
Arabic-STS
Collection
4 items
•
Updated
•
1
🚀 🚀 This is Arabic only sentence-transformers model finetuned from aubmindlab/bert-base-arabertv02. It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, clustering, and more.
This model supports Matryoshka embeddings, allowing you to truncate embeddings into smaller sizes to optimize performance and memory usage, based on your task requirements. Available truncation sizes include: 768, 512, 256, 128, and 64
You can select the appropriate embedding size for your use case, ensuring flexibility in resource management.
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
First install the Sentence Transformers library:
pip install -U sentence-transformers
Then you can load this model and run inference.
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("omarelshehy/Arabic-STS-Matryoshka-V2")
# Run inference
sentences = [
'أحب قراءة الكتب في أوقات فراغي.',
'أستمتع بقراءة القصص في المساء قبل النوم.',
'القراءة تعزز معرفتي وتفتح أمامي آفاق جديدة.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
I evaluated this model on the MTEB STS17 for arabic for different Embedding sizes 🪆
The results are plotted below:
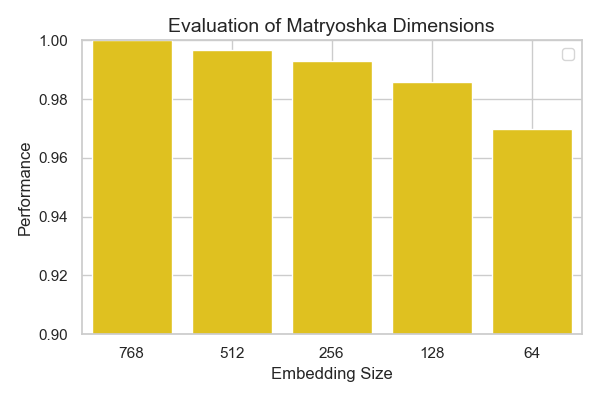
as seen from the plot, only very small degradation of performance happens across smaller matryoshka embedding sizes.
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
@misc{kusupati2024matryoshka,
title={Matryoshka Representation Learning},
author={Aditya Kusupati and Gantavya Bhatt and Aniket Rege and Matthew Wallingford and Aditya Sinha and Vivek Ramanujan and William Howard-Snyder and Kaifeng Chen and Sham Kakade and Prateek Jain and Ali Farhadi},
year={2024},
eprint={2205.13147},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Base model
aubmindlab/bert-base-arabertv02