
Video-GPT via Next Clip Diffusion
![]()
News | Overview | Methodology | Capabilities | Quick Start | Pre-Training | Acknowledgement | License | Citation
1. News
- 2025-5-21:✨✨We release our 4 stages prograssive training code (supporting Huawei's NPU and NVIDIA's GPU). You can refer to LVM/script/train and LVM/train for detailed training information.
- 2025-5-21:✨✨We release the inference code in LVM/script/inference and LVM/inference.
- 2025-5-21:🔥🔥We release the first version of Video-GPT. Model Weight: Video-GPT
2. Overview
Video-GPT is a video self-supervised generative pre-trained model which treats video as new language for visual world modeling by next clip diffusion. It is designed to be simple, flexible, and easy to follow. We provide inference code so that everyone can explore more functionalities of Video-GPT.
Previous works on visual generation relies heavily on supervisory signals from textual modalities (such as Sora, WanX, HunyuanVideo, MovieGen). However, vision, as a natural ability of human beings, was formed even earlier than language. Therefore, we believe that the information of the visual modality itself is sufficient to support the model to model the world.
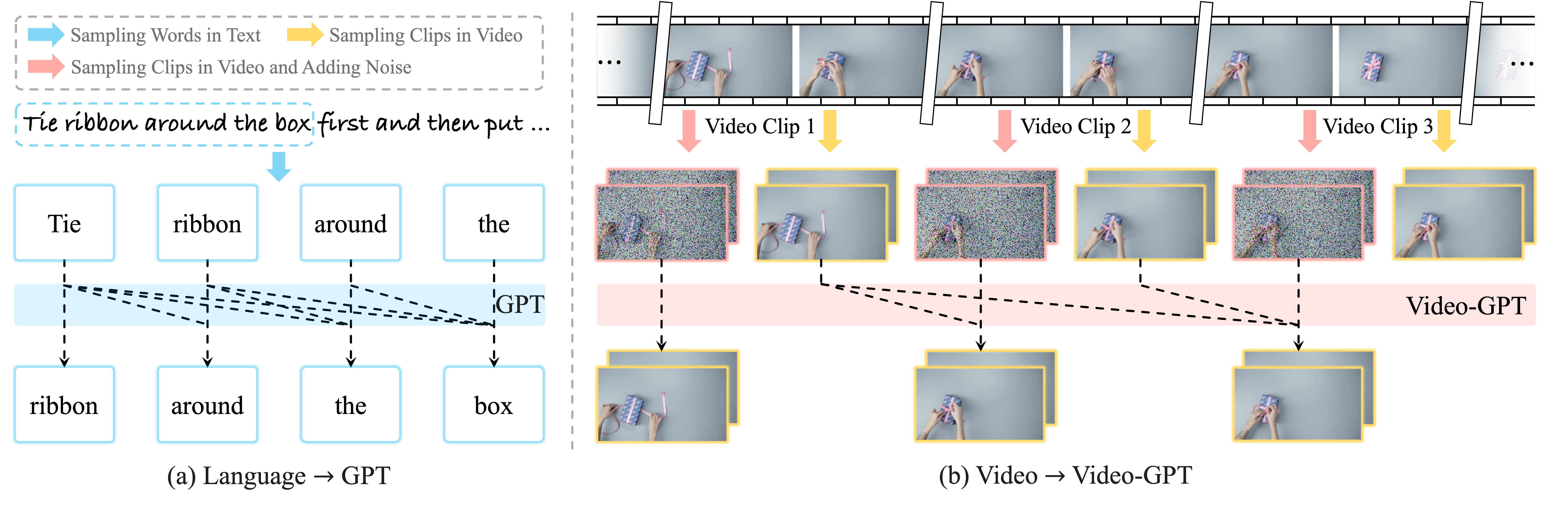
In addition, compared with the previous model architecture with many special designs for diffusion model (e.g., UNet, DiT, MM-DiT), we adopted the simplest vanilla transformer architecture. On the one hand, it is more conducive to the exploration of scaling law in the future. On the other hand, it is also more convenient for the community to follow up.
Due to the limited resources, Video-GPT still has room for improvement. We will continue to optimize it, and hope it inspires more universal video generative foundation models.
If you have any questions, ideas, or interesting tasks you want Video-GPT to accomplish, feel free to discuss with us: [email protected]. We welcome any feedback to help us improve the model.
3. Methodology
You can see details in our paper.
4. What Can Video-GPT do?
Video-GPT is a video self-supervised generative pre-trained model that you can use to perform various tasks. It can be directly applied to video prediction, or fine-tuned to tasks such as video object segmentation and image animation with very little data. Its intermediate layer features are also suitable for representation learning.
Here is the illustrations of Video-GPT's capabilities:
Powerful world modeling capabilities

Based on the pre-trained Video-GPT, we continue training on class to video and text to video tasks, and can achieve better results than training from scratch.


By fine-tuning with a small amount of data, Video-GPT can also achieve good generalization performance on downstream tasks.







5. Quick Start
Using Video-GPT
Install via Github:
git clone https://github.com/zhuangshaobin/Video-GPT.git
cd Video-GPT
If you are using GPUs from NVIDIA, then
bash env_nv.sh
If you are using NPUs from Huawei, then
bash env_hw.sh
Then you can use the following command to extract the first few frames of the video for video prediction. If you are using GPUs from NVIDIA, then
bash LVM/script/inference/inference_nv.sh
If you are using NPUs from Huawei, then
bash LVM/script/inference/inference_hw.sh
6. Pre-Training
We provide our 4 stage training script to train or fine-tune Video-GPT. If you are using GPUs from NVIDIA, then
# 1-stage pre-training
bash LVM/script/train/pretrain_stage1_nv.sh
# 2-stage pre-training
bash LVM/script/train/pretrain_stage2_nv.sh
# 3-stage pre-training
bash LVM/script/train/pretrain_stage3_nv.sh
# 4-stage pre-training
bash LVM/script/train/pretrain_stage4_nv.sh
If you are using NPUs from Huawei, then
# 1-stage pre-training
bash LVM/script/train/pretrain_stage1_hw.sh
# 2-stage pre-training
bash LVM/script/train/pretrain_stage2_hw.sh
# 3-stage pre-training
bash LVM/script/train/pretrain_stage3_hw.sh
# 4-stage pre-training
bash LVM/script/train/pretrain_stage4_hw.sh
Acknowledgement
We built our repository based on the repository of OmniGen, which also did a great job!
License
This repo is licensed under the MIT License.
Citation
If you find this repository useful, please consider giving a star ⭐ and citation
@article{zhuang2025videogptclipdiffusion,
title={Video-GPT via Next Clip Diffusion},
author={Shaobin Zhuang and Zhipeng Huang and Ying Zhang and Fangyikang Wang and Canmiao Fu and Binxin Yang and Chong Sun and Chen Li and Yali Wang},
journal={arXiv preprint arXiv:2505.12489},
year={2025}
}
- Downloads last month
- 0