
EMOVA-Models
Collection
A collection of EMOVA models (https://emova-ollm.github.io/)
•
11 items
•
Updated
•
3
![]()
🤗 EMOVA-Models | 🤗 EMOVA-Datasets | 🤗 EMOVA-Demo
📄 Paper | 🌐 Project-Page | 💻 Github | 💻 EMOVA-Speech-Tokenizer-Github
EMOVA (EMotionally Omni-present Voice Assistant) is a novel end-to-end omni-modal LLM that can see, hear and speak without relying on external models. Given the omni-modal (i.e., textual, visual and speech) inputs, EMOVA can generate both textual and speech responses with vivid emotional controls by utilizing the speech decoder together with a style encoder. EMOVA possesses general omni-modal understanding and generation capabilities, featuring its superiority in advanced vision-language understanding, emotional spoken dialogue, and spoken dialogue with structural data understanding. We summarize its key advantages as:
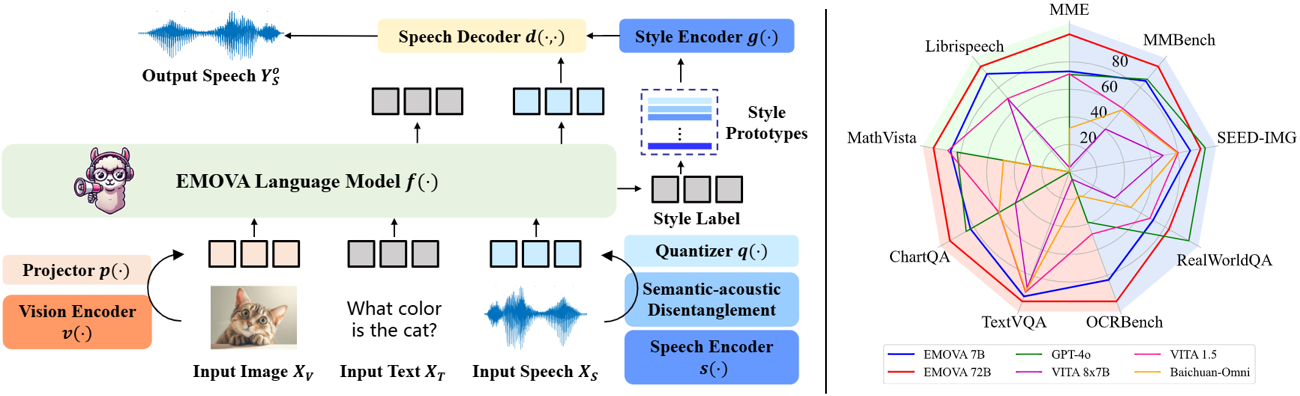
| Benchmarks | EMOVA-3B | EMOVA-7B | EMOVA-72B | GPT-4o | VITA 8x7B | VITA 1.5 | Baichuan-Omni |
|---|---|---|---|---|---|---|---|
| MME | 2175 | 2317 | 2402 | 2310 | 2097 | 2311 | 2187 |
| MMBench | 79.2 | 83.0 | 86.4 | 83.4 | 71.8 | 76.6 | 76.2 |
| SEED-Image | 74.9 | 75.5 | 76.6 | 77.1 | 72.6 | 74.2 | 74.1 |
| MM-Vet | 57.3 | 59.4 | 64.8 | - | 41.6 | 51.1 | 65.4 |
| RealWorldQA | 62.6 | 67.5 | 71.0 | 75.4 | 59.0 | 66.8 | 62.6 |
| TextVQA | 77.2 | 78.0 | 81.4 | - | 71.8 | 74.9 | 74.3 |
| ChartQA | 81.5 | 84.9 | 88.7 | 85.7 | 76.6 | 79.6 | 79.6 |
| DocVQA | 93.5 | 94.2 | 95.9 | 92.8 | - | - | - |
| InfoVQA | 71.2 | 75.1 | 83.2 | - | - | - | - |
| OCRBench | 803 | 814 | 843 | 736 | 678 | 752 | 700 |
| ScienceQA-Img | 92.7 | 96.4 | 98.2 | - | - | - | - |
| AI2D | 78.6 | 81.7 | 85.8 | 84.6 | 73.1 | 79.3 | - |
| MathVista | 62.6 | 65.5 | 69.9 | 63.8 | 44.9 | 66.2 | 51.9 |
| Mathverse | 31.4 | 40.9 | 50.0 | - | - | - | - |
| Librispeech (WER↓) | 5.4 | 4.1 | 2.9 | - | 3.4 | 8.1 | - |
This repo contains the EMOVA-Qwen2.5-72B checkpoint organized in the HuggingFace format, and thus, can be directly loaded with transformers Auto APIs.
from transformers import AutoModel, AutoProcessor
from PIL import Image
import torch
### Uncomment if you want to use Ascend NPUs
# import torch_npu
# from torch_npu.contrib import transfer_to_npu
# prepare models and processors
model = AutoModel.from_pretrained(
"Emova-ollm/emova-qwen-2-5-72b-hf",
torch_dtype=torch.bfloat16,
attn_implementation='flash_attention_2', # OR 'sdpa' for Ascend NPUs
low_cpu_mem_usage=True,
trust_remote_code=True).eval().cuda()
processor = AutoProcessor.from_pretrained("Emova-ollm/emova-qwen-2-5-72b-hf", trust_remote_code=True)
# only necessary for spoken dialogue
# Note to inference with speech inputs/outputs, **emova_speech_tokenizer** is still a necessary dependency (https://huggingface.co/Emova-ollm/emova_speech_tokenizer_hf#install).
speeck_tokenizer = AutoModel.from_pretrained("Emova-ollm/emova_speech_tokenizer_hf", torch_dtype=torch.float32, trust_remote_code=True).eval().cuda()
processor.set_speech_tokenizer(speeck_tokenizer)
# Example 1: image-text
inputs = dict(
text=[
{"role": "system", "content": [{"type": "text", "text": "You are a helpful assistant."}]},
{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": "What's shown in this image?"}]},
{"role": "assistant", "content": [{"type": "text", "text": "This image shows a red stop sign."}]},
{"role": "user", "content": [{"type": "text", "text": "Describe the image in more details."}]},
],
images=Image.open('path/to/image')
)
# Example 2: text-audio
inputs = dict(
text=[{"role": "system", "content": [{"type": "text", "text": "You are a helpful assistant."}]}],
audios='path/to/audio'
)
# Example 3: image-text-audio
inputs = dict(
text=[{"role": "system", "content": [{"type": "text", "text": "You are a helpful assistant."}]}],
images=Image.open('path/to/image'),
audios='path/to/audio'
)
# run processors
has_speech = 'audios' in inputs.keys()
inputs = processor(**inputs, return_tensors="pt")
inputs = inputs.to(model.device)
# prepare generation arguments
gen_kwargs = {"max_new_tokens": 4096, "do_sample": False} # add if necessary
speech_kwargs = {"speaker": "female", "output_wav_prefix": "output"} if has_speech else {}
# run generation
# for speech outputs, we will return the saved wav paths (c.f., output_wav_prefix)
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(processor.batch_decode(outputs, skip_special_tokens=True, **speech_kwargs))
@article{chen2024emova,
title={Emova: Empowering language models to see, hear and speak with vivid emotions},
author={Chen, Kai and Gou, Yunhao and Huang, Runhui and Liu, Zhili and Tan, Daxin and Xu, Jing and Wang, Chunwei and Zhu, Yi and Zeng, Yihan and Yang, Kuo and others},
journal={arXiv preprint arXiv:2409.18042},
year={2024}
}
Base model
Emova-ollm/qwen2vit600m