
|
| 36 |
+
a photo of a chair
|
| 37 |
+
a photo of a tv
|
| 38 |
+
a photo of a broccoli
|
| 39 |
+
a photo of a bed
|
| 40 |
+
a photo of a skis
|
| 41 |
+
a photo of a handbag
|
| 42 |
+
a photo of a pizza
|
| 43 |
+
a photo of a frisbee
|
| 44 |
+
a photo of a scissors
|
| 45 |
+
a photo of a bottle
|
| 46 |
+
a photo of an elephant
|
| 47 |
+
a photo of a toilet
|
| 48 |
+
a photo of an oven
|
| 49 |
+
a photo of an orange
|
| 50 |
+
a photo of a person
|
| 51 |
+
a photo of a teddy bear
|
| 52 |
+
a photo of a vase
|
| 53 |
+
a photo of a banana
|
| 54 |
+
a photo of a toothbrush
|
| 55 |
+
a photo of a tv remote
|
| 56 |
+
a photo of a dining table
|
| 57 |
+
a photo of a stop sign
|
| 58 |
+
a photo of a sheep
|
| 59 |
+
a photo of a fire hydrant
|
| 60 |
+
a photo of an airplane
|
| 61 |
+
a photo of a giraffe
|
| 62 |
+
a photo of a horse
|
| 63 |
+
a photo of a cat
|
| 64 |
+
a photo of a donut
|
| 65 |
+
a photo of a boat
|
| 66 |
+
a photo of a baseball glove
|
| 67 |
+
a photo of a hair drier
|
| 68 |
+
a photo of a sink
|
| 69 |
+
a photo of a cake
|
| 70 |
+
a photo of a wine glass
|
| 71 |
+
a photo of an apple
|
| 72 |
+
a photo of a bus
|
| 73 |
+
a photo of a tennis racket
|
| 74 |
+
a photo of a knife
|
| 75 |
+
a photo of a hot dog
|
| 76 |
+
a photo of a truck
|
| 77 |
+
a photo of an umbrella
|
| 78 |
+
a photo of a sports ball
|
| 79 |
+
a photo of a bear
|
| 80 |
+
a photo of a kite
|
| 81 |
+
a photo of a bench and a sports ball
|
| 82 |
+
a photo of a toothbrush and a snowboard
|
| 83 |
+
a photo of a toaster and an oven
|
| 84 |
+
a photo of a broccoli and a vase
|
| 85 |
+
a photo of a tennis racket and a wine glass
|
| 86 |
+
a photo of a fork and a knife
|
| 87 |
+
a photo of a hair drier and a cake
|
| 88 |
+
a photo of a horse and a giraffe
|
| 89 |
+
a photo of a horse and a computer keyboard
|
| 90 |
+
a photo of a toothbrush and a carrot
|
| 91 |
+
a photo of a cake and a zebra
|
| 92 |
+
a photo of a hair drier and a bear
|
| 93 |
+
a photo of a knife and a zebra
|
| 94 |
+
a photo of a couch and a wine glass
|
| 95 |
+
a photo of a frisbee and a vase
|
| 96 |
+
a photo of a book and a laptop
|
| 97 |
+
a photo of a dining table and a bear
|
| 98 |
+
a photo of a frisbee and a couch
|
| 99 |
+
a photo of a couch and a horse
|
| 100 |
+
a photo of a toilet and a computer mouse
|
| 101 |
+
a photo of a bottle and a refrigerator
|
| 102 |
+
a photo of a potted plant and a backpack
|
| 103 |
+
a photo of a skateboard and a cake
|
| 104 |
+
a photo of a broccoli and a parking meter
|
| 105 |
+
a photo of a zebra and a bed
|
| 106 |
+
a photo of an oven and a bed
|
| 107 |
+
a photo of a baseball bat and a fork
|
| 108 |
+
a photo of a vase and a spoon
|
| 109 |
+
a photo of a skateboard and a sink
|
| 110 |
+
a photo of a pizza and a bench
|
| 111 |
+
a photo of a bowl and a pizza
|
| 112 |
+
a photo of a tennis racket and a bird
|
| 113 |
+
a photo of a wine glass and a bear
|
| 114 |
+
a photo of a fork and a book
|
| 115 |
+
a photo of a scissors and a bowl
|
| 116 |
+
a photo of a laptop and a carrot
|
| 117 |
+
a photo of a stop sign and a bottle
|
| 118 |
+
a photo of a microwave and a truck
|
| 119 |
+
a photo of a person and a bear
|
| 120 |
+
a photo of a frisbee and a cell phone
|
| 121 |
+
a photo of a parking meter and a teddy bear
|
| 122 |
+
a photo of a tennis racket and a bicycle
|
| 123 |
+
a photo of a stop sign and a motorcycle
|
| 124 |
+
a photo of a fire hydrant and a tennis racket
|
| 125 |
+
a photo of a scissors and a sandwich
|
| 126 |
+
a photo of a pizza and a book
|
| 127 |
+
a photo of a giraffe and a computer mouse
|
| 128 |
+
a photo of a stop sign and a toaster
|
| 129 |
+
a photo of a computer mouse and a zebra
|
| 130 |
+
a photo of a chair and a bench
|
| 131 |
+
a photo of a tv and a carrot
|
| 132 |
+
a photo of a surfboard and a suitcase
|
| 133 |
+
a photo of a computer keyboard and a laptop
|
| 134 |
+
a photo of a computer keyboard and a microwave
|
| 135 |
+
a photo of a scissors and a bird
|
| 136 |
+
a photo of a person and a snowboard
|
| 137 |
+
a photo of a cow and a horse
|
| 138 |
+
a photo of a handbag and a refrigerator
|
| 139 |
+
a photo of a chair and a laptop
|
| 140 |
+
a photo of a toothbrush and a bench
|
| 141 |
+
a photo of a book and a baseball bat
|
| 142 |
+
a photo of a horse and a train
|
| 143 |
+
a photo of a bench and a vase
|
| 144 |
+
a photo of a traffic light and a backpack
|
| 145 |
+
a photo of a sports ball and a cow
|
| 146 |
+
a photo of a computer mouse and a spoon
|
| 147 |
+
a photo of a tv and a bicycle
|
| 148 |
+
a photo of a bench and a snowboard
|
| 149 |
+
a photo of a toothbrush and a toilet
|
| 150 |
+
a photo of a person and an apple
|
| 151 |
+
a photo of a sink and a sports ball
|
| 152 |
+
a photo of a stop sign and a dog
|
| 153 |
+
a photo of a knife and a stop sign
|
| 154 |
+
a photo of a wine glass and a handbag
|
| 155 |
+
a photo of a bowl and a skis
|
| 156 |
+
a photo of a frisbee and an apple
|
| 157 |
+
a photo of a computer keyboard and a cell phone
|
| 158 |
+
a photo of a stop sign and a fork
|
| 159 |
+
a photo of a potted plant and a boat
|
| 160 |
+
a photo of a tv and a cell phone
|
| 161 |
+
a photo of a tie and a broccoli
|
| 162 |
+
a photo of a potted plant and a donut
|
| 163 |
+
a photo of a person and a sink
|
| 164 |
+
a photo of a couch and a snowboard
|
| 165 |
+
a photo of a fork and a baseball glove
|
| 166 |
+
a photo of an apple and a toothbrush
|
| 167 |
+
a photo of a bus and a baseball glove
|
| 168 |
+
a photo of a person and a stop sign
|
| 169 |
+
a photo of a carrot and a couch
|
| 170 |
+
a photo of a baseball bat and a bear
|
| 171 |
+
a photo of a fire hydrant and a train
|
| 172 |
+
a photo of a baseball glove and a carrot
|
| 173 |
+
a photo of a microwave and a bench
|
| 174 |
+
a photo of a cake and a stop sign
|
| 175 |
+
a photo of a car and a computer mouse
|
| 176 |
+
a photo of a suitcase and a dining table
|
| 177 |
+
a photo of a person and a traffic light
|
| 178 |
+
a photo of a cell phone and a horse
|
| 179 |
+
a photo of a baseball bat and a giraffe
|
| 180 |
+
a photo of two clocks
|
| 181 |
+
a photo of two backpacks
|
| 182 |
+
a photo of four handbags
|
| 183 |
+
a photo of two frisbees
|
| 184 |
+
a photo of three sports balls
|
| 185 |
+
a photo of two bears
|
| 186 |
+
a photo of two ties
|
| 187 |
+
a photo of four sinks
|
| 188 |
+
a photo of two toothbrushs
|
| 189 |
+
a photo of three persons
|
| 190 |
+
a photo of three tennis rackets
|
| 191 |
+
a photo of four bowls
|
| 192 |
+
a photo of four vases
|
| 193 |
+
a photo of three cups
|
| 194 |
+
a photo of four computer keyboards
|
| 195 |
+
a photo of three sinks
|
| 196 |
+
a photo of two ovens
|
| 197 |
+
a photo of two toilets
|
| 198 |
+
a photo of two bicycles
|
| 199 |
+
a photo of two trains
|
| 200 |
+
a photo of three oranges
|
| 201 |
+
a photo of three buses
|
| 202 |
+
a photo of three handbags
|
| 203 |
+
a photo of three snowboards
|
| 204 |
+
a photo of two snowboards
|
| 205 |
+
a photo of four dogs
|
| 206 |
+
a photo of three apples
|
| 207 |
+
a photo of two sheeps
|
| 208 |
+
a photo of three hot dogs
|
| 209 |
+
a photo of three zebras
|
| 210 |
+
a photo of three kites
|
| 211 |
+
a photo of four apples
|
| 212 |
+
a photo of three cell phones
|
| 213 |
+
a photo of four baseball gloves
|
| 214 |
+
a photo of three computer keyboards
|
| 215 |
+
a photo of two beds
|
| 216 |
+
a photo of two tv remotes
|
| 217 |
+
a photo of three fire hydrants
|
| 218 |
+
a photo of three books
|
| 219 |
+
a photo of four giraffes
|
| 220 |
+
a photo of two vases
|
| 221 |
+
a photo of four donuts
|
| 222 |
+
a photo of four chairs
|
| 223 |
+
a photo of three baseball bats
|
| 224 |
+
a photo of four stop signs
|
| 225 |
+
a photo of two pizzas
|
| 226 |
+
a photo of three refrigerators
|
| 227 |
+
a photo of two fire hydrants
|
| 228 |
+
a photo of three giraffes
|
| 229 |
+
a photo of four tvs
|
| 230 |
+
a photo of three wine glasses
|
| 231 |
+
a photo of four broccolis
|
| 232 |
+
a photo of three trucks
|
| 233 |
+
a photo of two trucks
|
| 234 |
+
a photo of two carrots
|
| 235 |
+
a photo of two sandwichs
|
| 236 |
+
a photo of four traffic lights
|
| 237 |
+
a photo of four clocks
|
| 238 |
+
a photo of two cars
|
| 239 |
+
a photo of two bananas
|
| 240 |
+
a photo of two wine glasses
|
| 241 |
+
a photo of three pizzas
|
| 242 |
+
a photo of four knifes
|
| 243 |
+
a photo of three suitcases
|
| 244 |
+
a photo of four zebras
|
| 245 |
+
a photo of two teddy bears
|
| 246 |
+
a photo of four skateboards
|
| 247 |
+
a photo of four hot dogs
|
| 248 |
+
a photo of three birds
|
| 249 |
+
a photo of four boats
|
| 250 |
+
a photo of four microwaves
|
| 251 |
+
a photo of two hair driers
|
| 252 |
+
a photo of three laptops
|
| 253 |
+
a photo of three cows
|
| 254 |
+
a photo of two parking meters
|
| 255 |
+
a photo of four benchs
|
| 256 |
+
a photo of three benchs
|
| 257 |
+
a photo of four frisbees
|
| 258 |
+
a photo of four books
|
| 259 |
+
a photo of four buses
|
| 260 |
+
a photo of a blue fire hydrant
|
| 261 |
+
a photo of a pink car
|
| 262 |
+
a photo of a purple cup
|
| 263 |
+
a photo of a blue cow
|
| 264 |
+
a photo of a yellow boat
|
| 265 |
+
a photo of a blue umbrella
|
| 266 |
+
a photo of a blue elephant
|
| 267 |
+
a photo of a yellow elephant
|
| 268 |
+
a photo of a red bicycle
|
| 269 |
+
a photo of a purple suitcase
|
| 270 |
+
a photo of a purple hair drier
|
| 271 |
+
a photo of a white sandwich
|
| 272 |
+
a photo of a purple elephant
|
| 273 |
+
a photo of a green microwave
|
| 274 |
+
a photo of a red zebra
|
| 275 |
+
a photo of a red apple
|
| 276 |
+
a photo of a yellow tv remote
|
| 277 |
+
a photo of a blue toilet
|
| 278 |
+
a photo of an orange orange
|
| 279 |
+
a photo of a black donut
|
| 280 |
+
a photo of a red vase
|
| 281 |
+
a photo of a purple pizza
|
| 282 |
+
a photo of a pink skateboard
|
| 283 |
+
a photo of a green skateboard
|
| 284 |
+
a photo of a purple bear
|
| 285 |
+
a photo of a brown chair
|
| 286 |
+
a photo of a brown computer keyboard
|
| 287 |
+
a photo of an orange cow
|
| 288 |
+
a photo of a brown skis
|
| 289 |
+
a photo of a white kite
|
| 290 |
+
a photo of a red dog
|
| 291 |
+
a photo of a green couch
|
| 292 |
+
a photo of a yellow airplane
|
| 293 |
+
a photo of an orange tv
|
| 294 |
+
a photo of a white scissors
|
| 295 |
+
a photo of a pink cell phone
|
| 296 |
+
a photo of a green surfboard
|
| 297 |
+
a photo of a white fire hydrant
|
| 298 |
+
a photo of a black bicycle
|
| 299 |
+
a photo of a purple carrot
|
| 300 |
+
a photo of a black dining table
|
| 301 |
+
a photo of a purple potted plant
|
| 302 |
+
a photo of a purple backpack
|
| 303 |
+
a photo of a yellow train
|
| 304 |
+
a photo of a pink potted plant
|
| 305 |
+
a photo of a red giraffe
|
| 306 |
+
a photo of a brown bear
|
| 307 |
+
a photo of a black train
|
| 308 |
+
a photo of an orange laptop
|
| 309 |
+
a photo of a green hot dog
|
| 310 |
+
a photo of a yellow parking meter
|
| 311 |
+
a photo of a red potted plant
|
| 312 |
+
a photo of a green traffic light
|
| 313 |
+
a photo of a blue tv
|
| 314 |
+
a photo of a brown refrigerator
|
| 315 |
+
a photo of a black tv remote
|
| 316 |
+
a photo of a purple scissors
|
| 317 |
+
a photo of a yellow orange
|
| 318 |
+
a photo of a brown toaster
|
| 319 |
+
a photo of a red parking meter
|
| 320 |
+
a photo of a brown orange
|
| 321 |
+
a photo of a green clock
|
| 322 |
+
a photo of a white sheep
|
| 323 |
+
a photo of a yellow oven
|
| 324 |
+
a photo of a green vase
|
| 325 |
+
a photo of a black teddy bear
|
| 326 |
+
a photo of a yellow carrot
|
| 327 |
+
a photo of a black hot dog
|
| 328 |
+
a photo of a red scissors
|
| 329 |
+
a photo of a white teddy bear
|
| 330 |
+
a photo of a black skis
|
| 331 |
+
a photo of a blue dining table
|
| 332 |
+
a photo of a black refrigerator
|
| 333 |
+
a photo of a white dog
|
| 334 |
+
a photo of an orange scissors
|
| 335 |
+
a photo of a red cell phone
|
| 336 |
+
a photo of a white orange
|
| 337 |
+
a photo of a blue clock
|
| 338 |
+
a photo of a blue carrot
|
| 339 |
+
a photo of a green motorcycle
|
| 340 |
+
a photo of a pink stop sign
|
| 341 |
+
a photo of a black vase
|
| 342 |
+
a photo of a black backpack
|
| 343 |
+
a photo of a red car
|
| 344 |
+
a photo of a green computer mouse
|
| 345 |
+
a photo of a red backpack
|
| 346 |
+
a photo of a green bus
|
| 347 |
+
a photo of an orange toaster
|
| 348 |
+
a photo of a yellow fork
|
| 349 |
+
a photo of a pink parking meter
|
| 350 |
+
a photo of a blue book
|
| 351 |
+
a photo of a yellow broccoli
|
| 352 |
+
a photo of an orange computer mouse
|
| 353 |
+
a photo of a red cake
|
| 354 |
+
a photo of a dog right of a teddy bear
|
| 355 |
+
a photo of a wine glass above a kite
|
| 356 |
+
a photo of a couch below a cup
|
| 357 |
+
a photo of a laptop left of a cow
|
| 358 |
+
a photo of a fork above a hair drier
|
| 359 |
+
a photo of a tie right of a baseball bat
|
| 360 |
+
a photo of a stop sign above a fork
|
| 361 |
+
a photo of a bird below a skateboard
|
| 362 |
+
a photo of an apple above a tv
|
| 363 |
+
a photo of a train above a potted plant
|
| 364 |
+
a photo of a truck left of a refrigerator
|
| 365 |
+
a photo of a tv remote below a cow
|
| 366 |
+
a photo of a bottle right of a train
|
| 367 |
+
a photo of a dog above a cow
|
| 368 |
+
a photo of a skateboard above a person
|
| 369 |
+
a photo of a baseball glove below an umbrella
|
| 370 |
+
a photo of a dining table right of an oven
|
| 371 |
+
a photo of a hot dog left of a suitcase
|
| 372 |
+
a photo of a bus below a toothbrush
|
| 373 |
+
a photo of a backpack right of a sandwich
|
| 374 |
+
a photo of a cake below a baseball bat
|
| 375 |
+
a photo of a dog right of a tie
|
| 376 |
+
a photo of a suitcase right of a boat
|
| 377 |
+
a photo of a bear above a clock
|
| 378 |
+
a photo of a tv remote left of an umbrella
|
| 379 |
+
a photo of a sports ball left of an umbrella
|
| 380 |
+
a photo of a train right of a dining table
|
| 381 |
+
a photo of a hair drier below an elephant
|
| 382 |
+
a photo of a tennis racket right of a spoon
|
| 383 |
+
a photo of a wine glass right of a hot dog
|
| 384 |
+
a photo of a computer mouse left of a bench
|
| 385 |
+
a photo of a carrot left of an orange
|
| 386 |
+
a photo of a kite above a toothbrush
|
| 387 |
+
a photo of a toaster below a traffic light
|
| 388 |
+
a photo of a cat below a baseball glove
|
| 389 |
+
a photo of a skis right of a zebra
|
| 390 |
+
a photo of a stop sign above a chair
|
| 391 |
+
a photo of a stop sign above a parking meter
|
| 392 |
+
a photo of a hot dog right of a skateboard
|
| 393 |
+
a photo of a pizza below a computer keyboard
|
| 394 |
+
a photo of a hair drier left of a toilet
|
| 395 |
+
a photo of a cow left of a stop sign
|
| 396 |
+
a photo of a suitcase above a skis
|
| 397 |
+
a photo of a book above a laptop
|
| 398 |
+
a photo of a toothbrush below a pizza
|
| 399 |
+
a photo of a toilet left of a kite
|
| 400 |
+
a photo of a tie above a sink
|
| 401 |
+
a photo of a bird left of a couch
|
| 402 |
+
a photo of a bed right of a sports ball
|
| 403 |
+
a photo of an elephant below a surfboard
|
| 404 |
+
a photo of a frisbee right of a motorcycle
|
| 405 |
+
a photo of a vase above a fire hydrant
|
| 406 |
+
a photo of a zebra left of an elephant
|
| 407 |
+
a photo of a bench left of a bear
|
| 408 |
+
a photo of a donut right of a bench
|
| 409 |
+
a photo of a frisbee below a horse
|
| 410 |
+
a photo of a computer keyboard above a snowboard
|
| 411 |
+
a photo of a tv below a cow
|
| 412 |
+
a photo of an elephant below a horse
|
| 413 |
+
a photo of a suitcase left of a banana
|
| 414 |
+
a photo of a train below an airplane
|
| 415 |
+
a photo of a cat below a backpack
|
| 416 |
+
a photo of a backpack below a cake
|
| 417 |
+
a photo of a sandwich below a knife
|
| 418 |
+
a photo of a bicycle above a parking meter
|
| 419 |
+
a photo of a knife right of a suitcase
|
| 420 |
+
a photo of a hot dog above a knife
|
| 421 |
+
a photo of a zebra right of a parking meter
|
| 422 |
+
a photo of a chair left of a zebra
|
| 423 |
+
a photo of a cow below an airplane
|
| 424 |
+
a photo of a cup left of an umbrella
|
| 425 |
+
a photo of a zebra below a computer keyboard
|
| 426 |
+
a photo of a zebra below a broccoli
|
| 427 |
+
a photo of a laptop below a sports ball
|
| 428 |
+
a photo of a truck left of a baseball bat
|
| 429 |
+
a photo of a refrigerator above a baseball bat
|
| 430 |
+
a photo of a tv above a baseball bat
|
| 431 |
+
a photo of a baseball glove right of a bear
|
| 432 |
+
a photo of a refrigerator below a scissors
|
| 433 |
+
a photo of a dining table above a suitcase
|
| 434 |
+
a photo of a parking meter above a broccoli
|
| 435 |
+
a photo of a frisbee above a truck
|
| 436 |
+
a photo of a pizza right of a banana
|
| 437 |
+
a photo of a bus above a boat
|
| 438 |
+
a photo of a cell phone left of a tennis racket
|
| 439 |
+
a photo of a horse right of a broccoli
|
| 440 |
+
a photo of a broccoli above a bottle
|
| 441 |
+
a photo of a vase right of a horse
|
| 442 |
+
a photo of a bear above a spoon
|
| 443 |
+
a photo of a zebra right of a bed
|
| 444 |
+
a photo of a cow right of a laptop
|
| 445 |
+
a photo of a bed right of a frisbee
|
| 446 |
+
a photo of a tie right of a motorcycle
|
| 447 |
+
a photo of a laptop right of a tv
|
| 448 |
+
a photo of a cell phone right of a chair
|
| 449 |
+
a photo of a couch below a potted plant
|
| 450 |
+
a photo of a clock below a tv
|
| 451 |
+
a photo of a couch below a vase
|
| 452 |
+
a photo of a donut below a cat
|
| 453 |
+
a photo of a couch left of a toaster
|
| 454 |
+
a photo of a purple wine glass and a black apple
|
| 455 |
+
a photo of a green bus and a purple microwave
|
| 456 |
+
a photo of a green skis and a brown airplane
|
| 457 |
+
a photo of a yellow computer keyboard and a black sink
|
| 458 |
+
a photo of a pink oven and a green motorcycle
|
| 459 |
+
a photo of a purple parking meter and a red laptop
|
| 460 |
+
a photo of a yellow skateboard and an orange computer mouse
|
| 461 |
+
a photo of a red skis and a brown tie
|
| 462 |
+
a photo of a pink skateboard and a black train
|
| 463 |
+
a photo of a white handbag and a purple bed
|
| 464 |
+
a photo of a purple elephant and a brown sports ball
|
| 465 |
+
a photo of a purple dog and a black dining table
|
| 466 |
+
a photo of a white dining table and a red car
|
| 467 |
+
a photo of a blue cell phone and a green apple
|
| 468 |
+
a photo of a red car and an orange potted plant
|
| 469 |
+
a photo of a brown carrot and a white potted plant
|
| 470 |
+
a photo of a black kite and a green bear
|
| 471 |
+
a photo of a blue laptop and a brown bear
|
| 472 |
+
a photo of a green teddy bear and a brown kite
|
| 473 |
+
a photo of a yellow stop sign and a blue potted plant
|
| 474 |
+
a photo of an orange snowboard and a green cat
|
| 475 |
+
a photo of an orange truck and a pink sink
|
| 476 |
+
a photo of a brown hot dog and a purple pizza
|
| 477 |
+
a photo of a green couch and an orange umbrella
|
| 478 |
+
a photo of a brown bed and a pink cell phone
|
| 479 |
+
a photo of a black broccoli and a yellow cake
|
| 480 |
+
a photo of a red train and a purple bear
|
| 481 |
+
a photo of a purple tennis racket and a black sink
|
| 482 |
+
a photo of a blue vase and a black banana
|
| 483 |
+
a photo of a blue clock and a white cup
|
| 484 |
+
a photo of a red umbrella and a blue couch
|
| 485 |
+
a photo of a white handbag and a red giraffe
|
| 486 |
+
a photo of a pink tv remote and a blue airplane
|
| 487 |
+
a photo of a pink handbag and a black scissors
|
| 488 |
+
a photo of a brown car and a pink hair drier
|
| 489 |
+
a photo of a black bus and a brown cell phone
|
| 490 |
+
a photo of a purple sheep and a pink banana
|
| 491 |
+
a photo of a blue handbag and a white cell phone
|
| 492 |
+
a photo of a white pizza and a green umbrella
|
| 493 |
+
a photo of a white tie and a purple skateboard
|
| 494 |
+
a photo of a yellow sports ball and a green boat
|
| 495 |
+
a photo of a white wine glass and a brown giraffe
|
| 496 |
+
a photo of a yellow bowl and a white baseball glove
|
| 497 |
+
a photo of an orange microwave and a black spoon
|
| 498 |
+
a photo of an orange skateboard and a pink bowl
|
| 499 |
+
a photo of a blue toilet and a white suitcase
|
| 500 |
+
a photo of a white boat and an orange hot dog
|
| 501 |
+
a photo of a yellow dining table and a pink dog
|
| 502 |
+
a photo of a red cake and a purple chair
|
| 503 |
+
a photo of a blue tie and a pink dining table
|
| 504 |
+
a photo of a blue cow and a black computer keyboard
|
| 505 |
+
a photo of a yellow pizza and a green oven
|
| 506 |
+
a photo of a red laptop and a brown car
|
| 507 |
+
a photo of a purple computer keyboard and a blue scissors
|
| 508 |
+
a photo of a green surfboard and an orange oven
|
| 509 |
+
a photo of a yellow parking meter and a pink refrigerator
|
| 510 |
+
a photo of a brown computer mouse and a purple bottle
|
| 511 |
+
a photo of a red umbrella and a green cow
|
| 512 |
+
a photo of a red giraffe and a black cell phone
|
| 513 |
+
a photo of a brown oven and a purple train
|
| 514 |
+
a photo of a blue baseball bat and a pink book
|
| 515 |
+
a photo of a green cup and a yellow bowl
|
| 516 |
+
a photo of a yellow suitcase and a brown bus
|
| 517 |
+
a photo of an orange motorcycle and a pink donut
|
| 518 |
+
a photo of an orange giraffe and a white baseball glove
|
| 519 |
+
a photo of an orange handbag and a green carrot
|
| 520 |
+
a photo of a black bottle and a white refrigerator
|
| 521 |
+
a photo of a white dog and a blue potted plant
|
| 522 |
+
a photo of an orange handbag and a red car
|
| 523 |
+
a photo of a red stop sign and a blue book
|
| 524 |
+
a photo of a yellow car and an orange toothbrush
|
| 525 |
+
a photo of a black potted plant and a yellow toilet
|
| 526 |
+
a photo of a brown dining table and a white suitcase
|
| 527 |
+
a photo of an orange donut and a yellow stop sign
|
| 528 |
+
a photo of a green suitcase and a blue boat
|
| 529 |
+
a photo of an orange tennis racket and a yellow sports ball
|
| 530 |
+
a photo of a purple computer keyboard and a red chair
|
| 531 |
+
a photo of a purple suitcase and an orange pizza
|
| 532 |
+
a photo of a white bottle and a blue sheep
|
| 533 |
+
a photo of a purple backpack and a white umbrella
|
| 534 |
+
a photo of an orange potted plant and a black spoon
|
| 535 |
+
a photo of a green tennis racket and a black dog
|
| 536 |
+
a photo of a yellow handbag and a blue refrigerator
|
| 537 |
+
a photo of a pink broccoli and a red sink
|
| 538 |
+
a photo of a red bowl and a pink sink
|
| 539 |
+
a photo of a white toilet and a red apple
|
| 540 |
+
a photo of a pink dining table and a black sandwich
|
| 541 |
+
a photo of a black car and a green parking meter
|
| 542 |
+
a photo of a yellow bird and a black motorcycle
|
| 543 |
+
a photo of a brown giraffe and a white stop sign
|
| 544 |
+
a photo of a white banana and a black elephant
|
| 545 |
+
a photo of an orange cow and a purple sandwich
|
| 546 |
+
a photo of a red clock and a black cell phone
|
| 547 |
+
a photo of a brown knife and a blue donut
|
| 548 |
+
a photo of a red cup and a pink handbag
|
| 549 |
+
a photo of a yellow bicycle and a red motorcycle
|
| 550 |
+
a photo of a red orange and a purple broccoli
|
| 551 |
+
a photo of an orange traffic light and a white toilet
|
| 552 |
+
a photo of a green cup and a red pizza
|
| 553 |
+
a photo of a blue pizza and a yellow baseball glove
|
eval/gen/geneval/prompts/object_names.txt
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
person
|
| 2 |
+
bicycle
|
| 3 |
+
car
|
| 4 |
+
motorcycle
|
| 5 |
+
airplane
|
| 6 |
+
bus
|
| 7 |
+
train
|
| 8 |
+
truck
|
| 9 |
+
boat
|
| 10 |
+
traffic light
|
| 11 |
+
fire hydrant
|
| 12 |
+
stop sign
|
| 13 |
+
parking meter
|
| 14 |
+
bench
|
| 15 |
+
bird
|
| 16 |
+
cat
|
| 17 |
+
dog
|
| 18 |
+
horse
|
| 19 |
+
sheep
|
| 20 |
+
cow
|
| 21 |
+
elephant
|
| 22 |
+
bear
|
| 23 |
+
zebra
|
| 24 |
+
giraffe
|
| 25 |
+
backpack
|
| 26 |
+
umbrella
|
| 27 |
+
handbag
|
| 28 |
+
tie
|
| 29 |
+
suitcase
|
| 30 |
+
frisbee
|
| 31 |
+
skis
|
| 32 |
+
snowboard
|
| 33 |
+
sports ball
|
| 34 |
+
kite
|
| 35 |
+
baseball bat
|
| 36 |
+
baseball glove
|
| 37 |
+
skateboard
|
| 38 |
+
surfboard
|
| 39 |
+
tennis racket
|
| 40 |
+
bottle
|
| 41 |
+
wine glass
|
| 42 |
+
cup
|
| 43 |
+
fork
|
| 44 |
+
knife
|
| 45 |
+
spoon
|
| 46 |
+
bowl
|
| 47 |
+
banana
|
| 48 |
+
apple
|
| 49 |
+
sandwich
|
| 50 |
+
orange
|
| 51 |
+
broccoli
|
| 52 |
+
carrot
|
| 53 |
+
hot dog
|
| 54 |
+
pizza
|
| 55 |
+
donut
|
| 56 |
+
cake
|
| 57 |
+
chair
|
| 58 |
+
couch
|
| 59 |
+
potted plant
|
| 60 |
+
bed
|
| 61 |
+
dining table
|
| 62 |
+
toilet
|
| 63 |
+
tv
|
| 64 |
+
laptop
|
| 65 |
+
computer mouse
|
| 66 |
+
tv remote
|
| 67 |
+
computer keyboard
|
| 68 |
+
cell phone
|
| 69 |
+
microwave
|
| 70 |
+
oven
|
| 71 |
+
toaster
|
| 72 |
+
sink
|
| 73 |
+
refrigerator
|
| 74 |
+
book
|
| 75 |
+
clock
|
| 76 |
+
vase
|
| 77 |
+
scissors
|
| 78 |
+
teddy bear
|
| 79 |
+
hair drier
|
| 80 |
+
toothbrush
|
eval/gen/wise/cal_score.py
ADDED
|
@@ -0,0 +1,162 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2025 Bytedance Ltd. and/or its affiliates.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 3 |
+
|
| 4 |
+
import json
|
| 5 |
+
import os
|
| 6 |
+
import argparse
|
| 7 |
+
from collections import defaultdict
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def calculate_wiscore(consistency, realism, aesthetic_quality):
|
| 11 |
+
return 0.7 * consistency + 0.2 * realism + 0.1 * aesthetic_quality
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def cal_culture(file_path):
|
| 15 |
+
all_scores = []
|
| 16 |
+
total_objects = 0
|
| 17 |
+
has_9_9 = False
|
| 18 |
+
|
| 19 |
+
with open(file_path, 'r') as file:
|
| 20 |
+
for line in file:
|
| 21 |
+
total_objects += 1
|
| 22 |
+
data = json.loads(line)
|
| 23 |
+
if 9.9 in [data['consistency'], data['realism'], data['aesthetic_quality']]:
|
| 24 |
+
has_9_9 = True
|
| 25 |
+
wiscore = calculate_wiscore(data['consistency'], data['realism'], data['aesthetic_quality'])
|
| 26 |
+
all_scores.append(wiscore)
|
| 27 |
+
|
| 28 |
+
if has_9_9 or total_objects < 400:
|
| 29 |
+
print(f"Skipping file {file_path}: Contains 9.9 or has less than 400 objects.")
|
| 30 |
+
return None
|
| 31 |
+
|
| 32 |
+
total_score = sum(all_scores)
|
| 33 |
+
avg_score = total_score / (len(all_scores)*2) if len(all_scores) > 0 else 0
|
| 34 |
+
|
| 35 |
+
score = {
|
| 36 |
+
'total': total_score,
|
| 37 |
+
'average': avg_score
|
| 38 |
+
}
|
| 39 |
+
|
| 40 |
+
print(f" Cultural - Total: {score['total']:.2f}, Average: {score['average']:.2f}")
|
| 41 |
+
|
| 42 |
+
return avg_score
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def cal_space_time(file_path):
|
| 46 |
+
categories = defaultdict(list)
|
| 47 |
+
total_objects = 0
|
| 48 |
+
has_9_9 = False
|
| 49 |
+
|
| 50 |
+
with open(file_path, 'r') as file:
|
| 51 |
+
for line in file:
|
| 52 |
+
total_objects += 1
|
| 53 |
+
data = json.loads(line)
|
| 54 |
+
if 9.9 in [data['consistency'], data['realism'], data['aesthetic_quality']]:
|
| 55 |
+
has_9_9 = True
|
| 56 |
+
subcategory = data['Subcategory']
|
| 57 |
+
wiscore = calculate_wiscore(data['consistency'], data['realism'], data['aesthetic_quality'])
|
| 58 |
+
if subcategory in ['Longitudinal time', 'Horizontal time']:
|
| 59 |
+
categories['Time'].append(wiscore)
|
| 60 |
+
else:
|
| 61 |
+
categories['Space'].append(wiscore)
|
| 62 |
+
|
| 63 |
+
if has_9_9 or total_objects < 300:
|
| 64 |
+
print(f"Skipping file {file_path}: Contains 9.9 or has less than 400 objects.")
|
| 65 |
+
return None
|
| 66 |
+
|
| 67 |
+
total_scores = {category: sum(scores) for category, scores in categories.items()}
|
| 68 |
+
avg_scores = {category: sum(scores) / (len(scores) * 2 )if len(scores) > 0 else 0 for category, scores in categories.items()}
|
| 69 |
+
|
| 70 |
+
scores = {
|
| 71 |
+
'total': total_scores,
|
| 72 |
+
'average': avg_scores
|
| 73 |
+
}
|
| 74 |
+
|
| 75 |
+
print(f" Time - Total: {scores['total'].get('Time', 0):.2f}, Average: {scores['average'].get('Time', 0):.2f}")
|
| 76 |
+
print(f" Space - Total: {scores['total'].get('Space', 0):.2f}, Average: {scores['average'].get('Space', 0):.2f}")
|
| 77 |
+
|
| 78 |
+
return avg_scores
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def cal_science(file_path):
|
| 82 |
+
categories = defaultdict(list)
|
| 83 |
+
total_objects = 0
|
| 84 |
+
has_9_9 = False
|
| 85 |
+
|
| 86 |
+
with open(file_path, 'r') as file:
|
| 87 |
+
for line in file:
|
| 88 |
+
total_objects += 1
|
| 89 |
+
data = json.loads(line)
|
| 90 |
+
if 9.9 in [data['consistency'], data['realism'], data['aesthetic_quality']]:
|
| 91 |
+
has_9_9 = True
|
| 92 |
+
|
| 93 |
+
prompt_id = data.get('prompt_id', 0)
|
| 94 |
+
if 701 <= prompt_id <= 800:
|
| 95 |
+
category = 'Biology'
|
| 96 |
+
elif 801 <= prompt_id <= 900:
|
| 97 |
+
category = 'Physics'
|
| 98 |
+
elif 901 <= prompt_id <= 1000:
|
| 99 |
+
category = 'Chemistry'
|
| 100 |
+
else:
|
| 101 |
+
category = "?"
|
| 102 |
+
|
| 103 |
+
wiscore = calculate_wiscore(data['consistency'], data['realism'], data['aesthetic_quality'])
|
| 104 |
+
categories[category].append(wiscore)
|
| 105 |
+
|
| 106 |
+
if has_9_9 or total_objects < 300:
|
| 107 |
+
print(f"Skipping file {file_path}: Contains 9.9 or has less than 300 objects.")
|
| 108 |
+
return None
|
| 109 |
+
|
| 110 |
+
total_scores = {category: sum(scores) for category, scores in categories.items()}
|
| 111 |
+
avg_scores = {category: sum(scores) / (len(scores)*2) if len(scores) > 0 else 0 for category, scores in categories.items()}
|
| 112 |
+
|
| 113 |
+
scores = {
|
| 114 |
+
'total': total_scores,
|
| 115 |
+
'average': avg_scores
|
| 116 |
+
}
|
| 117 |
+
|
| 118 |
+
for category in ['Biology', 'Physics', 'Chemistry']:
|
| 119 |
+
print(f" {category} - Total: {scores['total'].get(category, 0):.2f}, Average: {scores['average'].get(category, 0):.2f}")
|
| 120 |
+
|
| 121 |
+
return avg_scores
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
if __name__ == "__main__":
|
| 125 |
+
parser = argparse.ArgumentParser(description='Image Quality Assessment Tool')
|
| 126 |
+
parser.add_argument('--output_dir', required=True,
|
| 127 |
+
help='Path to the output directory')
|
| 128 |
+
args = parser.parse_args()
|
| 129 |
+
|
| 130 |
+
avg_score = dict()
|
| 131 |
+
|
| 132 |
+
score = cal_culture(
|
| 133 |
+
os.path.join(args.output_dir, "cultural_common_sense_scores.jsonl")
|
| 134 |
+
)
|
| 135 |
+
avg_score['Cultural'] = score
|
| 136 |
+
|
| 137 |
+
scores = cal_space_time(
|
| 138 |
+
os.path.join(args.output_dir, "spatio-temporal_reasoning_scores.jsonl")
|
| 139 |
+
)
|
| 140 |
+
avg_score.update(scores)
|
| 141 |
+
|
| 142 |
+
scores = cal_science(
|
| 143 |
+
os.path.join(args.output_dir, "natural_science_scores.jsonl")
|
| 144 |
+
)
|
| 145 |
+
avg_score.update(scores)
|
| 146 |
+
|
| 147 |
+
avg_all = sum(avg_score.values()) / len(avg_score)
|
| 148 |
+
|
| 149 |
+
avg_score['Overall'] = avg_all
|
| 150 |
+
keys = ""
|
| 151 |
+
values = ""
|
| 152 |
+
for k, v in avg_score.items():
|
| 153 |
+
keys += f"{k} "
|
| 154 |
+
values += f"{v:.2f} "
|
| 155 |
+
print(keys)
|
| 156 |
+
print(values)
|
| 157 |
+
|
| 158 |
+
writer = open(os.path.join(args.output_dir, "results.txt"), 'w')
|
| 159 |
+
print(f"write results to file {os.path.join(args.output_dir, 'results.txt')}")
|
| 160 |
+
writer.write(keys + "\n")
|
| 161 |
+
writer.write(values + "\n")
|
| 162 |
+
writer.close()
|
eval/gen/wise/final_data.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
eval/gen/wise/gpt_eval_mp.py
ADDED
|
@@ -0,0 +1,268 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2025 Bytedance Ltd. and/or its affiliates.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 3 |
+
|
| 4 |
+
import json
|
| 5 |
+
import os
|
| 6 |
+
import base64
|
| 7 |
+
import re
|
| 8 |
+
import argparse
|
| 9 |
+
import openai
|
| 10 |
+
from pathlib import Path
|
| 11 |
+
from typing import Dict, Any, List
|
| 12 |
+
import concurrent.futures
|
| 13 |
+
|
| 14 |
+
openai.api_key = os.getenv('OPENAI_API_KEY')
|
| 15 |
+
print(openai.api_key)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def parse_arguments():
|
| 19 |
+
parser = argparse.ArgumentParser(description='Image Quality Assessment Tool')
|
| 20 |
+
|
| 21 |
+
parser.add_argument('--json_path', required=True,
|
| 22 |
+
help='Path to the prompts JSON file')
|
| 23 |
+
parser.add_argument('--image_dir', required=True,
|
| 24 |
+
help='Path to the image directory')
|
| 25 |
+
parser.add_argument('--output_dir', required=True,
|
| 26 |
+
help='Path to the output directory')
|
| 27 |
+
|
| 28 |
+
return parser.parse_args()
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def get_config(args):
|
| 32 |
+
filename = args.json_path.split("/")[-1].split(".")[0]
|
| 33 |
+
return {
|
| 34 |
+
"json_path": args.json_path,
|
| 35 |
+
"image_dir": args.image_dir,
|
| 36 |
+
"output_dir": args.output_dir,
|
| 37 |
+
"result_files": {
|
| 38 |
+
"full": f"{filename}_full.jsonl",
|
| 39 |
+
"scores": f"{filename}_scores.jsonl",
|
| 40 |
+
}
|
| 41 |
+
}
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def extract_scores(evaluation_text: str) -> Dict[str, float]:
|
| 45 |
+
score_pattern = r"\*{0,2}(Consistency|Realism|Aesthetic Quality)\*{0,2}\s*[::]?\s*(\d)"
|
| 46 |
+
matches = re.findall(score_pattern, evaluation_text, re.IGNORECASE)
|
| 47 |
+
|
| 48 |
+
scores = {
|
| 49 |
+
"consistency": 9.9,
|
| 50 |
+
"realism": 9.9,
|
| 51 |
+
"aesthetic_quality": 9.9
|
| 52 |
+
}
|
| 53 |
+
|
| 54 |
+
for key, value in matches:
|
| 55 |
+
key = key.lower().replace(" ", "_")
|
| 56 |
+
if key in scores:
|
| 57 |
+
scores[key] = float(value)
|
| 58 |
+
|
| 59 |
+
return scores
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def encode_image(image_path: str) -> str:
|
| 63 |
+
with open(image_path, "rb") as image_file:
|
| 64 |
+
return base64.b64encode(image_file.read()).decode('utf-8')
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def load_prompts(json_path: str) -> Dict[int, Dict[str, Any]]:
|
| 68 |
+
with open(json_path, 'r') as f:
|
| 69 |
+
data = json.load(f)
|
| 70 |
+
return {item["prompt_id"]: item for item in data}
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def build_evaluation_messages(prompt_data: Dict, image_base64: str) -> list:
|
| 74 |
+
return [
|
| 75 |
+
{
|
| 76 |
+
"role": "system",
|
| 77 |
+
"content": [
|
| 78 |
+
{
|
| 79 |
+
"type": "text",
|
| 80 |
+
"text": "You are a professional Vincennes image quality audit expert, please evaluate the image quality strictly according to the protocol."
|
| 81 |
+
}
|
| 82 |
+
]
|
| 83 |
+
},
|
| 84 |
+
{
|
| 85 |
+
"role": "user",
|
| 86 |
+
"content": [
|
| 87 |
+
{
|
| 88 |
+
"type": "text",
|
| 89 |
+
"text": f"""Please evaluate strictly and return ONLY the three scores as requested.
|
| 90 |
+
|
| 91 |
+
# Text-to-Image Quality Evaluation Protocol
|
| 92 |
+
|
| 93 |
+
## System Instruction
|
| 94 |
+
You are an AI quality auditor for text-to-image generation. Apply these rules with ABSOLUTE RUTHLESSNESS. Only images meeting the HIGHEST standards should receive top scores.
|
| 95 |
+
|
| 96 |
+
**Input Parameters**
|
| 97 |
+
- PROMPT: [User's original prompt to]
|
| 98 |
+
- EXPLANATION: [Further explanation of the original prompt]
|
| 99 |
+
---
|
| 100 |
+
|
| 101 |
+
## Scoring Criteria
|
| 102 |
+
|
| 103 |
+
**Consistency (0-2):** How accurately and completely the image reflects the PROMPT.
|
| 104 |
+
* **0 (Rejected):** Fails to capture key elements of the prompt, or contradicts the prompt.
|
| 105 |
+
* **1 (Conditional):** Partially captures the prompt. Some elements are present, but not all, or not accurately. Noticeable deviations from the prompt's intent.
|
| 106 |
+
* **2 (Exemplary):** Perfectly and completely aligns with the PROMPT. Every single element and nuance of the prompt is flawlessly represented in the image. The image is an ideal, unambiguous visual realization of the given prompt.
|
| 107 |
+
|
| 108 |
+
**Realism (0-2):** How realistically the image is rendered.
|
| 109 |
+
* **0 (Rejected):** Physically implausible and clearly artificial. Breaks fundamental laws of physics or visual realism.
|
| 110 |
+
* **1 (Conditional):** Contains minor inconsistencies or unrealistic elements. While somewhat believable, noticeable flaws detract from realism.
|
| 111 |
+
* **2 (Exemplary):** Achieves photorealistic quality, indistinguishable from a real photograph. Flawless adherence to physical laws, accurate material representation, and coherent spatial relationships. No visual cues betraying AI generation.
|
| 112 |
+
|
| 113 |
+
**Aesthetic Quality (0-2):** The overall artistic appeal and visual quality of the image.
|
| 114 |
+
* **0 (Rejected):** Poor aesthetic composition, visually unappealing, and lacks artistic merit.
|
| 115 |
+
* **1 (Conditional):** Demonstrates basic visual appeal, acceptable composition, and color harmony, but lacks distinction or artistic flair.
|
| 116 |
+
* **2 (Exemplary):** Possesses exceptional aesthetic quality, comparable to a masterpiece. Strikingly beautiful, with perfect composition, a harmonious color palette, and a captivating artistic style. Demonstrates a high degree of artistic vision and execution.
|
| 117 |
+
|
| 118 |
+
---
|
| 119 |
+
|
| 120 |
+
## Output Format
|
| 121 |
+
|
| 122 |
+
**Do not include any other text, explanations, or labels.** You must return only three lines of text, each containing a metric and the corresponding score, for example:
|
| 123 |
+
|
| 124 |
+
**Example Output:**
|
| 125 |
+
Consistency: 2
|
| 126 |
+
Realism: 1
|
| 127 |
+
Aesthetic Quality: 0
|
| 128 |
+
|
| 129 |
+
---
|
| 130 |
+
|
| 131 |
+
**IMPORTANT Enforcement:**
|
| 132 |
+
|
| 133 |
+
Be EXTREMELY strict in your evaluation. A score of '2' should be exceedingly rare and reserved only for images that truly excel and meet the highest possible standards in each metric. If there is any doubt, downgrade the score.
|
| 134 |
+
|
| 135 |
+
For **Consistency**, a score of '2' requires complete and flawless adherence to every aspect of the prompt, leaving no room for misinterpretation or omission.
|
| 136 |
+
|
| 137 |
+
For **Realism**, a score of '2' means the image is virtually indistinguishable from a real photograph in terms of detail, lighting, physics, and material properties.
|
| 138 |
+
|
| 139 |
+
For **Aesthetic Quality**, a score of '2' demands exceptional artistic merit, not just pleasant visuals.
|
| 140 |
+
|
| 141 |
+
---
|
| 142 |
+
Here are the Prompt and EXPLANATION for this evaluation:
|
| 143 |
+
PROMPT: "{prompt_data['Prompt']}"
|
| 144 |
+
EXPLANATION: "{prompt_data['Explanation']}"
|
| 145 |
+
Please strictly adhere to the scoring criteria and follow the template format when providing your results."""
|
| 146 |
+
},
|
| 147 |
+
{
|
| 148 |
+
"type": "image_url",
|
| 149 |
+
"image_url": {
|
| 150 |
+
"url": f"data:image/png;base64,{image_base64}"
|
| 151 |
+
}
|
| 152 |
+
}
|
| 153 |
+
]
|
| 154 |
+
}
|
| 155 |
+
]
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
def evaluate_image(prompt_data: Dict, image_path: str, config: Dict) -> Dict[str, Any]:
|
| 159 |
+
try:
|
| 160 |
+
base64_image = encode_image(image_path)
|
| 161 |
+
messages = build_evaluation_messages(prompt_data, base64_image)
|
| 162 |
+
|
| 163 |
+
response = openai_client.chat.completions.create(
|
| 164 |
+
model=model,
|
| 165 |
+
messages=messages,
|
| 166 |
+
temperature=0.0,
|
| 167 |
+
max_tokens=2000,
|
| 168 |
+
n=1,
|
| 169 |
+
)
|
| 170 |
+
response = response.to_dict()
|
| 171 |
+
|
| 172 |
+
evaluation_text = response['choices'][0]['message']['content'].strip()
|
| 173 |
+
scores = extract_scores(evaluation_text)
|
| 174 |
+
|
| 175 |
+
return {
|
| 176 |
+
"evaluation": evaluation_text,
|
| 177 |
+
**scores
|
| 178 |
+
}
|
| 179 |
+
except Exception as e:
|
| 180 |
+
return {
|
| 181 |
+
"evaluation": f"Evaluation failed: {str(e)}",
|
| 182 |
+
"consistency": 9.9,
|
| 183 |
+
"realism": 9.9,
|
| 184 |
+
"aesthetic_quality": 9.9
|
| 185 |
+
}
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
def save_results(data, filename, config):
|
| 189 |
+
path = os.path.join(config["output_dir"], filename)
|
| 190 |
+
|
| 191 |
+
assert filename.endswith('.jsonl')
|
| 192 |
+
with open(path, 'a', encoding='utf-8') as f:
|
| 193 |
+
json_line = json.dumps(data, ensure_ascii=False)
|
| 194 |
+
f.write(json_line + '\n')
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
def process_prompt(prompt_id, prompt_data, config):
|
| 198 |
+
image_path = os.path.join(config["image_dir"], f"{prompt_id}.png")
|
| 199 |
+
|
| 200 |
+
if not os.path.exists(image_path):
|
| 201 |
+
print(f"Warning: Image not found {image_path}")
|
| 202 |
+
return None
|
| 203 |
+
|
| 204 |
+
print(f"Evaluating prompt_id: {prompt_id}...")
|
| 205 |
+
evaluation_result = evaluate_image(prompt_data, image_path, config)
|
| 206 |
+
|
| 207 |
+
full_record = {
|
| 208 |
+
"prompt_id": prompt_id,
|
| 209 |
+
"prompt": prompt_data["Prompt"],
|
| 210 |
+
"key": prompt_data["Explanation"],
|
| 211 |
+
"image_path": image_path,
|
| 212 |
+
"evaluation": evaluation_result["evaluation"]
|
| 213 |
+
}
|
| 214 |
+
|
| 215 |
+
score_record = {
|
| 216 |
+
"prompt_id": prompt_id,
|
| 217 |
+
"Subcategory": prompt_data["Subcategory"],
|
| 218 |
+
"consistency": evaluation_result["consistency"],
|
| 219 |
+
"realism": evaluation_result["realism"],
|
| 220 |
+
"aesthetic_quality": evaluation_result["aesthetic_quality"]
|
| 221 |
+
}
|
| 222 |
+
|
| 223 |
+
return full_record, score_record
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
if __name__ == "__main__":
|
| 227 |
+
api_key = openai.api_key
|
| 228 |
+
base_url = "your_api_url",
|
| 229 |
+
api_version = "2024-03-01-preview"
|
| 230 |
+
model = "gpt-4o-2024-11-20"
|
| 231 |
+
|
| 232 |
+
openai_client = openai.AzureOpenAI(
|
| 233 |
+
azure_endpoint=base_url,
|
| 234 |
+
api_version=api_version,
|
| 235 |
+
api_key=api_key,
|
| 236 |
+
)
|
| 237 |
+
|
| 238 |
+
args = parse_arguments()
|
| 239 |
+
config = get_config(args)
|
| 240 |
+
Path(config["output_dir"]).mkdir(parents=True, exist_ok=True)
|
| 241 |
+
|
| 242 |
+
prompts = load_prompts(config["json_path"])
|
| 243 |
+
|
| 244 |
+
processed_ids = set()
|
| 245 |
+
if os.path.exists(os.path.join(config["output_dir"], config["result_files"]["full"])):
|
| 246 |
+
with open(os.path.join(config["output_dir"], config["result_files"]["full"]), 'r', encoding='utf-8') as f:
|
| 247 |
+
for line in f:
|
| 248 |
+
data = json.loads(line)
|
| 249 |
+
processed_ids.add(data["prompt_id"])
|
| 250 |
+
left_prompts = {k: v for k, v in prompts.items() if k not in processed_ids}
|
| 251 |
+
print(f"Process {len(left_prompts)} prompts...")
|
| 252 |
+
|
| 253 |
+
MAX_THREADS = 30
|
| 254 |
+
|
| 255 |
+
with concurrent.futures.ThreadPoolExecutor(max_workers=MAX_THREADS) as executor:
|
| 256 |
+
futures = [executor.submit(process_prompt, prompt_id, prompt_data, config)
|
| 257 |
+
for prompt_id, prompt_data in left_prompts.items()]
|
| 258 |
+
for future in concurrent.futures.as_completed(futures):
|
| 259 |
+
try:
|
| 260 |
+
result = future.result()
|
| 261 |
+
if result:
|
| 262 |
+
full_record, score_record = result
|
| 263 |
+
print(full_record)
|
| 264 |
+
save_results(full_record, config["result_files"]["full"], config)
|
| 265 |
+
save_results(score_record, config["result_files"]["scores"], config)
|
| 266 |
+
|
| 267 |
+
except Exception as e:
|
| 268 |
+
print(f"An error occurred: {e}")
|
eval/vlm/__init__.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2025 Bytedance Ltd. and/or its affiliates.
|
| 2 |
+
# SPDX-License-Identifier: Apache-2.0
|
eval/vlm/eval/mathvista/calculate_score.py
ADDED
|
@@ -0,0 +1,271 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023 OpenGVLab
|
| 2 |
+
# Copyright (c) 2025 Bytedance Ltd. and/or its affiliates.
|
| 3 |
+
# SPDX-License-Identifier: MIT
|
| 4 |
+
#
|
| 5 |
+
# This file has been modified by ByteDance Ltd. and/or its affiliates. on 2025-05-20.
|
| 6 |
+
#
|
| 7 |
+
# Original file was released under MIT, with the full license text
|
| 8 |
+
# available at https://github.com/OpenGVLab/InternVL/blob/main/LICENSE.
|
| 9 |
+
#
|
| 10 |
+
# This modified file is released under the same license.
|
| 11 |
+
|
| 12 |
+
import argparse
|
| 13 |
+
|
| 14 |
+
import pandas as pd
|
| 15 |
+
# !pip install python-Levenshtein
|
| 16 |
+
from Levenshtein import distance
|
| 17 |
+
from utilities import *
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def get_most_similar(prediction, choices):
|
| 21 |
+
"""
|
| 22 |
+
Use the Levenshtein distance (or edit distance) to determine which of the choices is most similar to the given prediction
|
| 23 |
+
"""
|
| 24 |
+
distances = [distance(prediction, choice) for choice in choices]
|
| 25 |
+
ind = distances.index(min(distances))
|
| 26 |
+
return choices[ind]
|
| 27 |
+
# return min(choices, key=lambda choice: distance(prediction, choice))
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def normalize_extracted_answer(extraction, choices, question_type, answer_type, precision):
|
| 31 |
+
"""
|
| 32 |
+
Normalize the extracted answer to match the answer type
|
| 33 |
+
"""
|
| 34 |
+
if question_type == 'multi_choice':
|
| 35 |
+
# make sure the extraction is a string
|
| 36 |
+
if isinstance(extraction, str):
|
| 37 |
+
extraction = extraction.strip()
|
| 38 |
+
else:
|
| 39 |
+
try:
|
| 40 |
+
extraction = str(extraction)
|
| 41 |
+
except:
|
| 42 |
+
extraction = ''
|
| 43 |
+
|
| 44 |
+
# extract "A" from "(A) text"
|
| 45 |
+
letter = re.findall(r'\(([a-zA-Z])\)', extraction)
|
| 46 |
+
if len(letter) > 0:
|
| 47 |
+
extraction = letter[0].upper()
|
| 48 |
+
|
| 49 |
+
options = [chr(ord('A') + i) for i in range(len(choices))]
|
| 50 |
+
|
| 51 |
+
if extraction in options:
|
| 52 |
+
# convert option letter to text, e.g. "A" -> "text"
|
| 53 |
+
ind = options.index(extraction)
|
| 54 |
+
extraction = choices[ind]
|
| 55 |
+
else:
|
| 56 |
+
# select the most similar option
|
| 57 |
+
extraction = get_most_similar(extraction, choices)
|
| 58 |
+
assert extraction in choices
|
| 59 |
+
|
| 60 |
+
elif answer_type == 'integer':
|
| 61 |
+
try:
|
| 62 |
+
extraction = str(int(float(extraction)))
|
| 63 |
+
except:
|
| 64 |
+
extraction = None
|
| 65 |
+
|
| 66 |
+
elif answer_type == 'float':
|
| 67 |
+
try:
|
| 68 |
+
extraction = str(round(float(extraction), int(precision)))
|
| 69 |
+
except:
|
| 70 |
+
extraction = None
|
| 71 |
+
|
| 72 |
+
elif answer_type == 'list':
|
| 73 |
+
try:
|
| 74 |
+
extraction = str(extraction)
|
| 75 |
+
except:
|
| 76 |
+
extraction = None
|
| 77 |
+
|
| 78 |
+
return extraction
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def safe_equal(prediction, answer):
|
| 82 |
+
"""
|
| 83 |
+
Check if the prediction is equal to the answer, even if they are of different types
|
| 84 |
+
"""
|
| 85 |
+
try:
|
| 86 |
+
if prediction == answer:
|
| 87 |
+
return True
|
| 88 |
+
return False
|
| 89 |
+
except Exception as e:
|
| 90 |
+
print(e)
|
| 91 |
+
return False
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def get_acc_with_contion(res_pd, key, value):
|
| 95 |
+
if key == 'skills':
|
| 96 |
+
# if value in res_pd[key]:
|
| 97 |
+
total_pd = res_pd[res_pd[key].apply(lambda x: value in x)]
|
| 98 |
+
else:
|
| 99 |
+
total_pd = res_pd[res_pd[key] == value]
|
| 100 |
+
|
| 101 |
+
correct_pd = total_pd[total_pd['true_false'] == True] # noqa: E712
|
| 102 |
+
acc = '{:.2f}'.format(len(correct_pd) / len(total_pd) * 100)
|
| 103 |
+
return len(correct_pd), len(total_pd), acc
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
if __name__ == '__main__':
|
| 107 |
+
parser = argparse.ArgumentParser()
|
| 108 |
+
parser.add_argument('--output_dir', type=str, default='./results')
|
| 109 |
+
parser.add_argument('--output_file', type=str, default='output.json')
|
| 110 |
+
parser.add_argument('--score_file', type=str, default='scores.json')
|
| 111 |
+
parser.add_argument('--gt_file', type=str, default='./eval/vlm/data/MathVista/annot_testmini.json', help='ground truth file')
|
| 112 |
+
parser.add_argument('--number', type=int, default=-1, help='number of problems to run')
|
| 113 |
+
parser.add_argument('--rerun', action='store_true', help='rerun the evaluation')
|
| 114 |
+
parser.add_argument('--caculate_gain', action='store_true', help='caculate the score gains over random guess')
|
| 115 |
+
parser.add_argument('--random_file', type=str, default='score_random_guess.json')
|
| 116 |
+
args = parser.parse_args()
|
| 117 |
+
|
| 118 |
+
# args
|
| 119 |
+
output_file = os.path.join(args.output_dir, args.output_file)
|
| 120 |
+
|
| 121 |
+
# # quick test
|
| 122 |
+
# output_file = '../results/llava-llama-2-13b/output_llava_llama_2_13b.json'
|
| 123 |
+
|
| 124 |
+
# read json
|
| 125 |
+
print(f'Reading {output_file}...')
|
| 126 |
+
results = read_json(output_file)
|
| 127 |
+
|
| 128 |
+
# read ground truth
|
| 129 |
+
print(f'Reading {args.gt_file}...')
|
| 130 |
+
gts = read_json(args.gt_file)
|
| 131 |
+
|
| 132 |
+
# full pids
|
| 133 |
+
full_pids = list(results.keys())
|
| 134 |
+
if args.number > 0:
|
| 135 |
+
full_pids = full_pids[:min(args.number, len(full_pids))]
|
| 136 |
+
print('Number of testing problems:', len(full_pids))
|
| 137 |
+
|
| 138 |
+
## [1] Evaluate if the prediction is true or false
|
| 139 |
+
print('\nEvaluating the predictions...')
|
| 140 |
+
update_json_flag = False
|
| 141 |
+
for pid in full_pids:
|
| 142 |
+
problem = results[pid]
|
| 143 |
+
# print(problem)
|
| 144 |
+
|
| 145 |
+
if args.rerun:
|
| 146 |
+
if 'prediction' in problem:
|
| 147 |
+
del problem['prediction']
|
| 148 |
+
if 'true_false' in problem:
|
| 149 |
+
del problem['true_false']
|
| 150 |
+
|
| 151 |
+
choices = problem['choices']
|
| 152 |
+
question_type = problem['question_type']
|
| 153 |
+
answer_type = problem['answer_type']
|
| 154 |
+
precision = problem['precision']
|
| 155 |
+
extraction = problem['extraction']
|
| 156 |
+
|
| 157 |
+
if 'answer' in problem:
|
| 158 |
+
answer = problem['answer']
|
| 159 |
+
else:
|
| 160 |
+
if pid in gts:
|
| 161 |
+
answer = gts[pid]['answer']
|
| 162 |
+
else:
|
| 163 |
+
answer = ''
|
| 164 |
+
problem['answer'] = answer
|
| 165 |
+
|
| 166 |
+
# normalize the extracted answer to match the answer type
|
| 167 |
+
prediction = normalize_extracted_answer(extraction, choices, question_type, answer_type, precision)
|
| 168 |
+
|
| 169 |
+
# verify the prediction is true or false
|
| 170 |
+
true_false = safe_equal(prediction, answer)
|
| 171 |
+
|
| 172 |
+
# update the problem
|
| 173 |
+
if 'true_false' not in problem:
|
| 174 |
+
update_json_flag = True
|
| 175 |
+
|
| 176 |
+
elif true_false != problem['true_false']:
|
| 177 |
+
update_json_flag = True
|
| 178 |
+
|
| 179 |
+
if 'prediction' not in problem:
|
| 180 |
+
update_json_flag = True
|
| 181 |
+
|
| 182 |
+
elif prediction != problem['prediction']:
|
| 183 |
+
update_json_flag = True
|
| 184 |
+
|
| 185 |
+
problem['prediction'] = prediction
|
| 186 |
+
problem['true_false'] = true_false
|
| 187 |
+
|
| 188 |
+
# save the updated json
|
| 189 |
+
if update_json_flag:
|
| 190 |
+
print('\n!!!Some problems are updated.!!!')
|
| 191 |
+
print(f'\nSaving {output_file}...')
|
| 192 |
+
save_json(results, output_file)
|
| 193 |
+
|
| 194 |
+
## [2] Calculate the average accuracy
|
| 195 |
+
total = len(full_pids)
|
| 196 |
+
correct = 0
|
| 197 |
+
for pid in full_pids:
|
| 198 |
+
if results[pid]['true_false']:
|
| 199 |
+
correct += 1
|
| 200 |
+
accuracy = str(round(correct / total * 100, 2))
|
| 201 |
+
print(f'\nCorrect: {correct}, Total: {total}, Accuracy: {accuracy}%')
|
| 202 |
+
|
| 203 |
+
scores = {'average': {'accuracy': accuracy, 'correct': correct, 'total': total}}
|
| 204 |
+
|
| 205 |
+
## [3] Calculate the fine-grained accuracy scores
|
| 206 |
+
|
| 207 |
+
# merge the 'metadata' attribute into the data
|
| 208 |
+
for pid in results:
|
| 209 |
+
results[pid].update(results[pid].pop('metadata'))
|
| 210 |
+
|
| 211 |
+
# convert the data to a pandas DataFrame
|
| 212 |
+
df = pd.DataFrame(results).T
|
| 213 |
+
|
| 214 |
+
print(len(df))
|
| 215 |
+
print('Number of test problems:', len(df))
|
| 216 |
+
# assert len(df) == 1000 # Important!!!
|
| 217 |
+
|
| 218 |
+
# asign the target keys for evaluation
|
| 219 |
+
target_keys = ['question_type', 'answer_type', 'language', 'source', 'category', 'task', 'context', 'grade',
|
| 220 |
+
'skills']
|
| 221 |
+
|
| 222 |
+
for key in target_keys:
|
| 223 |
+
print(f'\nType: [{key}]')
|
| 224 |
+
# get the unique values of the key
|
| 225 |
+
if key == 'skills':
|
| 226 |
+
# the value is a list
|
| 227 |
+
values = []
|
| 228 |
+
for i in range(len(df)):
|
| 229 |
+
values += df[key][i]
|
| 230 |
+
values = list(set(values))
|
| 231 |
+
else:
|
| 232 |
+
values = df[key].unique()
|
| 233 |
+
# print(values)
|
| 234 |
+
|
| 235 |
+
# calculate the accuracy for each value
|
| 236 |
+
scores[key] = {}
|
| 237 |
+
for value in values:
|
| 238 |
+
correct, total, acc = get_acc_with_contion(df, key, value)
|
| 239 |
+
if total > 0:
|
| 240 |
+
print(f'[{value}]: {acc}% ({correct}/{total})')
|
| 241 |
+
scores[key][value] = {'accuracy': acc, 'correct': correct, 'total': total}
|
| 242 |
+
|
| 243 |
+
# sort the scores by accuracy
|
| 244 |
+
scores[key] = dict(sorted(scores[key].items(), key=lambda item: float(item[1]['accuracy']), reverse=True))
|
| 245 |
+
|
| 246 |
+
# save the scores
|
| 247 |
+
scores_file = os.path.join(args.output_dir, args.score_file)
|
| 248 |
+
print(f'\nSaving {scores_file}...')
|
| 249 |
+
save_json(scores, scores_file)
|
| 250 |
+
print('\nDone!')
|
| 251 |
+
|
| 252 |
+
# [4] Calculate the score gains over random guess
|
| 253 |
+
if args.caculate_gain:
|
| 254 |
+
random_file = os.path.join(args.output_dir, args.random_file)
|
| 255 |
+
random_scores = json.load(open(random_file))
|
| 256 |
+
|
| 257 |
+
print('\nCalculating the score gains...')
|
| 258 |
+
for key in scores:
|
| 259 |
+
if key == 'average':
|
| 260 |
+
gain = round(float(scores[key]['accuracy']) - float(random_scores[key]['accuracy']), 2)
|
| 261 |
+
scores[key]['acc_gain'] = gain
|
| 262 |
+
else:
|
| 263 |
+
for sub_key in scores[key]:
|
| 264 |
+
gain = round(
|
| 265 |
+
float(scores[key][sub_key]['accuracy']) - float(random_scores[key][sub_key]['accuracy']), 2)
|
| 266 |
+
scores[key][sub_key]['acc_gain'] = str(gain)
|
| 267 |
+
|
| 268 |
+
# save the score gains
|
| 269 |
+
print(f'\nSaving {scores_file}...')
|
| 270 |
+
save_json(scores, scores_file)
|
| 271 |
+
print('\nDone!')
|
eval/vlm/eval/mathvista/evaluate_mathvista.py
ADDED
|
@@ -0,0 +1,210 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023 OpenGVLab
|
| 2 |
+
# Copyright (c) 2025 Bytedance Ltd. and/or its affiliates.
|
| 3 |
+
# SPDX-License-Identifier: MIT
|
| 4 |
+
#
|
| 5 |
+
# This file has been modified by ByteDance Ltd. and/or its affiliates. on 2025-05-20.
|
| 6 |
+
#
|
| 7 |
+
# Original file was released under MIT, with the full license text
|
| 8 |
+
# available at https://github.com/OpenGVLab/InternVL/blob/main/LICENSE.
|
| 9 |
+
#
|
| 10 |
+
# This modified file is released under the same license.
|
| 11 |
+
|
| 12 |
+
import argparse
|
| 13 |
+
import itertools
|
| 14 |
+
import json
|
| 15 |
+
import os
|
| 16 |
+
import random
|
| 17 |
+
|
| 18 |
+
import torch
|
| 19 |
+
from datasets import concatenate_datasets, load_dataset
|
| 20 |
+
from eval.vlm.utils import load_model_and_tokenizer, build_transform, process_conversation
|
| 21 |
+
from tqdm import tqdm
|
| 22 |
+
|
| 23 |
+
ds_collections = {
|
| 24 |
+
'MathVista_testmini': {
|
| 25 |
+
'root': 'AI4Math/MathVista',
|
| 26 |
+
'max_new_tokens': 4096,
|
| 27 |
+
'min_new_tokens': 1,
|
| 28 |
+
'split': 'testmini'
|
| 29 |
+
},
|
| 30 |
+
'MathVista_test': {
|
| 31 |
+
'root': 'AI4Math/MathVista',
|
| 32 |
+
'max_new_tokens': 4096,
|
| 33 |
+
'min_new_tokens': 1,
|
| 34 |
+
'split': 'test'
|
| 35 |
+
},
|
| 36 |
+
}
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
COT_INSTRUCTION = (
|
| 40 |
+
'Your task is to answer the question below. '
|
| 41 |
+
"Give step by step reasoning before you answer, and when you're ready to answer, "
|
| 42 |
+
"please use the format \"Final answer: ..\""
|
| 43 |
+
'\n\n'
|
| 44 |
+
'Question:'
|
| 45 |
+
'\n\n'
|
| 46 |
+
'{question}'
|
| 47 |
+
)
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def collate_fn(batches):
|
| 51 |
+
images = [_['images'] for _ in batches]
|
| 52 |
+
data_items = [_['data_item'] for _ in batches]
|
| 53 |
+
return images, data_items
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
class MathVistaDataset(torch.utils.data.Dataset):
|
| 57 |
+
|
| 58 |
+
def __init__(self, root, split):
|
| 59 |
+
dataset = load_dataset(root, cache_dir=os.path.join(os.getcwd(), 'eval/vlm/data/MathVista/'))
|
| 60 |
+
self.data = dataset[split]
|
| 61 |
+
|
| 62 |
+
def __len__(self):
|
| 63 |
+
return len(self.data)
|
| 64 |
+
|
| 65 |
+
def __getitem__(self, idx):
|
| 66 |
+
data_item = self.data[idx]
|
| 67 |
+
image = data_item['decoded_image']
|
| 68 |
+
del data_item['decoded_image']
|
| 69 |
+
|
| 70 |
+
images = [image.convert('RGB') if image.mode != 'RGB' else image]
|
| 71 |
+
|
| 72 |
+
return {
|
| 73 |
+
'images': images,
|
| 74 |
+
'data_item': data_item,
|
| 75 |
+
}
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
class InferenceSampler(torch.utils.data.sampler.Sampler):
|
| 79 |
+
|
| 80 |
+
def __init__(self, size):
|
| 81 |
+
self._size = int(size)
|
| 82 |
+
assert size > 0
|
| 83 |
+
self._rank = torch.distributed.get_rank()
|
| 84 |
+
self._world_size = torch.distributed.get_world_size()
|
| 85 |
+
self._local_indices = self._get_local_indices(size, self._world_size, self._rank)
|
| 86 |
+
|
| 87 |
+
@staticmethod
|
| 88 |
+
def _get_local_indices(total_size, world_size, rank):
|
| 89 |
+
shard_size = total_size // world_size
|
| 90 |
+
left = total_size % world_size
|
| 91 |
+
shard_sizes = [shard_size + int(r < left) for r in range(world_size)]
|
| 92 |
+
|
| 93 |
+
begin = sum(shard_sizes[:rank])
|
| 94 |
+
end = min(sum(shard_sizes[:rank + 1]), total_size)
|
| 95 |
+
return range(begin, end)
|
| 96 |
+
|
| 97 |
+
def __iter__(self):
|
| 98 |
+
yield from self._local_indices
|
| 99 |
+
|
| 100 |
+
def __len__(self):
|
| 101 |
+
return len(self._local_indices)
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
def evaluate_chat_model():
|
| 105 |
+
random.seed(args.seed)
|
| 106 |
+
|
| 107 |
+
for ds_name in args.datasets:
|
| 108 |
+
dataset = MathVistaDataset(
|
| 109 |
+
root=ds_collections[ds_name]['root'],
|
| 110 |
+
split=ds_collections[ds_name]['split'],
|
| 111 |
+
)
|
| 112 |
+
dataloader = torch.utils.data.DataLoader(
|
| 113 |
+
dataset=dataset,
|
| 114 |
+
sampler=InferenceSampler(len(dataset)),
|
| 115 |
+
batch_size=args.batch_size,
|
| 116 |
+
num_workers=args.num_workers,
|
| 117 |
+
pin_memory=True,
|
| 118 |
+
drop_last=False,
|
| 119 |
+
collate_fn=collate_fn,
|
| 120 |
+
)
|
| 121 |
+
|
| 122 |
+
outputs = []
|
| 123 |
+
for _, (images, data_items) in tqdm(enumerate(dataloader)):
|
| 124 |
+
if args.cot:
|
| 125 |
+
question = COT_INSTRUCTION.format(question=data_items[0]['query'])
|
| 126 |
+
else:
|
| 127 |
+
question = data_items[0]['query']
|
| 128 |
+
|
| 129 |
+
images = images[0]
|
| 130 |
+
images, conversation = process_conversation(images, question)
|
| 131 |
+
|
| 132 |
+
pred = model.chat(
|
| 133 |
+
tokenizer,
|
| 134 |
+
new_token_ids,
|
| 135 |
+
image_transform,
|
| 136 |
+
images=images,
|
| 137 |
+
prompt=conversation,
|
| 138 |
+
max_length=ds_collections[ds_name]['max_new_tokens'] if not args.cot else 4096, # TODO: how to use ds_collections[ds_name]['min_new_tokens']
|
| 139 |
+
)
|
| 140 |
+
|
| 141 |
+
data_item = data_items[0]
|
| 142 |
+
data_item['response'] = pred
|
| 143 |
+
outputs.append(data_item)
|
| 144 |
+
|
| 145 |
+
torch.distributed.barrier()
|
| 146 |
+
|
| 147 |
+
world_size = torch.distributed.get_world_size()
|
| 148 |
+
merged_outputs = [None for _ in range(world_size)]
|
| 149 |
+
torch.distributed.all_gather_object(merged_outputs, json.dumps(outputs))
|
| 150 |
+
|
| 151 |
+
merged_outputs = [json.loads(_) for _ in merged_outputs]
|
| 152 |
+
merged_outputs = [_ for _ in itertools.chain.from_iterable(merged_outputs)]
|
| 153 |
+
|
| 154 |
+
if torch.distributed.get_rank() == 0:
|
| 155 |
+
temp = {}
|
| 156 |
+
for data_item in merged_outputs:
|
| 157 |
+
pid = data_item['pid']
|
| 158 |
+
temp[pid] = data_item
|
| 159 |
+
|
| 160 |
+
print(f'Evaluating {ds_name} ...')
|
| 161 |
+
results_file = 'results.json'
|
| 162 |
+
output_path = os.path.join(args.out_dir, 'results.json')
|
| 163 |
+
json.dump(temp, open(output_path, 'w'), indent=4)
|
| 164 |
+
print('Results saved to {}'.format(output_path))
|
| 165 |
+
|
| 166 |
+
if args.cot:
|
| 167 |
+
cmd = f'python eval/vlm/eval/mathvista/extract_answer_mp.py --output_file {results_file} --output_dir {args.out_dir}'
|
| 168 |
+
else:
|
| 169 |
+
cmd = f'python eval/vlm/eval/mathvista/extract_answer_mp.py --output_file {results_file} --output_dir {args.out_dir}'
|
| 170 |
+
print(cmd)
|
| 171 |
+
os.system(cmd)
|
| 172 |
+
|
| 173 |
+
cmd = f'python eval/vlm/eval/mathvista/calculate_score.py --output_file {results_file} --output_dir {args.out_dir} --score_file score.json'
|
| 174 |
+
print(cmd)
|
| 175 |
+
os.system(cmd)
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
if __name__ == '__main__':
|
| 179 |
+
parser = argparse.ArgumentParser()
|
| 180 |
+
parser.add_argument('--datasets', type=str, default='MathVista_testmini')
|
| 181 |
+
parser.add_argument('--batch-size', type=int, default=1)
|
| 182 |
+
parser.add_argument('--num-workers', type=int, default=1)
|
| 183 |
+
parser.add_argument('--out-dir', type=str, default='results')
|
| 184 |
+
parser.add_argument('--seed', type=int, default=0)
|
| 185 |
+
parser.add_argument('--cot', action='store_true')
|
| 186 |
+
parser.add_argument('--model-path', type=str, default='hf/BAGEL-7B-MoT/')
|
| 187 |
+
args = parser.parse_args()
|
| 188 |
+
|
| 189 |
+
if not os.path.exists(args.out_dir):
|
| 190 |
+
os.makedirs(args.out_dir, exist_ok=True)
|
| 191 |
+
|
| 192 |
+
args.datasets = args.datasets.split(',')
|
| 193 |
+
print('datasets:', args.datasets)
|
| 194 |
+
assert args.batch_size == 1, 'Only batch size 1 is supported'
|
| 195 |
+
|
| 196 |
+
torch.distributed.init_process_group(
|
| 197 |
+
backend='nccl',
|
| 198 |
+
world_size=int(os.getenv('WORLD_SIZE', '1')),
|
| 199 |
+
rank=int(os.getenv('RANK', '0')),
|
| 200 |
+
)
|
| 201 |
+
|
| 202 |
+
torch.cuda.set_device(int(os.getenv('LOCAL_RANK', 0)))
|
| 203 |
+
|
| 204 |
+
model, tokenizer, new_token_ids = load_model_and_tokenizer(args)
|
| 205 |
+
image_transform = build_transform()
|
| 206 |
+
|
| 207 |
+
total_params = sum(p.numel() for p in model.parameters()) / 1e9
|
| 208 |
+
print(f'[test] total_params: {total_params}B')
|
| 209 |
+
|
| 210 |
+
evaluate_chat_model()
|
eval/vlm/eval/mathvista/extract_answer.py
ADDED
|
@@ -0,0 +1,160 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023 OpenGVLab
|
| 2 |
+
# Copyright (c) 2025 Bytedance Ltd. and/or its affiliates.
|
| 3 |
+
# SPDX-License-Identifier: MIT
|
| 4 |
+
#
|
| 5 |
+
# This file has been modified by ByteDance Ltd. and/or its affiliates. on 2025-05-20.
|
| 6 |
+
#
|
| 7 |
+
# Original file was released under MIT, with the full license text
|
| 8 |
+
# available at https://github.com/OpenGVLab/InternVL/blob/main/LICENSE.
|
| 9 |
+
#
|
| 10 |
+
# This modified file is released under the same license.
|
| 11 |
+
|
| 12 |
+
import argparse
|
| 13 |
+
|
| 14 |
+
from tqdm import tqdm
|
| 15 |
+
from utilities import *
|
| 16 |
+
|
| 17 |
+
openai.api_key = os.getenv('OPENAI_API_KEY')
|
| 18 |
+
print(openai.api_key)
|
| 19 |
+
|
| 20 |
+
# load demo prompt
|
| 21 |
+
from prompts.ext_ans import demo_prompt
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def verify_extraction(extraction):
|
| 25 |
+
extraction = extraction.strip()
|
| 26 |
+
if extraction == '' or extraction is None:
|
| 27 |
+
return False
|
| 28 |
+
return True
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def create_test_prompt(demo_prompt, query, response):
|
| 32 |
+
demo_prompt = demo_prompt.strip()
|
| 33 |
+
test_prompt = f'{query}\n\n{response}'
|
| 34 |
+
full_prompt = f'{demo_prompt}\n\n{test_prompt}\n\nExtracted answer: '
|
| 35 |
+
return full_prompt
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def _extract_answer(text):
|
| 39 |
+
match = re.search(r'(Final answer:|Answer:)\s*(.*)', text, re.IGNORECASE)
|
| 40 |
+
if match:
|
| 41 |
+
return match.group(2).strip()
|
| 42 |
+
return text
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def extract_answer(response, problem, quick_extract=False):
|
| 46 |
+
question_type = problem['question_type']
|
| 47 |
+
answer_type = problem['answer_type']
|
| 48 |
+
choices = problem['choices']
|
| 49 |
+
query = problem['query']
|
| 50 |
+
|
| 51 |
+
if response == '':
|
| 52 |
+
return ''
|
| 53 |
+
|
| 54 |
+
if question_type == 'multi_choice' and response in choices:
|
| 55 |
+
return response
|
| 56 |
+
|
| 57 |
+
if answer_type == 'integer':
|
| 58 |
+
try:
|
| 59 |
+
extraction = int(response)
|
| 60 |
+
return str(extraction)
|
| 61 |
+
except:
|
| 62 |
+
pass
|
| 63 |
+
|
| 64 |
+
if answer_type == 'float':
|
| 65 |
+
try:
|
| 66 |
+
extraction = str(float(response))
|
| 67 |
+
return extraction
|
| 68 |
+
except:
|
| 69 |
+
pass
|
| 70 |
+
|
| 71 |
+
# quick extraction
|
| 72 |
+
if quick_extract:
|
| 73 |
+
print('Quickly extracting answer...')
|
| 74 |
+
# The answer is "text". -> "text"
|
| 75 |
+
try:
|
| 76 |
+
result = _extract_answer(response)
|
| 77 |
+
return result
|
| 78 |
+
# result = re.search(r'The answer is "(.*)"\.', response)
|
| 79 |
+
# if result:
|
| 80 |
+
# extraction = result.group(1)
|
| 81 |
+
# return extraction
|
| 82 |
+
except:
|
| 83 |
+
pass
|
| 84 |
+
|
| 85 |
+
# general extraction
|
| 86 |
+
try:
|
| 87 |
+
full_prompt = create_test_prompt(demo_prompt, query, response)
|
| 88 |
+
extraction = get_chat_response(full_prompt, openai.api_key, patience=5)
|
| 89 |
+
return extraction
|
| 90 |
+
except Exception as e:
|
| 91 |
+
print(e)
|
| 92 |
+
print(f'Error in extracting answer for {pid}')
|
| 93 |
+
|
| 94 |
+
return ''
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
if __name__ == '__main__':
|
| 98 |
+
parser = argparse.ArgumentParser()
|
| 99 |
+
# input
|
| 100 |
+
parser.add_argument('--output_dir', type=str, default='./results')
|
| 101 |
+
parser.add_argument('--output_file', type=str, default='mathvista_answer.json')
|
| 102 |
+
parser.add_argument('--response_label', type=str, default='response', help='response label for the input file')
|
| 103 |
+
# model
|
| 104 |
+
parser.add_argument('--llm_engine', type=str, default='gpt-4-0613', help='llm engine',
|
| 105 |
+
choices=['gpt-3.5-turbo', 'gpt-3.5', 'gpt-4', 'gpt-4-0314', 'gpt-4-0613'])
|
| 106 |
+
parser.add_argument('--number', type=int, default=-1, help='number of problems to run')
|
| 107 |
+
parser.add_argument('--quick_extract', action='store_true', help='use rules to extract answer for some problems')
|
| 108 |
+
parser.add_argument('--rerun', action='store_true', help='rerun the answer extraction')
|
| 109 |
+
# output
|
| 110 |
+
parser.add_argument('--save_every', type=int, default=10, help='save every n problems')
|
| 111 |
+
parser.add_argument('--output_label', type=str, default='', help='label for the output file')
|
| 112 |
+
args = parser.parse_args()
|
| 113 |
+
|
| 114 |
+
# args
|
| 115 |
+
label = args.response_label
|
| 116 |
+
result_file = os.path.join(args.output_dir, args.output_file)
|
| 117 |
+
|
| 118 |
+
if args.output_label != '':
|
| 119 |
+
output_file = result_file.replace('.json', f'_{args.output_label}.json')
|
| 120 |
+
else:
|
| 121 |
+
output_file = result_file
|
| 122 |
+
|
| 123 |
+
# read results
|
| 124 |
+
print(f'Reading {result_file}...')
|
| 125 |
+
results = read_json(result_file)
|
| 126 |
+
|
| 127 |
+
# full pids
|
| 128 |
+
full_pids = list(results.keys())
|
| 129 |
+
if args.number > 0:
|
| 130 |
+
full_pids = full_pids[:min(args.number, len(full_pids))]
|
| 131 |
+
print('Number of testing problems:', len(full_pids))
|
| 132 |
+
|
| 133 |
+
# test pids
|
| 134 |
+
if args.rerun:
|
| 135 |
+
test_pids = full_pids
|
| 136 |
+
else:
|
| 137 |
+
test_pids = []
|
| 138 |
+
for pid in full_pids:
|
| 139 |
+
# print(pid)
|
| 140 |
+
if 'extraction' not in results[pid] or not verify_extraction(results[pid]['extraction']):
|
| 141 |
+
test_pids.append(pid)
|
| 142 |
+
|
| 143 |
+
test_num = len(test_pids)
|
| 144 |
+
print('Number of problems to run:', test_num)
|
| 145 |
+
# print(test_pids)
|
| 146 |
+
|
| 147 |
+
# tqdm, enumerate results
|
| 148 |
+
for i, pid in enumerate(tqdm(test_pids)):
|
| 149 |
+
problem = results[pid]
|
| 150 |
+
|
| 151 |
+
assert label in problem
|
| 152 |
+
response = problem[label]
|
| 153 |
+
|
| 154 |
+
extraction = extract_answer(response, problem, args.quick_extract)
|
| 155 |
+
results[pid]['extraction'] = extraction
|
| 156 |
+
|
| 157 |
+
if i % args.save_every == 0 or i == test_num - 1:
|
| 158 |
+
print(f'Saving results to {output_file}...')
|
| 159 |
+
save_json(results, output_file)
|
| 160 |
+
print(f'Results saved.')
|
eval/vlm/eval/mathvista/extract_answer_mp.py
ADDED
|
@@ -0,0 +1,161 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023 OpenGVLab
|
| 2 |
+
# Copyright (c) 2025 Bytedance Ltd. and/or its affiliates.
|
| 3 |
+
# SPDX-License-Identifier: MIT
|
| 4 |
+
#
|
| 5 |
+
# This file has been modified by ByteDance Ltd. and/or its affiliates. on 2025-05-20.
|
| 6 |
+
#
|
| 7 |
+
# Original file was released under MIT, with the full license text
|
| 8 |
+
# available at https://github.com/OpenGVLab/InternVL/blob/main/LICENSE.
|
| 9 |
+
#
|
| 10 |
+
# This modified file is released under the same license.
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
import argparse
|
| 14 |
+
import os
|
| 15 |
+
import re
|
| 16 |
+
import json
|
| 17 |
+
import openai
|
| 18 |
+
from concurrent.futures import ThreadPoolExecutor, as_completed
|
| 19 |
+
from tqdm import tqdm
|
| 20 |
+
from utilities import *
|
| 21 |
+
from prompts.ext_ans import demo_prompt
|
| 22 |
+
|
| 23 |
+
openai.api_key = os.getenv('OPENAI_API_KEY')
|
| 24 |
+
print(openai.api_key)
|
| 25 |
+
|
| 26 |
+
def verify_extraction(extraction):
|
| 27 |
+
extraction = extraction.strip()
|
| 28 |
+
if extraction == '' or extraction is None:
|
| 29 |
+
return False
|
| 30 |
+
return True
|
| 31 |
+
|
| 32 |
+
def create_test_prompt(demo_prompt, query, response):
|
| 33 |
+
demo_prompt = demo_prompt.strip()
|
| 34 |
+
test_prompt = f'{query}\n\n{response}'
|
| 35 |
+
full_prompt = f'{demo_prompt}\n\n{test_prompt}\n\nExtracted answer: '
|
| 36 |
+
return full_prompt
|
| 37 |
+
|
| 38 |
+
def _extract_answer(text):
|
| 39 |
+
match = re.search(r'(Final answer:|Answer:)\s*(.*)', text, re.IGNORECASE)
|
| 40 |
+
if match:
|
| 41 |
+
return match.group(2).strip()
|
| 42 |
+
return text
|
| 43 |
+
|
| 44 |
+
def extract_answer(response, problem, quick_extract=False):
|
| 45 |
+
question_type = problem['question_type']
|
| 46 |
+
answer_type = problem['answer_type']
|
| 47 |
+
choices = problem['choices']
|
| 48 |
+
query = problem['query']
|
| 49 |
+
|
| 50 |
+
if response == '':
|
| 51 |
+
return ''
|
| 52 |
+
|
| 53 |
+
if question_type == 'multi_choice' and response in choices:
|
| 54 |
+
return response
|
| 55 |
+
|
| 56 |
+
if answer_type == 'integer':
|
| 57 |
+
try:
|
| 58 |
+
extraction = int(response)
|
| 59 |
+
return str(extraction)
|
| 60 |
+
except:
|
| 61 |
+
pass
|
| 62 |
+
|
| 63 |
+
if answer_type == 'float':
|
| 64 |
+
try:
|
| 65 |
+
extraction = str(float(response))
|
| 66 |
+
return extraction
|
| 67 |
+
except:
|
| 68 |
+
pass
|
| 69 |
+
|
| 70 |
+
# quick extraction
|
| 71 |
+
if quick_extract:
|
| 72 |
+
print('Quickly extracting answer...')
|
| 73 |
+
try:
|
| 74 |
+
result = _extract_answer(response)
|
| 75 |
+
return result
|
| 76 |
+
except:
|
| 77 |
+
pass
|
| 78 |
+
|
| 79 |
+
try:
|
| 80 |
+
full_prompt = create_test_prompt(demo_prompt, query, response)
|
| 81 |
+
extraction = get_chat_response(full_prompt, openai.api_key, patience=5, model=args.llm_engine)
|
| 82 |
+
return extraction
|
| 83 |
+
except Exception as e:
|
| 84 |
+
print(e)
|
| 85 |
+
|
| 86 |
+
return ''
|
| 87 |
+
|
| 88 |
+
def process_problem(pid, results, label, args):
|
| 89 |
+
problem = results[pid]
|
| 90 |
+
response = problem[label]
|
| 91 |
+
extraction = extract_answer(response, problem, args.quick_extract)
|
| 92 |
+
return pid, extraction
|
| 93 |
+
|
| 94 |
+
if __name__ == '__main__':
|
| 95 |
+
parser = argparse.ArgumentParser()
|
| 96 |
+
# input
|
| 97 |
+
parser.add_argument('--output_dir', type=str, default='./results')
|
| 98 |
+
parser.add_argument('--output_file', type=str, default='mathvista_answer.json')
|
| 99 |
+
parser.add_argument('--response_label', type=str, default='response', help='response label for the input file')
|
| 100 |
+
# model
|
| 101 |
+
parser.add_argument('--llm_engine', type=str, default='gpt-4o-2024-11-20', help='llm engine',
|
| 102 |
+
choices=['gpt-3.5-turbo', 'gpt-3.5', 'gpt-4', 'gpt-4-0314', 'gpt-4-0613',
|
| 103 |
+
'gpt-4o-2024-08-06', 'gpt-4o-2024-11-20'])
|
| 104 |
+
parser.add_argument('--number', type=int, default=-1, help='number of problems to run')
|
| 105 |
+
parser.add_argument('--quick_extract', action='store_true', help='use rules to extract answer for some problems')
|
| 106 |
+
parser.add_argument('--rerun', action='store_true', help='rerun the answer extraction')
|
| 107 |
+
# output
|
| 108 |
+
parser.add_argument('--save_every', type=int, default=100, help='save every n problems')
|
| 109 |
+
parser.add_argument('--output_label', type=str, default='', help='label for the output file')
|
| 110 |
+
parser.add_argument('--max_workers', type=int, default=40, help='max workers for ThreadPoolExecutor')
|
| 111 |
+
args = parser.parse_args()
|
| 112 |
+
|
| 113 |
+
label = args.response_label
|
| 114 |
+
result_file = os.path.join(args.output_dir, args.output_file)
|
| 115 |
+
|
| 116 |
+
if args.output_label != '':
|
| 117 |
+
output_file = result_file.replace('.json', f'_{args.output_label}.json')
|
| 118 |
+
else:
|
| 119 |
+
output_file = result_file
|
| 120 |
+
|
| 121 |
+
print(f'Reading {result_file}...')
|
| 122 |
+
results = read_json(result_file)
|
| 123 |
+
|
| 124 |
+
full_pids = list(results.keys())
|
| 125 |
+
if args.number > 0:
|
| 126 |
+
full_pids = full_pids[:min(args.number, len(full_pids))]
|
| 127 |
+
print('Number of total problems:', len(full_pids))
|
| 128 |
+
|
| 129 |
+
if args.rerun:
|
| 130 |
+
test_pids = full_pids
|
| 131 |
+
else:
|
| 132 |
+
test_pids = []
|
| 133 |
+
for pid in full_pids:
|
| 134 |
+
if 'extraction' not in results[pid] or not verify_extraction(results[pid]['extraction']):
|
| 135 |
+
test_pids.append(pid)
|
| 136 |
+
|
| 137 |
+
test_num = len(test_pids)
|
| 138 |
+
print('Number of problems to run:', test_num)
|
| 139 |
+
|
| 140 |
+
with ThreadPoolExecutor(max_workers=args.max_workers) as executor:
|
| 141 |
+
future_to_pid = {}
|
| 142 |
+
for pid in test_pids:
|
| 143 |
+
future = executor.submit(process_problem, pid, results, label, args)
|
| 144 |
+
future_to_pid[future] = pid
|
| 145 |
+
|
| 146 |
+
completed_count = 0
|
| 147 |
+
for future in tqdm(as_completed(future_to_pid), total=test_num):
|
| 148 |
+
pid = future_to_pid[future]
|
| 149 |
+
try:
|
| 150 |
+
pid_result, extraction = future.result()
|
| 151 |
+
results[pid_result]['extraction'] = extraction
|
| 152 |
+
except Exception as e:
|
| 153 |
+
print(f'Error processing pid={pid}: {e}')
|
| 154 |
+
|
| 155 |
+
completed_count += 1
|
| 156 |
+
if (completed_count % args.save_every == 0) or (completed_count == test_num):
|
| 157 |
+
print(f'Saving results to {output_file}... [{completed_count}/{test_num}]')
|
| 158 |
+
save_json(results, output_file)
|
| 159 |
+
print('Results saved.')
|
| 160 |
+
|
| 161 |
+
print('All done!')
|
eval/vlm/eval/mathvista/prompts/ext_ans.py
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023 OpenGVLab
|
| 2 |
+
# Copyright (c) 2025 Bytedance Ltd. and/or its affiliates.
|
| 3 |
+
# SPDX-License-Identifier: MIT
|
| 4 |
+
#
|
| 5 |
+
# This file has been modified by ByteDance Ltd. and/or its affiliates. on 2025-05-20.
|
| 6 |
+
#
|
| 7 |
+
# Original file was released under MIT, with the full license text
|
| 8 |
+
# available at https://github.com/OpenGVLab/InternVL/blob/main/LICENSE.
|
| 9 |
+
#
|
| 10 |
+
# This modified file is released under the same license.
|
| 11 |
+
|
| 12 |
+
# pids = 852, 104, 824, 506, 540
|
| 13 |
+
|
| 14 |
+
demo_prompt = """
|
| 15 |
+
Please read the following example. Then extract the answer from the model response and type it at the end of the prompt.
|
| 16 |
+
|
| 17 |
+
Hint: Please answer the question requiring an integer answer and provide the final value, e.g., 1, 2, 3, at the end.
|
| 18 |
+
Question: Which number is missing?
|
| 19 |
+
|
| 20 |
+
Model response: The number missing in the sequence is 14.
|
| 21 |
+
|
| 22 |
+
Extracted answer: 14
|
| 23 |
+
|
| 24 |
+
Hint: Please answer the question requiring a floating-point number with one decimal place and provide the final value, e.g., 1.2, 1.3, 1.4, at the end.
|
| 25 |
+
Question: What is the fraction of females facing the camera?
|
| 26 |
+
|
| 27 |
+
Model response: The fraction of females facing the camera is 0.6, which means that six out of ten females in the group are facing the camera.
|
| 28 |
+
|
| 29 |
+
Extracted answer: 0.6
|
| 30 |
+
|
| 31 |
+
Hint: Please answer the question requiring a floating-point number with two decimal places and provide the final value, e.g., 1.23, 1.34, 1.45, at the end.
|
| 32 |
+
Question: How much money does Luca need to buy a sour apple candy and a butterscotch candy? (Unit: $)
|
| 33 |
+
|
| 34 |
+
Model response: Luca needs $1.45 to buy a sour apple candy and a butterscotch candy.
|
| 35 |
+
|
| 36 |
+
Extracted answer: 1.45
|
| 37 |
+
|
| 38 |
+
Hint: Please answer the question requiring a Python list as an answer and provide the final list, e.g., [1, 2, 3], [1.2, 1.3, 1.4], at the end.
|
| 39 |
+
Question: Between which two years does the line graph saw its maximum peak?
|
| 40 |
+
|
| 41 |
+
Model response: The line graph saw its maximum peak between 2007 and 2008.
|
| 42 |
+
|
| 43 |
+
Extracted answer: [2007, 2008]
|
| 44 |
+
|
| 45 |
+
Hint: Please answer the question and provide the correct option letter, e.g., A, B, C, D, at the end.
|
| 46 |
+
Question: What fraction of the shape is blue?\nChoices:\n(A) 3/11\n(B) 8/11\n(C) 6/11\n(D) 3/5
|
| 47 |
+
|
| 48 |
+
Model response: The correct answer is (B) 8/11.
|
| 49 |
+
|
| 50 |
+
Extracted answer: B
|
| 51 |
+
"""
|
eval/vlm/eval/mathvista/utilities.py
ADDED
|
@@ -0,0 +1,229 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023 OpenGVLab
|
| 2 |
+
# Copyright (c) 2025 Bytedance Ltd. and/or its affiliates.
|
| 3 |
+
# SPDX-License-Identifier: MIT
|
| 4 |
+
#
|
| 5 |
+
# This file has been modified by ByteDance Ltd. and/or its affiliates. on 2025-05-20.
|
| 6 |
+
#
|
| 7 |
+
# Original file was released under MIT, with the full license text
|
| 8 |
+
# available at https://github.com/OpenGVLab/InternVL/blob/main/LICENSE.
|
| 9 |
+
#
|
| 10 |
+
# This modified file is released under the same license.
|
| 11 |
+
|
| 12 |
+
import json
|
| 13 |
+
import os
|
| 14 |
+
import pickle
|
| 15 |
+
import re
|
| 16 |
+
import time
|
| 17 |
+
|
| 18 |
+
import cv2
|
| 19 |
+
import openai
|
| 20 |
+
from word2number import w2n
|
| 21 |
+
|
| 22 |
+
openai_client = None
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def create_dir(output_dir):
|
| 26 |
+
if not os.path.exists(output_dir):
|
| 27 |
+
os.makedirs(output_dir)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def read_csv(file):
|
| 31 |
+
data = []
|
| 32 |
+
with open(file, 'r') as f:
|
| 33 |
+
for line in f:
|
| 34 |
+
data.append(line.strip())
|
| 35 |
+
return data
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def read_pandas_csv(csv_path):
|
| 39 |
+
# read a pandas csv sheet
|
| 40 |
+
import pandas as pd
|
| 41 |
+
df = pd.read_csv(csv_path)
|
| 42 |
+
return df
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def read_json(path):
|
| 46 |
+
with open(path, 'r', encoding='utf-8') as f:
|
| 47 |
+
return json.load(f)
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def read_jsonl(file):
|
| 51 |
+
with open(file, 'r') as f:
|
| 52 |
+
data = [json.loads(line) for line in f]
|
| 53 |
+
return data
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def read_pickle(path):
|
| 57 |
+
with open(path, 'rb') as f:
|
| 58 |
+
return pickle.load(f)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def save_json(data, path):
|
| 62 |
+
with open(path, 'w') as f:
|
| 63 |
+
json.dump(data, f, indent=4)
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def save_array_img(path, image):
|
| 67 |
+
cv2.imwrite(path, image)
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def contains_digit(text):
|
| 71 |
+
# check if text contains a digit
|
| 72 |
+
if any(char.isdigit() for char in text):
|
| 73 |
+
return True
|
| 74 |
+
return False
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def contains_number_word(text):
|
| 78 |
+
# check if text contains a number word
|
| 79 |
+
ignore_words = ['a', 'an', 'point']
|
| 80 |
+
words = re.findall(r'\b\w+\b', text) # This regex pattern matches any word in the text
|
| 81 |
+
for word in words:
|
| 82 |
+
if word in ignore_words:
|
| 83 |
+
continue
|
| 84 |
+
try:
|
| 85 |
+
w2n.word_to_num(word)
|
| 86 |
+
return True # If the word can be converted to a number, return True
|
| 87 |
+
except ValueError:
|
| 88 |
+
continue # If the word can't be converted to a number, continue with the next word
|
| 89 |
+
|
| 90 |
+
# check if text contains a digit
|
| 91 |
+
if any(char.isdigit() for char in text):
|
| 92 |
+
return True
|
| 93 |
+
|
| 94 |
+
return False # If none of the words could be converted to a number, return False
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def contains_quantity_word(text, special_keep_words=[]):
|
| 98 |
+
# check if text contains a quantity word
|
| 99 |
+
quantity_words = ['most', 'least', 'fewest'
|
| 100 |
+
'more', 'less', 'fewer',
|
| 101 |
+
'largest', 'smallest', 'greatest',
|
| 102 |
+
'larger', 'smaller', 'greater',
|
| 103 |
+
'highest', 'lowest', 'higher', 'lower',
|
| 104 |
+
'increase', 'decrease',
|
| 105 |
+
'minimum', 'maximum', 'max', 'min',
|
| 106 |
+
'mean', 'average', 'median',
|
| 107 |
+
'total', 'sum', 'add', 'subtract',
|
| 108 |
+
'difference', 'quotient', 'gap',
|
| 109 |
+
'half', 'double', 'twice', 'triple',
|
| 110 |
+
'square', 'cube', 'root',
|
| 111 |
+
'approximate', 'approximation',
|
| 112 |
+
'triangle', 'rectangle', 'circle', 'square', 'cube', 'sphere', 'cylinder', 'cone', 'pyramid',
|
| 113 |
+
'multiply', 'divide',
|
| 114 |
+
'percentage', 'percent', 'ratio', 'proportion', 'fraction', 'rate',
|
| 115 |
+
]
|
| 116 |
+
|
| 117 |
+
quantity_words += special_keep_words # dataset specific words
|
| 118 |
+
|
| 119 |
+
words = re.findall(r'\b\w+\b', text) # This regex pattern matches any word in the text
|
| 120 |
+
if any(word in quantity_words for word in words):
|
| 121 |
+
return True
|
| 122 |
+
|
| 123 |
+
return False # If none of the words could be converted to a number, return False
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
def is_bool_word(text):
|
| 127 |
+
if text in ['Yes', 'No', 'True', 'False',
|
| 128 |
+
'yes', 'no', 'true', 'false',
|
| 129 |
+
'YES', 'NO', 'TRUE', 'FALSE']:
|
| 130 |
+
return True
|
| 131 |
+
return False
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
def is_digit_string(text):
|
| 135 |
+
# remove ".0000"
|
| 136 |
+
text = text.strip()
|
| 137 |
+
text = re.sub(r'\.0+$', '', text)
|
| 138 |
+
try:
|
| 139 |
+
int(text)
|
| 140 |
+
return True
|
| 141 |
+
except ValueError:
|
| 142 |
+
return False
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
def is_float_string(text):
|
| 146 |
+
# text is a float string if it contains a "." and can be converted to a float
|
| 147 |
+
if '.' in text:
|
| 148 |
+
try:
|
| 149 |
+
float(text)
|
| 150 |
+
return True
|
| 151 |
+
except ValueError:
|
| 152 |
+
return False
|
| 153 |
+
return False
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
def copy_image(image_path, output_image_path):
|
| 157 |
+
from shutil import copyfile
|
| 158 |
+
copyfile(image_path, output_image_path)
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
def copy_dir(src_dir, dst_dir):
|
| 162 |
+
from shutil import copytree
|
| 163 |
+
|
| 164 |
+
# copy the source directory to the target directory
|
| 165 |
+
copytree(src_dir, dst_dir)
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
import PIL.Image as Image
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
def get_image_size(img_path):
|
| 172 |
+
img = Image.open(img_path)
|
| 173 |
+
width, height = img.size
|
| 174 |
+
return width, height
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
def get_chat_response(
|
| 178 |
+
promot="", api_key="",
|
| 179 |
+
base_url="your_api_url",
|
| 180 |
+
api_version="2024-03-01-preview", model="gpt-4-0613",
|
| 181 |
+
temperature=0, max_tokens=256, n=1, patience=10000000, sleep_time=0
|
| 182 |
+
):
|
| 183 |
+
openai_client = openai.AzureOpenAI(
|
| 184 |
+
azure_endpoint=base_url,
|
| 185 |
+
api_version=api_version,
|
| 186 |
+
api_key=api_key,
|
| 187 |
+
)
|
| 188 |
+
|
| 189 |
+
messages = [
|
| 190 |
+
{'role': 'user', 'content': promot},
|
| 191 |
+
]
|
| 192 |
+
while patience > 0:
|
| 193 |
+
patience -= 1
|
| 194 |
+
try:
|
| 195 |
+
response = openai_client.chat.completions.create(
|
| 196 |
+
model=model,
|
| 197 |
+
messages=messages,
|
| 198 |
+
# api_key=api_key,
|
| 199 |
+
temperature=temperature,
|
| 200 |
+
max_tokens=max_tokens,
|
| 201 |
+
n=n,
|
| 202 |
+
)
|
| 203 |
+
response = response.to_dict()
|
| 204 |
+
if n == 1:
|
| 205 |
+
prediction = response['choices'][0]['message']['content'].strip()
|
| 206 |
+
if prediction != '' and prediction is not None:
|
| 207 |
+
return prediction
|
| 208 |
+
else:
|
| 209 |
+
prediction = [choice['message']['content'].strip() for choice in response['choices']]
|
| 210 |
+
if prediction[0] != '' and prediction[0] is not None:
|
| 211 |
+
return prediction
|
| 212 |
+
|
| 213 |
+
except Exception as e:
|
| 214 |
+
if 'Rate limit' not in str(e):
|
| 215 |
+
print(e)
|
| 216 |
+
|
| 217 |
+
if 'Please reduce the length of the messages' in str(e):
|
| 218 |
+
print('!!Reduce promot size')
|
| 219 |
+
# reduce input prompt and keep the tail
|
| 220 |
+
new_size = int(len(promot) * 0.9)
|
| 221 |
+
new_start = len(promot) - new_size
|
| 222 |
+
promot = promot[new_start:]
|
| 223 |
+
messages = [
|
| 224 |
+
{'role': 'user', 'content': promot},
|
| 225 |
+
]
|
| 226 |
+
|
| 227 |
+
if sleep_time > 0:
|
| 228 |
+
time.sleep(sleep_time)
|
| 229 |
+
return ''
|
eval/vlm/eval/mmbench/evaluate_mmbench.py
ADDED
|
@@ -0,0 +1,283 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023 OpenGVLab
|
| 2 |
+
# Copyright (c) 2025 Bytedance Ltd. and/or its affiliates.
|
| 3 |
+
# SPDX-License-Identifier: MIT
|
| 4 |
+
#
|
| 5 |
+
# This file has been modified by ByteDance Ltd. and/or its affiliates. on 2025-05-20.
|
| 6 |
+
#
|
| 7 |
+
# Original file was released under MIT, with the full license text
|
| 8 |
+
# available at https://github.com/OpenGVLab/InternVL/blob/main/LICENSE.
|
| 9 |
+
#
|
| 10 |
+
# This modified file is released under the same license.
|
| 11 |
+
|
| 12 |
+
import argparse
|
| 13 |
+
import base64
|
| 14 |
+
import itertools
|
| 15 |
+
import json
|
| 16 |
+
import os
|
| 17 |
+
import random
|
| 18 |
+
from io import BytesIO
|
| 19 |
+
|
| 20 |
+
import pandas as pd
|
| 21 |
+
import torch
|
| 22 |
+
from eval.vlm.utils import load_model_and_tokenizer, build_transform, process_conversation
|
| 23 |
+
from PIL import Image
|
| 24 |
+
from tqdm import tqdm
|
| 25 |
+
|
| 26 |
+
ds_collections = {
|
| 27 |
+
'mmbench_dev_20230712': {
|
| 28 |
+
'root': 'eval/vlm/data/mmbench/mmbench_dev_20230712.tsv',
|
| 29 |
+
'max_new_tokens': 100,
|
| 30 |
+
'min_new_tokens': 1,
|
| 31 |
+
'type': 'dev',
|
| 32 |
+
'language': 'en'
|
| 33 |
+
},
|
| 34 |
+
'mmbench_dev_cn_20231003': {
|
| 35 |
+
'root': 'eval/vlm/data/mmbench/mmbench_dev_cn_20231003.tsv',
|
| 36 |
+
'max_new_tokens': 100,
|
| 37 |
+
'min_new_tokens': 1,
|
| 38 |
+
'type': 'dev',
|
| 39 |
+
'language': 'cn'
|
| 40 |
+
},
|
| 41 |
+
'mmbench_dev_en_20231003': {
|
| 42 |
+
'root': 'eval/vlm/data/mmbench/mmbench_dev_en_20231003.tsv',
|
| 43 |
+
'max_new_tokens': 100,
|
| 44 |
+
'min_new_tokens': 1,
|
| 45 |
+
'type': 'dev',
|
| 46 |
+
'language': 'en'
|
| 47 |
+
},
|
| 48 |
+
'mmbench_test_cn_20231003': {
|
| 49 |
+
'root': 'eval/vlm/data/mmbench/mmbench_test_cn_20231003.tsv',
|
| 50 |
+
'max_new_tokens': 100,
|
| 51 |
+
'min_new_tokens': 1,
|
| 52 |
+
'type': 'test',
|
| 53 |
+
'language': 'cn'
|
| 54 |
+
},
|
| 55 |
+
'mmbench_test_en_20231003': {
|
| 56 |
+
'root': 'eval/vlm/data/mmbench/mmbench_test_en_20231003.tsv',
|
| 57 |
+
'max_new_tokens': 100,
|
| 58 |
+
'min_new_tokens': 1,
|
| 59 |
+
'type': 'test',
|
| 60 |
+
'language': 'en'
|
| 61 |
+
},
|
| 62 |
+
'ccbench_dev_cn': {
|
| 63 |
+
'root': 'eval/vlm/data/mmbench/CCBench_legacy.tsv',
|
| 64 |
+
'max_new_tokens': 100,
|
| 65 |
+
'min_new_tokens': 1,
|
| 66 |
+
'type': 'dev',
|
| 67 |
+
'language': 'cn'
|
| 68 |
+
}
|
| 69 |
+
}
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def collate_fn(batches):
|
| 73 |
+
questions = [_['question'] for _ in batches]
|
| 74 |
+
images = [_['images'] for _ in batches]
|
| 75 |
+
conversation = [_['conversation'] for _ in batches]
|
| 76 |
+
answers = [_['answer'] for _ in batches]
|
| 77 |
+
indexes = [_['index'] for _ in batches]
|
| 78 |
+
options = [_['option'] for _ in batches]
|
| 79 |
+
return questions, images, conversation, answers, indexes, options
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
class MMBenchDataset(torch.utils.data.Dataset):
|
| 83 |
+
|
| 84 |
+
def __init__(self, root, prompt, language):
|
| 85 |
+
self.df = pd.read_csv(root, sep='\t')
|
| 86 |
+
self.prompt = prompt
|
| 87 |
+
self.language = language
|
| 88 |
+
|
| 89 |
+
def __len__(self):
|
| 90 |
+
return len(self.df)
|
| 91 |
+
|
| 92 |
+
def __getitem__(self, idx):
|
| 93 |
+
index = self.df.iloc[idx]['index']
|
| 94 |
+
image = self.df.iloc[idx]['image']
|
| 95 |
+
question = self.df.iloc[idx]['question']
|
| 96 |
+
answer = self.df.iloc[idx]['answer'] if 'answer' in self.df.iloc[0].keys() else None
|
| 97 |
+
# catetory = self.df.iloc[idx]['category']
|
| 98 |
+
# l2_catetory = self.df.iloc[idx]['l2-category']
|
| 99 |
+
|
| 100 |
+
image = Image.open(BytesIO(base64.b64decode(image))).convert('RGB')
|
| 101 |
+
images = [image]
|
| 102 |
+
|
| 103 |
+
option_candidate = ['A', 'B', 'C', 'D', 'E']
|
| 104 |
+
options = {
|
| 105 |
+
cand: self.load_from_df(idx, cand)
|
| 106 |
+
for cand in option_candidate
|
| 107 |
+
if self.load_from_df(idx, cand) is not None
|
| 108 |
+
}
|
| 109 |
+
|
| 110 |
+
hint = self.load_from_df(idx, 'hint')
|
| 111 |
+
if hint is not None:
|
| 112 |
+
question = hint + '\n' + question
|
| 113 |
+
for key, item in options.items():
|
| 114 |
+
question += f'\n{key}. {item}'
|
| 115 |
+
if self.language == 'cn':
|
| 116 |
+
question = question + '\n' + self.prompt['cn']
|
| 117 |
+
else:
|
| 118 |
+
question = question + '\n' + self.prompt['en']
|
| 119 |
+
|
| 120 |
+
images, conversation = process_conversation(images, question)
|
| 121 |
+
|
| 122 |
+
return {
|
| 123 |
+
'question': question,
|
| 124 |
+
'images': images,
|
| 125 |
+
'conversation': conversation,
|
| 126 |
+
'answer': answer,
|
| 127 |
+
'index': index,
|
| 128 |
+
'option': options
|
| 129 |
+
}
|
| 130 |
+
|
| 131 |
+
def load_from_df(self, idx, key):
|
| 132 |
+
if key in self.df.iloc[idx] and not pd.isna(self.df.iloc[idx][key]):
|
| 133 |
+
return self.df.iloc[idx][key]
|
| 134 |
+
else:
|
| 135 |
+
return None
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
class InferenceSampler(torch.utils.data.sampler.Sampler):
|
| 139 |
+
|
| 140 |
+
def __init__(self, size):
|
| 141 |
+
self._size = int(size)
|
| 142 |
+
assert size > 0
|
| 143 |
+
self._rank = torch.distributed.get_rank()
|
| 144 |
+
self._world_size = torch.distributed.get_world_size()
|
| 145 |
+
self._local_indices = self._get_local_indices(size, self._world_size, self._rank)
|
| 146 |
+
|
| 147 |
+
@staticmethod
|
| 148 |
+
def _get_local_indices(total_size, world_size, rank):
|
| 149 |
+
shard_size = total_size // world_size
|
| 150 |
+
left = total_size % world_size
|
| 151 |
+
shard_sizes = [shard_size + int(r < left) for r in range(world_size)]
|
| 152 |
+
|
| 153 |
+
begin = sum(shard_sizes[:rank])
|
| 154 |
+
end = min(sum(shard_sizes[:rank + 1]), total_size)
|
| 155 |
+
return range(begin, end)
|
| 156 |
+
|
| 157 |
+
def __iter__(self):
|
| 158 |
+
yield from self._local_indices
|
| 159 |
+
|
| 160 |
+
def __len__(self):
|
| 161 |
+
return len(self._local_indices)
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
def post_process(pred, option):
|
| 165 |
+
pred = pred.strip()
|
| 166 |
+
option_candidate = list(option.keys())
|
| 167 |
+
if len(pred) == 1:
|
| 168 |
+
return pred
|
| 169 |
+
if len(pred) == 0:
|
| 170 |
+
pred = "C"
|
| 171 |
+
elif len(pred) != 1 and pred[0] in option_candidate:
|
| 172 |
+
return pred[0]
|
| 173 |
+
elif len(pred) != 1 and pred[0] not in option_candidate:
|
| 174 |
+
for k, v in option.items():
|
| 175 |
+
if v in pred:
|
| 176 |
+
return k
|
| 177 |
+
|
| 178 |
+
return pred
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
def evaluate_chat_model():
|
| 182 |
+
random.seed(args.seed)
|
| 183 |
+
|
| 184 |
+
for ds_name in args.datasets:
|
| 185 |
+
dataset = MMBenchDataset(
|
| 186 |
+
root=ds_collections[ds_name]['root'],
|
| 187 |
+
prompt=prompt,
|
| 188 |
+
language=ds_collections[ds_name]['language'],
|
| 189 |
+
)
|
| 190 |
+
dataloader = torch.utils.data.DataLoader(
|
| 191 |
+
dataset=dataset,
|
| 192 |
+
sampler=InferenceSampler(len(dataset)),
|
| 193 |
+
batch_size=args.batch_size,
|
| 194 |
+
num_workers=args.num_workers,
|
| 195 |
+
pin_memory=True,
|
| 196 |
+
drop_last=False,
|
| 197 |
+
collate_fn=collate_fn,
|
| 198 |
+
)
|
| 199 |
+
|
| 200 |
+
outputs = []
|
| 201 |
+
for _, (questions, images, conversation, answers, indexes, options) in tqdm(enumerate(dataloader)):
|
| 202 |
+
pred = model.chat(
|
| 203 |
+
tokenizer,
|
| 204 |
+
new_token_ids,
|
| 205 |
+
image_transform,
|
| 206 |
+
images=images[0], # batch=1
|
| 207 |
+
prompt=conversation[0], # batch=1
|
| 208 |
+
max_length=ds_collections[ds_name]['max_new_tokens'], # TODO: how to use ds_collections[ds_name]['min_new_tokens']
|
| 209 |
+
)
|
| 210 |
+
preds = [post_process(pred, options[0])]
|
| 211 |
+
|
| 212 |
+
for question, pred, answer, index in zip(questions, preds, answers, indexes):
|
| 213 |
+
outputs.append({
|
| 214 |
+
'question': question,
|
| 215 |
+
'answer': pred,
|
| 216 |
+
'gt_answers': answer,
|
| 217 |
+
'index': int(index)
|
| 218 |
+
})
|
| 219 |
+
|
| 220 |
+
torch.distributed.barrier()
|
| 221 |
+
|
| 222 |
+
world_size = torch.distributed.get_world_size()
|
| 223 |
+
merged_outputs = [None for _ in range(world_size)]
|
| 224 |
+
torch.distributed.all_gather_object(merged_outputs, json.dumps(outputs))
|
| 225 |
+
|
| 226 |
+
merged_outputs = [json.loads(_) for _ in merged_outputs]
|
| 227 |
+
merged_outputs = [_ for _ in itertools.chain.from_iterable(merged_outputs)]
|
| 228 |
+
|
| 229 |
+
if torch.distributed.get_rank() == 0:
|
| 230 |
+
print(f'Evaluating {ds_name} ...')
|
| 231 |
+
results_file = 'results.xlsx'
|
| 232 |
+
output_path = os.path.join(args.out_dir, results_file)
|
| 233 |
+
df = pd.read_table(ds_collections[ds_name]['root'])
|
| 234 |
+
cur_df = df.copy()
|
| 235 |
+
if 'mmbench' in ds_name:
|
| 236 |
+
cur_df = cur_df.drop(columns=['hint', 'category', 'source', 'image', 'comment', 'l2-category'])
|
| 237 |
+
cur_df.insert(6, 'prediction', None)
|
| 238 |
+
else:
|
| 239 |
+
cur_df = cur_df.drop(columns=['category', 'image'])
|
| 240 |
+
cur_df.insert(8, 'prediction', None)
|
| 241 |
+
for item in merged_outputs:
|
| 242 |
+
cur_df.loc[df['index'] == item['index'], 'prediction'] = item['answer']
|
| 243 |
+
|
| 244 |
+
cur_df.to_excel(output_path, index=False, engine='openpyxl')
|
| 245 |
+
print('Results saved to {}'.format(output_path))
|
| 246 |
+
|
| 247 |
+
|
| 248 |
+
if __name__ == '__main__':
|
| 249 |
+
parser = argparse.ArgumentParser()
|
| 250 |
+
parser.add_argument('--datasets', type=str, default='mmbench_dev_20230712')
|
| 251 |
+
parser.add_argument('--batch-size', type=int, default=1)
|
| 252 |
+
parser.add_argument('--num-workers', type=int, default=1)
|
| 253 |
+
parser.add_argument('--out-dir', type=str, default='results')
|
| 254 |
+
parser.add_argument('--seed', type=int, default=0)
|
| 255 |
+
parser.add_argument('--model-path', type=str, default='hf/BAGEL-7B-MoT/')
|
| 256 |
+
args = parser.parse_args()
|
| 257 |
+
|
| 258 |
+
if not os.path.exists(args.out_dir):
|
| 259 |
+
os.makedirs(args.out_dir, exist_ok=True)
|
| 260 |
+
|
| 261 |
+
args.datasets = args.datasets.split(',')
|
| 262 |
+
print('datasets:', args.datasets)
|
| 263 |
+
assert args.batch_size == 1, 'Only batch size 1 is supported'
|
| 264 |
+
|
| 265 |
+
torch.distributed.init_process_group(
|
| 266 |
+
backend='nccl',
|
| 267 |
+
world_size=int(os.getenv('WORLD_SIZE', '1')),
|
| 268 |
+
rank=int(os.getenv('RANK', '0')),
|
| 269 |
+
)
|
| 270 |
+
|
| 271 |
+
torch.cuda.set_device(int(os.getenv('LOCAL_RANK', 0)))
|
| 272 |
+
|
| 273 |
+
model, tokenizer, new_token_ids = load_model_and_tokenizer(args)
|
| 274 |
+
image_transform = build_transform()
|
| 275 |
+
|
| 276 |
+
total_params = sum(p.numel() for p in model.parameters()) / 1e9
|
| 277 |
+
print(f'[test] total_params: {total_params}B')
|
| 278 |
+
|
| 279 |
+
prompt = {
|
| 280 |
+
'en': "Answer with the option's letter from the given choices directly.",
|
| 281 |
+
'cn': '请直接回答选项字母。'
|
| 282 |
+
}
|
| 283 |
+
evaluate_chat_model()
|
eval/vlm/eval/mme/Your_Results/OCR.txt
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
0001.jpg Is the word in the logo "angie's"? Please answer yes or no. Yes
|
| 2 |
+
0001.jpg Is the word in the logo "angle's"? Please answer yes or no. No
|
| 3 |
+
0002.jpg Is the word in the logo "c'est cheese"? Please answer yes or no. Yes
|
| 4 |
+
0002.jpg Is the word in the logo "crest cheese"? Please answer yes or no. No
|
| 5 |
+
0003.jpg Is the word in the logo "beavertails pastry"? Please answer yes or no. Yes
|
| 6 |
+
0003.jpg Is the word in the logo "beavertalls pastry"? Please answer yes or no. No
|
| 7 |
+
0004.jpg Is the word in the logo "old market sundries"? Please answer yes or no. Yes
|
| 8 |
+
0004.jpg Is the word in the logo "old market hundreds"? Please answer yes or no. No
|
| 9 |
+
0005.jpg Is the word in the logo "kress"? Please answer yes or no. Yes
|
| 10 |
+
0005.jpg Is the word in the logo "dress"? Please answer yes or no. No
|
| 11 |
+
0006.jpg Is the word in the logo "the beatles story liver pool"? Please answer yes or no. Yes
|
| 12 |
+
0006.jpg Is the word in the logo "the beats story liver pool"? Please answer yes or no. No
|
| 13 |
+
0007.jpg Is the phone number in the picture "0131 555 6363"? Please answer yes or no. Yes
|
| 14 |
+
0007.jpg Is the phone number in the picture "0137 556 6363"? Please answer yes or no. No
|
| 15 |
+
0008.jpg Is the word in the logo "phil's market"? Please answer yes or no. Yes
|
| 16 |
+
0008.jpg Is the word in the logo "phll's market"? Please answer yes or no. No
|
| 17 |
+
0009.jpg Is the word in the logo "fenders diner"? Please answer yes or no. Yes
|
| 18 |
+
0009.jpg Is the word in the logo "finders diner"? Please answer yes or no. No
|
| 19 |
+
0010.jpg Is the word in the logo "high time coffee shop"? Please answer yes or no. Yes
|
| 20 |
+
0010.jpg Is the word in the logo "high tite cofeee shop"? Please answer yes or no. No
|
| 21 |
+
0011.jpg Is the word in the logo "ihop restaurant"? Please answer yes or no. Yes
|
| 22 |
+
0011.jpg Is the word in the logo "lhop restaurant"? Please answer yes or no. No
|
| 23 |
+
0012.jpg Is the word in the logo "casa grecque restaurants"? Please answer yes or no. Yes
|
| 24 |
+
0012.jpg Is the word in the logo "case grecque restaurants"? Please answer yes or no. No
|
| 25 |
+
0013.jpg Is the word in the picture "seabreeze motel"? Please answer yes or no. Yes
|
| 26 |
+
0013.jpg Is the word in the picture "seebreeze model"? Please answer yes or no. No
|
| 27 |
+
0014.jpg Is the word in the logo "penarth pier built 1894"? Please answer yes or no. Yes
|
| 28 |
+
0014.jpg Is the word in the logo "penarth pies buid 1894"? Please answer yes or no. No
|
| 29 |
+
0015.jpg Is the text in the picture "hollywood"? Please answer yes or no. Yes
|
| 30 |
+
0015.jpg Is the text in the picture "holly word"? Please answer yes or no. No
|
| 31 |
+
0016.jpg Is the word in the logo "shop rite"? Please answer yes or no. Yes
|
| 32 |
+
0016.jpg Is the word in the logo "stop rite"? Please answer yes or no. No
|
| 33 |
+
0017.jpg Is the word in the logo "hardco industrial construction"? Please answer yes or no. Yes
|
| 34 |
+
0017.jpg Is the word in the logo "hardto industal construction"? Please answer yes or no. No
|
| 35 |
+
0018.jpg Is the word in the logo "oldsmobile service"? Please answer yes or no. Yes
|
| 36 |
+
0018.jpg Is the word in the logo "old mobile service"? Please answer yes or no. No
|
| 37 |
+
0019.jpg Is the word in the logo "exchange hotel"? Please answer yes or no. Yes
|
| 38 |
+
0019.jpg Is the word in the logo "excharge hotel"? Please answer yes or no. No
|
| 39 |
+
0020.jpg Is the word in the logo "cold drinks"? Please answer yes or no. Yes
|
| 40 |
+
0020.jpg Is the word in the logo "cold rinks"? Please answer yes or no. No
|
eval/vlm/eval/mme/Your_Results/artwork.txt
ADDED
|
@@ -0,0 +1,400 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
10002.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 2 |
+
10002.jpg Does this artwork exist in the form of glassware? Please answer yes or no. No
|
| 3 |
+
10049.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 4 |
+
10049.jpg Does this artwork exist in the form of sculpture? Please answer yes or no. No
|
| 5 |
+
10256.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 6 |
+
10256.jpg Does this artwork exist in the form of sculpture? Please answer yes or no. No
|
| 7 |
+
10358.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 8 |
+
10358.jpg Does this artwork exist in the form of glassware? Please answer yes or no. No
|
| 9 |
+
10543.jpg Is this artwork displayed in fogg art museum, harvard university, cambridge? Please answer yes or no. Yes
|
| 10 |
+
10543.jpg Is this artwork displayed in museo civico, pistoia? Please answer yes or no. No
|
| 11 |
+
10581.jpg Does this artwork belong to the type of portrait? Please answer yes or no. Yes
|
| 12 |
+
10581.jpg Does this artwork belong to the type of genre? Please answer yes or no. No
|
| 13 |
+
1060.jpg Is this artwork created by antoniazzo romano? Please answer yes or no. Yes
|
| 14 |
+
1060.jpg Is this artwork created by gentile da fabriano? Please answer yes or no. No
|
| 15 |
+
10881.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 16 |
+
10881.jpg Does this artwork exist in the form of tapestry? Please answer yes or no. No
|
| 17 |
+
10970.jpg Does this artwork belong to the type of religious? Please answer yes or no. Yes
|
| 18 |
+
10970.jpg Does this artwork belong to the type of study? Please answer yes or no. No
|
| 19 |
+
11276.jpg Does this artwork exist in the form of sculpture? Please answer yes or no. Yes
|
| 20 |
+
11276.jpg Does this artwork exist in the form of graphics? Please answer yes or no. No
|
| 21 |
+
11331.jpg Is this artwork created by donatello? Please answer yes or no. Yes
|
| 22 |
+
11331.jpg Is this artwork created by zichy, mihály? Please answer yes or no. No
|
| 23 |
+
11488.jpg Does this artwork belong to the type of mythological? Please answer yes or no. Yes
|
| 24 |
+
11488.jpg Does this artwork belong to the type of historical? Please answer yes or no. No
|
| 25 |
+
11724.jpg Is this artwork created by duccio di buoninsegna? Please answer yes or no. Yes
|
| 26 |
+
11724.jpg Is this artwork created by giani, felice? Please answer yes or no. No
|
| 27 |
+
11726.jpg Is this artwork titled temptation on the mountain (detail)? Please answer yes or no. Yes
|
| 28 |
+
11726.jpg Is this artwork titled in the forest of fontainebleau? Please answer yes or no. No
|
| 29 |
+
12133.jpg Is this artwork titled hand study with bible? Please answer yes or no. Yes
|
| 30 |
+
12133.jpg Is this artwork titled self-portrait aged 78? Please answer yes or no. No
|
| 31 |
+
12439.jpg Is this artwork created by dürer, albrecht? Please answer yes or no. Yes
|
| 32 |
+
12439.jpg Is this artwork created by koekkoek, barend cornelis? Please answer yes or no. No
|
| 33 |
+
12561.jpg Is this artwork created by eberlein, gustav heinrich? Please answer yes or no. Yes
|
| 34 |
+
12561.jpg Is this artwork created by gillemans, jan pauwel the younger? Please answer yes or no. No
|
| 35 |
+
12652.jpg Is this artwork displayed in stedelijk museum de lakenhal, leiden? Please answer yes or no. Yes
|
| 36 |
+
12652.jpg Is this artwork displayed in palazzo ducale, mantua? Please answer yes or no. No
|
| 37 |
+
12736.jpg Is this artwork displayed in cannon hall museum, barnsley? Please answer yes or no. Yes
|
| 38 |
+
12736.jpg Is this artwork displayed in protestant parish church, gelnhausen? Please answer yes or no. No
|
| 39 |
+
12902.jpg Is this artwork displayed in private collection? Please answer yes or no. Yes
|
| 40 |
+
12902.jpg Is this artwork displayed in musée national gustave-moreau, paris? Please answer yes or no. No
|
| 41 |
+
12908.jpg Is this artwork titled ruth and boaz? Please answer yes or no. Yes
|
| 42 |
+
12908.jpg Is this artwork titled view of dresden from the right bank of the elbe with the augustus bridge? Please answer yes or no. No
|
| 43 |
+
13091.jpg Is this artwork titled italianate landscape with figures by classical ruins? Please answer yes or no. Yes
|
| 44 |
+
13091.jpg Is this artwork titled two boys singing? Please answer yes or no. No
|
| 45 |
+
13174.jpg Is this artwork titled nobility? Please answer yes or no. Yes
|
| 46 |
+
13174.jpg Is this artwork titled aretino in the studio of tintoretto? Please answer yes or no. No
|
| 47 |
+
13239.jpg Is this artwork titled doge ziani receiving the benediction of pope alexander iii? Please answer yes or no. Yes
|
| 48 |
+
13239.jpg Is this artwork titled the adoration of the shepherds? Please answer yes or no. No
|
| 49 |
+
13288.jpg Does this artwork exist in the form of architecture? Please answer yes or no. Yes
|
| 50 |
+
13288.jpg Does this artwork exist in the form of metalwork? Please answer yes or no. No
|
| 51 |
+
13696.jpg Is this artwork displayed in pinacoteca nazionale, siena? Please answer yes or no. Yes
|
| 52 |
+
13696.jpg Is this artwork displayed in british embassy, paris? Please answer yes or no. No
|
| 53 |
+
13760.jpg Is this artwork titled noli me tangere? Please answer yes or no. Yes
|
| 54 |
+
13760.jpg Is this artwork titled profile study of a bearded man? Please answer yes or no. No
|
| 55 |
+
13821.jpg Is this artwork created by frangipane, niccolò? Please answer yes or no. Yes
|
| 56 |
+
13821.jpg Is this artwork created by drevet, pierre? Please answer yes or no. No
|
| 57 |
+
13901.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 58 |
+
13901.jpg Does this artwork exist in the form of metalwork? Please answer yes or no. No
|
| 59 |
+
14283.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 60 |
+
14283.jpg Does this artwork exist in the form of mosaic? Please answer yes or no. No
|
| 61 |
+
14499.jpg Does this artwork belong to the type of religious? Please answer yes or no. Yes
|
| 62 |
+
14499.jpg Does this artwork belong to the type of mythological? Please answer yes or no. No
|
| 63 |
+
14777.jpg Does this artwork belong to the type of religious? Please answer yes or no. Yes
|
| 64 |
+
14777.jpg Does this artwork belong to the type of historical? Please answer yes or no. No
|
| 65 |
+
15028.jpg Does this artwork belong to the type of portrait? Please answer yes or no. Yes
|
| 66 |
+
15028.jpg Does this artwork belong to the type of study? Please answer yes or no. No
|
| 67 |
+
15232.jpg Is this artwork created by giordano, luca? Please answer yes or no. Yes
|
| 68 |
+
15232.jpg Is this artwork created by heyerdahl, hans olaf? Please answer yes or no. No
|
| 69 |
+
15246.jpg Is this artwork displayed in palazzo medici riccardi, florence? Please answer yes or no. Yes
|
| 70 |
+
15246.jpg Is this artwork displayed in abbey church of sainte-foy, conques (aveyron)? Please answer yes or no. No
|
| 71 |
+
15311.jpg Is this artwork created by giorgione? Please answer yes or no. Yes
|
| 72 |
+
15311.jpg Is this artwork created by marilhat, prosper? Please answer yes or no. No
|
| 73 |
+
15989.jpg Is this artwork displayed in pinacoteca, vatican? Please answer yes or no. Yes
|
| 74 |
+
15989.jpg Is this artwork displayed in cathedral museum, zamora? Please answer yes or no. No
|
| 75 |
+
16006.jpg Is this artwork displayed in private collection? Please answer yes or no. Yes
|
| 76 |
+
16006.jpg Is this artwork displayed in cathedral of san geminiano, modena? Please answer yes or no. No
|
| 77 |
+
16249.jpg Does this artwork belong to the type of landscape? Please answer yes or no. Yes
|
| 78 |
+
16249.jpg Does this artwork belong to the type of religious? Please answer yes or no. No
|
| 79 |
+
16538.jpg Is this artwork created by gogh, vincent van? Please answer yes or no. Yes
|
| 80 |
+
16538.jpg Is this artwork created by altdorfer, albrecht? Please answer yes or no. No
|
| 81 |
+
16835.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 82 |
+
16835.jpg Does this artwork exist in the form of illumination? Please answer yes or no. No
|
| 83 |
+
16911.jpg Is this artwork created by gossart, jan? Please answer yes or no. Yes
|
| 84 |
+
16911.jpg Is this artwork created by stanzione, massimo? Please answer yes or no. No
|
| 85 |
+
17311.jpg Does this artwork belong to the type of religious? Please answer yes or no. Yes
|
| 86 |
+
17311.jpg Does this artwork belong to the type of interior? Please answer yes or no. No
|
| 87 |
+
17317.jpg Is this artwork created by gozzoli, benozzo? Please answer yes or no. Yes
|
| 88 |
+
17317.jpg Is this artwork created by coriolano, cristoforo? Please answer yes or no. No
|
| 89 |
+
17535.jpg Is this artwork created by grebber, pieter de? Please answer yes or no. Yes
|
| 90 |
+
17535.jpg Is this artwork created by massys, quentin? Please answer yes or no. No
|
| 91 |
+
17823.jpg Is this artwork created by greuze, jean-baptiste? Please answer yes or no. Yes
|
| 92 |
+
17823.jpg Is this artwork created by landseer, sir edwin henry? Please answer yes or no. No
|
| 93 |
+
17838.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 94 |
+
17838.jpg Does this artwork exist in the form of furniture? Please answer yes or no. No
|
| 95 |
+
17998.jpg Does this artwork belong to the type of religious? Please answer yes or no. Yes
|
| 96 |
+
17998.jpg Does this artwork belong to the type of genre? Please answer yes or no. No
|
| 97 |
+
18566.jpg Is this artwork created by hamen, juan van der? Please answer yes or no. Yes
|
| 98 |
+
18566.jpg Is this artwork created by starnina, gherardo di jacopo? Please answer yes or no. No
|
| 99 |
+
18604.jpg Is this artwork created by hardouin-mansart, jules? Please answer yes or no. Yes
|
| 100 |
+
18604.jpg Is this artwork created by kerseboom, friedrich? Please answer yes or no. No
|
| 101 |
+
18722.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 102 |
+
18722.jpg Does this artwork exist in the form of sculpture? Please answer yes or no. No
|
| 103 |
+
1873.jpg Does this artwork exist in the form of architecture? Please answer yes or no. Yes
|
| 104 |
+
1873.jpg Does this artwork exist in the form of painting? Please answer yes or no. No
|
| 105 |
+
18902.jpg Is this artwork created by herrera, francisco de, the elder? Please answer yes or no. Yes
|
| 106 |
+
18902.jpg Is this artwork created by ingres, jean-auguste-dominique? Please answer yes or no. No
|
| 107 |
+
18926.jpg Is this artwork created by herring, john frederick the younger? Please answer yes or no. Yes
|
| 108 |
+
18926.jpg Is this artwork created by cozens, john robert? Please answer yes or no. No
|
| 109 |
+
19087.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 110 |
+
19087.jpg Does this artwork exist in the form of metalwork? Please answer yes or no. No
|
| 111 |
+
19154.jpg Is this artwork titled portrait of the merchant georg gisze (detail)? Please answer yes or no. Yes
|
| 112 |
+
19154.jpg Is this artwork titled pair of table candlesticks? Please answer yes or no. No
|
| 113 |
+
19417.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 114 |
+
19417.jpg Does this artwork exist in the form of mosaic? Please answer yes or no. No
|
| 115 |
+
19452.jpg Is this artwork titled the artist and his model? Please answer yes or no. Yes
|
| 116 |
+
19452.jpg Is this artwork titled the lovesick maiden (detail)? Please answer yes or no. No
|
| 117 |
+
19839.jpg Is this artwork created by janneck, franz christoph? Please answer yes or no. Yes
|
| 118 |
+
19839.jpg Is this artwork created by goupil, jules-adolphe? Please answer yes or no. No
|
| 119 |
+
19863.jpg Does this artwork belong to the type of religious? Please answer yes or no. Yes
|
| 120 |
+
19863.jpg Does this artwork belong to the type of mythological? Please answer yes or no. No
|
| 121 |
+
19993.jpg Is this artwork displayed in private collection? Please answer yes or no. Yes
|
| 122 |
+
19993.jpg Is this artwork displayed in cathedral of st paul, liège? Please answer yes or no. No
|
| 123 |
+
20176.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 124 |
+
20176.jpg Does this artwork exist in the form of furniture? Please answer yes or no. No
|
| 125 |
+
20437.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 126 |
+
20437.jpg Does this artwork exist in the form of tapestry? Please answer yes or no. No
|
| 127 |
+
20442.jpg Is this artwork created by kucharski, aleksander? Please answer yes or no. Yes
|
| 128 |
+
20442.jpg Is this artwork created by pourbus, frans the elder? Please answer yes or no. No
|
| 129 |
+
20455.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 130 |
+
20455.jpg Does this artwork exist in the form of metalwork? Please answer yes or no. No
|
| 131 |
+
20483.jpg Is this artwork titled allegory of the regency? Please answer yes or no. Yes
|
| 132 |
+
20483.jpg Is this artwork titled breton woman bathing? Please answer yes or no. No
|
| 133 |
+
20490.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 134 |
+
20490.jpg Does this artwork exist in the form of illumination? Please answer yes or no. No
|
| 135 |
+
20551.jpg Is this artwork created by lagrenée, jean-jacques? Please answer yes or no. Yes
|
| 136 |
+
20551.jpg Is this artwork created by scultori, diana? Please answer yes or no. No
|
| 137 |
+
20651.jpg Is this artwork titled a highland landscape? Please answer yes or no. Yes
|
| 138 |
+
20651.jpg Is this artwork titled a dog and a cat fighting in a kitchen interior? Please answer yes or no. No
|
| 139 |
+
20724.jpg Does this artwork belong to the type of portrait? Please answer yes or no. Yes
|
| 140 |
+
20724.jpg Does this artwork belong to the type of landscape? Please answer yes or no. No
|
| 141 |
+
21048.jpg Is this artwork created by lemoyne, jean-baptiste ii? Please answer yes or no. Yes
|
| 142 |
+
21048.jpg Is this artwork created by kneller, sir godfrey? Please answer yes or no. No
|
| 143 |
+
21097.jpg Does this artwork belong to the type of religious? Please answer yes or no. Yes
|
| 144 |
+
21097.jpg Does this artwork belong to the type of genre? Please answer yes or no. No
|
| 145 |
+
21244.jpg Does this artwork belong to the type of study? Please answer yes or no. Yes
|
| 146 |
+
21244.jpg Does this artwork belong to the type of portrait? Please answer yes or no. No
|
| 147 |
+
21469.jpg Does this artwork belong to the type of genre? Please answer yes or no. Yes
|
| 148 |
+
21469.jpg Does this artwork belong to the type of still-life? Please answer yes or no. No
|
| 149 |
+
21580.jpg Is this artwork created by linard, jacques? Please answer yes or no. Yes
|
| 150 |
+
21580.jpg Is this artwork created by bonino da campione? Please answer yes or no. No
|
| 151 |
+
21712.jpg Is this artwork titled st john the evangelist resuscitating drusiana? Please answer yes or no. Yes
|
| 152 |
+
21712.jpg Is this artwork titled la finette? Please answer yes or no. No
|
| 153 |
+
22329.jpg Is this artwork titled marriage of the virgin? Please answer yes or no. Yes
|
| 154 |
+
22329.jpg Is this artwork titled landscape with river and figures (detail)? Please answer yes or no. No
|
| 155 |
+
22366.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 156 |
+
22366.jpg Does this artwork exist in the form of glassware? Please answer yes or no. No
|
| 157 |
+
22667.jpg Is this artwork displayed in private collection? Please answer yes or no. Yes
|
| 158 |
+
22667.jpg Is this artwork displayed in san francesco d'assisi, pavia? Please answer yes or no. No
|
| 159 |
+
22760.jpg Is this artwork titled madonna and child (detail)? Please answer yes or no. Yes
|
| 160 |
+
22760.jpg Is this artwork titled view of the south and east walls? Please answer yes or no. No
|
| 161 |
+
22842.jpg Is this artwork titled ukrainian peasant girl? Please answer yes or no. Yes
|
| 162 |
+
22842.jpg Is this artwork titled virtue crowning merit? Please answer yes or no. No
|
| 163 |
+
23229.jpg Is this artwork displayed in national gallery, london? Please answer yes or no. Yes
|
| 164 |
+
23229.jpg Is this artwork displayed in notre-dame-la-riche, tours? Please answer yes or no. No
|
| 165 |
+
23427.jpg Is this artwork displayed in the hermitage, st. petersburg? Please answer yes or no. Yes
|
| 166 |
+
23427.jpg Is this artwork displayed in national gallery of victoria, melbourne? Please answer yes or no. No
|
| 167 |
+
23465.jpg Is this artwork displayed in private collection? Please answer yes or no. Yes
|
| 168 |
+
23465.jpg Is this artwork displayed in cistertian church, zirc? Please answer yes or no. No
|
| 169 |
+
23824.jpg Is this artwork titled christ walking on the water? Please answer yes or no. Yes
|
| 170 |
+
23824.jpg Is this artwork titled mademoiselle romaine lacaux? Please answer yes or no. No
|
| 171 |
+
24122.jpg Is this artwork displayed in museo correr, venice? Please answer yes or no. Yes
|
| 172 |
+
24122.jpg Is this artwork displayed in church of brou, bourg-en-bresse? Please answer yes or no. No
|
| 173 |
+
24260.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 174 |
+
24260.jpg Does this artwork exist in the form of illumination? Please answer yes or no. No
|
| 175 |
+
24291.jpg Is this artwork titled virgin and child with sts catherine, cecilia, barbara, and ursula? Please answer yes or no. Yes
|
| 176 |
+
24291.jpg Is this artwork titled sorrow? Please answer yes or no. No
|
| 177 |
+
24723.jpg Is this artwork titled tomb of henry the lion and his wife matilda? Please answer yes or no. Yes
|
| 178 |
+
24723.jpg Is this artwork titled god the father? Please answer yes or no. No
|
| 179 |
+
2490.jpg Does this artwork belong to the type of landscape? Please answer yes or no. Yes
|
| 180 |
+
2490.jpg Does this artwork belong to the type of mythological? Please answer yes or no. No
|
| 181 |
+
2507.jpg Is this artwork displayed in private collection? Please answer yes or no. Yes
|
| 182 |
+
2507.jpg Is this artwork displayed in st. vitus's cathedral, prague? Please answer yes or no. No
|
| 183 |
+
25312.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 184 |
+
25312.jpg Does this artwork exist in the form of metalwork? Please answer yes or no. No
|
| 185 |
+
25476.jpg Is this artwork created by michelangelo buonarroti? Please answer yes or no. Yes
|
| 186 |
+
25476.jpg Is this artwork created by beuckelaer, joachim? Please answer yes or no. No
|
| 187 |
+
25492.jpg Does this artwork exist in the form of sculpture? Please answer yes or no. Yes
|
| 188 |
+
25492.jpg Does this artwork exist in the form of illumination? Please answer yes or no. No
|
| 189 |
+
25513.jpg Does this artwork belong to the type of religious? Please answer yes or no. Yes
|
| 190 |
+
25513.jpg Does this artwork belong to the type of landscape? Please answer yes or no. No
|
| 191 |
+
26521.jpg Does this artwork exist in the form of illumination? Please answer yes or no. Yes
|
| 192 |
+
26521.jpg Does this artwork exist in the form of furniture? Please answer yes or no. No
|
| 193 |
+
26973.jpg Does this artwork belong to the type of religious? Please answer yes or no. Yes
|
| 194 |
+
26973.jpg Does this artwork belong to the type of mythological? Please answer yes or no. No
|
| 195 |
+
27021.jpg Is this artwork created by miniaturist, german? Please answer yes or no. Yes
|
| 196 |
+
27021.jpg Is this artwork created by trinquesse, louis-rolland? Please answer yes or no. No
|
| 197 |
+
27662.jpg Does this artwork belong to the type of still-life? Please answer yes or no. Yes
|
| 198 |
+
27662.jpg Does this artwork belong to the type of mythological? Please answer yes or no. No
|
| 199 |
+
27936.jpg Does this artwork belong to the type of portrait? Please answer yes or no. Yes
|
| 200 |
+
27936.jpg Does this artwork belong to the type of interior? Please answer yes or no. No
|
| 201 |
+
28039.jpg Is this artwork displayed in cappella palatina, palermo? Please answer yes or no. Yes
|
| 202 |
+
28039.jpg Is this artwork displayed in musée des beaux-arts, chambéry? Please answer yes or no. No
|
| 203 |
+
28345.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 204 |
+
28345.jpg Does this artwork exist in the form of tapestry? Please answer yes or no. No
|
| 205 |
+
28400.jpg Does this artwork belong to the type of religious? Please answer yes or no. Yes
|
| 206 |
+
28400.jpg Does this artwork belong to the type of portrait? Please answer yes or no. No
|
| 207 |
+
28698.jpg Does this artwork belong to the type of religious? Please answer yes or no. Yes
|
| 208 |
+
28698.jpg Does this artwork belong to the type of still-life? Please answer yes or no. No
|
| 209 |
+
28758.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 210 |
+
28758.jpg Does this artwork exist in the form of graphics? Please answer yes or no. No
|
| 211 |
+
28974.jpg Is this artwork titled prayer before the meal? Please answer yes or no. Yes
|
| 212 |
+
28974.jpg Is this artwork titled rest in the mountains? Please answer yes or no. No
|
| 213 |
+
29266.jpg Is this artwork created by palma vecchio? Please answer yes or no. Yes
|
| 214 |
+
29266.jpg Is this artwork created by maris, jacobus hendricus? Please answer yes or no. No
|
| 215 |
+
30443.jpg Is this artwork titled the crucifixion with sts jerome and christopher? Please answer yes or no. Yes
|
| 216 |
+
30443.jpg Is this artwork titled tomb of michelangelo (detail)? Please answer yes or no. No
|
| 217 |
+
3085.jpg Is this artwork created by bartsius, willem? Please answer yes or no. Yes
|
| 218 |
+
3085.jpg Is this artwork created by oehme, ernst ferdinand? Please answer yes or no. No
|
| 219 |
+
30875.jpg Is this artwork created by pomarancio? Please answer yes or no. Yes
|
| 220 |
+
30875.jpg Is this artwork created by steen, jan? Please answer yes or no. No
|
| 221 |
+
3114.jpg Does this artwork belong to the type of religious? Please answer yes or no. Yes
|
| 222 |
+
3114.jpg Does this artwork belong to the type of study? Please answer yes or no. No
|
| 223 |
+
31808.jpg Is this artwork created by raffaello sanzio? Please answer yes or no. Yes
|
| 224 |
+
31808.jpg Is this artwork created by simon von taisten? Please answer yes or no. No
|
| 225 |
+
32147.jpg Is this artwork titled lucretia? Please answer yes or no. Yes
|
| 226 |
+
32147.jpg Is this artwork titled rinaldo abandoning armida (detail)? Please answer yes or no. No
|
| 227 |
+
3241.jpg Is this artwork titled holy family? Please answer yes or no. Yes
|
| 228 |
+
3241.jpg Is this artwork titled friedrich iii, the wise, and johann i, the constant, electors of saxony? Please answer yes or no. No
|
| 229 |
+
33017.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 230 |
+
33017.jpg Does this artwork exist in the form of glassware? Please answer yes or no. No
|
| 231 |
+
33069.jpg Does this artwork belong to the type of historical? Please answer yes or no. Yes
|
| 232 |
+
33069.jpg Does this artwork belong to the type of interior? Please answer yes or no. No
|
| 233 |
+
33173.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 234 |
+
33173.jpg Does this artwork exist in the form of graphics? Please answer yes or no. No
|
| 235 |
+
33753.jpg Is this artwork titled vanitas? Please answer yes or no. Yes
|
| 236 |
+
33753.jpg Is this artwork titled legend of st francis: 18. apparition at arles (detail)? Please answer yes or no. No
|
| 237 |
+
33854.jpg Does this artwork belong to the type of religious? Please answer yes or no. Yes
|
| 238 |
+
33854.jpg Does this artwork belong to the type of study? Please answer yes or no. No
|
| 239 |
+
339.jpg Is this artwork displayed in staatliche museen, berlin? Please answer yes or no. Yes
|
| 240 |
+
339.jpg Is this artwork displayed in national museum of religious carvings, valladolid? Please answer yes or no. No
|
| 241 |
+
33933.jpg Is this artwork titled madonna and child? Please answer yes or no. Yes
|
| 242 |
+
33933.jpg Is this artwork titled the bacino di san marco? Please answer yes or no. No
|
| 243 |
+
3404.jpg Is this artwork displayed in szépmûvészeti múzeum, budapest? Please answer yes or no. Yes
|
| 244 |
+
3404.jpg Is this artwork displayed in s. eustorgio, milan? Please answer yes or no. No
|
| 245 |
+
34109.jpg Is this artwork displayed in national gallery of art, washington? Please answer yes or no. Yes
|
| 246 |
+
34109.jpg Is this artwork displayed in abbey church of sainte-foy, conques? Please answer yes or no. No
|
| 247 |
+
34363.jpg Is this artwork displayed in museo del prado, madrid? Please answer yes or no. Yes
|
| 248 |
+
34363.jpg Is this artwork displayed in state tretyakov gallery, moscow? Please answer yes or no. No
|
| 249 |
+
34539.jpg Is this artwork titled the victory of eucharistic truth over heresy? Please answer yes or no. Yes
|
| 250 |
+
34539.jpg Is this artwork titled a sunday afternoon on the ile de la grande jatte? Please answer yes or no. No
|
| 251 |
+
34627.jpg Does this artwork belong to the type of landscape? Please answer yes or no. Yes
|
| 252 |
+
34627.jpg Does this artwork belong to the type of genre? Please answer yes or no. No
|
| 253 |
+
34638.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 254 |
+
34638.jpg Does this artwork exist in the form of tapestry? Please answer yes or no. No
|
| 255 |
+
34669.jpg Does this artwork belong to the type of mythological? Please answer yes or no. Yes
|
| 256 |
+
34669.jpg Does this artwork belong to the type of historical? Please answer yes or no. No
|
| 257 |
+
35345.jpg Does this artwork belong to the type of religious? Please answer yes or no. Yes
|
| 258 |
+
35345.jpg Does this artwork belong to the type of landscape? Please answer yes or no. No
|
| 259 |
+
35439.jpg Is this artwork titled madonna and child with a host of musical angels? Please answer yes or no. Yes
|
| 260 |
+
35439.jpg Is this artwork titled garden in fontenay? Please answer yes or no. No
|
| 261 |
+
35460.jpg Is this artwork created by schinkel, karl friedrich? Please answer yes or no. Yes
|
| 262 |
+
35460.jpg Is this artwork created by giolfino, bartolomeo? Please answer yes or no. No
|
| 263 |
+
35486.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 264 |
+
35486.jpg Does this artwork exist in the form of furniture? Please answer yes or no. No
|
| 265 |
+
35513.jpg Is this artwork created by schongauer, martin? Please answer yes or no. Yes
|
| 266 |
+
35513.jpg Is this artwork created by cassioli, amos? Please answer yes or no. No
|
| 267 |
+
3552.jpg Is this artwork titled madonna degli alberetti? Please answer yes or no. Yes
|
| 268 |
+
3552.jpg Is this artwork titled peter gillis? Please answer yes or no. No
|
| 269 |
+
35658.jpg Is this artwork created by sebastiano del piombo? Please answer yes or no. Yes
|
| 270 |
+
35658.jpg Is this artwork created by jacobsz., dirck? Please answer yes or no. No
|
| 271 |
+
35736.jpg Does this artwork belong to the type of religious? Please answer yes or no. Yes
|
| 272 |
+
35736.jpg Does this artwork belong to the type of still-life? Please answer yes or no. No
|
| 273 |
+
35861.jpg Does this artwork belong to the type of interior? Please answer yes or no. Yes
|
| 274 |
+
35861.jpg Does this artwork belong to the type of still-life? Please answer yes or no. No
|
| 275 |
+
36805.jpg Is this artwork titled weir? Please answer yes or no. Yes
|
| 276 |
+
36805.jpg Is this artwork titled view of the window wall? Please answer yes or no. No
|
| 277 |
+
36966.jpg Does this artwork belong to the type of portrait? Please answer yes or no. Yes
|
| 278 |
+
36966.jpg Does this artwork belong to the type of religious? Please answer yes or no. No
|
| 279 |
+
37010.jpg Is this artwork titled madonna and child with the young st john? Please answer yes or no. Yes
|
| 280 |
+
37010.jpg Is this artwork titled sketch for attila? Please answer yes or no. No
|
| 281 |
+
37077.jpg Does this artwork belong to the type of religious? Please answer yes or no. Yes
|
| 282 |
+
37077.jpg Does this artwork belong to the type of still-life? Please answer yes or no. No
|
| 283 |
+
37439.jpg Is this artwork titled the message? Please answer yes or no. Yes
|
| 284 |
+
37439.jpg Is this artwork titled the descent from the cross? Please answer yes or no. No
|
| 285 |
+
37819.jpg Is this artwork created by tiepolo, giovanni battista? Please answer yes or no. Yes
|
| 286 |
+
37819.jpg Is this artwork created by kerricx, willem ignatius? Please answer yes or no. No
|
| 287 |
+
37866.jpg Does this artwork belong to the type of mythological? Please answer yes or no. Yes
|
| 288 |
+
37866.jpg Does this artwork belong to the type of still-life? Please answer yes or no. No
|
| 289 |
+
381.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 290 |
+
381.jpg Does this artwork exist in the form of architecture? Please answer yes or no. No
|
| 291 |
+
38178.jpg Is this artwork created by tintoretto? Please answer yes or no. Yes
|
| 292 |
+
38178.jpg Is this artwork created by morel, jean-baptiste? Please answer yes or no. No
|
| 293 |
+
38536.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 294 |
+
38536.jpg Does this artwork exist in the form of furniture? Please answer yes or no. No
|
| 295 |
+
38546.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 296 |
+
38546.jpg Does this artwork exist in the form of metalwork? Please answer yes or no. No
|
| 297 |
+
38694.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 298 |
+
38694.jpg Does this artwork exist in the form of metalwork? Please answer yes or no. No
|
| 299 |
+
38740.jpg Is this artwork displayed in musée toulouse-lautrec, albi? Please answer yes or no. Yes
|
| 300 |
+
38740.jpg Is this artwork displayed in kupferstichkabinett, gotha? Please answer yes or no. No
|
| 301 |
+
38881.jpg Does this artwork belong to the type of genre? Please answer yes or no. Yes
|
| 302 |
+
38881.jpg Does this artwork belong to the type of religious? Please answer yes or no. No
|
| 303 |
+
38993.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 304 |
+
38993.jpg Does this artwork exist in the form of illumination? Please answer yes or no. No
|
| 305 |
+
39026.jpg Does this artwork belong to the type of religious? Please answer yes or no. Yes
|
| 306 |
+
39026.jpg Does this artwork belong to the type of historical? Please answer yes or no. No
|
| 307 |
+
39124.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 308 |
+
39124.jpg Does this artwork exist in the form of graphics? Please answer yes or no. No
|
| 309 |
+
39188.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 310 |
+
39188.jpg Does this artwork exist in the form of architecture? Please answer yes or no. No
|
| 311 |
+
39482.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 312 |
+
39482.jpg Does this artwork exist in the form of metalwork? Please answer yes or no. No
|
| 313 |
+
39556.jpg Is this artwork created by unknown master, dutch? Please answer yes or no. Yes
|
| 314 |
+
39556.jpg Is this artwork created by cuyp, benjamin gerritsz.? Please answer yes or no. No
|
| 315 |
+
41036.jpg Is this artwork displayed in kunsthistorisches museum, vienna? Please answer yes or no. Yes
|
| 316 |
+
41036.jpg Is this artwork displayed in national museum of art, minsk? Please answer yes or no. No
|
| 317 |
+
41371.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 318 |
+
41371.jpg Does this artwork exist in the form of architecture? Please answer yes or no. No
|
| 319 |
+
41484.jpg Does this artwork belong to the type of religious? Please answer yes or no. Yes
|
| 320 |
+
41484.jpg Does this artwork belong to the type of historical? Please answer yes or no. No
|
| 321 |
+
41594.jpg Is this artwork created by veronese, paolo? Please answer yes or no. Yes
|
| 322 |
+
41594.jpg Is this artwork created by jeaurat, etienne? Please answer yes or no. No
|
| 323 |
+
416.jpg Does this artwork exist in the form of sculpture? Please answer yes or no. Yes
|
| 324 |
+
416.jpg Does this artwork exist in the form of others? Please answer yes or no. No
|
| 325 |
+
41653.jpg Is this artwork titled view of the sala del collegio? Please answer yes or no. Yes
|
| 326 |
+
41653.jpg Is this artwork titled reine lefebvre and margot? Please answer yes or no. No
|
| 327 |
+
41944.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 328 |
+
41944.jpg Does this artwork exist in the form of mosaic? Please answer yes or no. No
|
| 329 |
+
42152.jpg Is this artwork titled the pieterskerk in leiden? Please answer yes or no. Yes
|
| 330 |
+
42152.jpg Is this artwork titled portrait of cardinal reginald pole? Please answer yes or no. No
|
| 331 |
+
42288.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 332 |
+
42288.jpg Does this artwork exist in the form of stained-glass? Please answer yes or no. No
|
| 333 |
+
42303.jpg Is this artwork displayed in art museum, cincinnati? Please answer yes or no. Yes
|
| 334 |
+
42303.jpg Is this artwork displayed in banca del monte di bologna e ravenna, bologna? Please answer yes or no. No
|
| 335 |
+
42401.jpg Is this artwork created by waldmüller, fedinand georg? Please answer yes or no. Yes
|
| 336 |
+
42401.jpg Is this artwork created by seeman, enoch? Please answer yes or no. No
|
| 337 |
+
42447.jpg Is this artwork displayed in musée du louvre, paris? Please answer yes or no. Yes
|
| 338 |
+
42447.jpg Is this artwork displayed in santa catarina, pisa? Please answer yes or no. No
|
| 339 |
+
42585.jpg Is this artwork created by werff, pieter van der? Please answer yes or no. Yes
|
| 340 |
+
42585.jpg Is this artwork created by domenichini, apollonio? Please answer yes or no. No
|
| 341 |
+
42706.jpg Is this artwork displayed in musée du louvre, paris? Please answer yes or no. Yes
|
| 342 |
+
42706.jpg Is this artwork displayed in galleria nazionale d'arte moderna e contemporanea, rome? Please answer yes or no. No
|
| 343 |
+
42796.jpg Is this artwork displayed in private collection? Please answer yes or no. Yes
|
| 344 |
+
42796.jpg Is this artwork displayed in museo di san salvi, florence? Please answer yes or no. No
|
| 345 |
+
42857.jpg Does this artwork belong to the type of landscape? Please answer yes or no. Yes
|
| 346 |
+
42857.jpg Does this artwork belong to the type of study? Please answer yes or no. No
|
| 347 |
+
42905.jpg Is this artwork created by wit, jacob de? Please answer yes or no. Yes
|
| 348 |
+
42905.jpg Is this artwork created by vittone, bernardo antonio? Please answer yes or no. No
|
| 349 |
+
42941.jpg Is this artwork created by witte, emanuel de? Please answer yes or no. Yes
|
| 350 |
+
42941.jpg Is this artwork created by bicci di neri? Please answer yes or no. No
|
| 351 |
+
42956.jpg Is this artwork titled view of rome with the tiberand castel sant'angelo? Please answer yes or no. Yes
|
| 352 |
+
42956.jpg Is this artwork titled st bonaventure enters the franciscan order? Please answer yes or no. No
|
| 353 |
+
42987.jpg Is this artwork created by witz, konrad? Please answer yes or no. Yes
|
| 354 |
+
42987.jpg Is this artwork created by christus, petrus? Please answer yes or no. No
|
| 355 |
+
43142.jpg Does this artwork belong to the type of mythological? Please answer yes or no. Yes
|
| 356 |
+
43142.jpg Does this artwork belong to the type of interior? Please answer yes or no. No
|
| 357 |
+
43175.jpg Is this artwork displayed in private collection? Please answer yes or no. Yes
|
| 358 |
+
43175.jpg Is this artwork displayed in smith college museum of art, northampton? Please answer yes or no. No
|
| 359 |
+
43349.jpg Is this artwork created by zuccarelli, francesco? Please answer yes or no. Yes
|
| 360 |
+
43349.jpg Is this artwork created by baccanelli, giovanni antonio di giulio? Please answer yes or no. No
|
| 361 |
+
43445.jpg Does this artwork belong to the type of religious? Please answer yes or no. Yes
|
| 362 |
+
43445.jpg Does this artwork belong to the type of interior? Please answer yes or no. No
|
| 363 |
+
4836.jpg Is this artwork displayed in villa cornaro, piombino dese? Please answer yes or no. Yes
|
| 364 |
+
4836.jpg Is this artwork displayed in palais saint-vaast, arras? Please answer yes or no. No
|
| 365 |
+
5227.jpg Is this artwork created by botticelli, sandro? Please answer yes or no. Yes
|
| 366 |
+
5227.jpg Is this artwork created by vigri, caterina? Please answer yes or no. No
|
| 367 |
+
526.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 368 |
+
526.jpg Does this artwork exist in the form of tapestry? Please answer yes or no. No
|
| 369 |
+
5906.jpg Is this artwork created by bronzino, agnolo? Please answer yes or no. Yes
|
| 370 |
+
5906.jpg Is this artwork created by pellegrino da san daniele? Please answer yes or no. No
|
| 371 |
+
6168.jpg Does this artwork exist in the form of graphics? Please answer yes or no. Yes
|
| 372 |
+
6168.jpg Does this artwork exist in the form of tapestry? Please answer yes or no. No
|
| 373 |
+
6297.jpg Is this artwork titled peasants making merry outside a tavern 'the swan'? Please answer yes or no. Yes
|
| 374 |
+
6297.jpg Is this artwork titled allegory of quietude? Please answer yes or no. No
|
| 375 |
+
6478.jpg Does this artwork belong to the type of religious? Please answer yes or no. Yes
|
| 376 |
+
6478.jpg Does this artwork belong to the type of genre? Please answer yes or no. No
|
| 377 |
+
6969.jpg Is this artwork titled letizia ramolino bonaparte? Please answer yes or no. Yes
|
| 378 |
+
6969.jpg Is this artwork titled job and his daughters? Please answer yes or no. No
|
| 379 |
+
701.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 380 |
+
701.jpg Does this artwork exist in the form of others? Please answer yes or no. No
|
| 381 |
+
7702.jpg Is this artwork titled reine lefebvre and margot? Please answer yes or no. Yes
|
| 382 |
+
7702.jpg Is this artwork titled fire in the oil depot at san marcuola? Please answer yes or no. No
|
| 383 |
+
8101.jpg Is this artwork displayed in museu de arte, são paulo? Please answer yes or no. Yes
|
| 384 |
+
8101.jpg Is this artwork displayed in national széchényi library, budapest? Please answer yes or no. No
|
| 385 |
+
815.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 386 |
+
815.jpg Does this artwork exist in the form of furniture? Please answer yes or no. No
|
| 387 |
+
8797.jpg Is this artwork created by coecke van aelst, pieter? Please answer yes or no. Yes
|
| 388 |
+
8797.jpg Is this artwork created by abaquesne, masséot? Please answer yes or no. No
|
| 389 |
+
8885.jpg Is this artwork displayed in art museum, saint louis? Please answer yes or no. Yes
|
| 390 |
+
8885.jpg Is this artwork displayed in museo civico d'arte antica, turin? Please answer yes or no. No
|
| 391 |
+
9153.jpg Is this artwork displayed in galleria nazionale, parma? Please answer yes or no. Yes
|
| 392 |
+
9153.jpg Is this artwork displayed in hospital de san bernardo, seville? Please answer yes or no. No
|
| 393 |
+
9395.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 394 |
+
9395.jpg Does this artwork exist in the form of stained-glass? Please answer yes or no. No
|
| 395 |
+
9405.jpg Is this artwork created by courbet, gustave? Please answer yes or no. Yes
|
| 396 |
+
9405.jpg Is this artwork created by milani, aureliano? Please answer yes or no. No
|
| 397 |
+
9599.jpg Does this artwork exist in the form of painting? Please answer yes or no. Yes
|
| 398 |
+
9599.jpg Does this artwork exist in the form of ceramics? Please answer yes or no. No
|
| 399 |
+
995.jpg Does this artwork exist in the form of sculpture? Please answer yes or no. Yes
|
| 400 |
+
995.jpg Does this artwork exist in the form of painting? Please answer yes or no. No
|
eval/vlm/eval/mme/Your_Results/celebrity.txt
ADDED
|
@@ -0,0 +1,340 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
tt0032138_shot_0395_img_0.jpg Is the actor inside the red bounding box named Frank Morgan? Please answer yes or no. Yes
|
| 2 |
+
tt0032138_shot_0395_img_0.jpg Is the actor inside the red bounding box named Eric Schniewind? Please answer yes or no. No
|
| 3 |
+
tt0035423_shot_0464_img_0.jpg Is the actor inside the red bounding box called Hugh Jackman? Please answer yes or no. Yes
|
| 4 |
+
tt0035423_shot_0464_img_0.jpg Is the actor inside the red bounding box called Lizzie Hopley? Please answer yes or no. No
|
| 5 |
+
tt0038650_shot_0737_img_1.jpg Is the person inside the red bounding box called James Stewart? Please answer yes or no. Yes
|
| 6 |
+
tt0038650_shot_0737_img_1.jpg Is the person inside the red bounding box called Phil Selway? Please answer yes or no. No
|
| 7 |
+
tt0047396_shot_0333_img_0.jpg Is the actor inside the red bounding box named James Stewart? Please answer yes or no. Yes
|
| 8 |
+
tt0047396_shot_0333_img_0.jpg Is the actor inside the red bounding box named Ron Blair? Please answer yes or no. No
|
| 9 |
+
tt0048545_shot_0124_img_0.jpg Is the actor inside the red bounding box called Natalie Wood? Please answer yes or no. Yes
|
| 10 |
+
tt0048545_shot_0124_img_0.jpg Is the actor inside the red bounding box called Rebecca Jackson Mendoza? Please answer yes or no. No
|
| 11 |
+
tt0049470_shot_0279_img_0.jpg Is the person inside the red bounding box called James Stewart? Please answer yes or no. Yes
|
| 12 |
+
tt0049470_shot_0279_img_0.jpg Is the person inside the red bounding box called Matt Pashkow? Please answer yes or no. No
|
| 13 |
+
tt0049730_shot_0273_img_0.jpg Is the person inside the red bounding box called Vera Miles? Please answer yes or no. Yes
|
| 14 |
+
tt0049730_shot_0273_img_0.jpg Is the person inside the red bounding box called Addie Yungmee? Please answer yes or no. No
|
| 15 |
+
tt0052357_shot_0511_img_0.jpg Is the actor inside the red bounding box called Kim Novak? Please answer yes or no. Yes
|
| 16 |
+
tt0052357_shot_0511_img_0.jpg Is the actor inside the red bounding box called Abigail Van Alyn? Please answer yes or no. No
|
| 17 |
+
tt0053221_shot_0197_img_0.jpg Is the actor inside the red bounding box named John Wayne? Please answer yes or no. Yes
|
| 18 |
+
tt0053221_shot_0197_img_0.jpg Is the actor inside the red bounding box named Claude-Oliver Rudolph? Please answer yes or no. No
|
| 19 |
+
tt0054167_shot_0122_img_0.jpg Is the person inside the red bounding box called Anna Massey? Please answer yes or no. Yes
|
| 20 |
+
tt0054167_shot_0122_img_0.jpg Is the person inside the red bounding box called Eddie Tagoe? Please answer yes or no. No
|
| 21 |
+
tt0056869_shot_0320_img_0.jpg Is the person inside the red bounding box called Tippi Hedren? Please answer yes or no. Yes
|
| 22 |
+
tt0056869_shot_0320_img_0.jpg Is the person inside the red bounding box called Denise Mack? Please answer yes or no. No
|
| 23 |
+
tt0056923_shot_0835_img_0.jpg Is the actor inside the red bounding box called Audrey Hepburn? Please answer yes or no. Yes
|
| 24 |
+
tt0056923_shot_0835_img_0.jpg Is the actor inside the red bounding box called Chris April? Please answer yes or no. No
|
| 25 |
+
tt0057115_shot_0686_img_0.jpg Is the person inside the red bounding box named James Garner? Please answer yes or no. Yes
|
| 26 |
+
tt0057115_shot_0686_img_0.jpg Is the person inside the red bounding box named Chutimon Chuengcharoensukying? Please answer yes or no. No
|
| 27 |
+
tt0058331_shot_0353_img_0.jpg Is the actor inside the red bounding box named Julie Andrews? Please answer yes or no. Yes
|
| 28 |
+
tt0058331_shot_0353_img_0.jpg Is the actor inside the red bounding box named Ed Geldart? Please answer yes or no. No
|
| 29 |
+
tt0058461_shot_0901_img_0.jpg Is the actor inside the red bounding box called Gian Maria Volontè? Please answer yes or no. Yes
|
| 30 |
+
tt0058461_shot_0901_img_0.jpg Is the actor inside the red bounding box called Jennifer Connelly? Please answer yes or no. No
|
| 31 |
+
tt0061418_shot_0148_img_0.jpg Is the actor inside the red bounding box named Faye Dunaway? Please answer yes or no. Yes
|
| 32 |
+
tt0061418_shot_0148_img_0.jpg Is the actor inside the red bounding box named Warona Seane? Please answer yes or no. No
|
| 33 |
+
tt0061722_shot_0259_img_0.jpg Is the actor inside the red bounding box called Dustin Hoffman? Please answer yes or no. Yes
|
| 34 |
+
tt0061722_shot_0259_img_0.jpg Is the actor inside the red bounding box called Christopher Olsen? Please answer yes or no. No
|
| 35 |
+
tt0062622_shot_0291_img_0.jpg Is the actor inside the red bounding box named Keir Dullea? Please answer yes or no. Yes
|
| 36 |
+
tt0062622_shot_0291_img_0.jpg Is the actor inside the red bounding box named Frank Albanese? Please answer yes or no. No
|
| 37 |
+
tt0063442_shot_0702_img_0.jpg Is the actor inside the red bounding box called Linda Harrison? Please answer yes or no. Yes
|
| 38 |
+
tt0063442_shot_0702_img_0.jpg Is the actor inside the red bounding box called Michael McKean? Please answer yes or no. No
|
| 39 |
+
tt0064115_shot_0367_img_0.jpg Is the actor inside the red bounding box named Robert Redford? Please answer yes or no. Yes
|
| 40 |
+
tt0064115_shot_0367_img_0.jpg Is the actor inside the red bounding box named Cooper Murray? Please answer yes or no. No
|
| 41 |
+
tt0064665_shot_0300_img_0.jpg Is the actor inside the red bounding box called Jon Voight? Please answer yes or no. Yes
|
| 42 |
+
tt0064665_shot_0300_img_0.jpg Is the actor inside the red bounding box called Harvey Meyer? Please answer yes or no. No
|
| 43 |
+
tt0065214_shot_0366_img_0.jpg Is the person inside the red bounding box called Robert Ryan? Please answer yes or no. Yes
|
| 44 |
+
tt0065214_shot_0366_img_0.jpg Is the person inside the red bounding box called Victor Verhaeghe? Please answer yes or no. No
|
| 45 |
+
tt0065724_shot_0320_img_1.jpg Is the person inside the red bounding box named Karen Black? Please answer yes or no. Yes
|
| 46 |
+
tt0065724_shot_0320_img_1.jpg Is the person inside the red bounding box named Nick Discenza? Please answer yes or no. No
|
| 47 |
+
tt0066026_shot_0085_img_0.jpg Is the person inside the red bounding box called Donald Sutherland? Please answer yes or no. Yes
|
| 48 |
+
tt0066026_shot_0085_img_0.jpg Is the person inside the red bounding box called Michael Wollet? Please answer yes or no. No
|
| 49 |
+
tt0066921_shot_0631_img_0.jpg Is the actor inside the red bounding box called Malcolm McDowell? Please answer yes or no. Yes
|
| 50 |
+
tt0066921_shot_0631_img_0.jpg Is the actor inside the red bounding box called Darling Légitimus? Please answer yes or no. No
|
| 51 |
+
tt0067116_shot_0122_img_0.jpg Is the actor inside the red bounding box called Gene Hackman? Please answer yes or no. Yes
|
| 52 |
+
tt0067116_shot_0122_img_0.jpg Is the actor inside the red bounding box called Russell G. Jones? Please answer yes or no. No
|
| 53 |
+
tt0068646_shot_0166_img_0.jpg Is the actor inside the red bounding box called Marlon Brando? Please answer yes or no. Yes
|
| 54 |
+
tt0068646_shot_0166_img_0.jpg Is the actor inside the red bounding box called Voltaire Sterling? Please answer yes or no. No
|
| 55 |
+
tt0069762_shot_0723_img_0.jpg Is the person inside the red bounding box named Sissy Spacek? Please answer yes or no. Yes
|
| 56 |
+
tt0069762_shot_0723_img_0.jpg Is the person inside the red bounding box named Monica Giordano? Please answer yes or no. No
|
| 57 |
+
tt0070047_shot_0255_img_0.jpg Is the actor inside the red bounding box called Ellen Burstyn? Please answer yes or no. Yes
|
| 58 |
+
tt0070047_shot_0255_img_0.jpg Is the actor inside the red bounding box called Shawnee Smith? Please answer yes or no. No
|
| 59 |
+
tt0070379_shot_0569_img_0.jpg Is the actor inside the red bounding box named Richard Romanus? Please answer yes or no. Yes
|
| 60 |
+
tt0070379_shot_0569_img_0.jpg Is the actor inside the red bounding box named Valerie Colgan? Please answer yes or no. No
|
| 61 |
+
tt0070511_shot_0639_img_0.jpg Is the person inside the red bounding box called Dustin Hoffman? Please answer yes or no. Yes
|
| 62 |
+
tt0070511_shot_0639_img_0.jpg Is the person inside the red bounding box called Fernando Lueches? Please answer yes or no. No
|
| 63 |
+
tt0070735_shot_0818_img_0.jpg Is the person inside the red bounding box named Robert Redford? Please answer yes or no. Yes
|
| 64 |
+
tt0070735_shot_0818_img_0.jpg Is the person inside the red bounding box named Ellin Dennis? Please answer yes or no. No
|
| 65 |
+
tt0070849_shot_0021_img_1.jpg Is the person inside the red bounding box named Maria Schneider? Please answer yes or no. Yes
|
| 66 |
+
tt0070849_shot_0021_img_1.jpg Is the person inside the red bounding box named Mary Kellogg? Please answer yes or no. No
|
| 67 |
+
tt0071315_shot_0153_img_0.jpg Is the actor inside the red bounding box named Faye Dunaway? Please answer yes or no. Yes
|
| 68 |
+
tt0071315_shot_0153_img_0.jpg Is the actor inside the red bounding box named Kelly Hitman? Please answer yes or no. No
|
| 69 |
+
tt0071562_shot_0684_img_0.jpg Is the actor inside the red bounding box named Al Pacino? Please answer yes or no. Yes
|
| 70 |
+
tt0071562_shot_0684_img_0.jpg Is the actor inside the red bounding box named Debie Jarczewski? Please answer yes or no. No
|
| 71 |
+
tt0072684_shot_0512_img_1.jpg Is the person inside the red bounding box named Marisa Berenson? Please answer yes or no. Yes
|
| 72 |
+
tt0072684_shot_0512_img_1.jpg Is the person inside the red bounding box named Graham Bohea? Please answer yes or no. No
|
| 73 |
+
tt0073195_shot_0280_img_0.jpg Is the actor inside the red bounding box named Roy Scheider? Please answer yes or no. Yes
|
| 74 |
+
tt0073195_shot_0280_img_0.jpg Is the actor inside the red bounding box named Abdul Qadir Farookh? Please answer yes or no. No
|
| 75 |
+
tt0073629_shot_0700_img_0.jpg Is the person inside the red bounding box named Barry Bostwick? Please answer yes or no. Yes
|
| 76 |
+
tt0073629_shot_0700_img_0.jpg Is the person inside the red bounding box named Johnny Galecki? Please answer yes or no. No
|
| 77 |
+
tt0074119_shot_0814_img_0.jpg Is the actor inside the red bounding box called Robert Redford? Please answer yes or no. Yes
|
| 78 |
+
tt0074119_shot_0814_img_0.jpg Is the actor inside the red bounding box called Delroy Lindo? Please answer yes or no. No
|
| 79 |
+
tt0074285_shot_0535_img_1.jpg Is the person inside the red bounding box named William Katt? Please answer yes or no. Yes
|
| 80 |
+
tt0074285_shot_0535_img_1.jpg Is the person inside the red bounding box named Stephen Rider? Please answer yes or no. No
|
| 81 |
+
tt0075148_shot_0618_img_0.jpg Is the actor inside the red bounding box called Sylvester Stallone? Please answer yes or no. Yes
|
| 82 |
+
tt0075148_shot_0618_img_0.jpg Is the actor inside the red bounding box called Eric Hatch? Please answer yes or no. No
|
| 83 |
+
tt0075686_shot_0373_img_0.jpg Is the actor inside the red bounding box called Woody Allen? Please answer yes or no. Yes
|
| 84 |
+
tt0075686_shot_0373_img_0.jpg Is the actor inside the red bounding box called Penny Wallace? Please answer yes or no. No
|
| 85 |
+
tt0076729_shot_0451_img_0.jpg Is the actor inside the red bounding box called Sally Field? Please answer yes or no. Yes
|
| 86 |
+
tt0076729_shot_0451_img_0.jpg Is the actor inside the red bounding box called Giorgio Libassi? Please answer yes or no. No
|
| 87 |
+
tt0076759_shot_0930_img_0.jpg Is the actor inside the red bounding box called Harrison Ford? Please answer yes or no. Yes
|
| 88 |
+
tt0076759_shot_0930_img_0.jpg Is the actor inside the red bounding box called Ryoko Sadoshima? Please answer yes or no. No
|
| 89 |
+
tt0077402_shot_1220_img_0.jpg Is the person inside the red bounding box named Scott H. Reiniger? Please answer yes or no. Yes
|
| 90 |
+
tt0077402_shot_1220_img_0.jpg Is the person inside the red bounding box named Chris Delaney? Please answer yes or no. No
|
| 91 |
+
tt0077405_shot_0150_img_0.jpg Is the actor inside the red bounding box named Sam Shepard? Please answer yes or no. Yes
|
| 92 |
+
tt0077405_shot_0150_img_0.jpg Is the actor inside the red bounding box named Bijou Phillips? Please answer yes or no. No
|
| 93 |
+
tt0077416_shot_1442_img_0.jpg Is the person inside the red bounding box named Robert De Niro? Please answer yes or no. Yes
|
| 94 |
+
tt0077416_shot_1442_img_0.jpg Is the person inside the red bounding box named Stu Smith? Please answer yes or no. No
|
| 95 |
+
tt0077651_shot_0133_img_0.jpg Is the person inside the red bounding box called Jamie Lee Curtis? Please answer yes or no. Yes
|
| 96 |
+
tt0077651_shot_0133_img_0.jpg Is the person inside the red bounding box called Paris Arrowsmith? Please answer yes or no. No
|
| 97 |
+
tt0078788_shot_1434_img_0.jpg Is the person inside the red bounding box called Martin Sheen? Please answer yes or no. Yes
|
| 98 |
+
tt0078788_shot_1434_img_0.jpg Is the person inside the red bounding box called Le Capriccio Français? Please answer yes or no. No
|
| 99 |
+
tt0078841_shot_0692_img_0.jpg Is the actor inside the red bounding box named Shirley MacLaine? Please answer yes or no. Yes
|
| 100 |
+
tt0078841_shot_0692_img_0.jpg Is the actor inside the red bounding box named Tomas Choy? Please answer yes or no. No
|
| 101 |
+
tt0079417_shot_0735_img_0.jpg Is the actor inside the red bounding box called Meryl Streep? Please answer yes or no. Yes
|
| 102 |
+
tt0079417_shot_0735_img_0.jpg Is the actor inside the red bounding box called Ross Lacy? Please answer yes or no. No
|
| 103 |
+
tt0079470_shot_0798_img_0.jpg Is the person inside the red bounding box named Eric Idle? Please answer yes or no. Yes
|
| 104 |
+
tt0079470_shot_0798_img_0.jpg Is the person inside the red bounding box named Quincy Taylor? Please answer yes or no. No
|
| 105 |
+
tt0079945_shot_1411_img_0.jpg Is the person inside the red bounding box named Persis Khambatta? Please answer yes or no. Yes
|
| 106 |
+
tt0079945_shot_1411_img_0.jpg Is the person inside the red bounding box named Alison Waddell? Please answer yes or no. No
|
| 107 |
+
tt0080339_shot_0711_img_0.jpg Is the actor inside the red bounding box named Robert Hays? Please answer yes or no. Yes
|
| 108 |
+
tt0080339_shot_0711_img_0.jpg Is the actor inside the red bounding box named Grace Sullivan? Please answer yes or no. No
|
| 109 |
+
tt0080684_shot_1574_img_2.jpg Is the actor inside the red bounding box called Mark Hamill? Please answer yes or no. Yes
|
| 110 |
+
tt0080684_shot_1574_img_2.jpg Is the actor inside the red bounding box called Rodion Salnikov? Please answer yes or no. No
|
| 111 |
+
tt0081505_shot_0449_img_0.jpg Is the actor inside the red bounding box called Shelley Duvall? Please answer yes or no. Yes
|
| 112 |
+
tt0081505_shot_0449_img_0.jpg Is the actor inside the red bounding box called Antony Carrick? Please answer yes or no. No
|
| 113 |
+
tt0082089_shot_0046_img_0.jpg Is the actor inside the red bounding box named Kathleen Turner? Please answer yes or no. Yes
|
| 114 |
+
tt0082089_shot_0046_img_0.jpg Is the actor inside the red bounding box named Aaron Henderson? Please answer yes or no. No
|
| 115 |
+
tt0082198_shot_1353_img_0.jpg Is the person inside the red bounding box named Arnold Schwarzenegger? Please answer yes or no. Yes
|
| 116 |
+
tt0082198_shot_1353_img_0.jpg Is the person inside the red bounding box named Tim Herlihy? Please answer yes or no. No
|
| 117 |
+
tt0082971_shot_0831_img_0.jpg Is the actor inside the red bounding box called Harrison Ford? Please answer yes or no. Yes
|
| 118 |
+
tt0082971_shot_0831_img_0.jpg Is the actor inside the red bounding box called Richard Angarola? Please answer yes or no. No
|
| 119 |
+
tt0083658_shot_0963_img_0.jpg Is the person inside the red bounding box called Rutger Hauer? Please answer yes or no. Yes
|
| 120 |
+
tt0083658_shot_0963_img_0.jpg Is the person inside the red bounding box called Stéphane Julien? Please answer yes or no. No
|
| 121 |
+
tt0083866_shot_0364_img_0.jpg Is the actor inside the red bounding box called Robert MacNaughton? Please answer yes or no. Yes
|
| 122 |
+
tt0083866_shot_0364_img_0.jpg Is the actor inside the red bounding box called Seam Turay? Please answer yes or no. No
|
| 123 |
+
tt0083907_shot_0633_img_0.jpg Is the actor inside the red bounding box named Bruce Campbell? Please answer yes or no. Yes
|
| 124 |
+
tt0083907_shot_0633_img_0.jpg Is the actor inside the red bounding box named Kaden Leos? Please answer yes or no. No
|
| 125 |
+
tt0083929_shot_0405_img_0.jpg Is the actor inside the red bounding box named Jennifer Jason Leigh? Please answer yes or no. Yes
|
| 126 |
+
tt0083929_shot_0405_img_0.jpg Is the actor inside the red bounding box named Eric D. Sandgren? Please answer yes or no. No
|
| 127 |
+
tt0084726_shot_0283_img_0.jpg Is the actor inside the red bounding box named Leonard Nimoy? Please answer yes or no. Yes
|
| 128 |
+
tt0084726_shot_0283_img_0.jpg Is the actor inside the red bounding box named John Cusack? Please answer yes or no. No
|
| 129 |
+
tt0086190_shot_0815_img_0.jpg Is the actor inside the red bounding box named Carrie Fisher? Please answer yes or no. Yes
|
| 130 |
+
tt0086190_shot_0815_img_0.jpg Is the actor inside the red bounding box named Ernie Adams? Please answer yes or no. No
|
| 131 |
+
tt0086250_shot_1079_img_0.jpg Is the actor inside the red bounding box called Steven Bauer? Please answer yes or no. Yes
|
| 132 |
+
tt0086250_shot_1079_img_0.jpg Is the actor inside the red bounding box called Bill Nunn? Please answer yes or no. No
|
| 133 |
+
tt0086856_shot_0929_img_0.jpg Is the actor inside the red bounding box called Peter Weller? Please answer yes or no. Yes
|
| 134 |
+
tt0086856_shot_0929_img_0.jpg Is the actor inside the red bounding box called Tracee Cocco? Please answer yes or no. No
|
| 135 |
+
tt0086879_shot_0158_img_0.jpg Is the person inside the red bounding box called Elizabeth Berridge? Please answer yes or no. Yes
|
| 136 |
+
tt0086879_shot_0158_img_0.jpg Is the person inside the red bounding box called Ralph Ineson? Please answer yes or no. No
|
| 137 |
+
tt0087332_shot_0798_img_0.jpg Is the person inside the red bounding box called Bill Murray? Please answer yes or no. Yes
|
| 138 |
+
tt0087332_shot_0798_img_0.jpg Is the person inside the red bounding box called Jiao Xu? Please answer yes or no. No
|
| 139 |
+
tt0087469_shot_0049_img_2.jpg Is the person inside the red bounding box named Harrison Ford? Please answer yes or no. Yes
|
| 140 |
+
tt0087469_shot_0049_img_2.jpg Is the person inside the red bounding box named Paulo Benedeti? Please answer yes or no. No
|
| 141 |
+
tt0088847_shot_0109_img_0.jpg Is the actor inside the red bounding box named Anthony Michael Hall? Please answer yes or no. Yes
|
| 142 |
+
tt0088847_shot_0109_img_0.jpg Is the actor inside the red bounding box named Luis Javier? Please answer yes or no. No
|
| 143 |
+
tt0088944_shot_0634_img_0.jpg Is the actor inside the red bounding box named Arnold Schwarzenegger? Please answer yes or no. Yes
|
| 144 |
+
tt0088944_shot_0634_img_0.jpg Is the actor inside the red bounding box named Shaine Jones? Please answer yes or no. No
|
| 145 |
+
tt0088993_shot_0569_img_0.jpg Is the actor inside the red bounding box called George A. Romero? Please answer yes or no. Yes
|
| 146 |
+
tt0088993_shot_0569_img_0.jpg Is the actor inside the red bounding box called James Eckhouse? Please answer yes or no. No
|
| 147 |
+
tt0089218_shot_0327_img_0.jpg Is the person inside the red bounding box named Sean Astin? Please answer yes or no. Yes
|
| 148 |
+
tt0089218_shot_0327_img_0.jpg Is the person inside the red bounding box named Dan Hunter? Please answer yes or no. No
|
| 149 |
+
tt0089881_shot_0034_img_0.jpg Is the actor inside the red bounding box called Tatsuya Nakadai? Please answer yes or no. Yes
|
| 150 |
+
tt0089881_shot_0034_img_0.jpg Is the actor inside the red bounding box called Nancy Vee? Please answer yes or no. No
|
| 151 |
+
tt0090022_shot_0464_img_0.jpg Is the actor inside the red bounding box called Scott Glenn? Please answer yes or no. Yes
|
| 152 |
+
tt0090022_shot_0464_img_0.jpg Is the actor inside the red bounding box called Robert Ryan? Please answer yes or no. No
|
| 153 |
+
tt0090605_shot_0344_img_0.jpg Is the person inside the red bounding box called Sigourney Weaver? Please answer yes or no. Yes
|
| 154 |
+
tt0090605_shot_0344_img_0.jpg Is the person inside the red bounding box called Lia Beldam? Please answer yes or no. No
|
| 155 |
+
tt0090756_shot_0135_img_0.jpg Is the person inside the red bounding box named Laura Dern? Please answer yes or no. Yes
|
| 156 |
+
tt0090756_shot_0135_img_0.jpg Is the person inside the red bounding box named Keith Frost? Please answer yes or no. No
|
| 157 |
+
tt0091042_shot_0098_img_0.jpg Is the person inside the red bounding box called Matthew Broderick? Please answer yes or no. Yes
|
| 158 |
+
tt0091042_shot_0098_img_0.jpg Is the person inside the red bounding box called Mina E. Mina? Please answer yes or no. No
|
| 159 |
+
tt0091738_shot_0073_img_1.jpg Is the actor inside the red bounding box called Kathleen Turner? Please answer yes or no. Yes
|
| 160 |
+
tt0091738_shot_0073_img_1.jpg Is the actor inside the red bounding box called Pat Kiernan? Please answer yes or no. No
|
| 161 |
+
tt0091867_shot_0422_img_2.jpg Is the person inside the red bounding box named Simon Callow? Please answer yes or no. Yes
|
| 162 |
+
tt0091867_shot_0422_img_2.jpg Is the person inside the red bounding box named Rusty Goffe? Please answer yes or no. No
|
| 163 |
+
tt0092099_shot_0455_img_1.jpg Is the person inside the red bounding box called Tom Cruise? Please answer yes or no. Yes
|
| 164 |
+
tt0092099_shot_0455_img_1.jpg Is the person inside the red bounding box called Carol Krolick? Please answer yes or no. No
|
| 165 |
+
tt0092699_shot_0208_img_0.jpg Is the actor inside the red bounding box called William Hurt? Please answer yes or no. Yes
|
| 166 |
+
tt0092699_shot_0208_img_0.jpg Is the actor inside the red bounding box called Hildur Ruriks? Please answer yes or no. No
|
| 167 |
+
tt0093565_shot_0409_img_0.jpg Is the actor inside the red bounding box named Cher? Please answer yes or no. Yes
|
| 168 |
+
tt0093565_shot_0409_img_0.jpg Is the actor inside the red bounding box named Mark Brady? Please answer yes or no. No
|
| 169 |
+
tt0093748_shot_0346_img_0.jpg Is the actor inside the red bounding box called John Candy? Please answer yes or no. Yes
|
| 170 |
+
tt0093748_shot_0346_img_0.jpg Is the actor inside the red bounding box called Sarah Heller? Please answer yes or no. No
|
| 171 |
+
tt0093773_shot_0212_img_0.jpg Is the person inside the red bounding box named Jesse Ventura? Please answer yes or no. Yes
|
| 172 |
+
tt0093773_shot_0212_img_0.jpg Is the person inside the red bounding box named Akio Mitamura? Please answer yes or no. No
|
| 173 |
+
tt0093779_shot_1047_img_0.jpg Is the person inside the red bounding box named Peter Falk? Please answer yes or no. Yes
|
| 174 |
+
tt0093779_shot_1047_img_0.jpg Is the person inside the red bounding box named Lisa Ann Walter? Please answer yes or no. No
|
| 175 |
+
tt0094226_shot_0237_img_2.jpg Is the actor inside the red bounding box called Kevin Costner? Please answer yes or no. Yes
|
| 176 |
+
tt0094226_shot_0237_img_2.jpg Is the actor inside the red bounding box called Colin Hill? Please answer yes or no. No
|
| 177 |
+
tt0094737_shot_0567_img_0.jpg Is the person inside the red bounding box called Tom Hanks? Please answer yes or no. Yes
|
| 178 |
+
tt0094737_shot_0567_img_0.jpg Is the person inside the red bounding box called Chris McHallem? Please answer yes or no. No
|
| 179 |
+
tt0095016_shot_1170_img_0.jpg Is the actor inside the red bounding box called Paul Gleason? Please answer yes or no. Yes
|
| 180 |
+
tt0095016_shot_1170_img_0.jpg Is the actor inside the red bounding box called Carl Palmer? Please answer yes or no. No
|
| 181 |
+
tt0095250_shot_0509_img_0.jpg Is the actor inside the red bounding box named Jean Reno? Please answer yes or no. Yes
|
| 182 |
+
tt0095250_shot_0509_img_0.jpg Is the actor inside the red bounding box named Ralph Meyering Jr.? Please answer yes or no. No
|
| 183 |
+
tt0095765_shot_0008_img_0.jpg Is the actor inside the red bounding box called Antonella Attili? Please answer yes or no. Yes
|
| 184 |
+
tt0095765_shot_0008_img_0.jpg Is the actor inside the red bounding box called Amber Estrada? Please answer yes or no. No
|
| 185 |
+
tt0095953_shot_0412_img_0.jpg Is the person inside the red bounding box named Tom Cruise? Please answer yes or no. Yes
|
| 186 |
+
tt0095953_shot_0412_img_0.jpg Is the person inside the red bounding box named Lara Mulcahy? Please answer yes or no. No
|
| 187 |
+
tt0096320_shot_0085_img_0.jpg Is the actor inside the red bounding box called Arnold Schwarzenegger? Please answer yes or no. Yes
|
| 188 |
+
tt0096320_shot_0085_img_0.jpg Is the actor inside the red bounding box called Dan Duran? Please answer yes or no. No
|
| 189 |
+
tt0096754_shot_0570_img_1.jpg Is the person inside the red bounding box named Todd Graff? Please answer yes or no. Yes
|
| 190 |
+
tt0096754_shot_0570_img_1.jpg Is the person inside the red bounding box named Guy Carleton? Please answer yes or no. No
|
| 191 |
+
tt0096874_shot_0647_img_0.jpg Is the actor inside the red bounding box named Michael J. Fox? Please answer yes or no. Yes
|
| 192 |
+
tt0096874_shot_0647_img_0.jpg Is the actor inside the red bounding box named Momoko Komatsu? Please answer yes or no. No
|
| 193 |
+
tt0096895_shot_0819_img_1.jpg Is the person inside the red bounding box called Michael Keaton? Please answer yes or no. Yes
|
| 194 |
+
tt0096895_shot_0819_img_1.jpg Is the person inside the red bounding box called Ben Foster? Please answer yes or no. No
|
| 195 |
+
tt0097216_shot_0381_img_0.jpg Is the actor inside the red bounding box named Danny Aiello? Please answer yes or no. Yes
|
| 196 |
+
tt0097216_shot_0381_img_0.jpg Is the actor inside the red bounding box named Taissa Farmiga? Please answer yes or no. No
|
| 197 |
+
tt0097428_shot_0106_img_0.jpg Is the actor inside the red bounding box named Bill Murray? Please answer yes or no. Yes
|
| 198 |
+
tt0097428_shot_0106_img_0.jpg Is the actor inside the red bounding box named Michael Fawcett? Please answer yes or no. No
|
| 199 |
+
tt0097576_shot_1010_img_2.jpg Is the actor inside the red bounding box named Harrison Ford? Please answer yes or no. Yes
|
| 200 |
+
tt0097576_shot_1010_img_2.jpg Is the actor inside the red bounding box named M. Emmet Walsh? Please answer yes or no. No
|
| 201 |
+
tt0098635_shot_0556_img_0.jpg Is the actor inside the red bounding box named Meg Ryan? Please answer yes or no. Yes
|
| 202 |
+
tt0098635_shot_0556_img_0.jpg Is the actor inside the red bounding box named Tom Branch? Please answer yes or no. No
|
| 203 |
+
tt0098724_shot_0474_img_0.jpg Is the person inside the red bounding box named Andie MacDowell? Please answer yes or no. Yes
|
| 204 |
+
tt0098724_shot_0474_img_0.jpg Is the person inside the red bounding box named Linda Taylor? Please answer yes or no. No
|
| 205 |
+
tt0099423_shot_1010_img_0.jpg Is the person inside the red bounding box called Bruce Willis? Please answer yes or no. Yes
|
| 206 |
+
tt0099423_shot_1010_img_0.jpg Is the person inside the red bounding box called Trevor Eve? Please answer yes or no. No
|
| 207 |
+
tt0099487_shot_0123_img_0.jpg Is the actor inside the red bounding box named Johnny Depp? Please answer yes or no. Yes
|
| 208 |
+
tt0099487_shot_0123_img_0.jpg Is the actor inside the red bounding box named Farrah Forke? Please answer yes or no. No
|
| 209 |
+
tt0099674_shot_1356_img_0.jpg Is the person inside the red bounding box named Al Pacino? Please answer yes or no. Yes
|
| 210 |
+
tt0099674_shot_1356_img_0.jpg Is the person inside the red bounding box named Nick Porrazzo? Please answer yes or no. No
|
| 211 |
+
tt0099685_shot_1132_img_0.jpg Is the actor inside the red bounding box called Ray Liotta? Please answer yes or no. Yes
|
| 212 |
+
tt0099685_shot_1132_img_0.jpg Is the actor inside the red bounding box called Chick Allan? Please answer yes or no. No
|
| 213 |
+
tt0099810_shot_0285_img_0.jpg Is the person inside the red bounding box called Alec Baldwin? Please answer yes or no. Yes
|
| 214 |
+
tt0099810_shot_0285_img_0.jpg Is the person inside the red bounding box called Jennifer Anglin? Please answer yes or no. No
|
| 215 |
+
tt0100157_shot_0365_img_0.jpg Is the actor inside the red bounding box named James Caan? Please answer yes or no. Yes
|
| 216 |
+
tt0100157_shot_0365_img_0.jpg Is the actor inside the red bounding box named Bryan Johnson? Please answer yes or no. No
|
| 217 |
+
tt0100403_shot_0517_img_0.jpg Is the person inside the red bounding box called Gary Busey? Please answer yes or no. Yes
|
| 218 |
+
tt0100403_shot_0517_img_0.jpg Is the person inside the red bounding box called Alfred Tiaki Hotu? Please answer yes or no. No
|
| 219 |
+
tt0100405_shot_0786_img_0.jpg Is the actor inside the red bounding box named Jason Alexander? Please answer yes or no. Yes
|
| 220 |
+
tt0100405_shot_0786_img_0.jpg Is the actor inside the red bounding box named Alexandra Bastedo? Please answer yes or no. No
|
| 221 |
+
tt0101410_shot_0105_img_0.jpg Is the person inside the red bounding box named John Turturro? Please answer yes or no. Yes
|
| 222 |
+
tt0101410_shot_0105_img_0.jpg Is the person inside the red bounding box named David Gore? Please answer yes or no. No
|
| 223 |
+
tt0102492_shot_0086_img_0.jpg Is the actor inside the red bounding box called Jamie Lee Curtis? Please answer yes or no. Yes
|
| 224 |
+
tt0102492_shot_0086_img_0.jpg Is the actor inside the red bounding box called Heidi Fischer? Please answer yes or no. No
|
| 225 |
+
tt0103064_shot_1206_img_0.jpg Is the actor inside the red bounding box named Arnold Schwarzenegger? Please answer yes or no. Yes
|
| 226 |
+
tt0103064_shot_1206_img_0.jpg Is the actor inside the red bounding box named Gigi Lee? Please answer yes or no. No
|
| 227 |
+
tt0103064_shot_2602_img_1.jpg Is the person inside the red bounding box named Arnold Schwarzenegger? Please answer yes or no. Yes
|
| 228 |
+
tt0103064_shot_2602_img_1.jpg Is the person inside the red bounding box named Candice Azzara? Please answer yes or no. No
|
| 229 |
+
tt0103776_shot_0719_img_0.jpg Is the person inside the red bounding box called Michael Keaton? Please answer yes or no. Yes
|
| 230 |
+
tt0103776_shot_0719_img_0.jpg Is the person inside the red bounding box called Nicholas Rice? Please answer yes or no. No
|
| 231 |
+
tt0104036_shot_0336_img_1.jpg Is the person inside the red bounding box named Stephen Rea? Please answer yes or no. Yes
|
| 232 |
+
tt0104036_shot_0336_img_1.jpg Is the person inside the red bounding box named Mimi Lizio? Please answer yes or no. No
|
| 233 |
+
tt0104257_shot_0477_img_0.jpg Is the person inside the red bounding box named Jack Nicholson? Please answer yes or no. Yes
|
| 234 |
+
tt0104257_shot_0477_img_0.jpg Is the person inside the red bounding box named Emma Julia Jacobs? Please answer yes or no. No
|
| 235 |
+
tt0104348_shot_0340_img_0.jpg Is the person inside the red bounding box called Ed Harris? Please answer yes or no. Yes
|
| 236 |
+
tt0104348_shot_0340_img_0.jpg Is the person inside the red bounding box called Carla Lizzette Mejia? Please answer yes or no. No
|
| 237 |
+
tt0105236_shot_0193_img_0.jpg Is the actor inside the red bounding box named Harvey Keitel? Please answer yes or no. Yes
|
| 238 |
+
tt0105236_shot_0193_img_0.jpg Is the actor inside the red bounding box named Terence Yin? Please answer yes or no. No
|
| 239 |
+
tt0105665_shot_0351_img_0.jpg Is the actor inside the red bounding box named Kyle MacLachlan? Please answer yes or no. Yes
|
| 240 |
+
tt0105665_shot_0351_img_0.jpg Is the actor inside the red bounding box named Julia Hsu? Please answer yes or no. No
|
| 241 |
+
tt0105695_shot_1436_img_1.jpg Is the person inside the red bounding box called Jaimz Woolvett? Please answer yes or no. Yes
|
| 242 |
+
tt0105695_shot_1436_img_1.jpg Is the person inside the red bounding box called Hermione Baddeley? Please answer yes or no. No
|
| 243 |
+
tt0106977_shot_1604_img_0.jpg Is the person inside the red bounding box named Tommy Lee Jones? Please answer yes or no. Yes
|
| 244 |
+
tt0106977_shot_1604_img_0.jpg Is the person inside the red bounding box named Honey Chhaya? Please answer yes or no. No
|
| 245 |
+
tt0107614_shot_0116_img_0.jpg Is the person inside the red bounding box called Sally Field? Please answer yes or no. Yes
|
| 246 |
+
tt0107614_shot_0116_img_0.jpg Is the person inside the red bounding box called Arthur Senzy? Please answer yes or no. No
|
| 247 |
+
tt0108399_shot_0778_img_0.jpg Is the actor inside the red bounding box called Christopher Walken? Please answer yes or no. Yes
|
| 248 |
+
tt0108399_shot_0778_img_0.jpg Is the actor inside the red bounding box called Fiona Sit? Please answer yes or no. No
|
| 249 |
+
tt0109831_shot_0298_img_0.jpg Is the person inside the red bounding box called Hugh Grant? Please answer yes or no. Yes
|
| 250 |
+
tt0109831_shot_0298_img_0.jpg Is the person inside the red bounding box called Renée Zellweger? Please answer yes or no. No
|
| 251 |
+
tt0111280_shot_0258_img_0.jpg Is the actor inside the red bounding box named Gates McFadden? Please answer yes or no. Yes
|
| 252 |
+
tt0111280_shot_0258_img_0.jpg Is the actor inside the red bounding box named Michael Angarano? Please answer yes or no. No
|
| 253 |
+
tt0111280_shot_1479_img_2.jpg Is the actor inside the red bounding box called William Shatner? Please answer yes or no. Yes
|
| 254 |
+
tt0111280_shot_1479_img_2.jpg Is the actor inside the red bounding box called Richard Rohrbough? Please answer yes or no. No
|
| 255 |
+
tt0112384_shot_0878_img_0.jpg Is the person inside the red bounding box called Kathleen Quinlan? Please answer yes or no. Yes
|
| 256 |
+
tt0112384_shot_0878_img_0.jpg Is the person inside the red bounding box called Veronica Diaz Carranza? Please answer yes or no. No
|
| 257 |
+
tt0112641_shot_0412_img_1.jpg Is the actor inside the red bounding box called Robert De Niro? Please answer yes or no. Yes
|
| 258 |
+
tt0112641_shot_0412_img_1.jpg Is the actor inside the red bounding box called Pierre Malherbe? Please answer yes or no. No
|
| 259 |
+
tt0112740_shot_1056_img_0.jpg Is the person inside the red bounding box named Denzel Washington? Please answer yes or no. Yes
|
| 260 |
+
tt0112740_shot_1056_img_0.jpg Is the person inside the red bounding box named Bill Pullman? Please answer yes or no. No
|
| 261 |
+
tt0113101_shot_0547_img_0.jpg Is the person inside the red bounding box named Tim Roth? Please answer yes or no. Yes
|
| 262 |
+
tt0113101_shot_0547_img_0.jpg Is the person inside the red bounding box named Honey Chhaya? Please answer yes or no. No
|
| 263 |
+
tt0114369_shot_1138_img_0.jpg Is the person inside the red bounding box named Brad Pitt? Please answer yes or no. Yes
|
| 264 |
+
tt0114369_shot_1138_img_0.jpg Is the person inside the red bounding box named Benjamin Nitze? Please answer yes or no. No
|
| 265 |
+
tt0114388_shot_0162_img_0.jpg Is the actor inside the red bounding box called Emma Thompson? Please answer yes or no. Yes
|
| 266 |
+
tt0114388_shot_0162_img_0.jpg Is the actor inside the red bounding box called Francis P. Hughes? Please answer yes or no. No
|
| 267 |
+
tt0114388_shot_1207_img_1.jpg Is the person inside the red bounding box called Hugh Grant? Please answer yes or no. Yes
|
| 268 |
+
tt0114388_shot_1207_img_1.jpg Is the person inside the red bounding box called Zach Hopkins? Please answer yes or no. No
|
| 269 |
+
tt0115798_shot_0844_img_1.jpg Is the person inside the red bounding box named Jim Carrey? Please answer yes or no. Yes
|
| 270 |
+
tt0115798_shot_0844_img_1.jpg Is the person inside the red bounding box named Renee Herlocker? Please answer yes or no. No
|
| 271 |
+
tt0116367_shot_0755_img_0.jpg Is the actor inside the red bounding box named George Clooney? Please answer yes or no. Yes
|
| 272 |
+
tt0116367_shot_0755_img_0.jpg Is the actor inside the red bounding box named Ben Crowley? Please answer yes or no. No
|
| 273 |
+
tt0116629_shot_1570_img_2.jpg Is the person inside the red bounding box called Will Smith? Please answer yes or no. Yes
|
| 274 |
+
tt0116629_shot_1570_img_2.jpg Is the person inside the red bounding box called E. Katherine Kerr? Please answer yes or no. No
|
| 275 |
+
tt0116695_shot_0343_img_0.jpg Is the person inside the red bounding box named Tom Cruise? Please answer yes or no. Yes
|
| 276 |
+
tt0116695_shot_0343_img_0.jpg Is the person inside the red bounding box named Billy Dee? Please answer yes or no. No
|
| 277 |
+
tt0117060_shot_0412_img_0.jpg Is the actor inside the red bounding box called Tom Cruise? Please answer yes or no. Yes
|
| 278 |
+
tt0117060_shot_0412_img_0.jpg Is the actor inside the red bounding box called Carrie Lazar? Please answer yes or no. No
|
| 279 |
+
tt0117060_shot_1401_img_0.jpg Is the actor inside the red bounding box called Jean Reno? Please answer yes or no. Yes
|
| 280 |
+
tt0117060_shot_1401_img_0.jpg Is the actor inside the red bounding box called Jill Teed? Please answer yes or no. No
|
| 281 |
+
tt0117381_shot_0798_img_1.jpg Is the person inside the red bounding box called Edward Norton? Please answer yes or no. Yes
|
| 282 |
+
tt0117381_shot_0798_img_1.jpg Is the person inside the red bounding box called Michael Tezla? Please answer yes or no. No
|
| 283 |
+
tt0117500_shot_2467_img_0.jpg Is the actor inside the red bounding box called Ed Harris? Please answer yes or no. Yes
|
| 284 |
+
tt0117500_shot_2467_img_0.jpg Is the actor inside the red bounding box called Paul J.Q. Lee? Please answer yes or no. No
|
| 285 |
+
tt0117509_shot_0041_img_0.jpg Is the actor inside the red bounding box named Paul Rudd? Please answer yes or no. Yes
|
| 286 |
+
tt0117509_shot_0041_img_0.jpg Is the actor inside the red bounding box named Max Martini? Please answer yes or no. No
|
| 287 |
+
tt0117571_shot_0475_img_0.jpg Is the person inside the red bounding box named Neve Campbell? Please answer yes or no. Yes
|
| 288 |
+
tt0117571_shot_0475_img_0.jpg Is the person inside the red bounding box named Frank Hoyt Taylor? Please answer yes or no. No
|
| 289 |
+
tt0117731_shot_0300_img_0.jpg Is the actor inside the red bounding box called Patrick Stewart? Please answer yes or no. Yes
|
| 290 |
+
tt0117731_shot_0300_img_0.jpg Is the actor inside the red bounding box called Debra Montague? Please answer yes or no. No
|
| 291 |
+
tt0117731_shot_1067_img_0.jpg Is the actor inside the red bounding box called Patrick Stewart? Please answer yes or no. Yes
|
| 292 |
+
tt0117731_shot_1067_img_0.jpg Is the actor inside the red bounding box called Jenny Wilson? Please answer yes or no. No
|
| 293 |
+
tt0118548_shot_1296_img_0.jpg Is the actor inside the red bounding box called Clint Eastwood? Please answer yes or no. Yes
|
| 294 |
+
tt0118548_shot_1296_img_0.jpg Is the actor inside the red bounding box called Kate Winslet? Please answer yes or no. No
|
| 295 |
+
tt0118571_shot_0627_img_0.jpg Is the actor inside the red bounding box called Glenn Close? Please answer yes or no. Yes
|
| 296 |
+
tt0118571_shot_0627_img_0.jpg Is the actor inside the red bounding box called Arlene Farber? Please answer yes or no. No
|
| 297 |
+
tt0118636_shot_0007_img_1.jpg Is the person inside the red bounding box called Brad Renfro? Please answer yes or no. Yes
|
| 298 |
+
tt0118636_shot_0007_img_1.jpg Is the person inside the red bounding box called Sandra Park? Please answer yes or no. No
|
| 299 |
+
tt0118636_shot_0344_img_0.jpg Is the actor inside the red bounding box called Brad Renfro? Please answer yes or no. Yes
|
| 300 |
+
tt0118636_shot_0344_img_0.jpg Is the actor inside the red bounding box called Karen Strassman? Please answer yes or no. No
|
| 301 |
+
tt0118655_shot_0279_img_0.jpg Is the person inside the red bounding box called Robert Wagner? Please answer yes or no. Yes
|
| 302 |
+
tt0118655_shot_0279_img_0.jpg Is the person inside the red bounding box called Arthur Birnbaum? Please answer yes or no. No
|
| 303 |
+
tt0118655_shot_1152_img_2.jpg Is the actor inside the red bounding box called Seth Green? Please answer yes or no. Yes
|
| 304 |
+
tt0118655_shot_1152_img_2.jpg Is the actor inside the red bounding box called Sue Doucette? Please answer yes or no. No
|
| 305 |
+
tt0118689_shot_0706_img_0.jpg Is the actor inside the red bounding box called Rowan Atkinson? Please answer yes or no. Yes
|
| 306 |
+
tt0118689_shot_0706_img_0.jpg Is the actor inside the red bounding box called Hugo Perez? Please answer yes or no. No
|
| 307 |
+
tt0118689_shot_0969_img_2.jpg Is the actor inside the red bounding box called Rowan Atkinson? Please answer yes or no. Yes
|
| 308 |
+
tt0118689_shot_0969_img_2.jpg Is the actor inside the red bounding box called Jack Shields? Please answer yes or no. No
|
| 309 |
+
tt0118715_shot_0079_img_0.jpg Is the actor inside the red bounding box called Jeff Bridges? Please answer yes or no. Yes
|
| 310 |
+
tt0118715_shot_0079_img_0.jpg Is the actor inside the red bounding box called Scott Adkins? Please answer yes or no. No
|
| 311 |
+
tt0118749_shot_0795_img_0.jpg Is the person inside the red bounding box called John C. Reilly? Please answer yes or no. Yes
|
| 312 |
+
tt0118749_shot_0795_img_0.jpg Is the person inside the red bounding box called Chris Lowell? Please answer yes or no. No
|
| 313 |
+
tt0118883_shot_0691_img_1.jpg Is the actor inside the red bounding box called Julia Roberts? Please answer yes or no. Yes
|
| 314 |
+
tt0118883_shot_0691_img_1.jpg Is the actor inside the red bounding box called Roger Bart? Please answer yes or no. No
|
| 315 |
+
tt0118971_shot_0679_img_0.jpg Is the actor inside the red bounding box called Charlize Theron? Please answer yes or no. Yes
|
| 316 |
+
tt0118971_shot_0679_img_0.jpg Is the actor inside the red bounding box called Young-min Kim? Please answer yes or no. No
|
| 317 |
+
tt0119008_shot_0979_img_0.jpg Is the actor inside the red bounding box named Al Pacino? Please answer yes or no. Yes
|
| 318 |
+
tt0119008_shot_0979_img_0.jpg Is the actor inside the red bounding box named Neil Tweddle? Please answer yes or no. No
|
| 319 |
+
tt0119094_shot_0446_img_2.jpg Is the actor inside the red bounding box called Nicolas Cage? Please answer yes or no. Yes
|
| 320 |
+
tt0119094_shot_0446_img_2.jpg Is the actor inside the red bounding box called Juan Gabriel Pareja? Please answer yes or no. No
|
| 321 |
+
tt0119116_shot_0721_img_0.jpg Is the actor inside the red bounding box called Bruce Willis? Please answer yes or no. Yes
|
| 322 |
+
tt0119116_shot_0721_img_0.jpg Is the actor inside the red bounding box called Troye Sivan? Please answer yes or no. No
|
| 323 |
+
tt0119174_shot_0439_img_0.jpg Is the actor inside the red bounding box named Michael Douglas? Please answer yes or no. Yes
|
| 324 |
+
tt0119174_shot_0439_img_0.jpg Is the actor inside the red bounding box named Carola McGuinness? Please answer yes or no. No
|
| 325 |
+
tt0119314_shot_0572_img_0.jpg Is the actor inside the red bounding box called Scarlett Johansson? Please answer yes or no. Yes
|
| 326 |
+
tt0119314_shot_0572_img_0.jpg Is the actor inside the red bounding box called Daisy Beaumont? Please answer yes or no. No
|
| 327 |
+
tt0119528_shot_0171_img_0.jpg Is the person inside the red bounding box called Jim Carrey? Please answer yes or no. Yes
|
| 328 |
+
tt0119528_shot_0171_img_0.jpg Is the person inside the red bounding box called Eliot Paton? Please answer yes or no. No
|
| 329 |
+
tt0119528_shot_0761_img_1.jpg Is the actor inside the red bounding box named Jim Carrey? Please answer yes or no. Yes
|
| 330 |
+
tt0119528_shot_0761_img_1.jpg Is the actor inside the red bounding box named Jari Kinnunen? Please answer yes or no. No
|
| 331 |
+
tt0119643_shot_0330_img_0.jpg Is the actor inside the red bounding box named Brad Pitt? Please answer yes or no. Yes
|
| 332 |
+
tt0119643_shot_0330_img_0.jpg Is the actor inside the red bounding box named Anthony Hopkins? Please answer yes or no. No
|
| 333 |
+
tt0119738_shot_0201_img_0.jpg Is the person inside the red bounding box named Christopher Masterson? Please answer yes or no. Yes
|
| 334 |
+
tt0119738_shot_0201_img_0.jpg Is the person inside the red bounding box named Edwin Craig? Please answer yes or no. No
|
| 335 |
+
tt0119822_shot_0878_img_0.jpg Is the person inside the red bounding box named Greg Kinnear? Please answer yes or no. Yes
|
| 336 |
+
tt0119822_shot_0878_img_0.jpg Is the person inside the red bounding box named Aleksandr Dubina? Please answer yes or no. No
|
| 337 |
+
tt0120338_shot_0444_img_2.jpg Is the actor inside the red bounding box named Kate Winslet? Please answer yes or no. Yes
|
| 338 |
+
tt0120338_shot_0444_img_2.jpg Is the actor inside the red bounding box named Donald Gibb? Please answer yes or no. No
|
| 339 |
+
tt0120338_shot_1130_img_2.jpg Is the person inside the red bounding box called Leonardo DiCaprio? Please answer yes or no. Yes
|
| 340 |
+
tt0120338_shot_1130_img_2.jpg Is the person inside the red bounding box called Anne Betancourt? Please answer yes or no. No
|