
EMOVA-Models
Collection
A collection of EMOVA models (https://emova-ollm.github.io/)
•
11 items
•
Updated
•
2

🤗 HuggingFace | 📄 Paper | 🌐 Project-Page | 💻 Github | 💻 EMOVA-Github
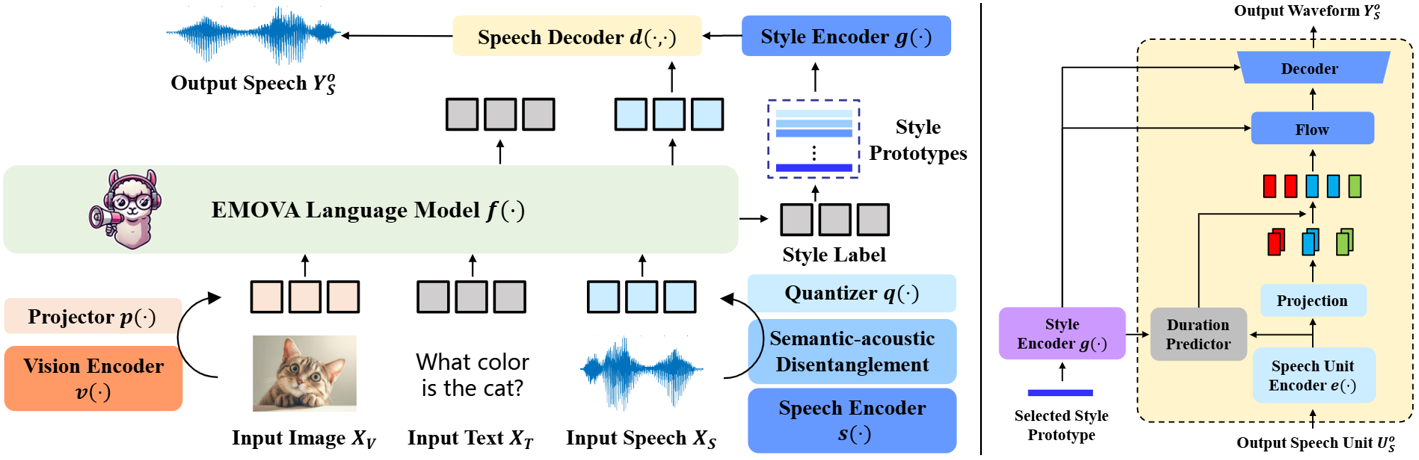
This repo contains the official speech tokenizer used to train the EMOVA series of models. With a semantic-acoustic disentangled design, it not only facilitates seamless omni-modal alignment among vision, language and speech modalities, but also empowers flexible speech style controls including speakers, emotions and pitches. We summarize its key advantages as:
Discrete speech tokenizer: it contains a SPIRAL-based speech-to-unit (S2U) tokenizer to capture both phonetic and tonal information of input speeches, which is then discretized by a finite scalar quantizater (FSQ) into discrete speech units, and a VITS-based unit-to-speech (U2S) de-tokenizer to reconstruct speech signals from speech units.
Semantic-acoustic disentanglement: to seamlessly align speech units with the highly semantic embedding space of LLMs, we opt for decoupling the semantic contents and acoustic styles of input speeches, and only the former are utilized to generate the speech tokens.
Biligunal tokenization: EMOVA speech tokenizer supports both Chinese and English speech tokenization with the same speech codebook.
Flexible speech style control: thanks to the semantic-acoustic disentanglement, EMOVA speech tokenizer supports 24 speech style controls (i.e., 2 speakers, 3 pitches, and 4 emotions). Check the Usage for more details.
Clone this repo and create the EMOVA virtual environment with conda. Our code has been validated on NVIDIA A800/H20 GPU & Ascend 910B3 NPU servers. Other devices might be available as well.
Initialize the conda environment:
git clone https://github.com/emova-ollm/EMOVA_speech_tokenizer.git
conda create -n emova python=3.10 -y
conda activate emova
Install the required packages (note that instructions are different from GPUs and NPUs):
# upgrade pip and setuptools if necessary
pip install -U pip setuptools
cd emova_speech_tokenizer
pip install -e . # for NVIDIA GPUs (e.g., A800 and H20)
pip install -e .[npu] # OR for Ascend NPUS (e.g., 910B3)
Before this, remember to finish Installation first!
EMOVA speech tokenizer can be easily deployed using the 🤗 HuggingFace transformers API!
import random
from transformers import AutoModel
import torch
### Uncomment if you want to use Ascend NPUs
# import torch_npu
# from torch_npu.contrib import transfer_to_npu
# load pretrained model
model = AutoModel.from_pretrained("Emova-ollm/emova_speech_tokenizer_hf", torch_dtype=torch.float32, trust_remote_code=True).eval().cuda()
# S2U
wav_file = "./examples/s2u/example.wav"
speech_unit = model.encode(wav_file)
print(speech_unit)
# U2S
emotion = random.choice(['angry', 'happy', 'neutral', 'sad'])
speed = random.choice(['normal', 'fast', 'slow'])
pitch = random.choice(['normal', 'high', 'low'])
gender = random.choice(['female', 'male'])
condition = f'gender-{gender}_emotion-{emotion}_speed-{speed}_pitch-{pitch}'
output_wav_file = f'./examples/u2s/{condition}_output.wav'
model.decode(speech_unit, condition=condition, output_wav_file=output_wav_file)
If you find our model/code/paper helpful, please consider citing our papers and staring us!
@article{chen2024emova,
title={Emova: Empowering language models to see, hear and speak with vivid emotions},
author={Chen, Kai and Gou, Yunhao and Huang, Runhui and Liu, Zhili and Tan, Daxin and Xu, Jing and Wang, Chunwei and Zhu, Yi and Zeng, Yihan and Yang, Kuo and others},
journal={arXiv preprint arXiv:2409.18042},
year={2024}
}
Base model
Emova-ollm/emova_speech_tokenizer