
SANA-1.5
Collection
SANA-1.5: Efficient Scaling of Training-Time and Inference-Time Compute in Linear Diffusion Transformer
•
6 items
•
Updated
•
1
![]()






We introduce SANA-1.5,an efficient model with scaling of training-time and inference time techniques. SANA-1.5 delivers: efficient model growth from 1.6B Sana-1.0 model to 4.8B, achieving similar or better performance than training from scratch and saving 60% training cost; efficient model depth pruning, slimming any model size as you want; powerful VLM selection based inference scaling, smaller model+inference scaling > larger model; Top-notch GenEval & DPGBench results. Detailed results are shown in the below table.
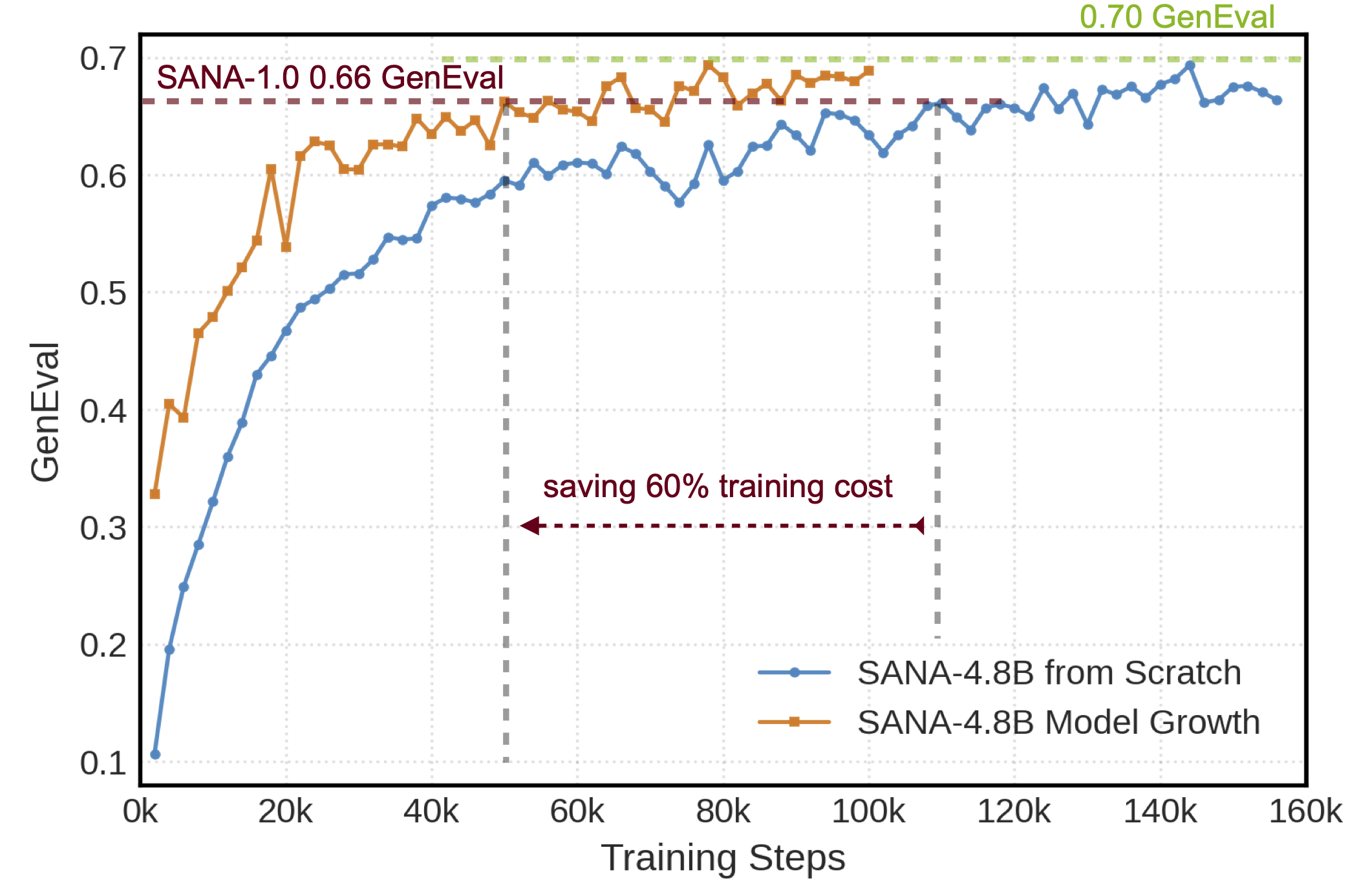
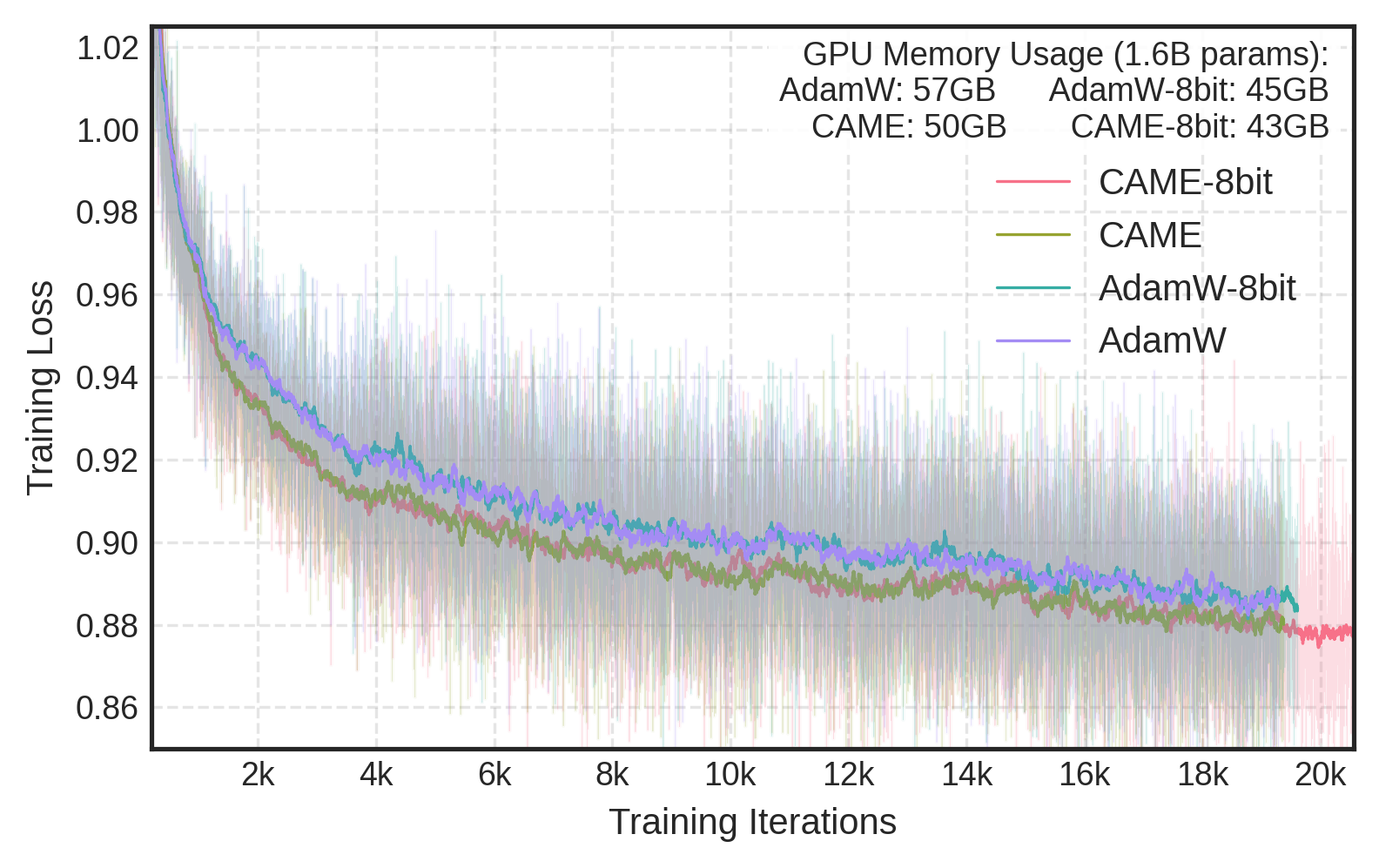
Source code is available at https://github.com/NVlabs/Sana.
For research purposes, we recommend our generative-models Github repository (https://github.com/NVlabs/Sana),
which is more suitable for both training and inference and for which most advanced diffusion sampler like Flow-DPM-Solver is integrated.
MIT Han-Lab provides free Sana inference.
Under construction PR
import torch
from diffusers import SanaPipeline
pipe = SanaPipeline.from_pretrained(
"Efficient-Large-Model/SANA1.5_4.8B_1024px_diffusers",
torch_dtype=torch.bfloat16,
)
pipe.to("cuda")
pipe.text_encoder.to(torch.bfloat16)
# pipe.enable_model_cpu_offload()
prompt = 'Self-portrait oil painting, a beautiful cyborg with golden hair, 8k'
image = pipe(
prompt=prompt,
height=1024,
width=1024,
guidance_scale=4.5,
num_inference_steps=20,
)[0]
image[0].save(f"sana1.5.png")
The model is intended for research purposes only. Possible research areas and tasks include
Generation of artworks and use in design and other artistic processes.
Applications in educational or creative tools.
Research on generative models.
Safe deployment of models which have the potential to generate harmful content.
Probing and understanding the limitations and biases of generative models.
Excluded uses are described below.
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Unable to build the model tree, the base model loops to the model itself. Learn more.