
The dataset viewer is not available for this subset.
Exception: SplitsNotFoundError
Message: The split names could not be parsed from the dataset config.
Traceback: Traceback (most recent call last):
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/inspect.py", line 299, in get_dataset_config_info
for split_generator in builder._split_generators(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/packaged_modules/webdataset/webdataset.py", line 83, in _split_generators
raise ValueError(
ValueError: The TAR archives of the dataset should be in WebDataset format, but the files in the archive don't share the same prefix or the same types.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/src/services/worker/src/worker/job_runners/config/split_names.py", line 65, in compute_split_names_from_streaming_response
for split in get_dataset_split_names(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/inspect.py", line 353, in get_dataset_split_names
info = get_dataset_config_info(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/inspect.py", line 304, in get_dataset_config_info
raise SplitsNotFoundError("The split names could not be parsed from the dataset config.") from err
datasets.inspect.SplitsNotFoundError: The split names could not be parsed from the dataset config.Need help to make the dataset viewer work? Make sure to review how to configure the dataset viewer, and open a discussion for direct support.
FaceID-6M: A Large-Scale, Open-Source FaceID Customization Dataset
This repository contains the dataset described in FaceID-6M: A Large-Scale, Open-Source FaceID Customization Dataset.
Links
Introduction
FaceID-6M, is the first large-scale, open-source faceID dataset containing 6 million high-quality text-image pairs. Filtered from LAION-5B, which includes billions of diverse and publicly available text-image pairs, FaceID-6M undergoes a rigorous image and text filtering process to ensure dataset quality. For image filtering, we apply a pre-trained face detection model to remove images that lack human faces, contain more than three faces, have low resolution, or feature faces occupying less than 4% of the total image area. For text filtering, we implement a keyword-based strategy to retain descriptions containing human-related terms, including references to people (e.g., man), nationality (e.g., Chinese), ethnicity (e.g., East Asian), professions (e.g., engineer), and names (e.g., Donald Trump). Through these cleaning processes, FaceID-6M provides a high-quality dataset optimized for training powerful FaceID customization models, facilitating advancements in the field by offering an open resource for research and development.

Comparison with Previous Works
FaceID Fidelity

Based on these results, we can infer that the model trained on our FaceID-6M dataset achieves a level of performance comparable to the official InstantID model in maintaining FaceID fidelity. For example, in case 2 and case 3, both the official InstantID model and the FaceID-6M-trained model effectively generate the intended images based on the input. This clearly highlights the effectiveness of our FaceID-6M dataset in training robust FaceID customization models.
Scaling Results
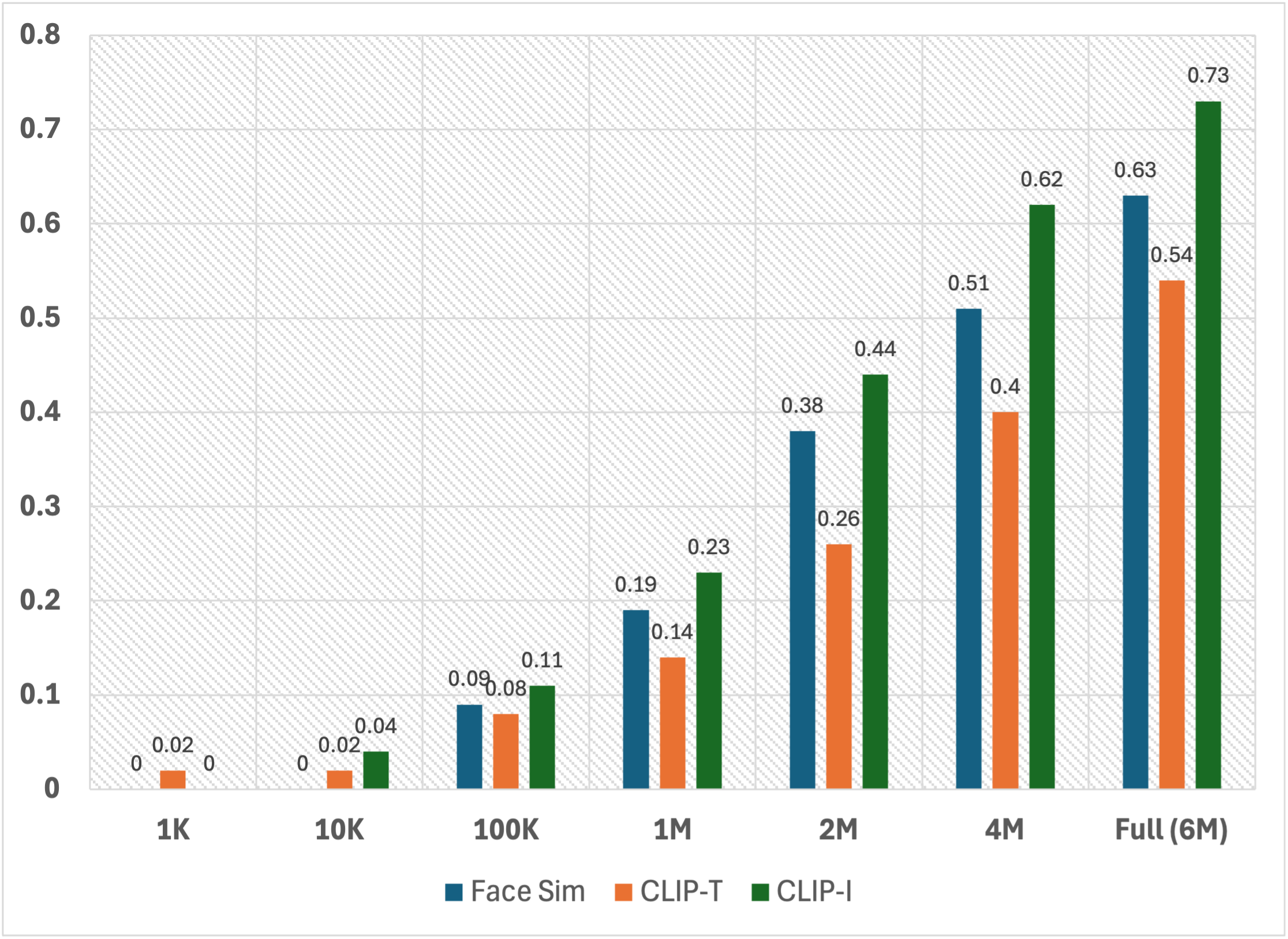
To evaluate the impact of dataset size on model performance and optimize the trade-off between performance and training cost, we conduct scaling experiments by sampling subsets of different sizes from FaceID-6M. The sampled dataset sizes include: (1) 1K, (2) 10K, (3) 100K, (4) 1M, (5) 2M, (6) 4M, and (7) the full dataset (6M). For the experimental setup, we utilize the InstantID FaceID customization framework and adhere to the configurations used in the previous quantitative evaluations. The trained models are tested on the subset of COCO2017 test set, with Face Sim, CLIP-T, and CLIP-I as the evaluation metrics.
The results demonstrate a clear correlation between training dataset size and the performance of FaceID customization models. For example, the Face Sim score increased from 0.38 with 2M training data, to 0.51 with 4M, and further improved to 0.63 when using 6M data. These results underscore the significant contribution of our FaceID-6M dataset in advancing FaceID customization research, highlighting its importance in driving improvements in the field.
Released FaceID-6M dataset
We release two versions of our constructed dataset:
- FaceID-70K: This is a subset of our FaceID-6M by further removing images lower than 1024 pixels either in width or height, consisting approximately 70K text-image pairs.
- FaceID-6M: This is our constructed full FaceID customization dataset.
Please note that due to the large file size, we have pre-split it into multiple smaller parts. Before use, please execute the merge and unzip commands to restore the full file. Take the InstantID-FaceID-70K dataset as the example:
cat laion_1024.tar.gz.* > laion_1024.tar.gztar zxvf laion_1024.tar.gz
Index
After restoring the full dataset, you will find large amounts .png and .npy file, and also a ./face directory and a *.jsonl file:
*.png: Tmage files*.npy: The pre-computed landmarks of the face in the related image, which is necessary to train InstantID-based models. If you don't need that, just ignore them../face: The directory including face files.*.jsonl: Descriptions or texts. Ignore the file paths listed in the.jsonlfile and use the line number instead to locate the corresponding image, face, and.npyfiles. For example, the 0th line in the.jsonlfile corresponds to0.png,0.npy, and./face/0.png.
Released FaceID Customization Models
We release two versions of trained InstantID models:
- InstantID-FaceID-70K: Model trained on our FaceID-70K dataset.
- InstantID-FaceID-6M: Model trained on our FaceID-6M dataset.
Usage
For instructions on training and inference of FaceID customization models using our dataset, please visit our GitHub repository: https://github.com/ShuheSH/FaceID-6M
Contact
If you have any issues or questions about this repo, feel free to contact [email protected]
@article{wang2025faceid,
title={FaceID-6M: A Large-Scale, Open-Source FaceID Customization Dataset},
author={Wang, Shuhe and Li, Xiaoya and Li, Jiwei and Wang, Guoyin and Sun, Xiaofei and Zhu, Bob and Qiu, Han and Yu, Mo and Shen, Shengjie and Hovy, Eduard},
journal={arXiv preprint arXiv:2503.07091},
year={2025}
}
- Downloads last month
- 8,620