
Vamba
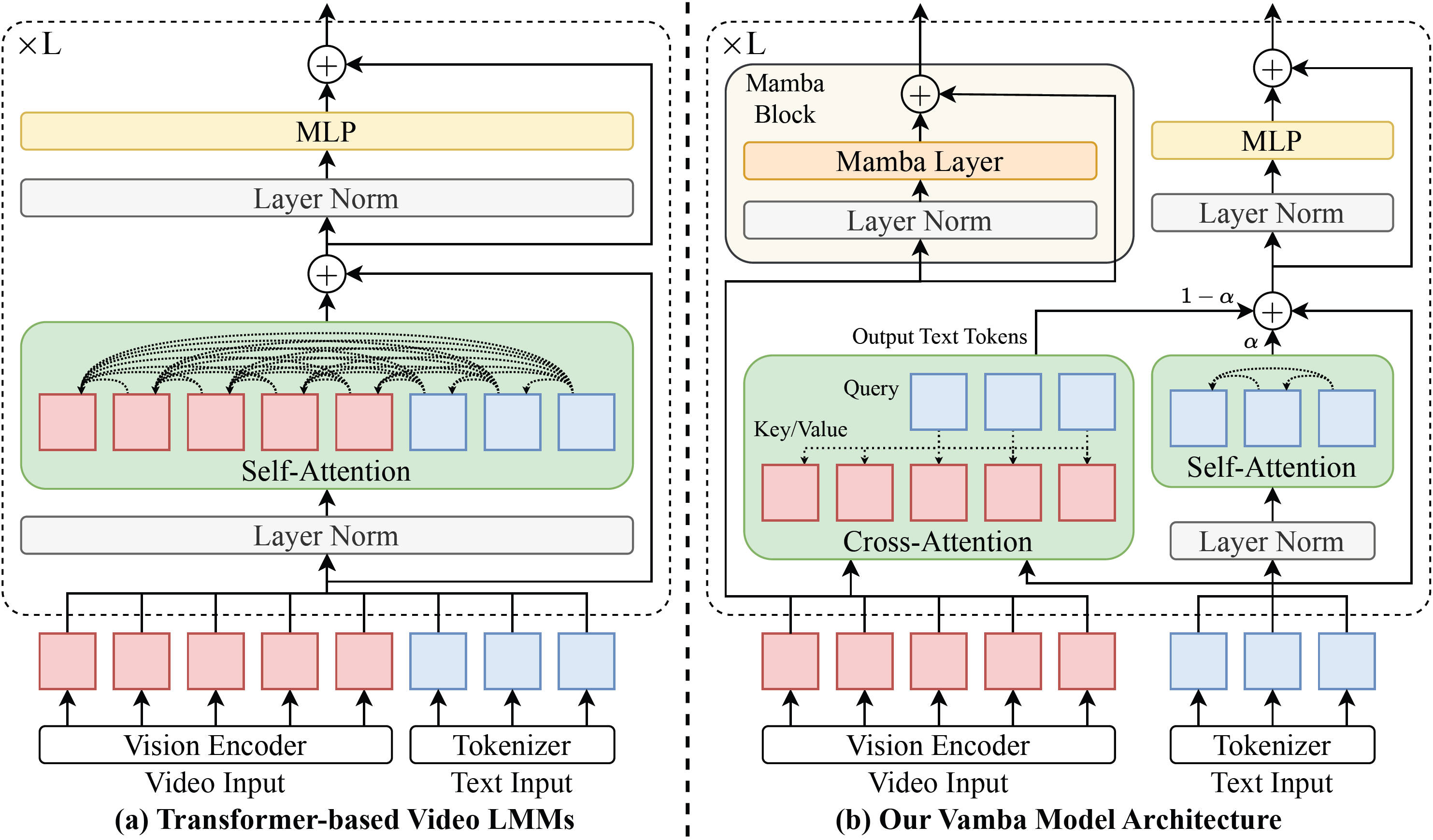
This repo contains model checkpoints for Vamba-Qwen2-VL-7B. Vamba is a hybrid Mamba-Transformer model that leverages cross-attention layers and Mamba-2 blocks for efficient hour-long video understanding.
🌐 Homepage | 📖 arXiv | 💻 GitHub | 🤗 Model
Vamba Model Architecture
Citation
If you find our paper useful, please cite us with
coming soon
- Downloads last month
- 3
Inference Providers
NEW
This model is not currently available via any of the supported Inference Providers.
The model cannot be deployed to the HF Inference API:
The model has no library tag.