
Multimodal AI
Collection
Large multimodal models
•
18 items
•
Updated
•
2
Note: This is the pretrained model used for OLA-VLM-CLIP-ViT-Llama3-8b.
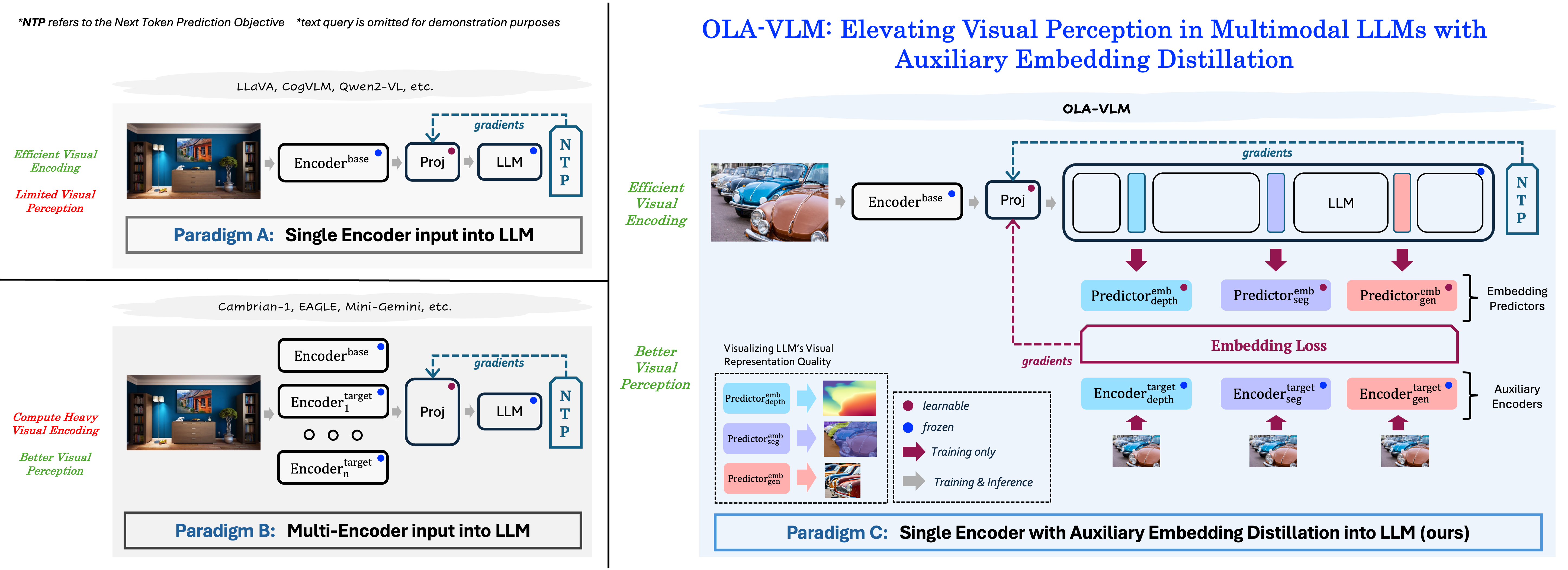
OLA-VLM distills target visual information into the intermediate representations of the LLM from a set of target encoders. It adopts a predictive embedding optimization approach at selected LLM layers during training to minimize the embedding losses along with the next token prediction (NTP) objective, resulting in a vision-centric approach to training the Multimodal Large Language Model.
If you found our work useful in your research, please consider starring ⭐ us on GitHub and citing 📚 us in your research!
@article{jain2024ola_vlm,
title={{OLA-VLM: Elevating Visual Perception in Multimodal LLMs with Auxiliary Embedding Distillation}},
author={Jitesh Jain and Zhengyuan Yang and Humphrey Shi and Jianfeng Gao and Jianwei Yang},
journal={arXiv},
year={2024}
}