
Seed-Coder
Collection
3 items
•
Updated
We are thrilled to introduce Seed-Coder, a powerful, transparent, and parameter-efficient family of open-source code models at the 8B scale, featuring base, instruct, and reasoning variants. Seed-Coder contributes to promote the evolution of open code models through the following highlights.
This repo contains the Seed-Coder-8B-Reasoning model, which has the following features:
| Model Name | Length | Download | Notes |
|---|---|---|---|
| Seed-Coder-8B-Base | 32K | 🤗 Model | Pretrained on our model-centric code data. |
| Seed-Coder-8B-Instruct | 32K | 🤗 Model | Instruction-tuned for alignment with user intent. |
| 👉 Seed-Coder-8B-Reasoning | 32K | 🤗 Model | RL trained to boost reasoning capabilities. |
You will need to install the latest versions of transformers and accelerate:
pip install -U transformers accelerate
Here is a simple example demonstrating how to load the model and perform code generation using the Hugging Face pipeline API:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "ByteDance-Seed/Seed-Coder-8B-Reasoning"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto", trust_remote_code=True)
messages = [
{"role": "user", "content": "Write a quick sort algorithm."},
]
input_ids = tokenizer.apply_chat_template(
messages,
tokenize=True,
return_tensors="pt",
add_generation_prompt=True,
).to(model.device)
outputs = model.generate(input_ids, max_new_tokens=16384)
response = tokenizer.decode(outputs[0][input_ids.shape[-1]:], skip_special_tokens=True)
print(response)
Seed-Coder-8B-Reasoning strikes impressive performance on competitive programming, demonstrating that smaller LLMs can also be competent on complex reasoning tasks. Our model surpasses QwQ-32B and DeepSeek-R1 on IOI'2024, and achieves an ELO rating comparable to o1-mini on Codeforces contests.

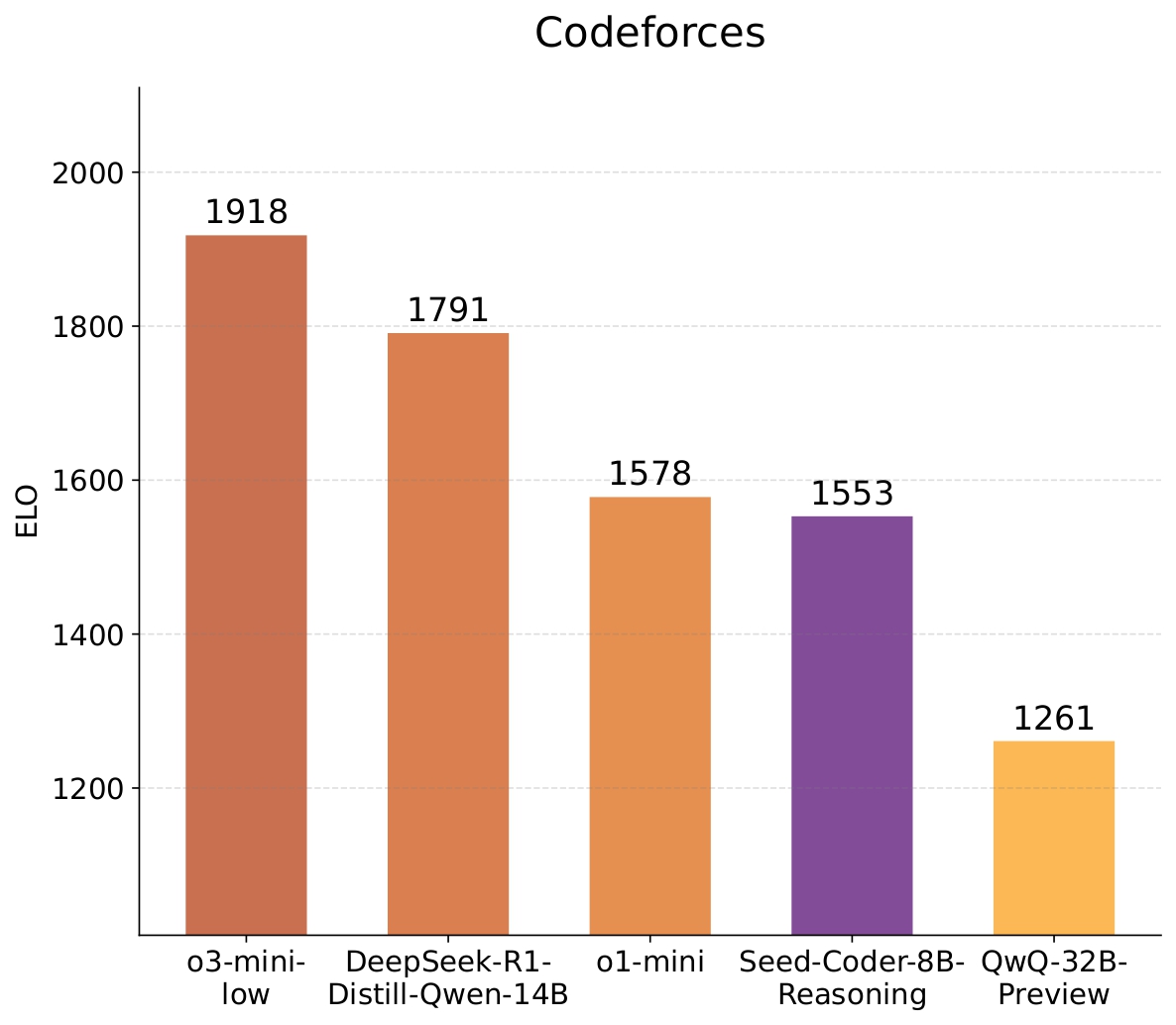
For detailed benchmark performance, please refer to our 📑 Technical Report.
This project is licensed under the MIT License. See the LICENSE file for details.
Base model
ByteDance-Seed/Seed-Coder-8B-Base