Spaces:
Sleeping

Sleeping
313512028_李長鑫
commited on
Add files via upload
Browse files- README.md +25 -25
- app.py +153 -153
- requirements.txt +5 -5
README.md
CHANGED
|
@@ -1,25 +1,25 @@
|
|
| 1 |
-
---
|
| 2 |
-
title: Text To Image
|
| 3 |
-
emoji: 🖼
|
| 4 |
-
colorFrom: purple
|
| 5 |
-
colorTo: red
|
| 6 |
-
sdk: gradio
|
| 7 |
-
sdk_version: 5.0.1
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
-
---
|
| 11 |
-
|
| 12 |
-
# Text-to-Image Generator
|
| 13 |
-
This is a Gradle-based application that uses DiffusionPipeline to generate high-quality images from text prompts. Designed to run seamlessly on Hugging Face Spaces.
|
| 14 |
-
|
| 15 |
-
|
| 16 |
-
[](https://github.com/lee-910530/huggingface-text-to-image/actions/workflows/main.yml)
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
Try Demo Text To Image [Here](https://huggingface.co/spaces/lee-910530/text-to-image)
|
| 20 |
-
|
| 21 |
-
|
| 22 |
-
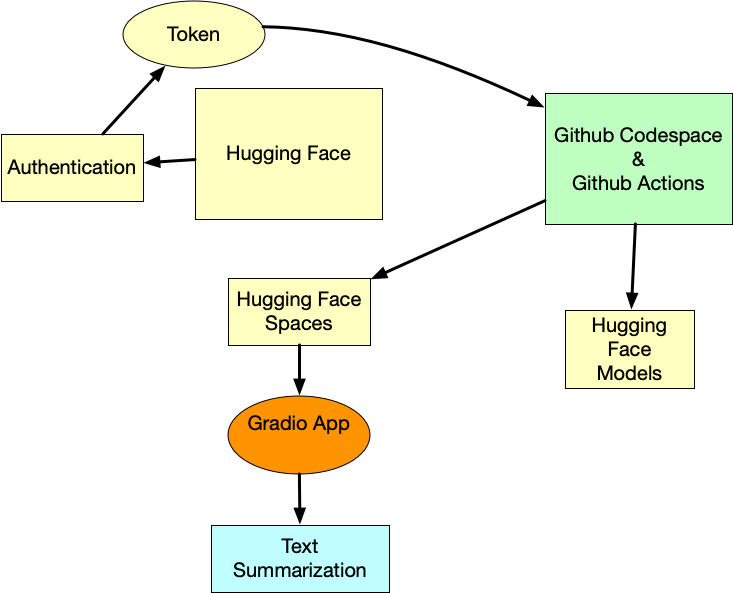
|
| 23 |
-
|
| 24 |
-
# References
|
| 25 |
-
[MLOps with Hugging Face Spaces, Gradio and Github Actions](https://github.com/nogibjj/hugging-face)
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: Text To Image
|
| 3 |
+
emoji: 🖼
|
| 4 |
+
colorFrom: purple
|
| 5 |
+
colorTo: red
|
| 6 |
+
sdk: gradio
|
| 7 |
+
sdk_version: 5.0.1
|
| 8 |
+
app_file: app.py
|
| 9 |
+
pinned: false
|
| 10 |
+
---
|
| 11 |
+
|
| 12 |
+
# Text-to-Image Generator
|
| 13 |
+
This is a Gradle-based application that uses DiffusionPipeline to generate high-quality images from text prompts. Designed to run seamlessly on Hugging Face Spaces.
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
[](https://github.com/lee-910530/huggingface-text-to-image/actions/workflows/main.yml)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
Try Demo Text To Image [Here](https://huggingface.co/spaces/lee-910530/text-to-image)
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+

|
| 23 |
+
|
| 24 |
+
# References
|
| 25 |
+
[MLOps with Hugging Face Spaces, Gradio and Github Actions](https://github.com/nogibjj/hugging-face)
|
app.py
CHANGED
|
@@ -1,154 +1,154 @@
|
|
| 1 |
-
import gradio as gr
|
| 2 |
-
import numpy as np
|
| 3 |
-
import random
|
| 4 |
-
|
| 5 |
-
# import spaces #[uncomment to use ZeroGPU]
|
| 6 |
-
from diffusers import DiffusionPipeline
|
| 7 |
-
import torch
|
| 8 |
-
|
| 9 |
-
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 10 |
-
model_repo_id = "stabilityai/sdxl-turbo" # Replace to the model you would like to use
|
| 11 |
-
|
| 12 |
-
if torch.cuda.is_available():
|
| 13 |
-
torch_dtype = torch.float16
|
| 14 |
-
else:
|
| 15 |
-
torch_dtype = torch.float32
|
| 16 |
-
|
| 17 |
-
pipe = DiffusionPipeline.from_pretrained(model_repo_id, torch_dtype=torch_dtype)
|
| 18 |
-
pipe = pipe.to(device)
|
| 19 |
-
|
| 20 |
-
MAX_SEED = np.iinfo(np.int32).max
|
| 21 |
-
MAX_IMAGE_SIZE = 1024
|
| 22 |
-
|
| 23 |
-
|
| 24 |
-
# @spaces.GPU #[uncomment to use ZeroGPU]
|
| 25 |
-
def infer(
|
| 26 |
-
prompt,
|
| 27 |
-
negative_prompt,
|
| 28 |
-
seed,
|
| 29 |
-
randomize_seed,
|
| 30 |
-
width,
|
| 31 |
-
height,
|
| 32 |
-
guidance_scale,
|
| 33 |
-
num_inference_steps,
|
| 34 |
-
progress=gr.Progress(track_tqdm=True),
|
| 35 |
-
):
|
| 36 |
-
if randomize_seed:
|
| 37 |
-
seed = random.randint(0, MAX_SEED)
|
| 38 |
-
|
| 39 |
-
generator = torch.Generator().manual_seed(seed)
|
| 40 |
-
|
| 41 |
-
image = pipe(
|
| 42 |
-
prompt=prompt,
|
| 43 |
-
negative_prompt=negative_prompt,
|
| 44 |
-
guidance_scale=guidance_scale,
|
| 45 |
-
num_inference_steps=num_inference_steps,
|
| 46 |
-
width=width,
|
| 47 |
-
height=height,
|
| 48 |
-
generator=generator,
|
| 49 |
-
).images[0]
|
| 50 |
-
|
| 51 |
-
return image, seed
|
| 52 |
-
|
| 53 |
-
|
| 54 |
-
examples = [
|
| 55 |
-
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k",
|
| 56 |
-
"An astronaut riding a green horse",
|
| 57 |
-
"A delicious ceviche cheesecake slice",
|
| 58 |
-
]
|
| 59 |
-
|
| 60 |
-
css = """
|
| 61 |
-
#col-container {
|
| 62 |
-
margin: 0 auto;
|
| 63 |
-
max-width: 640px;
|
| 64 |
-
}
|
| 65 |
-
"""
|
| 66 |
-
|
| 67 |
-
with gr.Blocks(css=css) as demo:
|
| 68 |
-
with gr.Column(elem_id="col-container"):
|
| 69 |
-
gr.Markdown(" # Text-to-Image Gradio Template")
|
| 70 |
-
|
| 71 |
-
with gr.Row():
|
| 72 |
-
prompt = gr.Text(
|
| 73 |
-
label="Prompt",
|
| 74 |
-
show_label=False,
|
| 75 |
-
max_lines=1,
|
| 76 |
-
placeholder="Enter your prompt",
|
| 77 |
-
container=False,
|
| 78 |
-
)
|
| 79 |
-
|
| 80 |
-
run_button = gr.Button("Run", scale=0, variant="primary")
|
| 81 |
-
|
| 82 |
-
result = gr.Image(label="Result", show_label=False)
|
| 83 |
-
|
| 84 |
-
with gr.Accordion("Advanced Settings", open=False):
|
| 85 |
-
negative_prompt = gr.Text(
|
| 86 |
-
label="Negative prompt",
|
| 87 |
-
max_lines=1,
|
| 88 |
-
placeholder="Enter a negative prompt",
|
| 89 |
-
visible=False,
|
| 90 |
-
)
|
| 91 |
-
|
| 92 |
-
seed = gr.Slider(
|
| 93 |
-
label="Seed",
|
| 94 |
-
minimum=0,
|
| 95 |
-
maximum=MAX_SEED,
|
| 96 |
-
step=1,
|
| 97 |
-
value=0,
|
| 98 |
-
)
|
| 99 |
-
|
| 100 |
-
randomize_seed = gr.Checkbox(label="Randomize seed", value=True)
|
| 101 |
-
|
| 102 |
-
with gr.Row():
|
| 103 |
-
width = gr.Slider(
|
| 104 |
-
label="Width",
|
| 105 |
-
minimum=256,
|
| 106 |
-
maximum=MAX_IMAGE_SIZE,
|
| 107 |
-
step=32,
|
| 108 |
-
value=1024, # Replace with defaults that work for your model
|
| 109 |
-
)
|
| 110 |
-
|
| 111 |
-
height = gr.Slider(
|
| 112 |
-
label="Height",
|
| 113 |
-
minimum=256,
|
| 114 |
-
maximum=MAX_IMAGE_SIZE,
|
| 115 |
-
step=32,
|
| 116 |
-
value=1024, # Replace with defaults that work for your model
|
| 117 |
-
)
|
| 118 |
-
|
| 119 |
-
with gr.Row():
|
| 120 |
-
guidance_scale = gr.Slider(
|
| 121 |
-
label="Guidance scale",
|
| 122 |
-
minimum=0.0,
|
| 123 |
-
maximum=10.0,
|
| 124 |
-
step=0.1,
|
| 125 |
-
value=0.0, # Replace with defaults that work for your model
|
| 126 |
-
)
|
| 127 |
-
|
| 128 |
-
num_inference_steps = gr.Slider(
|
| 129 |
-
label="Number of inference steps",
|
| 130 |
-
minimum=1,
|
| 131 |
-
maximum=50,
|
| 132 |
-
step=1,
|
| 133 |
-
value=2, # Replace with defaults that work for your model
|
| 134 |
-
)
|
| 135 |
-
|
| 136 |
-
gr.Examples(examples=examples, inputs=[prompt])
|
| 137 |
-
gr.on(
|
| 138 |
-
triggers=[run_button.click, prompt.submit],
|
| 139 |
-
fn=infer,
|
| 140 |
-
inputs=[
|
| 141 |
-
prompt,
|
| 142 |
-
negative_prompt,
|
| 143 |
-
seed,
|
| 144 |
-
randomize_seed,
|
| 145 |
-
width,
|
| 146 |
-
height,
|
| 147 |
-
guidance_scale,
|
| 148 |
-
num_inference_steps,
|
| 149 |
-
],
|
| 150 |
-
outputs=[result, seed],
|
| 151 |
-
)
|
| 152 |
-
|
| 153 |
-
if __name__ == "__main__":
|
| 154 |
demo.launch()
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import numpy as np
|
| 3 |
+
import random
|
| 4 |
+
|
| 5 |
+
# import spaces #[uncomment to use ZeroGPU]
|
| 6 |
+
from diffusers import DiffusionPipeline
|
| 7 |
+
import torch
|
| 8 |
+
|
| 9 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 10 |
+
model_repo_id = "stabilityai/sdxl-turbo" # Replace to the model you would like to use
|
| 11 |
+
|
| 12 |
+
if torch.cuda.is_available():
|
| 13 |
+
torch_dtype = torch.float16
|
| 14 |
+
else:
|
| 15 |
+
torch_dtype = torch.float32
|
| 16 |
+
|
| 17 |
+
pipe = DiffusionPipeline.from_pretrained(model_repo_id, torch_dtype=torch_dtype)
|
| 18 |
+
pipe = pipe.to(device)
|
| 19 |
+
|
| 20 |
+
MAX_SEED = np.iinfo(np.int32).max
|
| 21 |
+
MAX_IMAGE_SIZE = 1024
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
# @spaces.GPU #[uncomment to use ZeroGPU]
|
| 25 |
+
def infer(
|
| 26 |
+
prompt,
|
| 27 |
+
negative_prompt,
|
| 28 |
+
seed,
|
| 29 |
+
randomize_seed,
|
| 30 |
+
width,
|
| 31 |
+
height,
|
| 32 |
+
guidance_scale,
|
| 33 |
+
num_inference_steps,
|
| 34 |
+
progress=gr.Progress(track_tqdm=True),
|
| 35 |
+
):
|
| 36 |
+
if randomize_seed:
|
| 37 |
+
seed = random.randint(0, MAX_SEED)
|
| 38 |
+
|
| 39 |
+
generator = torch.Generator().manual_seed(seed)
|
| 40 |
+
|
| 41 |
+
image = pipe(
|
| 42 |
+
prompt=prompt,
|
| 43 |
+
negative_prompt=negative_prompt,
|
| 44 |
+
guidance_scale=guidance_scale,
|
| 45 |
+
num_inference_steps=num_inference_steps,
|
| 46 |
+
width=width,
|
| 47 |
+
height=height,
|
| 48 |
+
generator=generator,
|
| 49 |
+
).images[0]
|
| 50 |
+
|
| 51 |
+
return image, seed
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
examples = [
|
| 55 |
+
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k",
|
| 56 |
+
"An astronaut riding a green horse",
|
| 57 |
+
"A delicious ceviche cheesecake slice",
|
| 58 |
+
]
|
| 59 |
+
|
| 60 |
+
css = """
|
| 61 |
+
#col-container {
|
| 62 |
+
margin: 0 auto;
|
| 63 |
+
max-width: 640px;
|
| 64 |
+
}
|
| 65 |
+
"""
|
| 66 |
+
|
| 67 |
+
with gr.Blocks(css=css) as demo:
|
| 68 |
+
with gr.Column(elem_id="col-container"):
|
| 69 |
+
gr.Markdown(" # Text-to-Image Gradio Template")
|
| 70 |
+
|
| 71 |
+
with gr.Row():
|
| 72 |
+
prompt = gr.Text(
|
| 73 |
+
label="Prompt",
|
| 74 |
+
show_label=False,
|
| 75 |
+
max_lines=1,
|
| 76 |
+
placeholder="Enter your prompt",
|
| 77 |
+
container=False,
|
| 78 |
+
)
|
| 79 |
+
|
| 80 |
+
run_button = gr.Button("Run", scale=0, variant="primary")
|
| 81 |
+
|
| 82 |
+
result = gr.Image(label="Result", show_label=False)
|
| 83 |
+
|
| 84 |
+
with gr.Accordion("Advanced Settings", open=False):
|
| 85 |
+
negative_prompt = gr.Text(
|
| 86 |
+
label="Negative prompt",
|
| 87 |
+
max_lines=1,
|
| 88 |
+
placeholder="Enter a negative prompt",
|
| 89 |
+
visible=False,
|
| 90 |
+
)
|
| 91 |
+
|
| 92 |
+
seed = gr.Slider(
|
| 93 |
+
label="Seed",
|
| 94 |
+
minimum=0,
|
| 95 |
+
maximum=MAX_SEED,
|
| 96 |
+
step=1,
|
| 97 |
+
value=0,
|
| 98 |
+
)
|
| 99 |
+
|
| 100 |
+
randomize_seed = gr.Checkbox(label="Randomize seed", value=True)
|
| 101 |
+
|
| 102 |
+
with gr.Row():
|
| 103 |
+
width = gr.Slider(
|
| 104 |
+
label="Width",
|
| 105 |
+
minimum=256,
|
| 106 |
+
maximum=MAX_IMAGE_SIZE,
|
| 107 |
+
step=32,
|
| 108 |
+
value=1024, # Replace with defaults that work for your model
|
| 109 |
+
)
|
| 110 |
+
|
| 111 |
+
height = gr.Slider(
|
| 112 |
+
label="Height",
|
| 113 |
+
minimum=256,
|
| 114 |
+
maximum=MAX_IMAGE_SIZE,
|
| 115 |
+
step=32,
|
| 116 |
+
value=1024, # Replace with defaults that work for your model
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
with gr.Row():
|
| 120 |
+
guidance_scale = gr.Slider(
|
| 121 |
+
label="Guidance scale",
|
| 122 |
+
minimum=0.0,
|
| 123 |
+
maximum=10.0,
|
| 124 |
+
step=0.1,
|
| 125 |
+
value=0.0, # Replace with defaults that work for your model
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
num_inference_steps = gr.Slider(
|
| 129 |
+
label="Number of inference steps",
|
| 130 |
+
minimum=1,
|
| 131 |
+
maximum=50,
|
| 132 |
+
step=1,
|
| 133 |
+
value=2, # Replace with defaults that work for your model
|
| 134 |
+
)
|
| 135 |
+
|
| 136 |
+
gr.Examples(examples=examples, inputs=[prompt])
|
| 137 |
+
gr.on(
|
| 138 |
+
triggers=[run_button.click, prompt.submit],
|
| 139 |
+
fn=infer,
|
| 140 |
+
inputs=[
|
| 141 |
+
prompt,
|
| 142 |
+
negative_prompt,
|
| 143 |
+
seed,
|
| 144 |
+
randomize_seed,
|
| 145 |
+
width,
|
| 146 |
+
height,
|
| 147 |
+
guidance_scale,
|
| 148 |
+
num_inference_steps,
|
| 149 |
+
],
|
| 150 |
+
outputs=[result, seed],
|
| 151 |
+
)
|
| 152 |
+
|
| 153 |
+
if __name__ == "__main__":
|
| 154 |
demo.launch()
|
requirements.txt
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
-
accelerate
|
| 2 |
-
diffusers
|
| 3 |
-
invisible_watermark
|
| 4 |
-
torch
|
| 5 |
-
transformers
|
| 6 |
xformers
|
|
|
|
| 1 |
+
accelerate
|
| 2 |
+
diffusers
|
| 3 |
+
invisible_watermark
|
| 4 |
+
torch
|
| 5 |
+
transformers
|
| 6 |
xformers
|