
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
All my models - in order
Collection
29 items
•
Updated
•
6

It's the 10th of May, 2025—lots of progress is being made in the world of AI (DeepSeek, Qwen, etc...)—but still, there has yet to be a fully coherent 1B RP model. Why?
Well, at 1B size, the mere fact a model is even coherent is some kind of a marvel—and getting it to roleplay feels like you're asking too much from 1B parameters. Making very small yet smart models is quite hard, making one that does RP is exceedingly hard. I should know.
I've made the world's first 3B roleplay model—Impish_LLAMA_3B—and I thought that this was the absolute minimum size for coherency and RP capabilities. I was wrong.
One of my stated goals was to make AI accessible and available for everyone—but not everyone could run 13B or even 8B models. Some people only have mid-tier phones, should they be left behind?
A growing sentiment often says something along the lines of:
If your waifu runs on someone else's hardware—then she's not your waifu.
I'm not an expert in waifu culture, but I do agree that people should be able to run models locally, without their data (knowingly or unknowingly) being used for X or Y.
I thought my goal of making a roleplay model that everyone could run would only be realized sometime in the future—when mid-tier phones got the equivalent of a high-end Snapdragon chipset. Again I was wrong, as this changes today.
Today, the 10th of May 2025, I proudly present to you—Nano_Imp_1B, the world's first and only fully coherent 1B-parameter roleplay model.

Intended use: Role-Play, Basic Creative Writing, Basic General Tasks.
Censorship level: Medium
4.5 / 10 (10 completely uncensored)
Pending
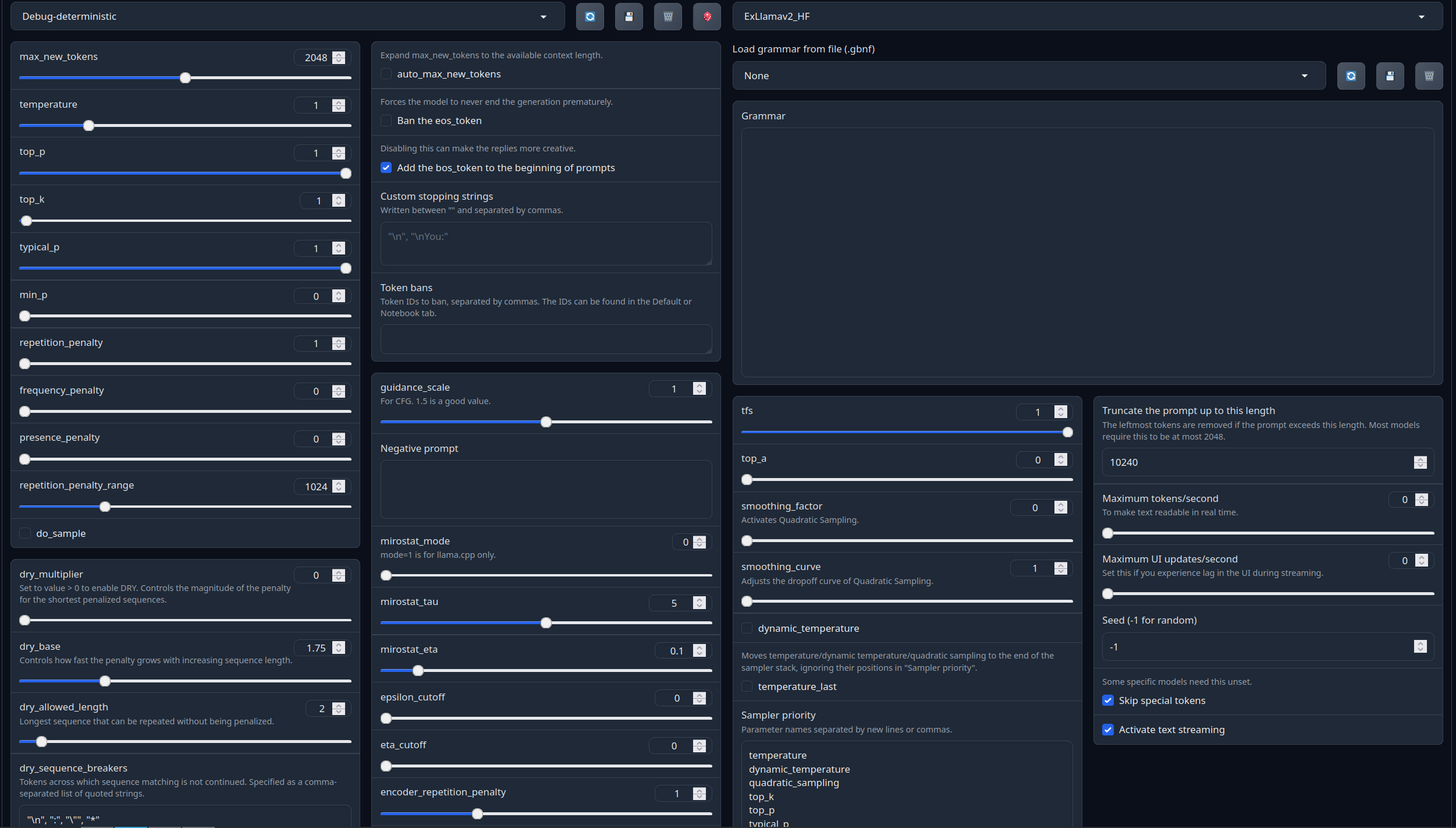
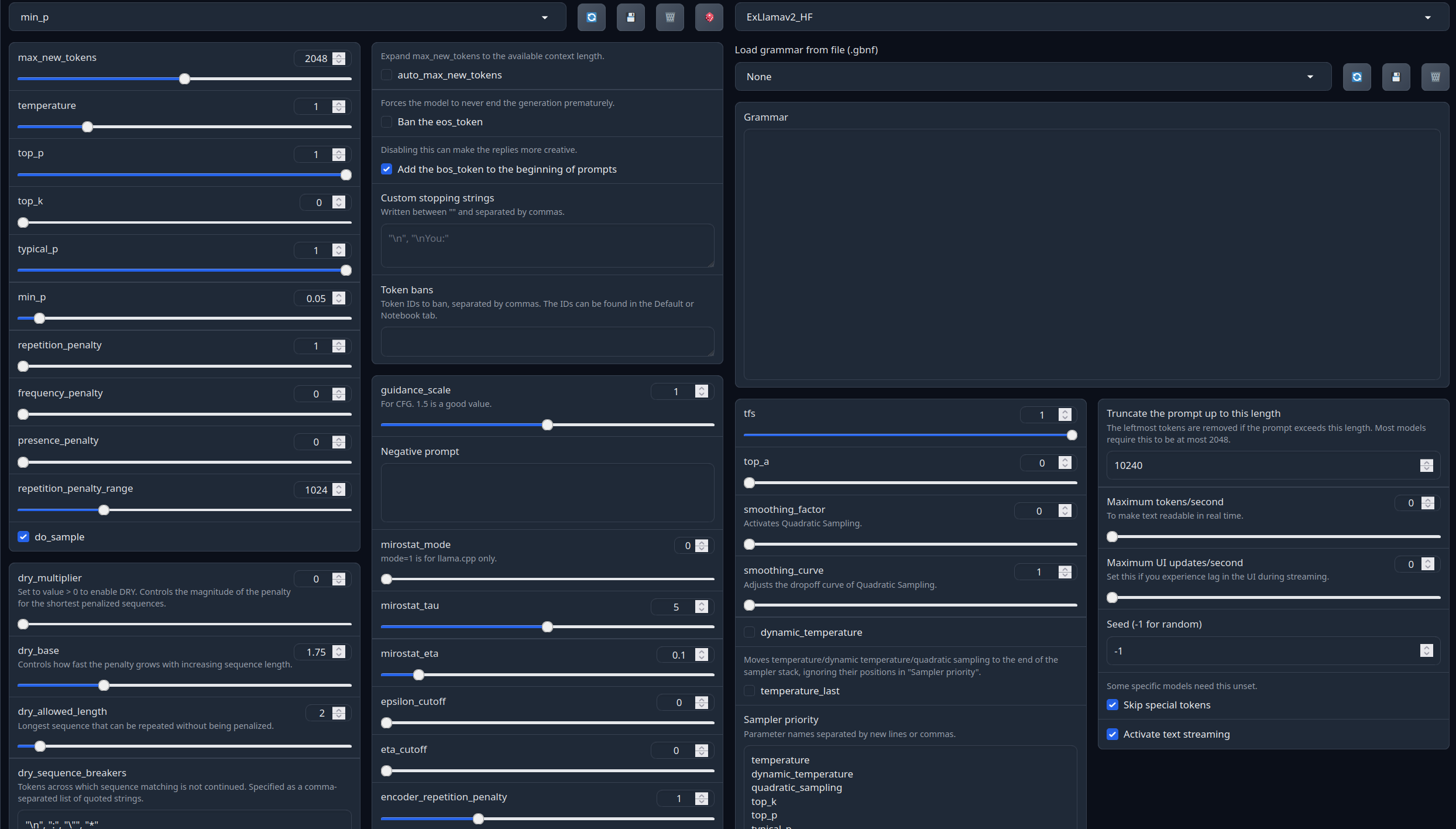
With these settings, each output message should be neatly displayed in 1 - 5 paragraphs, 2 - 3 is the most common. A single paragraph will be output as a response to a simple message ("What was your name again?").
min_P for RP works too but is more likely to put everything under one large paragraph, instead of a neatly formatted short one. Feel free to switch in between.
(Open the image in a new window to better see the full details)

temperature: 0.8
top_p: 0.95
top_k: 25
typical_p: 1
min_p: 0
repetition_penalty: 1.12
repetition_penalty_range: 1024
*action* speech *narration*
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{input}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{output}<|eot_id|>
Other recommended generation Presets:
max_new_tokens: 512
temperature: 0.98
top_p: 0.37
top_k: 100
typical_p: 1
min_p: 0
repetition_penalty: 1.18
do_sample: True
max_new_tokens: 512
temperature: 1.31
top_p: 0.14
top_k: 49
typical_p: 1
min_p: 0
repetition_penalty: 1.17
do_sample: True
max_new_tokens: 512
temperature: 0.7
top_p: 0.9
top_k: 20
typical_p: 1
min_p: 0
repetition_penalty: 1.15
do_sample: True
@llm{Nano_Imp_1B,
author = {SicariusSicariiStuff},
title = {Nano_Imp_1B},
year = {2025},
publisher = {Hugging Face},
url = {https://huggingface.co/SicariusSicariiStuff/Nano_Imp_1B}
}
Base model
meta-llama/Llama-3.2-1B-Instruct