
Dataset Preview
The full dataset viewer is not available (click to read why). Only showing a preview of the rows.
The dataset generation failed
Error code: DatasetGenerationError
Exception: TypeError
Message: Couldn't cast array of type timestamp[s] to null
Traceback: Traceback (most recent call last):
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 1870, in _prepare_split_single
writer.write_table(table)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/arrow_writer.py", line 622, in write_table
pa_table = table_cast(pa_table, self._schema)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 2292, in table_cast
return cast_table_to_schema(table, schema)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 2245, in cast_table_to_schema
arrays = [
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 2246, in <listcomp>
cast_array_to_feature(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 1795, in wrapper
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 1795, in <listcomp>
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 2005, in cast_array_to_feature
arrays = [
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 2006, in <listcomp>
_c(array.field(name) if name in array_fields else null_array, subfeature)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 1797, in wrapper
return func(array, *args, **kwargs)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 2102, in cast_array_to_feature
return array_cast(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 1797, in wrapper
return func(array, *args, **kwargs)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 1948, in array_cast
raise TypeError(f"Couldn't cast array of type {_short_str(array.type)} to {_short_str(pa_type)}")
TypeError: Couldn't cast array of type timestamp[s] to null
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/src/services/worker/src/worker/job_runners/config/parquet_and_info.py", line 1438, in compute_config_parquet_and_info_response
parquet_operations = convert_to_parquet(builder)
File "/src/services/worker/src/worker/job_runners/config/parquet_and_info.py", line 1050, in convert_to_parquet
builder.download_and_prepare(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 924, in download_and_prepare
self._download_and_prepare(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 1000, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 1741, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 1897, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.exceptions.DatasetGenerationError: An error occurred while generating the datasetNeed help to make the dataset viewer work? Make sure to review how to configure the dataset viewer, and open a discussion for direct support.
url
string | repository_url
string | labels_url
string | comments_url
string | events_url
string | html_url
string | id
int64 | node_id
string | number
int64 | title
string | user
dict | labels
list | state
string | locked
bool | assignee
null | assignees
sequence | milestone
null | comments
int64 | created_at
timestamp[us] | updated_at
timestamp[us] | closed_at
null | author_association
string | sub_issues_summary
dict | active_lock_reason
null | draft
bool | pull_request
dict | body
string | closed_by
null | reactions
dict | timeline_url
string | performed_via_github_app
null | state_reason
null |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/7426 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7426/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7426/comments | https://api.github.com/repos/huggingface/datasets/issues/7426/events | https://github.com/huggingface/datasets/pull/7426 | 2,883,754,507 | PR_kwDODunzps6Mwe6B | 7,426 | fix: None default with bool type on load creates typing error | {
"login": "stephantul",
"id": 8882233,
"node_id": "MDQ6VXNlcjg4ODIyMzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/8882233?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stephantul",
"html_url": "https://github.com/stephantul",
"followers_url": "https://api.github.com/users/stephantul/followers",
"following_url": "https://api.github.com/users/stephantul/following{/other_user}",
"gists_url": "https://api.github.com/users/stephantul/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stephantul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stephantul/subscriptions",
"organizations_url": "https://api.github.com/users/stephantul/orgs",
"repos_url": "https://api.github.com/users/stephantul/repos",
"events_url": "https://api.github.com/users/stephantul/events{/privacy}",
"received_events_url": "https://api.github.com/users/stephantul/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 2025-02-27T08:11:36 | 2025-02-27T08:11:36 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7426",
"html_url": "https://github.com/huggingface/datasets/pull/7426",
"diff_url": "https://github.com/huggingface/datasets/pull/7426.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7426.patch",
"merged_at": null
} | Hello!
Pyright flags any use of `load_dataset` as an error, because the default for `trust_remote_code` is `None`, but the function is typed as `bool`, not `Optional[bool]`. I changed the type and docstrings to reflect this, but no other code was touched.
| null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7426/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7426/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7425 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7425/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7425/comments | https://api.github.com/repos/huggingface/datasets/issues/7425/events | https://github.com/huggingface/datasets/issues/7425 | 2,883,684,686 | I_kwDODunzps6r4YlO | 7,425 | load_dataset("livecodebench/code_generation_lite", version_tag="release_v2") TypeError: 'NoneType' object is not callable | {
"login": "dshwei",
"id": 42167236,
"node_id": "MDQ6VXNlcjQyMTY3MjM2",
"avatar_url": "https://avatars.githubusercontent.com/u/42167236?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dshwei",
"html_url": "https://github.com/dshwei",
"followers_url": "https://api.github.com/users/dshwei/followers",
"following_url": "https://api.github.com/users/dshwei/following{/other_user}",
"gists_url": "https://api.github.com/users/dshwei/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dshwei/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dshwei/subscriptions",
"organizations_url": "https://api.github.com/users/dshwei/orgs",
"repos_url": "https://api.github.com/users/dshwei/repos",
"events_url": "https://api.github.com/users/dshwei/events{/privacy}",
"received_events_url": "https://api.github.com/users/dshwei/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 2025-02-27T07:36:02 | 2025-02-27T07:36:02 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
from datasets import load_dataset
lcb_codegen = load_dataset("livecodebench/code_generation_lite", version_tag="release_v2")
or
configs = get_dataset_config_names("livecodebench/code_generation_lite", trust_remote_code=True)
both error:
Traceback (most recent call last):
File "", line 1, in
File "/workspace/miniconda/envs/grpo/lib/python3.10/site-packages/datasets/load.py", line 2131, in load_dataset
builder_instance = load_dataset_builder(
File "/workspace/miniconda/envs/grpo/lib/python3.10/site-packages/datasets/load.py", line 1888, in load_dataset_builder
builder_instance: DatasetBuilder = builder_cls(
TypeError: 'NoneType' object is not callable
### Steps to reproduce the bug
from datasets import get_dataset_config_names
configs = get_dataset_config_names("livecodebench/code_generation_lite", trust_remote_code=True)
OR
lcb_codegen = load_dataset("livecodebench/code_generation_lite", version_tag="release_v2")
### Expected behavior
load datasets livecodebench/code_generation_lite
### Environment info
import datasets
version '3.3.2' | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7425/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7425/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7424 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7424/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7424/comments | https://api.github.com/repos/huggingface/datasets/issues/7424/events | https://github.com/huggingface/datasets/pull/7424 | 2,882,663,621 | PR_kwDODunzps6Ms1Qx | 7,424 | Faster folder based builder + parquet support + allow repeated media | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | open | false | null | [] | null | 1 | 2025-02-26T19:55:18 | 2025-02-27T17:41:05 | null | MEMBER | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7424",
"html_url": "https://github.com/huggingface/datasets/pull/7424",
"diff_url": "https://github.com/huggingface/datasets/pull/7424.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7424.patch",
"merged_at": null
} | This will be useful for LeRobotDataset (robotics datasets for [lerobot](https://github.com/huggingface/lerobot) based on videos)
Impacted builders:
- ImageFolder
- AudioFolder
- VideoFolder
Improvements:
- faster to stream (got a 5x speed up on an image dataset)
- improved RAM usage
- support for metadata.parquet
- allow to link to an image/audio/video multiple times
- support for pyarrow filters (mostly efficient for parquet)
Changes:
- the builders iterate on the metadata files instead of the media files
- the builders iterate on chunks of metadata instead of loading them in RAM completely
- added the `filters` argument to pass to `load_dataset`
- either as an [Expression](https://arrow.apache.org/docs/python/generated/pyarrow.dataset.Expression.html)
- or as tuples like `filters=[('event_name', '=', 'SomeEvent')]`
- small breaking change: you can't add labels to a dataset with`drop_labels=False` if it has a metadata file
TODO:
- [x] docs
- [ ] fix tests | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7424/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7424/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7423 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7423/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7423/comments | https://api.github.com/repos/huggingface/datasets/issues/7423/events | https://github.com/huggingface/datasets/issues/7423 | 2,879,271,409 | I_kwDODunzps6rnjHx | 7,423 | Row indexing a dataset with numpy integers | {
"login": "DavidRConnell",
"id": 35470740,
"node_id": "MDQ6VXNlcjM1NDcwNzQw",
"avatar_url": "https://avatars.githubusercontent.com/u/35470740?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DavidRConnell",
"html_url": "https://github.com/DavidRConnell",
"followers_url": "https://api.github.com/users/DavidRConnell/followers",
"following_url": "https://api.github.com/users/DavidRConnell/following{/other_user}",
"gists_url": "https://api.github.com/users/DavidRConnell/gists{/gist_id}",
"starred_url": "https://api.github.com/users/DavidRConnell/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/DavidRConnell/subscriptions",
"organizations_url": "https://api.github.com/users/DavidRConnell/orgs",
"repos_url": "https://api.github.com/users/DavidRConnell/repos",
"events_url": "https://api.github.com/users/DavidRConnell/events{/privacy}",
"received_events_url": "https://api.github.com/users/DavidRConnell/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | 0 | 2025-02-25T18:44:45 | 2025-02-25T18:44:45 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
Allow indexing datasets with a scalar numpy integer type.
### Motivation
Indexing a dataset with a scalar numpy.int* object raises a TypeError. This is due to the test in `datasets/formatting/formatting.py:key_to_query_type`
``` python
def key_to_query_type(key: Union[int, slice, range, str, Iterable]) -> str:
if isinstance(key, int):
return "row"
elif isinstance(key, str):
return "column"
elif isinstance(key, (slice, range, Iterable)):
return "batch"
_raise_bad_key_type(key)
```
In the row case, it checks if key is an int, which returns false when key is integer like but not a builtin python integer type. This is counterintuitive because a numpy array of np.int64s can be used for the batch case.
For example:
``` python
import numpy as np
import datasets
dataset = datasets.Dataset.from_dict({"a": [1, 2, 3, 4], "b": [5, 6, 7, 8]})
# Regular indexing
dataset[0]
dataset[:2]
# Indexing with numpy data types (expect same results)
idx = np.asarray([0, 1])
dataset[idx] # Succeeds when using an array of np.int64 values
dataset[idx[0]] # Fails with TypeError when using scalar np.int64
```
For the user, this can be solved by wrapping `idx[0]` in `int` but the test could also be changed in `key_to_query_type` to accept a less strict definition of int.
``` diff
+import numbers
+
def key_to_query_type(key: Union[int, slice, range, str, Iterable]) -> str:
+ if isinstance(key, numbers.Integral):
- if isinstance(key, int):
return "row"
elif isinstance(key, str):
return "column"
elif isinstance(key, (slice, range, Iterable)):
return "batch"
_raise_bad_key_type(key)
```
Looking at how others do it, pandas has an `is_integer` definition that it checks which uses `is_integer_object` defined in `pandas/_libs/utils.pxd`:
``` cython
cdef inline bint is_integer_object(object obj) noexcept:
"""
Cython equivalent of
`isinstance(val, (int, np.integer)) and not isinstance(val, (bool, np.timedelta64))`
Parameters
----------
val : object
Returns
-------
is_integer : bool
Notes
-----
This counts np.timedelta64 objects as integers.
"""
return (not PyBool_Check(obj) and isinstance(obj, (int, cnp.integer))
and not is_timedelta64_object(obj))
```
This would be less flexible as it explicitly checks for numpy integer, but worth noting that they had the need to ensure the key is not a bool.
### Your contribution
I can submit a pull request with the above changes after checking that indexing succeeds with the numpy integer type. Or if there is a different integer check that would be preferred I could add that.
If there is a reason not to want this behavior that is fine too.
| null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7423/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7423/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7421 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7421/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7421/comments | https://api.github.com/repos/huggingface/datasets/issues/7421/events | https://github.com/huggingface/datasets/issues/7421 | 2,878,369,052 | I_kwDODunzps6rkG0c | 7,421 | DVC integration broken | {
"login": "maxstrobel",
"id": 34747372,
"node_id": "MDQ6VXNlcjM0NzQ3Mzcy",
"avatar_url": "https://avatars.githubusercontent.com/u/34747372?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/maxstrobel",
"html_url": "https://github.com/maxstrobel",
"followers_url": "https://api.github.com/users/maxstrobel/followers",
"following_url": "https://api.github.com/users/maxstrobel/following{/other_user}",
"gists_url": "https://api.github.com/users/maxstrobel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/maxstrobel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/maxstrobel/subscriptions",
"organizations_url": "https://api.github.com/users/maxstrobel/orgs",
"repos_url": "https://api.github.com/users/maxstrobel/repos",
"events_url": "https://api.github.com/users/maxstrobel/events{/privacy}",
"received_events_url": "https://api.github.com/users/maxstrobel/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 2025-02-25T13:14:31 | 2025-02-25T13:14:31 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
The DVC integration seems to be broken.
Followed this guide: https://dvc.org/doc/user-guide/integrations/huggingface
### Steps to reproduce the bug
#### Script to reproduce
~~~python
from datasets import load_dataset
dataset = load_dataset(
"csv",
data_files="dvc://workshop/satellite-data/jan_train.csv",
storage_options={"url": "https://github.com/iterative/dataset-registry.git"},
)
print(dataset)
~~~
#### Error log
~~~
Traceback (most recent call last):
File "C:\tmp\test\load.py", line 3, in <module>
dataset = load_dataset(
^^^^^^^^^^^^^
File "C:\tmp\test\.venv\Lib\site-packages\datasets\load.py", line 2151, in load_dataset
builder_instance.download_and_prepare(
File "C:\tmp\test\.venv\Lib\site-packages\datasets\builder.py", line 808, in download_and_prepare
fs, output_dir = url_to_fs(output_dir, **(storage_options or {}))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: url_to_fs() got multiple values for argument 'url'
~~~
### Expected behavior
Integration would work and the indicated file is downloaded and opened.
### Environment info
#### Python version
~~~
python --version
Python 3.11.10
~~~
#### Venv (pip install datasets dvc):
~~~
Package Version
---------------------- -----------
aiohappyeyeballs 2.4.6
aiohttp 3.11.13
aiohttp-retry 2.9.1
aiosignal 1.3.2
amqp 5.3.1
annotated-types 0.7.0
antlr4-python3-runtime 4.9.3
appdirs 1.4.4
asyncssh 2.20.0
atpublic 5.1
attrs 25.1.0
billiard 4.2.1
celery 5.4.0
certifi 2025.1.31
cffi 1.17.1
charset-normalizer 3.4.1
click 8.1.8
click-didyoumean 0.3.1
click-plugins 1.1.1
click-repl 0.3.0
colorama 0.4.6
configobj 5.0.9
cryptography 44.0.1
datasets 3.3.2
dictdiffer 0.9.0
dill 0.3.8
diskcache 5.6.3
distro 1.9.0
dpath 2.2.0
dulwich 0.22.7
dvc 3.59.1
dvc-data 3.16.9
dvc-http 2.32.0
dvc-objects 5.1.0
dvc-render 1.0.2
dvc-studio-client 0.21.0
dvc-task 0.40.2
entrypoints 0.4
filelock 3.17.0
flatten-dict 0.4.2
flufl-lock 8.1.0
frozenlist 1.5.0
fsspec 2024.12.0
funcy 2.0
gitdb 4.0.12
gitpython 3.1.44
grandalf 0.8
gto 1.7.2
huggingface-hub 0.29.1
hydra-core 1.3.2
idna 3.10
iterative-telemetry 0.0.10
kombu 5.4.2
markdown-it-py 3.0.0
mdurl 0.1.2
multidict 6.1.0
multiprocess 0.70.16
networkx 3.4.2
numpy 2.2.3
omegaconf 2.3.0
orjson 3.10.15
packaging 24.2
pandas 2.2.3
pathspec 0.12.1
platformdirs 4.3.6
prompt-toolkit 3.0.50
propcache 0.3.0
psutil 7.0.0
pyarrow 19.0.1
pycparser 2.22
pydantic 2.10.6
pydantic-core 2.27.2
pydot 3.0.4
pygit2 1.17.0
pygments 2.19.1
pygtrie 2.5.0
pyparsing 3.2.1
python-dateutil 2.9.0.post0
pytz 2025.1
pywin32 308
pyyaml 6.0.2
requests 2.32.3
rich 13.9.4
ruamel-yaml 0.18.10
ruamel-yaml-clib 0.2.12
scmrepo 3.3.10
semver 3.0.4
setuptools 75.8.0
shellingham 1.5.4
shortuuid 1.0.13
shtab 1.7.1
six 1.17.0
smmap 5.0.2
sqltrie 0.11.2
tabulate 0.9.0
tomlkit 0.13.2
tqdm 4.67.1
typer 0.15.1
typing-extensions 4.12.2
tzdata 2025.1
urllib3 2.3.0
vine 5.1.0
voluptuous 0.15.2
wcwidth 0.2.13
xxhash 3.5.0
yarl 1.18.3
zc-lockfile 3.0.post1
~~~ | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7421/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7421/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7420 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7420/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7420/comments | https://api.github.com/repos/huggingface/datasets/issues/7420/events | https://github.com/huggingface/datasets/issues/7420 | 2,876,281,928 | I_kwDODunzps6rcJRI | 7,420 | better correspondence between cached and saved datasets created using from_generator | {
"login": "vttrifonov",
"id": 12157034,
"node_id": "MDQ6VXNlcjEyMTU3MDM0",
"avatar_url": "https://avatars.githubusercontent.com/u/12157034?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vttrifonov",
"html_url": "https://github.com/vttrifonov",
"followers_url": "https://api.github.com/users/vttrifonov/followers",
"following_url": "https://api.github.com/users/vttrifonov/following{/other_user}",
"gists_url": "https://api.github.com/users/vttrifonov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vttrifonov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vttrifonov/subscriptions",
"organizations_url": "https://api.github.com/users/vttrifonov/orgs",
"repos_url": "https://api.github.com/users/vttrifonov/repos",
"events_url": "https://api.github.com/users/vttrifonov/events{/privacy}",
"received_events_url": "https://api.github.com/users/vttrifonov/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | 0 | 2025-02-24T22:14:37 | 2025-02-26T03:10:22 | null | CONTRIBUTOR | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
At the moment `.from_generator` can only create a dataset that lives in the cache. The cached dataset cannot be loaded with `load_from_disk` because the cache folder is missing `state.json`. So the only way to convert this cached dataset to a regular is to use `save_to_disk` which needs to create a copy of the cached dataset. For large datasets this can end up wasting a lot of space. In my case the saving operation failed so I am stuck with a large cached dataset and no clear way to convert to a `Dataset` that I can use. The requested feature is to provide a way to be able to load a cached dataset using `.load_from_disk`. Alternatively `.from_generator` can create the dataset at a specified location so that it can be loaded from there with `.load_from_disk`.
### Motivation
I have the following workflow which has exposed some awkwardness about the Datasets saving/caching.
1. I created a cached dataset using `.from_generator` which was cached in a folder. This dataset is rather large (~600GB) with many shards.
2. I tried to save this dataset using `.save_to_disk` to another location so that I can use later as a `Dataset`. This essentially creates another copy (for a total of 1.2TB!) of what is already in the cache... In my case the saving operation keeps dying for some reason and I am stuck with a cached dataset and no copy.
3. Now I am trying to "save" the existing cached dataset but it is not clear how to access the cached files after `.from_generator` has finished e.g. from a different process. I should not be even looking at the cache but I really do not want to waste another 2hr to generate the set so that if fails agains (I already did this couple of times).
- I tried `.load_from_disk` but it does not work with cached files and complains that this is not a `Dataset` (!).
- I looked at `.from_file` which takes one file but the cached file has many (shards) so I am not sure how to make this work.
- I tried `.load_dataset` but this seems to either try to "download" a copy (of a file which is already in the local file system!) which I will then need to save or I need to use `streaming=False` to create an `IterableDataset `which then I need to convert (using the cache) to `Dataset` so that I can save it. With both options I will end up with 3 copies of the same dataset for a total of ~2TB! I am hoping here is another way to do this...
Maybe I am missing something here: I looked at docs and forums but no luck. I have a bunch of arrow files cached by `Dataset.from_generator` and no clean way to make them into a `Dataset` that I can use.
This all could be so much easer if `load_from_disk` can recognize the cached files and produce a `Dataset`: after the cache is created I would not have to "save" it again and I can just load it when I need. At the moment `load_from_disk` needs `state.json` which is lacking in the cache folder. So perhaps `.from_generator` could be made to "finalize" (e.g. create `state.json`) the dataset once it is done so that it can be loaded easily. Or provide `.from_generator` with a `save_to_dir` parameter in addition to `cache_dir` which can be used for the whole process including creating the `state.json` at the end.
As a proof of concept I just created `state.json` by hand and `load_from_disk` worked using the cache! So it seems to be the missing piece here.
### Your contribution
Time permitting I can look into `.from_generator` to see if adding `state.json` is feasible. | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7420/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7420/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7419 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7419/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7419/comments | https://api.github.com/repos/huggingface/datasets/issues/7419/events | https://github.com/huggingface/datasets/issues/7419 | 2,875,635,320 | I_kwDODunzps6rZrZ4 | 7,419 | Import order crashes script execution | {
"login": "DamienMatias",
"id": 23298479,
"node_id": "MDQ6VXNlcjIzMjk4NDc5",
"avatar_url": "https://avatars.githubusercontent.com/u/23298479?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DamienMatias",
"html_url": "https://github.com/DamienMatias",
"followers_url": "https://api.github.com/users/DamienMatias/followers",
"following_url": "https://api.github.com/users/DamienMatias/following{/other_user}",
"gists_url": "https://api.github.com/users/DamienMatias/gists{/gist_id}",
"starred_url": "https://api.github.com/users/DamienMatias/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/DamienMatias/subscriptions",
"organizations_url": "https://api.github.com/users/DamienMatias/orgs",
"repos_url": "https://api.github.com/users/DamienMatias/repos",
"events_url": "https://api.github.com/users/DamienMatias/events{/privacy}",
"received_events_url": "https://api.github.com/users/DamienMatias/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 2025-02-24T17:03:43 | 2025-02-24T17:03:43 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Hello,
I'm trying to convert an HF dataset into a TFRecord so I'm importing `tensorflow` and `datasets` to do so.
Depending in what order I'm importing those librairies, my code hangs forever and is unkillable (CTRL+C doesn't work, I need to kill my shell entirely).
Thank you for your help
🙏
### Steps to reproduce the bug
If you run the following script, this will hang forever :
```python
import tensorflow as tf
import datasets
dataset = datasets.load_dataset("imagenet-1k", split="validation", streaming=True)
print(next(iter(dataset)))
```
however running the following will work fine (I just changed the order of the imports) :
```python
import datasets
import tensorflow as tf
dataset = datasets.load_dataset("imagenet-1k", split="validation", streaming=True)
print(next(iter(dataset)))
```
### Expected behavior
I'm expecting the script to reach the end and my case print the content of the first item in the dataset
```
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=408x500 at 0x70C646A03110>, 'label': 91}
```
### Environment info
```
$ datasets-cli env
- `datasets` version: 3.3.2
- Platform: Linux-6.8.0-1017-aws-x86_64-with-glibc2.35
- Python version: 3.11.7
- `huggingface_hub` version: 0.29.1
- PyArrow version: 19.0.1
- Pandas version: 2.2.3
- `fsspec` version: 2024.12.0
```
I'm also using `tensorflow==2.18.0`. | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7419/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7419/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7418 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7418/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7418/comments | https://api.github.com/repos/huggingface/datasets/issues/7418/events | https://github.com/huggingface/datasets/issues/7418 | 2,868,701,471 | I_kwDODunzps6q_Okf | 7,418 | pyarrow.lib.arrowinvalid: cannot mix list and non-list, non-null values with map function | {
"login": "alexxchen",
"id": 15705569,
"node_id": "MDQ6VXNlcjE1NzA1NTY5",
"avatar_url": "https://avatars.githubusercontent.com/u/15705569?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alexxchen",
"html_url": "https://github.com/alexxchen",
"followers_url": "https://api.github.com/users/alexxchen/followers",
"following_url": "https://api.github.com/users/alexxchen/following{/other_user}",
"gists_url": "https://api.github.com/users/alexxchen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alexxchen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alexxchen/subscriptions",
"organizations_url": "https://api.github.com/users/alexxchen/orgs",
"repos_url": "https://api.github.com/users/alexxchen/repos",
"events_url": "https://api.github.com/users/alexxchen/events{/privacy}",
"received_events_url": "https://api.github.com/users/alexxchen/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | open | false | null | [] | null | 4 | 2025-02-21T10:58:06 | 2025-02-25T15:26:46 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Encounter pyarrow.lib.arrowinvalid error with map function in some example when loading the dataset
### Steps to reproduce the bug
```
from datasets import load_dataset
from PIL import Image, PngImagePlugin
dataset = load_dataset("leonardPKU/GEOQA_R1V_Train_8K")
system_prompt="You are a helpful AI Assistant"
def make_conversation(example):
prompt = []
prompt.append({"role": "system", "content": system_prompt})
prompt.append(
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": example["problem"]},
]
}
)
return {"prompt": prompt}
def check_data_types(example):
for key, value in example.items():
if key == 'image':
if not isinstance(value, PngImagePlugin.PngImageFile):
print(value)
if key == "problem" or key == "solution":
if not isinstance(value, str):
print(value)
return example
dataset = dataset.map(check_data_types)
dataset = dataset.map(make_conversation)
```
### Expected behavior
Successfully process the dataset with map
### Environment info
datasets==3.3.1 | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7418/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7418/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7417 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7417/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7417/comments | https://api.github.com/repos/huggingface/datasets/issues/7417/events | https://github.com/huggingface/datasets/pull/7417 | 2,866,868,922 | PR_kwDODunzps6L78k3 | 7,417 | set dev version | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | 2025-02-20T17:45:29 | 2025-02-20T17:47:50 | null | MEMBER | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7417",
"html_url": "https://github.com/huggingface/datasets/pull/7417",
"diff_url": "https://github.com/huggingface/datasets/pull/7417.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7417.patch",
"merged_at": "2025-02-20T17:45:36"
} | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7417/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7417/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7416 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7416/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7416/comments | https://api.github.com/repos/huggingface/datasets/issues/7416/events | https://github.com/huggingface/datasets/pull/7416 | 2,866,862,143 | PR_kwDODunzps6L77G2 | 7,416 | Release: 3.3.2 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | 2025-02-20T17:42:11 | 2025-02-20T17:44:35 | null | MEMBER | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7416",
"html_url": "https://github.com/huggingface/datasets/pull/7416",
"diff_url": "https://github.com/huggingface/datasets/pull/7416.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7416.patch",
"merged_at": "2025-02-20T17:43:28"
} | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7416/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7416/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7415 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7415/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7415/comments | https://api.github.com/repos/huggingface/datasets/issues/7415/events | https://github.com/huggingface/datasets/issues/7415 | 2,865,774,546 | I_kwDODunzps6q0D_S | 7,415 | Shard Dataset at specific indices | {
"login": "nikonikolov",
"id": 11044035,
"node_id": "MDQ6VXNlcjExMDQ0MDM1",
"avatar_url": "https://avatars.githubusercontent.com/u/11044035?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nikonikolov",
"html_url": "https://github.com/nikonikolov",
"followers_url": "https://api.github.com/users/nikonikolov/followers",
"following_url": "https://api.github.com/users/nikonikolov/following{/other_user}",
"gists_url": "https://api.github.com/users/nikonikolov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nikonikolov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nikonikolov/subscriptions",
"organizations_url": "https://api.github.com/users/nikonikolov/orgs",
"repos_url": "https://api.github.com/users/nikonikolov/repos",
"events_url": "https://api.github.com/users/nikonikolov/events{/privacy}",
"received_events_url": "https://api.github.com/users/nikonikolov/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | open | false | null | [] | null | 3 | 2025-02-20T10:43:10 | 2025-02-24T11:06:45 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | I have a dataset of sequences, where each example in the sequence is a separate row in the dataset (similar to LeRobotDataset). When running `Dataset.save_to_disk` how can I provide indices where it's possible to shard the dataset such that no episode spans more than 1 shard. Consequently, when I run `Dataset.load_from_disk`, how can I load just a subset of the shards to save memory and time on different ranks?
I guess an alternative to this would be, given a loaded `Dataset`, how can I run `Dataset.shard` such that sharding doesn't split any episode across shards? | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7415/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7415/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7414 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7414/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7414/comments | https://api.github.com/repos/huggingface/datasets/issues/7414/events | https://github.com/huggingface/datasets/pull/7414 | 2,863,798,756 | PR_kwDODunzps6LxjsH | 7,414 | Gracefully cancel async tasks | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | 2025-02-19T16:10:58 | 2025-02-20T14:12:26 | null | MEMBER | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7414",
"html_url": "https://github.com/huggingface/datasets/pull/7414",
"diff_url": "https://github.com/huggingface/datasets/pull/7414.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7414.patch",
"merged_at": "2025-02-20T14:12:23"
} | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7414/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7414/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7413 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7413/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7413/comments | https://api.github.com/repos/huggingface/datasets/issues/7413/events | https://github.com/huggingface/datasets/issues/7413 | 2,860,947,582 | I_kwDODunzps6qhph- | 7,413 | Documentation on multiple media files of the same type with WebDataset | {
"login": "DCNemesis",
"id": 3616964,
"node_id": "MDQ6VXNlcjM2MTY5NjQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3616964?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DCNemesis",
"html_url": "https://github.com/DCNemesis",
"followers_url": "https://api.github.com/users/DCNemesis/followers",
"following_url": "https://api.github.com/users/DCNemesis/following{/other_user}",
"gists_url": "https://api.github.com/users/DCNemesis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/DCNemesis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/DCNemesis/subscriptions",
"organizations_url": "https://api.github.com/users/DCNemesis/orgs",
"repos_url": "https://api.github.com/users/DCNemesis/repos",
"events_url": "https://api.github.com/users/DCNemesis/events{/privacy}",
"received_events_url": "https://api.github.com/users/DCNemesis/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | open | false | null | [] | null | 1 | 2025-02-18T16:13:20 | 2025-02-20T14:17:54 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | The [current documentation](https://huggingface.co/docs/datasets/en/video_dataset) on a creating a video dataset includes only examples with one media file and one json. It would be useful to have examples where multiple files of the same type are included. For example, in a sign language dataset, you may have a base video and a video annotation of the extracted pose. According to the WebDataset documentation, this should be able to be done with period separated filenames. For example:
```e39871fd9fd74f55.base.mp4
e39871fd9fd74f55.pose.mp4
e39871fd9fd74f55.json
f18b91585c4d3f3e.base.mp4
f18b91585c4d3f3e.pose.mp4
f18b91585c4d3f3e.json
...
```
If you can confirm that this method of including multiple media files works with huggingface datasets and include an example in the documentation, I'd appreciate it. | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7413/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7413/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7412 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7412/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7412/comments | https://api.github.com/repos/huggingface/datasets/issues/7412/events | https://github.com/huggingface/datasets/issues/7412 | 2,859,433,710 | I_kwDODunzps6qb37u | 7,412 | Index Error Invalid Ket is out of bounds for size 0 for code-search-net/code_search_net dataset | {
"login": "harshakhmk",
"id": 56113657,
"node_id": "MDQ6VXNlcjU2MTEzNjU3",
"avatar_url": "https://avatars.githubusercontent.com/u/56113657?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/harshakhmk",
"html_url": "https://github.com/harshakhmk",
"followers_url": "https://api.github.com/users/harshakhmk/followers",
"following_url": "https://api.github.com/users/harshakhmk/following{/other_user}",
"gists_url": "https://api.github.com/users/harshakhmk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/harshakhmk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/harshakhmk/subscriptions",
"organizations_url": "https://api.github.com/users/harshakhmk/orgs",
"repos_url": "https://api.github.com/users/harshakhmk/repos",
"events_url": "https://api.github.com/users/harshakhmk/events{/privacy}",
"received_events_url": "https://api.github.com/users/harshakhmk/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 2025-02-18T05:58:33 | 2025-02-18T06:42:07 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
I am trying to do model pruning on sentence-transformers/all-mini-L6-v2 for the code-search-net/code_search_net dataset using INCTrainer class
However I am getting below error
```
raise IndexError(f"Invalid Key: {key is our of bounds for size {size}")
IndexError: Invalid key: 1840208 is out of bounds for size 0
```
### Steps to reproduce the bug
Model pruning on the above dataset using the below guide
https://huggingface.co/docs/optimum/en/intel/neural_compressor/optimization#pruning
### Expected behavior
The modsl should be successfully pruned
### Environment info
Torch version: 2.4.1
Python version: 3.8.10 | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7412/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7412/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7411 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7411/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7411/comments | https://api.github.com/repos/huggingface/datasets/issues/7411/events | https://github.com/huggingface/datasets/pull/7411 | 2,858,993,390 | PR_kwDODunzps6LhV0Z | 7,411 | Attempt to fix multiprocessing hang by closing and joining the pool before termination | {
"login": "dakinggg",
"id": 43149077,
"node_id": "MDQ6VXNlcjQzMTQ5MDc3",
"avatar_url": "https://avatars.githubusercontent.com/u/43149077?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dakinggg",
"html_url": "https://github.com/dakinggg",
"followers_url": "https://api.github.com/users/dakinggg/followers",
"following_url": "https://api.github.com/users/dakinggg/following{/other_user}",
"gists_url": "https://api.github.com/users/dakinggg/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dakinggg/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dakinggg/subscriptions",
"organizations_url": "https://api.github.com/users/dakinggg/orgs",
"repos_url": "https://api.github.com/users/dakinggg/repos",
"events_url": "https://api.github.com/users/dakinggg/events{/privacy}",
"received_events_url": "https://api.github.com/users/dakinggg/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | closed | false | null | [] | null | 3 | 2025-02-17T23:58:03 | 2025-02-19T21:11:24 | null | CONTRIBUTOR | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7411",
"html_url": "https://github.com/huggingface/datasets/pull/7411",
"diff_url": "https://github.com/huggingface/datasets/pull/7411.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7411.patch",
"merged_at": "2025-02-19T13:40:32"
} | https://github.com/huggingface/datasets/issues/6393 has plagued me on and off for a very long time. I have had various workarounds (one time combining two filter calls into one filter call removed the issue, another time making rank 0 go first resolved a cache race condition, one time i think upgrading the version of something resolved it). I don't know hf datasets well enough to fully understand the root cause, but I _think_ this PR fixes it.
Evidence: I have an LLM Foundry training yaml/script (datasets version 3.2.0) that results in a hang ~1/10 times (for a baseline for this testing, it was 2/36 runs that hung). I also reran with the latest datasets version (3.3.1) and got 4/36 hung. Installing datasets from this PR, I was able to successful run the script 144 times without a hang occurring. Assuming the base probability is 1/10, this should be more than enough times to have confidence it works.
After adding some logging, I could see that the code hung during the __exit__ of the mp pool context manager, after all shards had been processed, and the tqdm context manager had exited.
My best explanation: When multiprocessing pool __exit__ is called, it calls pool.terminate, which forcefully exits all the processes (and calls code related to this that I haven't looked at closely). I'm guessing this forceful termination has a bad interaction with some multithreading/multiprocessing that hf datasets does. If we instead call pool.close and pool.join before the pool.terminate happens, perhaps whatever that bad interaction is is able to complete gracefully, and then terminate call proceeds without issue.
If this PR seems good to you, I'd be very appreciative if you were able to do a patch release including it. Thank you!
@lhoestq | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7411/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7411/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7410 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7410/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7410/comments | https://api.github.com/repos/huggingface/datasets/issues/7410/events | https://github.com/huggingface/datasets/pull/7410 | 2,858,085,707 | PR_kwDODunzps6LeQBF | 7,410 | Set dev version | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | 2025-02-17T14:54:39 | 2025-02-17T14:56:58 | null | MEMBER | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7410",
"html_url": "https://github.com/huggingface/datasets/pull/7410",
"diff_url": "https://github.com/huggingface/datasets/pull/7410.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7410.patch",
"merged_at": "2025-02-17T14:54:56"
} | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7410/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7410/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7409 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7409/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7409/comments | https://api.github.com/repos/huggingface/datasets/issues/7409/events | https://github.com/huggingface/datasets/pull/7409 | 2,858,079,508 | PR_kwDODunzps6LeOpY | 7,409 | Release: 3.3.1 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | 2025-02-17T14:52:12 | 2025-02-17T14:54:32 | null | MEMBER | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7409",
"html_url": "https://github.com/huggingface/datasets/pull/7409",
"diff_url": "https://github.com/huggingface/datasets/pull/7409.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7409.patch",
"merged_at": "2025-02-17T14:53:13"
} | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7409/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7409/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7408 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7408/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7408/comments | https://api.github.com/repos/huggingface/datasets/issues/7408/events | https://github.com/huggingface/datasets/pull/7408 | 2,858,012,313 | PR_kwDODunzps6Ld_-m | 7,408 | Fix filter speed regression | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | 2025-02-17T14:25:32 | 2025-02-17T14:28:48 | null | MEMBER | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7408",
"html_url": "https://github.com/huggingface/datasets/pull/7408",
"diff_url": "https://github.com/huggingface/datasets/pull/7408.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7408.patch",
"merged_at": "2025-02-17T14:28:46"
} | close https://github.com/huggingface/datasets/issues/7404 | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7408/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7408/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7407 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7407/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7407/comments | https://api.github.com/repos/huggingface/datasets/issues/7407/events | https://github.com/huggingface/datasets/pull/7407 | 2,856,517,442 | PR_kwDODunzps6LY7y5 | 7,407 | Update use_with_pandas.mdx: to_pandas() correction in last section | {
"login": "ibarrien",
"id": 7552335,
"node_id": "MDQ6VXNlcjc1NTIzMzU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7552335?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ibarrien",
"html_url": "https://github.com/ibarrien",
"followers_url": "https://api.github.com/users/ibarrien/followers",
"following_url": "https://api.github.com/users/ibarrien/following{/other_user}",
"gists_url": "https://api.github.com/users/ibarrien/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ibarrien/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ibarrien/subscriptions",
"organizations_url": "https://api.github.com/users/ibarrien/orgs",
"repos_url": "https://api.github.com/users/ibarrien/repos",
"events_url": "https://api.github.com/users/ibarrien/events{/privacy}",
"received_events_url": "https://api.github.com/users/ibarrien/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | 2025-02-17T01:53:31 | 2025-02-20T17:28:04 | null | CONTRIBUTOR | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7407",
"html_url": "https://github.com/huggingface/datasets/pull/7407",
"diff_url": "https://github.com/huggingface/datasets/pull/7407.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7407.patch",
"merged_at": "2025-02-20T17:28:04"
} | last section ``to_pandas()" | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7407/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7407/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7406 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7406/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7406/comments | https://api.github.com/repos/huggingface/datasets/issues/7406/events | https://github.com/huggingface/datasets/issues/7406 | 2,856,441,206 | I_kwDODunzps6qQdV2 | 7,406 | Adding Core Maintainer List to CONTRIBUTING.md | {
"login": "jp1924",
"id": 93233241,
"node_id": "U_kgDOBY6gWQ",
"avatar_url": "https://avatars.githubusercontent.com/u/93233241?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jp1924",
"html_url": "https://github.com/jp1924",
"followers_url": "https://api.github.com/users/jp1924/followers",
"following_url": "https://api.github.com/users/jp1924/following{/other_user}",
"gists_url": "https://api.github.com/users/jp1924/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jp1924/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jp1924/subscriptions",
"organizations_url": "https://api.github.com/users/jp1924/orgs",
"repos_url": "https://api.github.com/users/jp1924/repos",
"events_url": "https://api.github.com/users/jp1924/events{/privacy}",
"received_events_url": "https://api.github.com/users/jp1924/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | 3 | 2025-02-17T00:32:40 | 2025-02-19T01:28:38 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
I propose adding a core maintainer list to the `CONTRIBUTING.md` file.
### Motivation
The Transformers and Liger-Kernel projects maintain lists of core maintainers for each module.
However, the Datasets project doesn't have such a list.
### Your contribution
I have nothing to add here. | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7406/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7406/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7405 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7405/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7405/comments | https://api.github.com/repos/huggingface/datasets/issues/7405/events | https://github.com/huggingface/datasets/issues/7405 | 2,856,372,814 | I_kwDODunzps6qQMpO | 7,405 | Lazy loading of environment variables | {
"login": "nikvaessen",
"id": 7225987,
"node_id": "MDQ6VXNlcjcyMjU5ODc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7225987?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nikvaessen",
"html_url": "https://github.com/nikvaessen",
"followers_url": "https://api.github.com/users/nikvaessen/followers",
"following_url": "https://api.github.com/users/nikvaessen/following{/other_user}",
"gists_url": "https://api.github.com/users/nikvaessen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nikvaessen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nikvaessen/subscriptions",
"organizations_url": "https://api.github.com/users/nikvaessen/orgs",
"repos_url": "https://api.github.com/users/nikvaessen/repos",
"events_url": "https://api.github.com/users/nikvaessen/events{/privacy}",
"received_events_url": "https://api.github.com/users/nikvaessen/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | open | false | null | [] | null | 1 | 2025-02-16T22:31:41 | 2025-02-17T15:17:18 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Loading a `.env` file after an `import datasets` call does not correctly use the environment variables.
This is due the fact that environment variables are read at import time:
https://github.com/huggingface/datasets/blob/de062f0552a810c52077543c1169c38c1f0c53fc/src/datasets/config.py#L155C1-L155C80
### Steps to reproduce the bug
```bash
# make tmp dir
mkdir -p /tmp/debug-env
# make .env file
echo HF_HOME=/tmp/debug-env/data > /tmp/debug-env/.env
# first load dotenv, downloads to /tmp/debug-env/data
uv run --with datasets,python-dotenv python3 -c \
'import dotenv; dotenv.load_dotenv("/tmp/debug-env/.env"); import datasets; datasets.load_dataset("Anthropic/hh-rlhf")'
# first import datasets, downloads to `~/.cache/huggingface`
uv run --with datasets,python-dotenv python3 -c \
'import datasets; import dotenv; dotenv.load_dotenv("/tmp/debug-env/.env"); datasets.load_dataset("Anthropic/hh-rlhf")'
```
### Expected behavior
I expect that setting environment variables with something like this:
```python3
if __name__ == "__main__":
load_dotenv()
main()
```
works correctly.
### Environment info
"datasets>=3.3.0",
| null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7405/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7405/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7404 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7404/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7404/comments | https://api.github.com/repos/huggingface/datasets/issues/7404/events | https://github.com/huggingface/datasets/issues/7404 | 2,856,366,207 | I_kwDODunzps6qQLB_ | 7,404 | Performance regression in `dataset.filter` | {
"login": "ttim",
"id": 82200,
"node_id": "MDQ6VXNlcjgyMjAw",
"avatar_url": "https://avatars.githubusercontent.com/u/82200?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ttim",
"html_url": "https://github.com/ttim",
"followers_url": "https://api.github.com/users/ttim/followers",
"following_url": "https://api.github.com/users/ttim/following{/other_user}",
"gists_url": "https://api.github.com/users/ttim/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ttim/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ttim/subscriptions",
"organizations_url": "https://api.github.com/users/ttim/orgs",
"repos_url": "https://api.github.com/users/ttim/repos",
"events_url": "https://api.github.com/users/ttim/events{/privacy}",
"received_events_url": "https://api.github.com/users/ttim/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | closed | false | null | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
}
] | null | 3 | 2025-02-16T22:19:14 | 2025-02-17T17:46:06 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
We're filtering dataset of ~1M (small-ish) records. At some point in the code we do `dataset.filter`, before (including 3.2.0) it was taking couple of seconds, and now it takes 4 hours.
We use 16 threads/workers, and stack trace at them look as follows:
```
Traceback (most recent call last):
File "/python/lib/python3.12/site-packages/multiprocess/process.py", line 314, in _bootstrap
self.run()
File "/python/lib/python3.12/site-packages/multiprocess/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/python/lib/python3.12/site-packages/multiprocess/pool.py", line 125, in worker
result = (True, func(*args, **kwds))
^^^^^^^^^^^^^^^^^^^
File "/python/lib/python3.12/site-packages/datasets/utils/py_utils.py", line 678, in _write_generator_to_queue
for i, result in enumerate(func(**kwargs)):
File "/python/lib/python3.12/site-packages/datasets/arrow_dataset.py", line 3511, in _map_single
for i, batch in iter_outputs(shard_iterable):
File "/python/lib/python3.12/site-packages/datasets/arrow_dataset.py", line 3461, in iter_outputs
yield i, apply_function(example, i, offset=offset)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/python/lib/python3.12/site-packages/datasets/arrow_dataset.py", line 3390, in apply_function
processed_inputs = function(*fn_args, *additional_args, **fn_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/python/lib/python3.12/site-packages/datasets/arrow_dataset.py", line 6416, in get_indices_from_mask_function
indices_array = indices_mapping.column(0).take(indices_array)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "pyarrow/table.pxi", line 1079, in pyarrow.lib.ChunkedArray.take
File "/python/lib/python3.12/site-packages/pyarrow/compute.py", line 458, in take
def take(data, indices, *, boundscheck=True, memory_pool=None):
```
### Steps to reproduce the bug
1. Save dataset of 1M records in arrow
2. Filter it with 16 threads
3. Watch it take too long
### Expected behavior
Filtering done fast
### Environment info
datasets 3.3.0, python 3.12 | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7404/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7404/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7402 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7402/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7402/comments | https://api.github.com/repos/huggingface/datasets/issues/7402/events | https://github.com/huggingface/datasets/pull/7402 | 2,855,880,858 | PR_kwDODunzps6LW8G3 | 7,402 | Fix a typo in arrow_dataset.py | {
"login": "jingedawang",
"id": 7996256,
"node_id": "MDQ6VXNlcjc5OTYyNTY=",
"avatar_url": "https://avatars.githubusercontent.com/u/7996256?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jingedawang",
"html_url": "https://github.com/jingedawang",
"followers_url": "https://api.github.com/users/jingedawang/followers",
"following_url": "https://api.github.com/users/jingedawang/following{/other_user}",
"gists_url": "https://api.github.com/users/jingedawang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jingedawang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jingedawang/subscriptions",
"organizations_url": "https://api.github.com/users/jingedawang/orgs",
"repos_url": "https://api.github.com/users/jingedawang/repos",
"events_url": "https://api.github.com/users/jingedawang/events{/privacy}",
"received_events_url": "https://api.github.com/users/jingedawang/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | 2025-02-16T04:52:02 | 2025-02-20T17:29:28 | null | CONTRIBUTOR | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7402",
"html_url": "https://github.com/huggingface/datasets/pull/7402",
"diff_url": "https://github.com/huggingface/datasets/pull/7402.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7402.patch",
"merged_at": "2025-02-20T17:29:28"
} | "in the feature" should be "in the future" | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7402/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7402/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7401 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7401/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7401/comments | https://api.github.com/repos/huggingface/datasets/issues/7401/events | https://github.com/huggingface/datasets/pull/7401 | 2,853,260,869 | PR_kwDODunzps6LOMSo | 7,401 | set dev version | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | 2025-02-14T10:17:03 | 2025-02-14T10:19:20 | null | MEMBER | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7401",
"html_url": "https://github.com/huggingface/datasets/pull/7401",
"diff_url": "https://github.com/huggingface/datasets/pull/7401.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7401.patch",
"merged_at": "2025-02-14T10:17:13"
} | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7401/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7401/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7399 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7399/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7399/comments | https://api.github.com/repos/huggingface/datasets/issues/7399/events | https://github.com/huggingface/datasets/issues/7399 | 2,853,098,442 | I_kwDODunzps6qDtPK | 7,399 | Synchronize parameters for various datasets | {
"login": "grofte",
"id": 7976840,
"node_id": "MDQ6VXNlcjc5NzY4NDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/7976840?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/grofte",
"html_url": "https://github.com/grofte",
"followers_url": "https://api.github.com/users/grofte/followers",
"following_url": "https://api.github.com/users/grofte/following{/other_user}",
"gists_url": "https://api.github.com/users/grofte/gists{/gist_id}",
"starred_url": "https://api.github.com/users/grofte/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/grofte/subscriptions",
"organizations_url": "https://api.github.com/users/grofte/orgs",
"repos_url": "https://api.github.com/users/grofte/repos",
"events_url": "https://api.github.com/users/grofte/events{/privacy}",
"received_events_url": "https://api.github.com/users/grofte/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | open | false | null | [] | null | 2 | 2025-02-14T09:15:11 | 2025-02-19T11:50:29 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
[IterableDatasetDict](https://huggingface.co/docs/datasets/v3.2.0/en/package_reference/main_classes#datasets.IterableDatasetDict.map) map function is missing the `desc` parameter. You can see the equivalent map function for [Dataset here](https://huggingface.co/docs/datasets/v3.2.0/en/package_reference/main_classes#datasets.Dataset.map).
There might be other parameters missing - I haven't checked.
### Steps to reproduce the bug
from datasets import Dataset, IterableDataset, IterableDatasetDict
ds = IterableDatasetDict({"train": Dataset.from_dict({"a": range(6)}).to_iterable_dataset(num_shards=3),
"validate": Dataset.from_dict({"a": range(6)}).to_iterable_dataset(num_shards=3)})
for d in ds["train"]:
print(d)
ds = ds.map(lambda x: {k: v+1 for k, v in x.items()}, desc="increment")
for d in ds["train"]:
print(d)
### Expected behavior
The description parameter should be available for all datasets (or none).
### Environment info
- `datasets` version: 3.2.0
- Platform: Linux-6.1.85+-x86_64-with-glibc2.35
- Python version: 3.11.11
- `huggingface_hub` version: 0.28.1
- PyArrow version: 17.0.0
- Pandas version: 2.2.2
- `fsspec` version: 2024.9.0 | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7399/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7399/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7398 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7398/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7398/comments | https://api.github.com/repos/huggingface/datasets/issues/7398/events | https://github.com/huggingface/datasets/pull/7398 | 2,853,097,869 | PR_kwDODunzps6LNoDk | 7,398 | Release: 3.3.0 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | 2025-02-14T09:15:03 | 2025-02-14T09:57:39 | null | MEMBER | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7398",
"html_url": "https://github.com/huggingface/datasets/pull/7398",
"diff_url": "https://github.com/huggingface/datasets/pull/7398.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7398.patch",
"merged_at": "2025-02-14T09:57:37"
} | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7398/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7398/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7397 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7397/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7397/comments | https://api.github.com/repos/huggingface/datasets/issues/7397/events | https://github.com/huggingface/datasets/pull/7397 | 2,852,829,763 | PR_kwDODunzps6LMuQD | 7,397 | Kannada dataset(Conversations, Wikipedia etc) | {
"login": "Likhith2612",
"id": 146451281,
"node_id": "U_kgDOCLqrUQ",
"avatar_url": "https://avatars.githubusercontent.com/u/146451281?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Likhith2612",
"html_url": "https://github.com/Likhith2612",
"followers_url": "https://api.github.com/users/Likhith2612/followers",
"following_url": "https://api.github.com/users/Likhith2612/following{/other_user}",
"gists_url": "https://api.github.com/users/Likhith2612/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Likhith2612/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Likhith2612/subscriptions",
"organizations_url": "https://api.github.com/users/Likhith2612/orgs",
"repos_url": "https://api.github.com/users/Likhith2612/repos",
"events_url": "https://api.github.com/users/Likhith2612/events{/privacy}",
"received_events_url": "https://api.github.com/users/Likhith2612/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | 2025-02-14T06:53:03 | 2025-02-20T17:28:54 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7397",
"html_url": "https://github.com/huggingface/datasets/pull/7397",
"diff_url": "https://github.com/huggingface/datasets/pull/7397.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7397.patch",
"merged_at": null
} | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7397/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7397/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7400 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7400/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7400/comments | https://api.github.com/repos/huggingface/datasets/issues/7400/events | https://github.com/huggingface/datasets/issues/7400 | 2,853,201,277 | I_kwDODunzps6qEGV9 | 7,400 | 504 Gateway Timeout when uploading large dataset to Hugging Face Hub | {
"login": "hotchpotch",
"id": 3500,
"node_id": "MDQ6VXNlcjM1MDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3500?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hotchpotch",
"html_url": "https://github.com/hotchpotch",
"followers_url": "https://api.github.com/users/hotchpotch/followers",
"following_url": "https://api.github.com/users/hotchpotch/following{/other_user}",
"gists_url": "https://api.github.com/users/hotchpotch/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hotchpotch/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hotchpotch/subscriptions",
"organizations_url": "https://api.github.com/users/hotchpotch/orgs",
"repos_url": "https://api.github.com/users/hotchpotch/repos",
"events_url": "https://api.github.com/users/hotchpotch/events{/privacy}",
"received_events_url": "https://api.github.com/users/hotchpotch/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | open | false | null | [] | null | 4 | 2025-02-14T02:18:35 | 2025-02-14T23:48:36 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Description
I encountered consistent 504 Gateway Timeout errors while attempting to upload a large dataset (approximately 500GB) to the Hugging Face Hub. The upload fails during the process with a Gateway Timeout error.
I will continue trying to upload. While it might succeed in future attempts, I wanted to report this issue in the meantime.
### Reproduction
- I attempted the upload 3 times
- Each attempt resulted in the same 504 error during the upload process (not at the start, but in the middle of the upload)
- Using `dataset.push_to_hub()` method
### Environment Information
```
- huggingface_hub version: 0.28.0
- Platform: Linux-6.8.0-52-generic-x86_64-with-glibc2.39
- Python version: 3.11.10
- Running in iPython ?: No
- Running in notebook ?: No
- Running in Google Colab ?: No
- Running in Google Colab Enterprise ?: No
- Token path ?: /home/hotchpotch/.cache/huggingface/token
- Has saved token ?: True
- Who am I ?: hotchpotch
- Configured git credential helpers: store
- FastAI: N/A
- Tensorflow: N/A
- Torch: 2.5.1
- Jinja2: 3.1.5
- Graphviz: N/A
- keras: N/A
- Pydot: N/A
- Pillow: 10.4.0
- hf_transfer: N/A
- gradio: N/A
- tensorboard: N/A
- numpy: 1.26.4
- pydantic: 2.10.6
- aiohttp: 3.11.11
- ENDPOINT: https://huggingface.co
- HF_HUB_CACHE: /home/hotchpotch/.cache/huggingface/hub
- HF_ASSETS_CACHE: /home/hotchpotch/.cache/huggingface/assets
- HF_TOKEN_PATH: /home/hotchpotch/.cache/huggingface/token
- HF_STORED_TOKENS_PATH: /home/hotchpotch/.cache/huggingface/stored_tokens
- HF_HUB_OFFLINE: False
- HF_HUB_DISABLE_TELEMETRY: False
- HF_HUB_DISABLE_PROGRESS_BARS: None
- HF_HUB_DISABLE_SYMLINKS_WARNING: False
- HF_HUB_DISABLE_EXPERIMENTAL_WARNING: False
- HF_HUB_DISABLE_IMPLICIT_TOKEN: False
- HF_HUB_ENABLE_HF_TRANSFER: False
- HF_HUB_ETAG_TIMEOUT: 10
- HF_HUB_DOWNLOAD_TIMEOUT: 10
```
### Full Error Traceback
```python
Traceback (most recent call last):
File "/home/hotchpotch/src/github.com/hotchpotch/fineweb-2-edu-classifier-japanese/.venv/lib/python3.11/site-packages/huggingface_hub/utils/_http.py", line 406, in hf_raise_for_status
response.raise_for_status()
File "/home/hotchpotch/src/github.com/hotchpotch/fineweb-2-edu-classifier-japanese/.venv/lib/python3.11/site-packages/requests/models.py", line 1024, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 504 Server Error: Gateway Time-out for url: https://huggingface.co/datasets/hotchpotch/fineweb-2-edu-japanese.git/info/lfs/objects/batch
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/hotchpotch/src/github.com/hotchpotch/fineweb-2-edu-classifier-japanese/create_edu_japanese_ds/upload_edu_japanese_ds.py", line 12, in <module>
ds.push_to_hub("hotchpotch/fineweb-2-edu-japanese", private=True)
File "/home/hotchpotch/src/github.com/hotchpotch/fineweb-2-edu-classifier-japanese/.venv/lib/python3.11/site-packages/datasets/dataset_dict.py", line 1665, in push_to_hub
split_additions, uploaded_size, dataset_nbytes = self[split]._push_parquet_shards_to_hub(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/hotchpotch/src/github.com/hotchpotch/fineweb-2-edu-classifier-japanese/.venv/lib/python3.11/site-packages/datasets/arrow_dataset.py", line 5301, in _push_parquet_shards_to_hub
api.preupload_lfs_files(
File "/home/hotchpotch/src/github.com/hotchpotch/fineweb-2-edu-classifier-japanese/.venv/lib/python3.11/site-packages/huggingface_hub/hf_api.py", line 4215, in preupload_lfs_files
_upload_lfs_files(
File "/home/hotchpotch/src/github.com/hotchpotch/fineweb-2-edu-classifier-japanese/.venv/lib/python3.11/site-packages/huggingface_hub/utils/_validators.py", line 114, in _inner_fn
return fn(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^
File "/home/hotchpotch/src/github.com/hotchpotch/fineweb-2-edu-classifier-japanese/.venv/lib/python3.11/site-packages/huggingface_hub/_commit_api.py", line 395, in _upload_lfs_files
batch_actions_chunk, batch_errors_chunk = post_lfs_batch_info(
^^^^^^^^^^^^^^^^^^^^
File "/home/hotchpotch/src/github.com/hotchpotch/fineweb-2-edu-classifier-japanese/.venv/lib/python3.11/site-packages/huggingface_hub/utils/_validators.py", line 114, in _inner_fn
return fn(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^
File "/home/hotchpotch/src/github.com/hotchpotch/fineweb-2-edu-classifier-japanese/.venv/lib/python3.11/site-packages/huggingface_hub/lfs.py", line 168, in post_lfs_batch_info
hf_raise_for_status(resp)
File "/home/hotchpotch/src/github.com/hotchpotch/fineweb-2-edu-classifier-japanese/.venv/lib/python3.11/site-packages/huggingface_hub/utils/_http.py", line 477, in hf_raise_for_status
raise _format(HfHubHTTPError, str(e), response) from e
huggingface_hub.errors.HfHubHTTPError: 504 Server Error: Gateway Time-out for url: https://huggingface.co/datasets/hotchpotch/fineweb-2-edu-japanese.git/info/lfs/objects/batch
```
| null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7400/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7400/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7396 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7396/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7396/comments | https://api.github.com/repos/huggingface/datasets/issues/7396/events | https://github.com/huggingface/datasets/pull/7396 | 2,851,716,755 | PR_kwDODunzps6LJBmT | 7,396 | Update README.md | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | 2025-02-13T17:44:36 | 2025-02-13T17:46:57 | null | MEMBER | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7396",
"html_url": "https://github.com/huggingface/datasets/pull/7396",
"diff_url": "https://github.com/huggingface/datasets/pull/7396.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7396.patch",
"merged_at": "2025-02-13T17:44:51"
} | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7396/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7396/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7395 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7395/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7395/comments | https://api.github.com/repos/huggingface/datasets/issues/7395/events | https://github.com/huggingface/datasets/pull/7395 | 2,851,575,160 | PR_kwDODunzps6LIivQ | 7,395 | Update docs | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | 2025-02-13T16:43:15 | 2025-02-13T17:20:32 | null | MEMBER | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7395",
"html_url": "https://github.com/huggingface/datasets/pull/7395",
"diff_url": "https://github.com/huggingface/datasets/pull/7395.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7395.patch",
"merged_at": "2025-02-13T17:20:29"
} | - update min python version
- replace canonical dataset names with new names
- avoid examples with trust_remote_code | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7395/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7395/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7394 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7394/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7394/comments | https://api.github.com/repos/huggingface/datasets/issues/7394/events | https://github.com/huggingface/datasets/issues/7394 | 2,847,172,115 | I_kwDODunzps6ptGYT | 7,394 | Using load_dataset with data_files and split arguments yields an error | {
"login": "devon-research",
"id": 61103399,
"node_id": "MDQ6VXNlcjYxMTAzMzk5",
"avatar_url": "https://avatars.githubusercontent.com/u/61103399?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/devon-research",
"html_url": "https://github.com/devon-research",
"followers_url": "https://api.github.com/users/devon-research/followers",
"following_url": "https://api.github.com/users/devon-research/following{/other_user}",
"gists_url": "https://api.github.com/users/devon-research/gists{/gist_id}",
"starred_url": "https://api.github.com/users/devon-research/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/devon-research/subscriptions",
"organizations_url": "https://api.github.com/users/devon-research/orgs",
"repos_url": "https://api.github.com/users/devon-research/repos",
"events_url": "https://api.github.com/users/devon-research/events{/privacy}",
"received_events_url": "https://api.github.com/users/devon-research/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 2025-02-12T04:50:11 | 2025-02-12T04:50:11 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
It seems the list of valid splits recorded by the package becomes incorrectly overwritten when using the `data_files` argument.
If I run
```python
from datasets import load_dataset
load_dataset("allenai/super", split="all_examples", data_files="tasks/expert.jsonl")
```
then I get the error
```
ValueError: Unknown split "all_examples". Should be one of ['train'].
```
However, if I run
```python
from datasets import load_dataset
load_dataset("allenai/super", split="train", name="Expert")
```
then I get
```
ValueError: Unknown split "train". Should be one of ['all_examples'].
```
### Steps to reproduce the bug
Run
```python
from datasets import load_dataset
load_dataset("allenai/super", split="all_examples", data_files="tasks/expert.jsonl")
```
### Expected behavior
No error.
### Environment info
Python = 3.12
datasets = 3.2.0 | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7394/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7394/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7393 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7393/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7393/comments | https://api.github.com/repos/huggingface/datasets/issues/7393/events | https://github.com/huggingface/datasets/pull/7393 | 2,846,446,674 | PR_kwDODunzps6K3DiZ | 7,393 | Optimized sequence encoding for scalars | {
"login": "lukasgd",
"id": 38319063,
"node_id": "MDQ6VXNlcjM4MzE5MDYz",
"avatar_url": "https://avatars.githubusercontent.com/u/38319063?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lukasgd",
"html_url": "https://github.com/lukasgd",
"followers_url": "https://api.github.com/users/lukasgd/followers",
"following_url": "https://api.github.com/users/lukasgd/following{/other_user}",
"gists_url": "https://api.github.com/users/lukasgd/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lukasgd/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lukasgd/subscriptions",
"organizations_url": "https://api.github.com/users/lukasgd/orgs",
"repos_url": "https://api.github.com/users/lukasgd/repos",
"events_url": "https://api.github.com/users/lukasgd/events{/privacy}",
"received_events_url": "https://api.github.com/users/lukasgd/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | 2025-02-11T20:30:44 | 2025-02-13T17:11:33 | null | CONTRIBUTOR | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7393",
"html_url": "https://github.com/huggingface/datasets/pull/7393",
"diff_url": "https://github.com/huggingface/datasets/pull/7393.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7393.patch",
"merged_at": "2025-02-13T17:11:32"
} | The change in https://github.com/huggingface/datasets/pull/3197 introduced redundant list-comprehensions when `obj` is a long sequence of scalars. This becomes a noticeable overhead when loading data from an `IterableDataset` in the function `_apply_feature_types_on_example` and can be eliminated by adding a check for scalars in `encode_nested_example` proposed here.
In the following code example
```
import time
from datasets.features import Sequence, Value
from datasets.features.features import encode_nested_example
schema = Sequence(Value("int32"))
obj = list(range(100000))
start = time.perf_counter()
result = encode_nested_example(schema, obj)
stop = time.perf_counter()
print(f"Time spent is {stop-start} sec")
```
`encode_nested_example` becomes 492x faster (from 0.0769 to 0.0002 sec), respectively 322x (from 0.00814 to 0.00003 sec) for a list of length 10000, on a GH200 system, making it unnoticeable when loading data with tokenization.
Another change is made to avoid creating arrays from scalars and afterwards re-extracting them during casting to python (`obj == obj.__array__()[()]` in that case), which avoids a regression in the array write benchmarks. | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7393/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7393/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7392 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7392/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7392/comments | https://api.github.com/repos/huggingface/datasets/issues/7392/events | https://github.com/huggingface/datasets/issues/7392 | 2,846,095,043 | I_kwDODunzps6po_bD | 7,392 | push_to_hub payload too large error when using large ClassLabel feature | {
"login": "DavidRConnell",
"id": 35470740,
"node_id": "MDQ6VXNlcjM1NDcwNzQw",
"avatar_url": "https://avatars.githubusercontent.com/u/35470740?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DavidRConnell",
"html_url": "https://github.com/DavidRConnell",
"followers_url": "https://api.github.com/users/DavidRConnell/followers",
"following_url": "https://api.github.com/users/DavidRConnell/following{/other_user}",
"gists_url": "https://api.github.com/users/DavidRConnell/gists{/gist_id}",
"starred_url": "https://api.github.com/users/DavidRConnell/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/DavidRConnell/subscriptions",
"organizations_url": "https://api.github.com/users/DavidRConnell/orgs",
"repos_url": "https://api.github.com/users/DavidRConnell/repos",
"events_url": "https://api.github.com/users/DavidRConnell/events{/privacy}",
"received_events_url": "https://api.github.com/users/DavidRConnell/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | open | false | null | [] | null | 1 | 2025-02-11T17:51:34 | 2025-02-11T18:01:31 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
When using `datasets.DatasetDict.push_to_hub` an `HfHubHTTPError: 413 Client Error: Payload Too Large for url` is raised if the dataset contains a large `ClassLabel` feature. Even if the total size of the dataset is small.
### Steps to reproduce the bug
``` python
import random
import sys
import datasets
random.seed(42)
def random_str(sz):
return "".join(chr(random.randint(ord("a"), ord("z"))) for _ in range(sz))
data = datasets.DatasetDict(
{
str(i): datasets.Dataset.from_dict(
{
"label": [list(range(3)) for _ in range(10)],
"abstract": [random_str(10_000) for _ in range(10)],
},
)
for i in range(3)
}
)
features = data["1"].features.copy()
features["label"] = datasets.Sequence(
datasets.ClassLabel(names=[str(i) for i in range(50_000)])
)
data = data.map(lambda examples: {}, features=features)
feat_size = sys.getsizeof(data["1"].features["label"].feature.names)
print(f"Size of ClassLabel names: {feat_size}")
# Size of ClassLabel names: 444376
data.push_to_hub("dconnell/pubtator3_test")
```
Note that this succeeds if `ClassLabel` has fewer names or if `ClassLabel` is replaced with `Value("int64")`
### Expected behavior
Should push the dataset to hub.
### Environment info
Copy-and-paste the text below in your GitHub issue.
- `datasets` version: 3.2.0
- Platform: Linux-5.15.0-126-generic-x86_64-with-glibc2.35
- Python version: 3.12.8
- `huggingface_hub` version: 0.28.1
- PyArrow version: 19.0.0
- Pandas version: 2.2.3
- `fsspec` version: 2024.9.0
| null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7392/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7392/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7391 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7391/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7391/comments | https://api.github.com/repos/huggingface/datasets/issues/7391/events | https://github.com/huggingface/datasets/issues/7391 | 2,845,184,764 | I_kwDODunzps6plhL8 | 7,391 | AttributeError: module 'pyarrow.lib' has no attribute 'ListViewType' | {
"login": "LinXin04",
"id": 25193686,
"node_id": "MDQ6VXNlcjI1MTkzNjg2",
"avatar_url": "https://avatars.githubusercontent.com/u/25193686?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LinXin04",
"html_url": "https://github.com/LinXin04",
"followers_url": "https://api.github.com/users/LinXin04/followers",
"following_url": "https://api.github.com/users/LinXin04/following{/other_user}",
"gists_url": "https://api.github.com/users/LinXin04/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LinXin04/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LinXin04/subscriptions",
"organizations_url": "https://api.github.com/users/LinXin04/orgs",
"repos_url": "https://api.github.com/users/LinXin04/repos",
"events_url": "https://api.github.com/users/LinXin04/events{/privacy}",
"received_events_url": "https://api.github.com/users/LinXin04/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 2025-02-11T12:02:26 | 2025-02-11T12:02:26 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | pyarrow 尝试了若干个版本都不可以 | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7391/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7391/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7390 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7390/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7390/comments | https://api.github.com/repos/huggingface/datasets/issues/7390/events | https://github.com/huggingface/datasets/issues/7390 | 2,843,813,365 | I_kwDODunzps6pgSX1 | 7,390 | Re-add py.typed | {
"login": "NeilGirdhar",
"id": 730137,
"node_id": "MDQ6VXNlcjczMDEzNw==",
"avatar_url": "https://avatars.githubusercontent.com/u/730137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NeilGirdhar",
"html_url": "https://github.com/NeilGirdhar",
"followers_url": "https://api.github.com/users/NeilGirdhar/followers",
"following_url": "https://api.github.com/users/NeilGirdhar/following{/other_user}",
"gists_url": "https://api.github.com/users/NeilGirdhar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NeilGirdhar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NeilGirdhar/subscriptions",
"organizations_url": "https://api.github.com/users/NeilGirdhar/orgs",
"repos_url": "https://api.github.com/users/NeilGirdhar/repos",
"events_url": "https://api.github.com/users/NeilGirdhar/events{/privacy}",
"received_events_url": "https://api.github.com/users/NeilGirdhar/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | 0 | 2025-02-10T22:12:52 | 2025-02-10T22:12:52 | null | CONTRIBUTOR | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
The motivation for removing py.typed no longer seems to apply. Would a solution like [this one](https://github.com/huggingface/huggingface_hub/pull/2752) work here?
### Motivation
MyPy support is broken. As more type checkers come out, such as RedKnot, these may also be broken. It would be good to be PEP 561 compliant as long as it's not too onerous.
### Your contribution
I can re-add py.typed, but I don't know how to make sur all of the `__all__` files are provided (although you may not need to with modern PyRight). | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7390/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7390/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7389 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7389/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7389/comments | https://api.github.com/repos/huggingface/datasets/issues/7389/events | https://github.com/huggingface/datasets/issues/7389 | 2,843,592,606 | I_kwDODunzps6pfcee | 7,389 | Getting statistics about filtered examples | {
"login": "jonathanasdf",
"id": 511073,
"node_id": "MDQ6VXNlcjUxMTA3Mw==",
"avatar_url": "https://avatars.githubusercontent.com/u/511073?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jonathanasdf",
"html_url": "https://github.com/jonathanasdf",
"followers_url": "https://api.github.com/users/jonathanasdf/followers",
"following_url": "https://api.github.com/users/jonathanasdf/following{/other_user}",
"gists_url": "https://api.github.com/users/jonathanasdf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jonathanasdf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jonathanasdf/subscriptions",
"organizations_url": "https://api.github.com/users/jonathanasdf/orgs",
"repos_url": "https://api.github.com/users/jonathanasdf/repos",
"events_url": "https://api.github.com/users/jonathanasdf/events{/privacy}",
"received_events_url": "https://api.github.com/users/jonathanasdf/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | closed | false | null | [] | null | 2 | 2025-02-10T20:48:29 | 2025-02-11T20:44:15 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | @lhoestq wondering if the team has thought about this and if there are any recommendations?
Currently when processing datasets some examples are bound to get filtered out, whether it's due to bad format, or length is too long, or any other custom filters that might be getting applied. Let's just focus on the filter by length for now, since that would be something that gets applied dynamically for each training run. Say we want to show a graph in W&B with the running total of the number of filtered examples so far.
What would be a good way to go about hooking this up? Because the map/filter operations happen before the DataLoader batches are created, at training time if we're just grabbing batches from the DataLoader then we won't know how many things have been filtered already. But there's not really a good way to include a 'num_filtered' key into the dataset itself either because dataset map/filter process examples independently and don't have a way to track a running sum.
The only approach I can kind of think of is having a 'is_filtered' key in the dataset, and then creating a custom batcher/collator that reads that and tracks the metric? | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7389/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7389/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7388 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7388/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7388/comments | https://api.github.com/repos/huggingface/datasets/issues/7388/events | https://github.com/huggingface/datasets/issues/7388 | 2,843,188,499 | I_kwDODunzps6pd50T | 7,388 | OSError: [Errno 22] Invalid argument forbidden character | {
"login": "langflogit",
"id": 124634542,
"node_id": "U_kgDOB23Frg",
"avatar_url": "https://avatars.githubusercontent.com/u/124634542?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/langflogit",
"html_url": "https://github.com/langflogit",
"followers_url": "https://api.github.com/users/langflogit/followers",
"following_url": "https://api.github.com/users/langflogit/following{/other_user}",
"gists_url": "https://api.github.com/users/langflogit/gists{/gist_id}",
"starred_url": "https://api.github.com/users/langflogit/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/langflogit/subscriptions",
"organizations_url": "https://api.github.com/users/langflogit/orgs",
"repos_url": "https://api.github.com/users/langflogit/repos",
"events_url": "https://api.github.com/users/langflogit/events{/privacy}",
"received_events_url": "https://api.github.com/users/langflogit/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | closed | false | null | [] | null | 2 | 2025-02-10T17:46:31 | 2025-02-11T13:42:32 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
I'm on Windows and i'm trying to load a datasets but i'm having title error because files in the repository are named with charactere like < >which can't be in a name file. Could it be possible to load this datasets but removing those charactere ?
### Steps to reproduce the bug
load_dataset("CATMuS/medieval") on Windows
### Expected behavior
Making the function to erase the forbidden character to allow loading the datasets who have those characters.
### Environment info
- `datasets` version: 3.2.0
- Platform: Windows-10-10.0.19045-SP0
- Python version: 3.12.2
- `huggingface_hub` version: 0.28.1
- PyArrow version: 19.0.0
- Pandas version: 2.2.3
- `fsspec` version: 2024.9.0 | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7388/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7388/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7387 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7387/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7387/comments | https://api.github.com/repos/huggingface/datasets/issues/7387/events | https://github.com/huggingface/datasets/issues/7387 | 2,841,228,048 | I_kwDODunzps6pWbMQ | 7,387 | Dynamic adjusting dataloader sampling weight | {
"login": "whc688",
"id": 72799643,
"node_id": "MDQ6VXNlcjcyNzk5NjQz",
"avatar_url": "https://avatars.githubusercontent.com/u/72799643?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/whc688",
"html_url": "https://github.com/whc688",
"followers_url": "https://api.github.com/users/whc688/followers",
"following_url": "https://api.github.com/users/whc688/following{/other_user}",
"gists_url": "https://api.github.com/users/whc688/gists{/gist_id}",
"starred_url": "https://api.github.com/users/whc688/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/whc688/subscriptions",
"organizations_url": "https://api.github.com/users/whc688/orgs",
"repos_url": "https://api.github.com/users/whc688/repos",
"events_url": "https://api.github.com/users/whc688/events{/privacy}",
"received_events_url": "https://api.github.com/users/whc688/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | open | false | null | [] | null | 3 | 2025-02-10T03:18:47 | 2025-02-11T13:24:05 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | Hi,
Thanks for your wonderful work! I'm wondering is there a way to dynamically adjust the sampling weight of each data in the dataset during training? Looking forward to your reply, thanks again. | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7387/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7387/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7386 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7386/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7386/comments | https://api.github.com/repos/huggingface/datasets/issues/7386/events | https://github.com/huggingface/datasets/issues/7386 | 2,840,032,524 | I_kwDODunzps6pR3UM | 7,386 | Add bookfolder Dataset Builder for Digital Book Formats | {
"login": "shikanime",
"id": 22115108,
"node_id": "MDQ6VXNlcjIyMTE1MTA4",
"avatar_url": "https://avatars.githubusercontent.com/u/22115108?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shikanime",
"html_url": "https://github.com/shikanime",
"followers_url": "https://api.github.com/users/shikanime/followers",
"following_url": "https://api.github.com/users/shikanime/following{/other_user}",
"gists_url": "https://api.github.com/users/shikanime/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shikanime/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shikanime/subscriptions",
"organizations_url": "https://api.github.com/users/shikanime/orgs",
"repos_url": "https://api.github.com/users/shikanime/repos",
"events_url": "https://api.github.com/users/shikanime/events{/privacy}",
"received_events_url": "https://api.github.com/users/shikanime/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | 1 | 2025-02-08T14:27:55 | 2025-02-08T14:30:10 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
This feature proposes adding a new dataset builder called bookfolder to the datasets library. This builder would allow users to easily load datasets consisting of various digital book formats, including: AZW, AZW3, CB7, CBR, CBT, CBZ, EPUB, MOBI, and PDF.
### Motivation
Currently, loading datasets of these digital book files requires manual effort. This would also lower the barrier to entry for working with these formats, enabling more diverse and interesting datasets to be used within the Hugging Face ecosystem.
### Your contribution
This feature is rather simple as it will be based on the folder-based builder, similar to imagefolder. I'm willing to contribute to this feature by submitting a PR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7386/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7386/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7385 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7385/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7385/comments | https://api.github.com/repos/huggingface/datasets/issues/7385/events | https://github.com/huggingface/datasets/pull/7385 | 2,830,664,522 | PR_kwDODunzps6KBO6i | 7,385 | Make IterableDataset (optionally) resumable | {
"login": "yzhangcs",
"id": 18402347,
"node_id": "MDQ6VXNlcjE4NDAyMzQ3",
"avatar_url": "https://avatars.githubusercontent.com/u/18402347?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yzhangcs",
"html_url": "https://github.com/yzhangcs",
"followers_url": "https://api.github.com/users/yzhangcs/followers",
"following_url": "https://api.github.com/users/yzhangcs/following{/other_user}",
"gists_url": "https://api.github.com/users/yzhangcs/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yzhangcs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yzhangcs/subscriptions",
"organizations_url": "https://api.github.com/users/yzhangcs/orgs",
"repos_url": "https://api.github.com/users/yzhangcs/repos",
"events_url": "https://api.github.com/users/yzhangcs/events{/privacy}",
"received_events_url": "https://api.github.com/users/yzhangcs/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | open | false | null | [] | null | 1 | 2025-02-04T15:55:33 | 2025-02-06T07:40:19 | null | CONTRIBUTOR | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7385",
"html_url": "https://github.com/huggingface/datasets/pull/7385",
"diff_url": "https://github.com/huggingface/datasets/pull/7385.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7385.patch",
"merged_at": null
} | ### What does this PR do?
This PR introduces a new `stateful` option to the `dataset.shuffle` method, which defaults to `False`.
When enabled, this option allows for resumable shuffling of `IterableDataset` instances, albeit with some additional memory overhead.
Key points:
* All tests have passed
* Docstrings have been updated to reflect the new functionality
I'm very looking forward to receiving feedback on this implementation! @lhoestq | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7385/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7385/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7384 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7384/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7384/comments | https://api.github.com/repos/huggingface/datasets/issues/7384/events | https://github.com/huggingface/datasets/pull/7384 | 2,828,208,828 | PR_kwDODunzps6J4wVi | 7,384 | Support async functions in map() | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | closed | false | null | [] | null | 2 | 2025-02-03T18:18:40 | 2025-02-13T14:01:13 | null | MEMBER | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7384",
"html_url": "https://github.com/huggingface/datasets/pull/7384",
"diff_url": "https://github.com/huggingface/datasets/pull/7384.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7384.patch",
"merged_at": "2025-02-13T14:00:06"
} | e.g. to download images or call an inference API like HF or vLLM
```python
import asyncio
import random
from datasets import Dataset
async def f(x):
await asyncio.sleep(random.random())
ds = Dataset.from_dict({"data": range(100)})
ds.map(f)
# Map: 100%|█████████████████████████████| 100/100 [00:01<00:00, 99.81 examples/s]
```
TODO
- [x] clean code (right now it's a big copy paste)
- [x] batched
- [x] Dataset.map()
- [x] IterableDataset.map()
- [x] Dataset.filter()
- [x] IterableDataset.filter()
- [x] test
- [x] docs | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7384/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 3,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7384/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7382 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7382/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7382/comments | https://api.github.com/repos/huggingface/datasets/issues/7382/events | https://github.com/huggingface/datasets/pull/7382 | 2,823,480,924 | PR_kwDODunzps6Jo69f | 7,382 | Add Pandas, PyArrow and Polars docs | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | closed | false | null | [] | null | 1 | 2025-01-31T13:22:59 | 2025-01-31T16:30:59 | null | MEMBER | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7382",
"html_url": "https://github.com/huggingface/datasets/pull/7382",
"diff_url": "https://github.com/huggingface/datasets/pull/7382.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7382.patch",
"merged_at": "2025-01-31T16:30:57"
} | (also added the missing numpy docs and fixed a small bug in pyarrow formatting) | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7382/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7382/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7381 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7381/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7381/comments | https://api.github.com/repos/huggingface/datasets/issues/7381/events | https://github.com/huggingface/datasets/issues/7381 | 2,815,649,092 | I_kwDODunzps6n02VE | 7,381 | Iterating over values of a column in the IterableDataset | {
"login": "TopCoder2K",
"id": 47208659,
"node_id": "MDQ6VXNlcjQ3MjA4NjU5",
"avatar_url": "https://avatars.githubusercontent.com/u/47208659?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TopCoder2K",
"html_url": "https://github.com/TopCoder2K",
"followers_url": "https://api.github.com/users/TopCoder2K/followers",
"following_url": "https://api.github.com/users/TopCoder2K/following{/other_user}",
"gists_url": "https://api.github.com/users/TopCoder2K/gists{/gist_id}",
"starred_url": "https://api.github.com/users/TopCoder2K/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TopCoder2K/subscriptions",
"organizations_url": "https://api.github.com/users/TopCoder2K/orgs",
"repos_url": "https://api.github.com/users/TopCoder2K/repos",
"events_url": "https://api.github.com/users/TopCoder2K/events{/privacy}",
"received_events_url": "https://api.github.com/users/TopCoder2K/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | 2 | 2025-01-28T13:17:36 | 2025-02-18T17:15:51 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
I would like to be able to iterate (and re-iterate if needed) over a column of an `IterableDataset` instance. The following example shows the supposed API:
```
def gen():
yield {"text": "Good", "label": 0}
yield {"text": "Bad", "label": 1}
ds = IterableDataset.from_generator(gen)
texts = ds["text"]
for v in texts:
print(v) # Prints "Good" and "Bad"
for v in texts:
print(v) # Prints "Good" and "Bad" again
```
### Motivation
In the real world problems, huge NNs like Transformer are not always the best option, so there is a need to conduct experiments with different methods. While 🤗Datasets is perfectly adapted to 🤗Transformers, it may be inconvenient when being used with other libraries. The ability to retrieve a particular column is the case (e.g., gensim's FastText [requires](https://radimrehurek.com/gensim/models/fasttext.html#gensim.models.fasttext.FastText.train) only lists of strings, not dictionaries).
While there are ways to achieve the desired functionality, they are not good ([forum](https://discuss.huggingface.co/t/how-to-iterate-over-values-of-a-column-in-the-iterabledataset/135649)). It would be great if there was a built-in solution.
### Your contribution
Theoretically, I can submit a PR, but I have very little knowledge of the internal structure of 🤗Datasets, so some help may be needed.
Moreover, I can only work on weekends, since I have a full-time job. However, the feature does not seem to be popular, so there is no need to implement it as fast as possible. | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7381/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7381/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7380 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7380/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7380/comments | https://api.github.com/repos/huggingface/datasets/issues/7380/events | https://github.com/huggingface/datasets/pull/7380 | 2,811,566,116 | PR_kwDODunzps6JAkj5 | 7,380 | fix: dill default for version bigger 0.3.8 | {
"login": "sam-hey",
"id": 40773225,
"node_id": "MDQ6VXNlcjQwNzczMjI1",
"avatar_url": "https://avatars.githubusercontent.com/u/40773225?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sam-hey",
"html_url": "https://github.com/sam-hey",
"followers_url": "https://api.github.com/users/sam-hey/followers",
"following_url": "https://api.github.com/users/sam-hey/following{/other_user}",
"gists_url": "https://api.github.com/users/sam-hey/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sam-hey/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sam-hey/subscriptions",
"organizations_url": "https://api.github.com/users/sam-hey/orgs",
"repos_url": "https://api.github.com/users/sam-hey/repos",
"events_url": "https://api.github.com/users/sam-hey/events{/privacy}",
"received_events_url": "https://api.github.com/users/sam-hey/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 2025-01-26T13:37:16 | 2025-01-26T13:37:16 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7380",
"html_url": "https://github.com/huggingface/datasets/pull/7380",
"diff_url": "https://github.com/huggingface/datasets/pull/7380.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7380.patch",
"merged_at": null
} | Fixes def log for dill version >= 0.3.9 | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7380/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7380/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7378 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7378/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7378/comments | https://api.github.com/repos/huggingface/datasets/issues/7378/events | https://github.com/huggingface/datasets/issues/7378 | 2,802,957,388 | I_kwDODunzps6nEbxM | 7,378 | Allow pushing config version to hub | {
"login": "momeara",
"id": 129072,
"node_id": "MDQ6VXNlcjEyOTA3Mg==",
"avatar_url": "https://avatars.githubusercontent.com/u/129072?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/momeara",
"html_url": "https://github.com/momeara",
"followers_url": "https://api.github.com/users/momeara/followers",
"following_url": "https://api.github.com/users/momeara/following{/other_user}",
"gists_url": "https://api.github.com/users/momeara/gists{/gist_id}",
"starred_url": "https://api.github.com/users/momeara/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/momeara/subscriptions",
"organizations_url": "https://api.github.com/users/momeara/orgs",
"repos_url": "https://api.github.com/users/momeara/repos",
"events_url": "https://api.github.com/users/momeara/events{/privacy}",
"received_events_url": "https://api.github.com/users/momeara/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | 1 | 2025-01-21T22:35:07 | 2025-01-30T13:56:56 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
Currently, when datasets are created, they can be versioned by passing the `version` argument to `load_dataset(...)`. For example creating `outcomes.csv` on the command line
```
echo "id,value\n1,0\n2,0\n3,1\n4,1\n" > outcomes.csv
```
and creating it
```
import datasets
dataset = datasets.load_dataset(
"csv",
data_files ="outcomes.csv",
keep_in_memory = True,
version = '1.0.0')
```
The version info is stored in the `info` and can be accessed e.g. by `next(iter(dataset.values())).info.version`
This dataset can be uploaded to the hub with `dataset.push_to_hub(repo_id = "maomlab/example_dataset")`. This will create a dataset on the hub with the following in the `README.md`, but it doesn't upload the version information:
```
---
dataset_info:
features:
- name: id
dtype: int64
- name: value
dtype: int64
splits:
- name: train
num_bytes: 64
num_examples: 4
download_size: 1332
dataset_size: 64
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
```
However, when I download from the hub, the version information is missing:
```
dataset_from_hub_no_version = datasets.load_dataset("maomlab/example_dataset")
next(iter(dataset.values())).info.version
```
I can add the version information manually to the hub, by appending it to the end of config section:
```
...
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
version: 1.0.0
---
```
And then when I download it, the version information is correct.
### Motivation
### Why adding version information for each config makes sense
1. The version information is already recorded in the dataset config info data structure and is able to parse it correctly, so it makes sense to sync it with `push_to_hub`.
2. Keeping the version info in at the config level is different from version info at the branch level. As the former relates to the version of the specific dataset the config refers to rather than the version of the dataset curation itself.
## A explanation for the current behavior:
In [datasets/src/datasets/info.py:159](https://github.com/huggingface/datasets/blob/fb91fd3c9ea91a818681a777faf8d0c46f14c680/src/datasets/info.py#L159C1-L160C1
), the `_INCLUDED_INFO_IN_YAML` variable doesn't include `"version"`.
If my reading of the code is right, adding `"version"` to `_INCLUDED_INFO_IN_YAML`, would allow the version information to be uploaded to the hub.
### Your contribution
Request: add `"version"` to `_INCLUDE_INFO_IN_YAML` in [datasets/src/datasets/info.py:159](https://github.com/huggingface/datasets/blob/fb91fd3c9ea91a818681a777faf8d0c46f14c680/src/datasets/info.py#L159C1-L160C1
)
| null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7378/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7378/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7377 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7377/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7377/comments | https://api.github.com/repos/huggingface/datasets/issues/7377/events | https://github.com/huggingface/datasets/issues/7377 | 2,802,723,285 | I_kwDODunzps6nDinV | 7,377 | Support for sparse arrays with the Arrow Sparse Tensor format? | {
"login": "JulesGM",
"id": 3231217,
"node_id": "MDQ6VXNlcjMyMzEyMTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/3231217?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JulesGM",
"html_url": "https://github.com/JulesGM",
"followers_url": "https://api.github.com/users/JulesGM/followers",
"following_url": "https://api.github.com/users/JulesGM/following{/other_user}",
"gists_url": "https://api.github.com/users/JulesGM/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JulesGM/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JulesGM/subscriptions",
"organizations_url": "https://api.github.com/users/JulesGM/orgs",
"repos_url": "https://api.github.com/users/JulesGM/repos",
"events_url": "https://api.github.com/users/JulesGM/events{/privacy}",
"received_events_url": "https://api.github.com/users/JulesGM/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | 1 | 2025-01-21T20:14:35 | 2025-01-30T14:06:45 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
AI in biology is becoming a big thing. One thing that would be a huge benefit to the field that Huggingface Datasets doesn't currently have is native support for **sparse arrays**.
Arrow has support for sparse tensors.
https://arrow.apache.org/docs/format/Other.html#sparse-tensor
It would be a big deal if Hugging Face Datasets supported sparse tensors as a feature type, natively.
### Motivation
This is important for example in the field of transcriptomics (modeling and understanding gene expression), because a large fraction of the genes are not expressed (zero). More generally, in science, sparse arrays are very common, so adding support for them would be very benefitial, it would make just using Hugging Face Dataset objects a lot more straightforward and clean.
### Your contribution
We can discuss this further once the team comments of what they think about the feature, and if there were previous attempts at making it work, and understanding their evaluation of how hard it would be. My intuition is that it should be fairly straightforward, as the Arrow backend already supports it. | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7377/reactions",
"total_count": 2,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/datasets/issues/7377/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7376 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7376/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7376/comments | https://api.github.com/repos/huggingface/datasets/issues/7376/events | https://github.com/huggingface/datasets/pull/7376 | 2,802,621,104 | PR_kwDODunzps6IiO9j | 7,376 | [docs] uv install | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 2025-01-21T19:15:48 | 2025-01-21T19:39:29 | null | MEMBER | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7376",
"html_url": "https://github.com/huggingface/datasets/pull/7376",
"diff_url": "https://github.com/huggingface/datasets/pull/7376.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7376.patch",
"merged_at": null
} | Proposes adding uv to installation docs (see Slack thread [here](https://huggingface.slack.com/archives/C01N44FJDHT/p1737377177709279) for more context) if you're interested! | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7376/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7376/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7375 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7375/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7375/comments | https://api.github.com/repos/huggingface/datasets/issues/7375/events | https://github.com/huggingface/datasets/issues/7375 | 2,800,609,218 | I_kwDODunzps6m7efC | 7,375 | vllm批量推理报错 | {
"login": "YuShengzuishuai",
"id": 51228154,
"node_id": "MDQ6VXNlcjUxMjI4MTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/51228154?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/YuShengzuishuai",
"html_url": "https://github.com/YuShengzuishuai",
"followers_url": "https://api.github.com/users/YuShengzuishuai/followers",
"following_url": "https://api.github.com/users/YuShengzuishuai/following{/other_user}",
"gists_url": "https://api.github.com/users/YuShengzuishuai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/YuShengzuishuai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/YuShengzuishuai/subscriptions",
"organizations_url": "https://api.github.com/users/YuShengzuishuai/orgs",
"repos_url": "https://api.github.com/users/YuShengzuishuai/repos",
"events_url": "https://api.github.com/users/YuShengzuishuai/events{/privacy}",
"received_events_url": "https://api.github.com/users/YuShengzuishuai/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | open | false | null | [] | null | 1 | 2025-01-21T03:22:23 | 2025-01-30T14:02:40 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug

### Steps to reproduce the bug
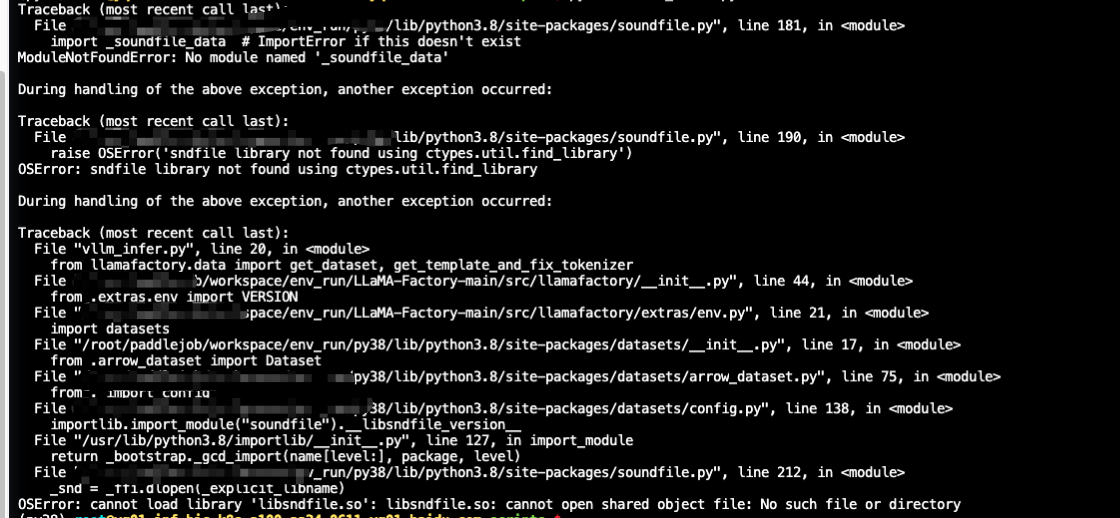
### Expected behavior

### Environment info
 | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7375/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7375/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7374 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7374/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7374/comments | https://api.github.com/repos/huggingface/datasets/issues/7374/events | https://github.com/huggingface/datasets/pull/7374 | 2,793,442,320 | PR_kwDODunzps6IC66n | 7,374 | Remove .h5 from imagefolder extensions | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | closed | false | null | [] | null | 0 | 2025-01-16T18:17:24 | 2025-01-16T18:26:40 | null | MEMBER | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7374",
"html_url": "https://github.com/huggingface/datasets/pull/7374",
"diff_url": "https://github.com/huggingface/datasets/pull/7374.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/7374.patch",
"merged_at": "2025-01-16T18:26:38"
} | the format is not relevant for imagefolder, and makes the viewer fail to process datasets on HF (so many that the viewer takes more time to process new datasets) | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7374/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7374/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/7373 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7373/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7373/comments | https://api.github.com/repos/huggingface/datasets/issues/7373/events | https://github.com/huggingface/datasets/issues/7373 | 2,793,237,139 | I_kwDODunzps6mfWqT | 7,373 | Excessive RAM Usage After Dataset Concatenation concatenate_datasets | {
"login": "sam-hey",
"id": 40773225,
"node_id": "MDQ6VXNlcjQwNzczMjI1",
"avatar_url": "https://avatars.githubusercontent.com/u/40773225?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sam-hey",
"html_url": "https://github.com/sam-hey",
"followers_url": "https://api.github.com/users/sam-hey/followers",
"following_url": "https://api.github.com/users/sam-hey/following{/other_user}",
"gists_url": "https://api.github.com/users/sam-hey/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sam-hey/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sam-hey/subscriptions",
"organizations_url": "https://api.github.com/users/sam-hey/orgs",
"repos_url": "https://api.github.com/users/sam-hey/repos",
"events_url": "https://api.github.com/users/sam-hey/events{/privacy}",
"received_events_url": "https://api.github.com/users/sam-hey/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
} | [] | open | false | null | [] | null | 1 | 2025-01-16T16:33:10 | 2025-01-17T08:05:22 | null | NONE | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
When loading a dataset from disk, concatenating it, and starting the training process, the RAM usage progressively increases until the kernel terminates the process due to excessive memory consumption.
https://github.com/huggingface/datasets/issues/2276
### Steps to reproduce the bug
```
rom datasets import DatasetDict, concatenate_datasets
dataset = DatasetDict.load_from_disk("data")
...
...
combined_dataset = concatenate_datasets(
[dataset[split] for split in dataset]
)
#start SentenceTransformer training
```
### Expected behavior
I would not expect RAM utilization to increase after concatenation. Removing the concatenation step resolves the issue
### Environment info
sentence-transformers==3.1.1
datasets==3.2.0
python3.10 | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/7373/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/7373/timeline | null | null |
End of preview.
Dataset Name: huggingface_dataset_github_repo
Description : This dataset contains structured issue data, extracted from GitHub repositories. It is useful for text classification , issue summarization etc
- Downloads last month
- 9