
Model Card for MultiBridge/wav2vec-LnNor-IPA-ft
This model is built for phoneme recognition tasks. It was developed by fine-tuning the wav2vec2 base model on TIMIT and LnNor datasets. The predictions are in IPA.
Model Details
Model Description
- Developed by: Multibridge
- Funded by [optional]: EEA Financial Mechanism and Norwegian Financial Mechanism
- Shared by [optional]: Multibridge
- Model type: Transformer
- Language(s) (NLP): English
- License: cc-by-4.0
- Finetuned from model [optional]: facebook/wav2vec2-base
Uses
Automatic phonetic transcription: Converting raw speech into phoneme sequences.
Speech processing applications: Serving as a component in speech processing pipelines or prototyping.
Bias, Risks, and Limitations
data specificity: By excluding recordings shorter than 2 seconds or longer than 30 seconds, and labels with fewer than 5 phonemes, some natural speech variations are ignored. This might affect the model's performance in real-world applications. The model's performance is influenced by the characteristics of TIMIT and LnNor datasets. This can lead to potential biases, especially if the target application involves speakers or dialects not well-represented in these datasets. LnNor contains non-native speech and automaticly generated annotations that don't reflect true pronunciation rather canonical pronunciation. This could result in a model that fails to accurately predict non-native speech.
frozen encoder: Freezing the encoder retains useful pre-learned features but also prevents the model from adapting fully to the new datasets.
Recommendations
Evaluate the model's performance for your specific use case.
How to Get Started with the Model
Use the code below to get started with the model.
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torch
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("MultiBridge/wav2vec-LnNor-IPA-ft")
model = Wav2Vec2ForCTC.from_pretrained("MultiBridge/wav2vec-LnNor-IPA-ft")
# load dummy dataset and read soundfiles
ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", split="validation")
# tokenize
input_values = processor(ds[0]["audio"]["array"], return_tensors="pt").input_values
# retrieve logits
with torch.no_grad():
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
# => should give ['mɪstɝkwɪltɝɪzðəəpɑslʌvðəmɪdəlklæsəzændwiɑəɡlædtəwɛlkəmhɪzɡɑspəl'] for MISTER QUILTER IS THE APOSTLE OF THE MIDDLE CLASSES AND WE ARE GLAD TO WELCOME HIS GOSPEL
Training Details
Training Data
The training data comes from two key sources:
TIMIT: A widely-used dataset for phonetic transcription, providing a standard benchmark in speech research.
LnNor: A multilingual dataset of high-quality speech recordings in Norwegian, English, and Polish. The dataset compiled from non-native speakers with various language proficiencies. The phoneme annotations in LnNor were generated using the WebMAUS tool, meaning they represent canonical phonemes rather than the true pronunciations typical of spontaneous speech or non native pronunciation.
Training Procedure
The original, pre-trained encoder representations were preserved - the encoder was kept frozen during fine-tuning in order to minimizes training time and resource consumption. The model was trained with CTC loss and AdamW optimizer, with no learning rate scheduler.
Preprocessing [optional]
The training dataset was filtered. Recordings shorter than 2 seconds or longer than 30 seconds were removed. Any labels consisting of fewer than 5 phonemes were discarded.
Training Hyperparameters
Training regime:
- learning rate: 1e-5
- optimizer: AdamW
- batch size: 64
- weight decay: 0.001
- epochs: 40
Speeds, Sizes, Times [optional]
- Avg epoch training time: 650s
- Number of updates: ~25k
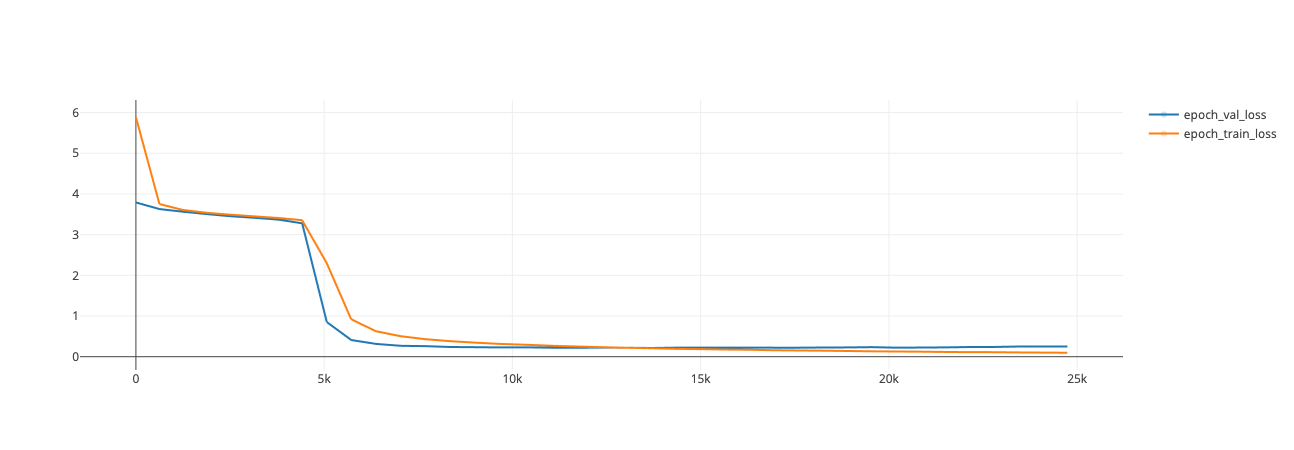
- Final training loss: 0.09713
- Final validation loss: 0.2142
Evaluation
Testing Data, Factors & Metrics
Testing Data
The model was evaluated on TIMIT's test split.
Metrics
CER/PER (Phoneme Error Rate)
Results
PER (Phoneme Error Rate) on TIMIT's test split: 0.0416
Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type: Nvidia A100-80
- Hours used: [More Information Needed]
- Cloud Provider: Poznan University of Technology
- Compute Region: Poland
- Carbon Emitted: [More Information Needed]
Technical Specifications [optional]
Model Architecture and Objective
Transformer model + CTC loss
Compute Infrastructure
Hardware
2 x Nvidia A100-80
Software
python 3.12
transformers 4.50.0
torch 2.6.0
Citation [optional]
BibTeX:
I you use the LnNor dataset for research, cite these papers:
@article{magdalena2024lnnor,
title={The LnNor Corpus: A spoken multilingual corpus of non-native and native Norwegian, English and Polish (Part 1)},
author={Magdalena, Wrembel and Hwaszcz, Krzysztof and Agnieszka, Pludra and Ska{\l}ba, Anna and Weckwerth, Jaros{\l}aw and Walczak, Angelika and Sypia{\'n}ska, Jolanta and {\.Z}ychli{\'n}ski, Sylwiusz and Malarski, Kamil and K{\k{e}}dzierska, Hanna and others},
year={2024},
publisher={Adam Mickiewicz University}
}
@article{wrembel2024lnnor,
title={The LnNor Corpus: A spoken multilingual corpus of non-native and native Norwegian, English and Polish--Part 2},
author={Wrembel, Magdalena and Hwaszcz, Krzysztof and Pludra, Agnieszka and Ska{\l}ba, Anna and Weckwerth, Jaros{\l}aw and Malarski, Kamil and Cal, Zuzanna Ewa and K{\k{e}}dzierska, Hanna and Czarnecki-Verner, Tristan and Balas, Anna and others},
year={2024},
publisher={Adam Mickiewicz University}
}
Model Card Authors [optional]
Agnieszka Pludra
Izabela Krysińska
Piotr Kabaciński
Model Card Contact
- Downloads last month
- 18
Model tree for MultiBridge/wav2vec-LnNor-IPA-ft
Base model
facebook/wav2vec2-base