

base_model:
- moonshotai/Moonlight-16B-A3B
license: mit
pipeline_tag: image-text-to-text
library_name: transformers
Introduction
We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities—all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across diverse challenging vision-language tasks, including college-level image and video comprehension, optical character recognition (OCR), mathematical reasoning, multi-image understanding, and more. It effectively competes with cutting-edge efficient VLMs like GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, even surpassing GPT-4o in several specialized domains. Kimi-VL also excels in processing long contexts and high-resolution images, achieving impressive results on benchmarks like LongVideoBench, MMLongBench-Doc, InfoVQA, and ScreenSpot-Pro. We also introduce Kimi-VL-Thinking, a variant fine-tuned for long-horizon reasoning, achieving high scores on MMMU, MathVision, and MathVista with a compact 2.8B activated LLM parameter footprint.
Architecture
Kimi-VL uses a Mixture-of-Experts (MoE) language model, a native-resolution visual encoder (MoonViT), and an MLP projector.

Model Variants
| Model | #Total Params | #Activated Params | Context Length | Download Link |
|---|---|---|---|---|
| Kimi-VL-A3B-Instruct | 16B | 3B | 128K | 🤗 Hugging Face |
| Kimi-VL-A3B-Thinking | 16B | 3B | 128K | 🤗 Hugging Face |
For general multimodal tasks, OCR, long video/document understanding, video perception, and agent applications, we recommend Kimi-VL-A3B-Instruct. For advanced text and multimodal reasoning (e.g., math), use Kimi-VL-A3B-Thinking. You can also chat with the Kimi-VL-A3B-Thinking model on our Huggingface Demo.
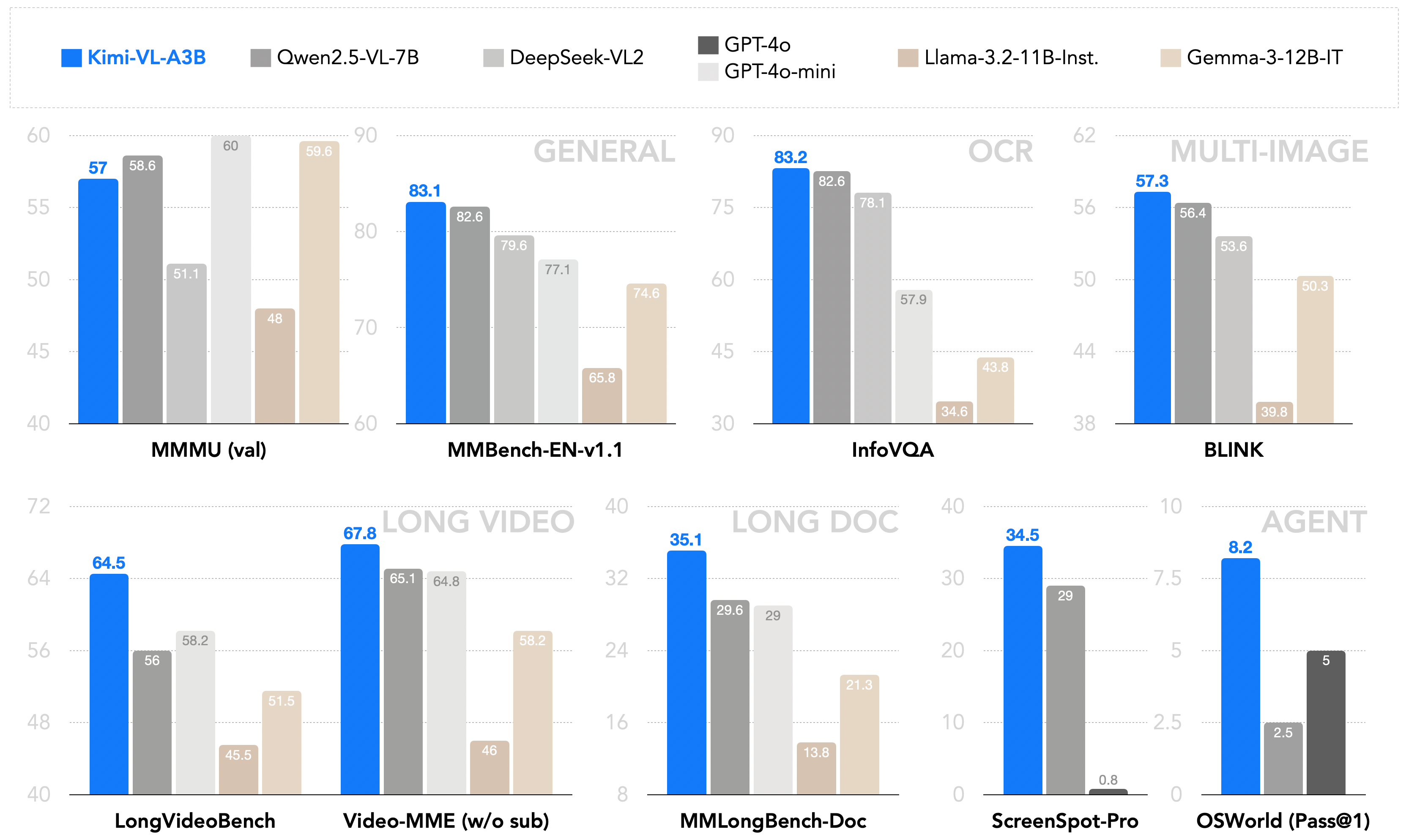
Performance
Kimi-VL robustly handles diverse tasks (perception, math, college-level problems, OCR, agent interaction) across various input formats (image, multi-image, video, long-document). See the Tech Report for detailed benchmark results. A brief comparison with other models:
Example Usage (Transformers)
from PIL import Image
from transformers import AutoModelForCausalLM, AutoProcessor
model_path = "moonshotai/Kimi-VL-A3B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype="auto", device_map="auto", trust_remote_code=True)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
image_path = "./figures/demo.png"
image = Image.open(image_path)
messages = [
{"role": "user", "content": [{"type": "image", "image": image_path}, {"type": "text", "text": "What is the dome building in the picture? Think step by step."}]}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
inputs = processor(images=image, text=text, return_tensors="pt", padding=True, truncation=True).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=512)
generated_ids_trimmed = [out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]
response = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
print(response)
Deployment (vLLM)
We have submitted a Merge Request #16387 to vLLM for easier deployment.
Citation
@misc{kimiteam2025kimivltechnicalreport,
title={{Kimi-VL} Technical Report},
author={Kimi Team and ...},
year={2025},
eprint={2504.07491},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2504.07491},
}