
Update README.md
Browse files
README.md
CHANGED
|
@@ -4,6 +4,101 @@ task_categories:
|
|
| 4 |
- text-to-image
|
| 5 |
---
|
| 6 |
|
| 7 |
-
|
| 8 |
|
| 9 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4 |
- text-to-image
|
| 5 |
---
|
| 6 |
|
| 7 |
+
# FaceID-6M: A Large-Scale, Open-Source FaceID Customization Dataset
|
| 8 |
|
| 9 |
+
This repository contains the dataset described in [FaceID-6M: A Large-Scale, Open-Source FaceID Customization Dataset](https://arxiv.org/abs/2503.07091).
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
## Links
|
| 13 |
+
- [FaceID-6M: A Large-Scale, Open-Source FaceID Customization Dataset](#faceid-6m-a-large-scale-open-source-faceid-customization-dataset)
|
| 14 |
+
- [Introduction](#introduction)
|
| 15 |
+
- [Comparison with Previous Works](#comparison-with-previous-works)
|
| 16 |
+
- [FaceID Fidelity](#faceid-fidelity)
|
| 17 |
+
- [Scaling Results](#scaling-results)
|
| 18 |
+
- [Released FaceID-6M dataset](#released-faceid-6m-dataset)
|
| 19 |
+
- [Released FaceID Customization Models](#released-faceid-customization-models)
|
| 20 |
+
- [Usage](#usage)
|
| 21 |
+
- [Contact](#contact)
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
## Introduction
|
| 27 |
+
|
| 28 |
+
FaceID-6M, is the first large-scale, open-source faceID dataset containing 6 million high-quality text-image pairs. Filtered from [LAION-5B](https://laion.ai/blog/laion-5b/), which includes billions of diverse and publicly available text-image pairs, FaceID-6M undergoes a rigorous image and text filtering process to ensure dataset quality. For image filtering, we apply a pre-trained face detection model to remove images that lack human faces, contain more than three faces, have low resolution, or feature faces occupying less than 4% of the total image area. For text filtering, we implement a keyword-based strategy to retain descriptions containing human-related terms, including references to people (e.g., man), nationality (e.g., Chinese), ethnicity (e.g., East Asian), professions (e.g., engineer), and names (e.g., Donald Trump).
|
| 29 |
+
Through these cleaning processes, FaceID-6M provides a high-quality dataset optimized for training powerful FaceID customization models, facilitating advancements in the field by offering an open resource for research and development.
|
| 30 |
+
|
| 31 |
+

|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
## Comparison with Previous Works
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
### FaceID Fidelity
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+

|
| 42 |
+
|
| 43 |
+
Based on these results, we can infer that the model trained on our FaceID-6M dataset achieves a level of performance comparable to the official InstantID model in maintaining FaceID fidelity. For example, in case 2 and case 3, both the official InstantID model and the FaceID-6M-trained model effectively generate the intended images based on the input.
|
| 44 |
+
This clearly highlights the effectiveness of our FaceID-6M dataset in training robust FaceID customization models.
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
### Scaling Results
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
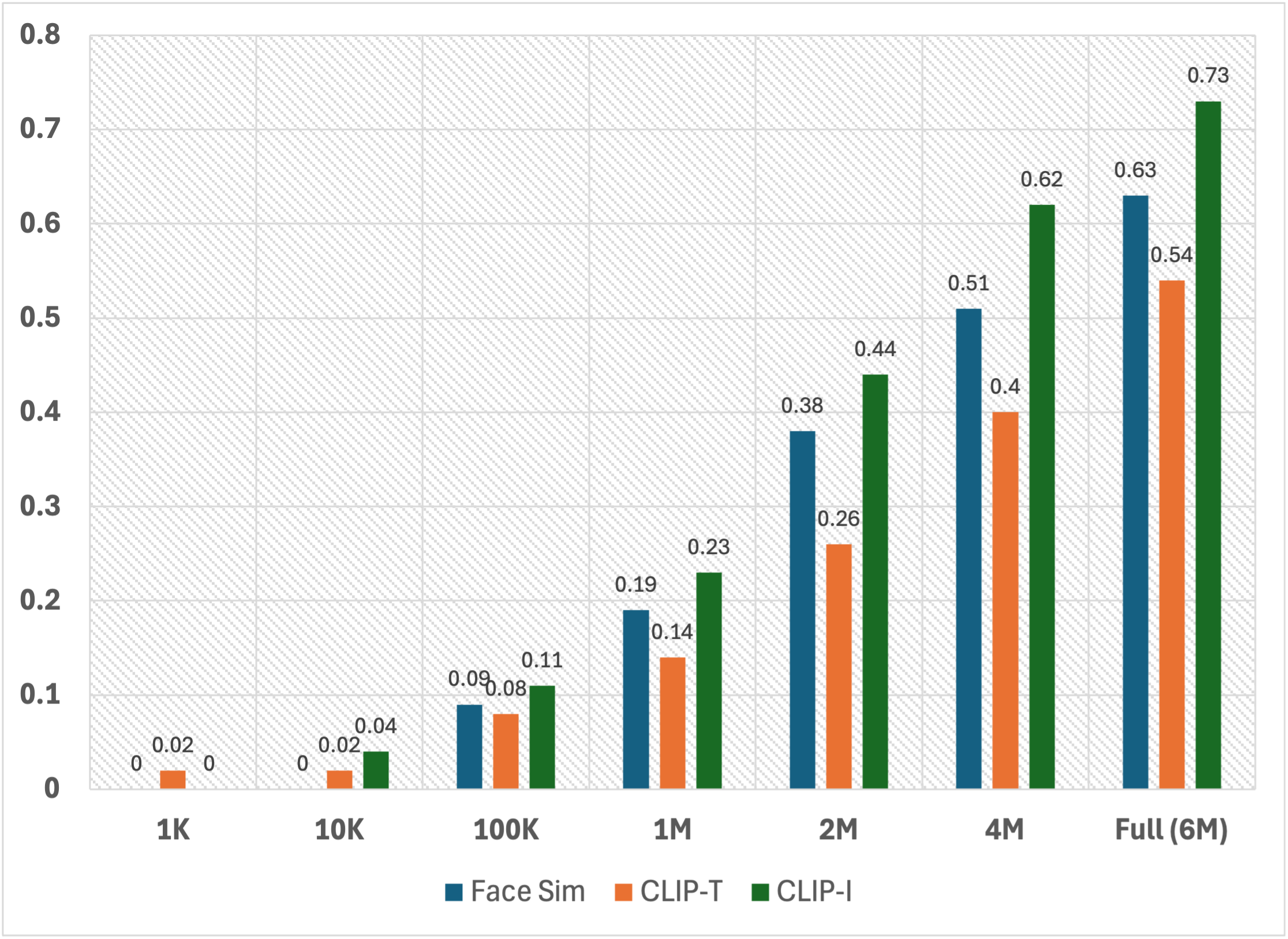
To evaluate the impact of dataset size on model performance and optimize the trade-off between performance and training cost, we conduct scaling experiments by sampling subsets of different sizes from FaceID-6M.
|
| 53 |
+
The sampled dataset sizes include: (1) 1K, (2) 10K, (3) 100K, (4) 1M, (5) 2M, (6) 4M, and (7) the full dataset (6M).
|
| 54 |
+
For the experimental setup, we utilize the [InstantID](https://github.com/instantX-research/InstantID) FaceID customization framework and adhere to the configurations used in the previous quantitative evaluations. The trained models are tested on the subset of [COCO2017](https://cocodataset.org/#detection-2017) test set, with Face Sim, CLIP-T, and CLIP-I as the evaluation metrics.
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
The results demonstrate a clear correlation between training dataset size and the performance of FaceID customization models.
|
| 58 |
+
For example, the Face Sim score increased from 0.38 with 2M training data, to 0.51 with 4M, and further improved to 0.63 when using 6M data.
|
| 59 |
+
These results underscore the significant contribution of our FaceID-6M dataset in advancing FaceID customization research, highlighting its importance in driving improvements in the field.
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
## Released FaceID-6M dataset
|
| 63 |
+
|
| 64 |
+
We release two versions of our constructed dataset:
|
| 65 |
+
1. [FaceID-70K](https://huggingface.co/datasets/Super-shuhe/FaceID-70K): This is a subset of our FaceID-6M by further removing images lower than 1024 pixels either in width or height, consisting approximately 70K text-image pairs.
|
| 66 |
+
2. [FaceID-6M](https://huggingface.co/datasets/Super-shuhe/FaceID-6M): This is our constructed full FaceID customization dataset.
|
| 67 |
+
|
| 68 |
+
Please note that due to the large file size, we have pre-split it into multiple smaller parts. Before use, please execute the merge and unzip commands to restore the full file. Take the InstantID-FaceID-70K dataset as the example:
|
| 69 |
+
1. `cat laion_1024.tar.gz.* > laion_1024.tar.gz`
|
| 70 |
+
2. `tar zxvf laion_1024.tar.gz`
|
| 71 |
+
|
| 72 |
+
**Index**
|
| 73 |
+
|
| 74 |
+
After restoring the full dataset, you will find large amounts `.png` and `.npy` file, and also a `./face` directory and a `*.jsonl` file:
|
| 75 |
+
1. `*.png`: Tmage files
|
| 76 |
+
2. `*.npy`: The pre-computed landmarks of the face in the related image, which is necessary to train [InstantID-based models](https://instantid.github.io/). If you don't need that, just ignore them.
|
| 77 |
+
3. `./face`: The directory including face files.
|
| 78 |
+
4. `*.jsonl`: Descriptions or texts. Ignore the file paths listed in the `.jsonl` file and use the line number instead to locate the corresponding image, face, and `.npy` files. For example, the 0th line in the `.jsonl` file corresponds to `0.png`, `0.npy`, and `./face/0.png`.
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
## Released FaceID Customization Models
|
| 82 |
+
|
| 83 |
+
We release two versions of trained InstantID models:
|
| 84 |
+
1. [InstantID-FaceID-70K](https://huggingface.co/Super-shuhe/InstantID-FaceID-70K): Model trained on our [FaceID-70K](https://huggingface.co/datasets/Super-shuhe/FaceID-70K) dataset.
|
| 85 |
+
2. [InstantID-FaceID-6M](https://huggingface.co/Super-shuhe/InstantID-FaceID-6M): Model trained on our [FaceID-6M](https://huggingface.co/datasets/Super-shuhe/FaceID-6M) dataset.
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
## Usage
|
| 89 |
+
|
| 90 |
+
For instructions on training and inference of FaceID customization models using our dataset, please visit our GitHub repository: https://github.com/ShuheSH/FaceID-6M
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
## Contact
|
| 94 |
+
|
| 95 |
+
If you have any issues or questions about this repo, feel free to contact [email protected]
|
| 96 |
+
|
| 97 |
+
```
|
| 98 |
+
@article{wang2025faceid,
|
| 99 |
+
title={FaceID-6M: A Large-Scale, Open-Source FaceID Customization Dataset},
|
| 100 |
+
author={Wang, Shuhe and Li, Xiaoya and Li, Jiwei and Wang, Guoyin and Sun, Xiaofei and Zhu, Bob and Qiu, Han and Yu, Mo and Shen, Shengjie and Hovy, Eduard},
|
| 101 |
+
journal={arXiv preprint arXiv:2503.07091},
|
| 102 |
+
year={2025}
|
| 103 |
+
}
|
| 104 |
+
```
|